Attention » Attention(三)——Transformer
2019-07-10 :: 7143 Words花式Attention(续)
https://mp.weixin.qq.com/s/g2PcmsDW9ixUCh_yP8W-Vg
各类Seq2Seq模型对比及《Attention Is All You Need》中技术详解
https://mp.weixin.qq.com/s/FtI94xY6a8TEvFCHfjMnmA
小组讨论谷歌机器翻译Attention is All You Need
https://mp.weixin.qq.com/s/SqIMkiP1IZMGWzwZWGOI7w
谈谈神经网络的注意机制和使用方法
https://mp.weixin.qq.com/s/EMCZHuvk5dOV_Rz00GkJMA
近年火爆的Attention模型,它的套路这里都有!
https://zhuanlan.zhihu.com/p/27464080
从《Convolutional Sequence to Sequence Learning》到《Attention Is All You Need》
http://www.cnblogs.com/robert-dlut/p/8638283.html
自然语言处理中的自注意力机制!
https://mp.weixin.qq.com/s/sAYOXEjAdA91x3nliHNX8w
Attention模型方法综述
https://mp.weixin.qq.com/s/MZ8qSQzXqZQPQa97BKitHA
深入理解注意力机制
https://mp.weixin.qq.com/s/s8sKoTzqyf-_-N0TSLnPow
不用看数学公式!图解谷歌神经机器翻译核心部分:注意力机制
https://mp.weixin.qq.com/s/TM5poGwSGi5C9szO13GYxg
一文解读NLP中的注意力机制
https://zhuanlan.zhihu.com/p/59698165
NLP中的Attention机制
https://mp.weixin.qq.com/s/JVkhX_v2fCaICawk-P-fzw
通俗易懂:8大步骤图解注意力机制
https://juejin.im/post/5e57d69b6fb9a07c8a5a1aa2
啥是Attention?
https://mp.weixin.qq.com/s/PF02OwP0CHDf6l4BHHDqow
一文读懂Attention机制
Transformer
之前的文章已经介绍了Attention和《Attention is All You Need》。但实际上,《Attention is All You Need》不仅提出了两种Attention模块,而且还提出了如下图所示的Transformer模型。该模型主要用于NMT领域,由于Attention不依赖上一刻的数据,同时精度也不弱于LSTM,因此有很好并行计算特性,在工业界得到了广泛应用。阿里巴巴和搜狗目前的NMT方案都是基于Transformer模型的。
代码:
https://github.com/Kyubyong/transformer
![]()
Transformer的讲解首推:
http://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
http://jalammar.github.io/illustrated-transformer/
The Illustrated Transformer
这里仅对要点做一个总结:
1.Transformer是一个标准的Seq2seq结构,有encoder和decoder两部分。
2.encoder可以并行执行,一次性算完。而decoder的输入不仅包含encoder的输出,还包含了decoder上次的输出,因此还是一个循环结构,并不能完全并行。
3.为了解决循环结构的次序问题,论文提出了上图所示的Masked Multi-Head Attention。
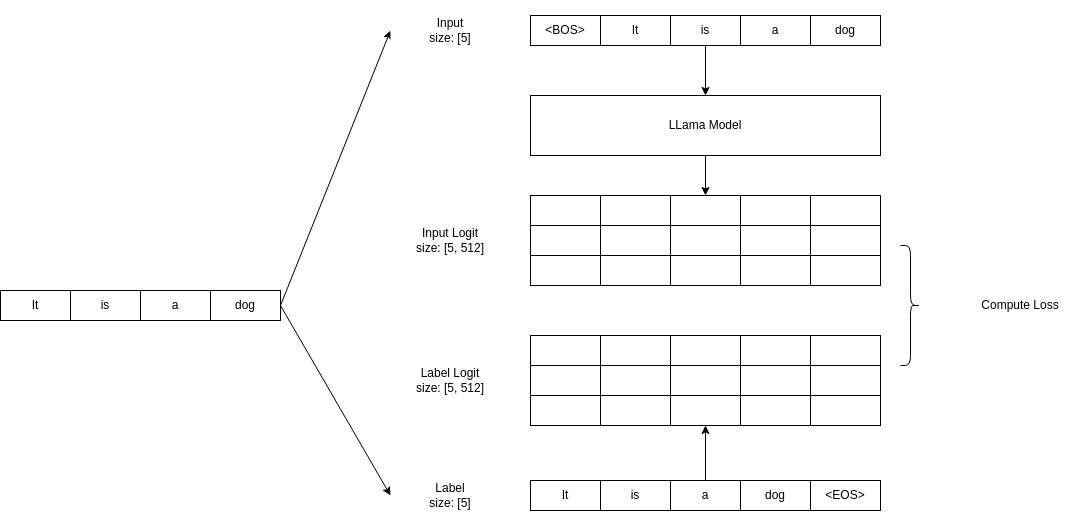
以预测下一个词的生成任务为例,训练时使用Mask,遮挡住训练文本中当前位置及之后的值,让Transformer输出各token的概率,并计算和训练文本之间的loss。
简单说就是:训练时只有encoder,使用Mask实现遮挡。由于encoder可以并行执行,所以Transformer的训练效率,远高于RNN。
4.Transformer最后的linear+softmax,也被称为lm heads。
从上图可以看出,prefill阶段只有最后一个位置的hidden,会做为lm heads的输入。这和encoder训练时,\(t_n\)预测\(t_{n+1}\)是一致的。
![]()
FFN
上图中的Feed Forward的公式为:
\[\text{FFN}(x) = \max(0,xW_1 + b_1)W_2 + b_2\]这实际上就是:
\[\text{FFN}(x) = \text{ReLU}(xW_1)W_2\]这里的ReLU也可以换成其他的激活函数。
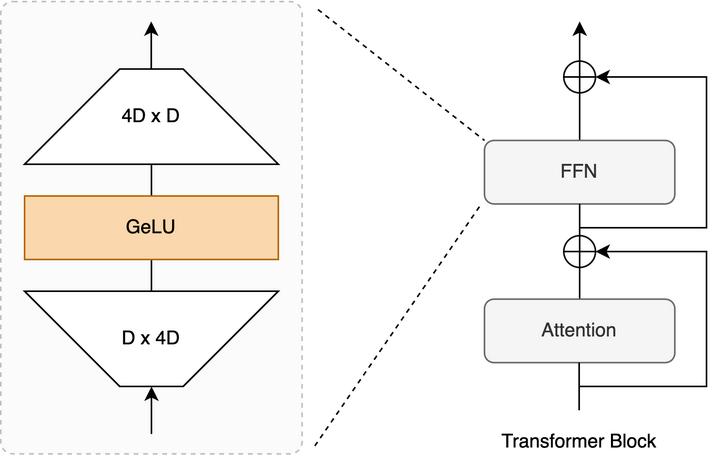
它本质上是一个升维又降维的过程。
这是LLAMA时代的FFN结构图:
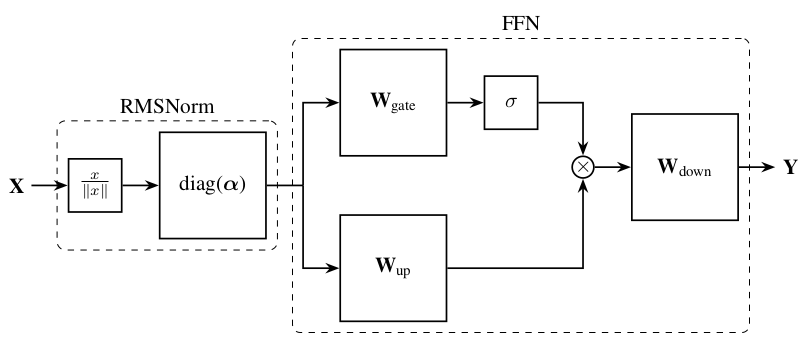
在这里,Batch Norm被换成了速度更快的RMS Norm,ReLU被换成了GLU或者它的变种。GLU参见这里。
attention是线性运算的还是非线性运算的?
全局来看,对于x来说是非线性运算。因为仔细看一下Attention的计算公式,其中确实有一个针对q和k的softmax的非线性运算。
但是对于value来说,并没有任何的非线性变换。所以每一次Attention的计算相当于是对value代表的向量进行了加权平均,虽然权重是非线性的权重。
这就是FFN必须要存在的原因,或者说更本质的原因是因为FFN提供了最简单的非线性变换。
参考:
https://zhuanlan.zhihu.com/p/685943779
聊一聊Transformer中的FFN
https://www.zhihu.com/question/646160485
为什么transformer里面的自注意力总是被魔改,但里面的FFN却始终不变?
https://www.zhihu.com/question/622085869
如何理解Transformers中FFNs的作用?
Reformer
https://mp.weixin.qq.com/s/9P-hF9VzDMgoPZ_CGREn8w
Reformer:一个高效的Transformer
https://mp.weixin.qq.com/s/-45YL1mzPmSOESfWlxUclA
图解Reformer:一种高效的Transformer
https://mp.weixin.qq.com/s/wJbbki3S8l10rSpFTWFpgg
对Reformer的深入解读
https://mp.weixin.qq.com/s/xBkK77lxKotfyfyXY_DK-g
Transformer家族系列(一):Reformer论文解读
https://mp.weixin.qq.com/s/szqvMyGoNgz0OFx3nzeV9g
Transformer家族系列(二):CNN在Transformer中的应用
参考
https://zhuanlan.zhihu.com/p/39034683
Attention is all you need模型笔记
https://zhuanlan.zhihu.com/p/40920384
真正的完全图解Seq2Seq Attention模型
https://mp.weixin.qq.com/s/RLxWevVWHXgX-UcoxDS70w
细讲《Attention Is All You Need》
https://mp.weixin.qq.com/s/1wReNLTtpKySPwi5u1iXMA
All Attention You Need
https://mp.weixin.qq.com/s/lUqpCae3TPkZlgT7gUatpg
Self-Attention与Transformer
https://mp.weixin.qq.com/s/O8_oOCtCCcU-kVklgxRoBg
Transformers Assemble(PART I)
https://mp.weixin.qq.com/s/zmChXVkF0pUiKrahx00EzQ
Transformers Assemble(PART II)
https://mp.weixin.qq.com/s/uPBLzJ-WidH4WBDiPt5NqA
Transformers Assemble(PART III)
https://mp.weixin.qq.com/s/8pNZVe66LmQ-G3gqs6tOxw
Transformers Assemble(PART IV)
https://mp.weixin.qq.com/s/i7oCZKb84w2jzuINAWWtiA
Transformers Assemble(PART V)
https://mp.weixin.qq.com/s/S_xhaDrOaPe38ZvDLWl4dg
从技术到产品,搜狗为我们解读了神经机器翻译的现状
https://mp.weixin.qq.com/s/vzjKU_0qhapWKOYZ4Rnj-Q
谷歌的机器翻译模型Transformer,现在可以用来做任何事了
https://mp.weixin.qq.com/s/lgGDTCF3qg84njv2IeHC9A
大规模集成Transformer模型,阿里达摩院如何打造WMT 2018机器翻译获胜系统
https://mp.weixin.qq.com/s/_UC2jlOfb34tfB_tsEXjMg
谷歌全新神经网络架构Transformer:基于自注意力机制,擅长自然语言理解
https://mp.weixin.qq.com/s/w3IKoygTLDsAxk1MB5JrGg
详细讲解Transformer新型神经网络在机器翻译中的应用
https://mp.weixin.qq.com/s/HzzDG8PpDlyilQjr2PH6PA
Transformer注解及PyTorch实现(上)
https://mp.weixin.qq.com/s/YDaSv5oHLEtyJrp4Y5e64A
Transformer注解及PyTorch实现(下)
https://mp.weixin.qq.com/s/BIwUYRq0yP9nE80OOlMWaQ
关于Transformer那些的你不知道的事
https://mp.weixin.qq.com/s/j0KRAOf8Sd0_tTlRadnw9Q
利用篇章信息提升机器翻译质量
https://mp.weixin.qq.com/s/s_s-MtrEwRNyllV_9qpAQA
放弃幻想,全面拥抱Transformer:NLP三大特征抽取器(CNN/RNN/TF)比较
https://mp.weixin.qq.com/s/NtWMcwUGg591meuGubWY1g
CMU和谷歌联手放出XL号Transformer!提速1800倍
https://mp.weixin.qq.com/s/_MI-OQUHVbyZ3Utd52rWMw
Facebook推出最新跨语言预训练模型,刷新多项跨语言任务记录
https://mp.weixin.qq.com/s/C0p1U0-x6aRipvYJItn8-g
Transformer在进化!谷歌大脑用架构搜索方法找到Evolved Transformer
https://mp.weixin.qq.com/s/cs4IjkmdPmu2-3Mu36f8UQ
OpenAI提出Sparse Transformer,文本、图像、声音都能预测,序列长度提高30倍
https://mp.weixin.qq.com/s/cpbIHt-rBu48uGifg_lPfg
Gaussian Transformer:一种自然语言推理的轻量方法
https://mp.weixin.qq.com/s/1y8jTqCcI7HkMA3qXtqdIg
阿里首次将Transformer用于淘宝电商推荐!效果超越深度兴趣网络DIN和谷歌WDL
https://mp.weixin.qq.com/s/E6E6tc2uDJofuNDJArB5RQ
邵晨泽:非自回归机器翻译
https://mp.weixin.qq.com/s/ZfvShgevhjhe39PmF-ONnA
周龙:同步双向文本生成
https://mp.weixin.qq.com/s/O7B-pQveMefaCuMswT7H-A
跨8千个字学习知识,上下文要多长还是交给Transformer自己决定吧
https://mp.weixin.qq.com/s/VG5WHwuO6DKRzcm0pddeMQ
参数少一半,效果还更好,天津大学和微软提出Transformer压缩模型
https://mp.weixin.qq.com/s/9aW1p03f6mEnvSRf56rcgw
Transformer-XL模型浅析
https://mp.weixin.qq.com/s/Xxk6n6r0lSuybjKlwzLAnw
TransformerXL:因为XL,所以更牛
https://mp.weixin.qq.com/s/o__YU5vlfKi4HGytlug3og
从头开始了解Transformer
https://mp.weixin.qq.com/s/DuRpnJRqvZ8Jfc7jutpIXw
Transformer研究指南
https://mp.weixin.qq.com/s/ehhsN0Xj1aUVyAxSxnFJmQ
Transformer落地:使用话语重写器改进多轮人机对话
https://zhuanlan.zhihu.com/p/85825460
Transformer在推荐模型中的应用总结
https://mp.weixin.qq.com/s/io87CCfThDZDwpIHngunqQ
Step-by-step to Transformer:深入解析工作原理(以Pytorch机器翻译为例)
https://mp.weixin.qq.com/s/9Sgln-bfP2DdB_o1RAgiGg
Transformer在深度推荐系统中的应用
https://mp.weixin.qq.com/s/61ZeO46s19sCW-3xQ_FUJg
如何在NLP中有效利用Deep Transformer?
https://www.zhihu.com/question/302392659
有了Transformer框架后是不是RNN完全可以废弃了?
https://mp.weixin.qq.com/s/_gTNZKCfhoazYR09hmu5lQ
时间自适应卷积:比自注意力更快的特征提取器
https://mp.weixin.qq.com/s/Oixc46P9rQeiMDjI-0j0cw
Transformer在美团搜索排序中的实践
https://mp.weixin.qq.com/s/S_RELwKsqInvacTxdwJBPg
浅谈Transformer模型中的位置表示
https://mp.weixin.qq.com/s/_lEOcyAovKMJYxBYsQIWUQ
万字长文带你一览ICLR2020最新Transformers进展(上)
https://mp.weixin.qq.com/s/4KCcFHBEYJ3nWaHplqVRNA
万字长文带你一览ICLR2020最新Transformers进展(下)
https://mp.weixin.qq.com/s/8tVste5Wuwy4o4jh-jx5hA
Transformer温故知新
https://zhuanlan.zhihu.com/p/143852458
NLP中更好&更快的Transformer
https://mp.weixin.qq.com/s/JpBds6NQIBZ0S8GsMo4LEA
这六大方法,如何让Transformer轻松应对高难度长文本序列?
https://mp.weixin.qq.com/s/R5jqk1ow_3cKLzM1XlDbUg
告别自注意力,谷歌为Transformer打造新内核Synthesizer

您的打赏,是对我的鼓励
