DL acceleration » 并行 & 框架 & 优化(九)——LLM System
2025-07-17 :: 4875 WordsLLM Inference(续)
https://www.zhihu.com/tardis/zm/art/647813179
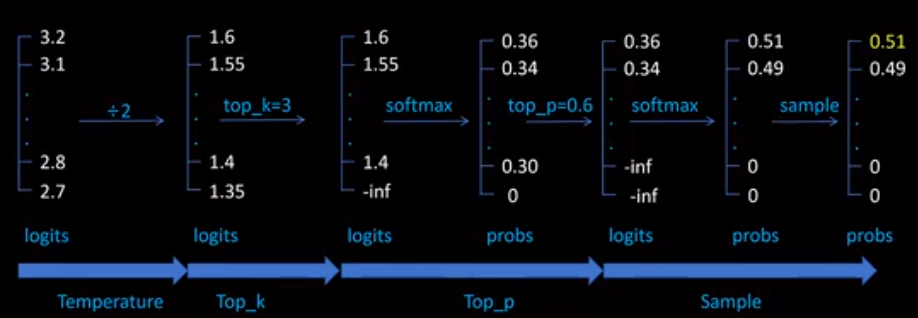
大模型文本生成——解码策略(Top-k & Top-p & Temperature)
https://b23.tv/OfdfBnz
如何设置大模型推理参数,top_k,top_p, temperature, num_beams
https://blog.csdn.net/HUSTHY/article/details/125990877
Contrastive Search Decoding——一种对比搜索解码文本生成算法
https://zhuanlan.zhihu.com/p/656707466
DoLa:层对比解码改善LLM的真实性
Speculative Decoding:先用一个轻量级“提议器”快速生成K个候选token,再用主模型并行打分,能少跑很多步主模型。
《Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads》提出:
不额外训练完整草稿模型,而是在原模型最后一层隐藏状态上挂3-5个轻量级前馈头(Medusa Heads),每个头负责预测第2,3,…,K+1位置的token。这些头与原模型共享KV缓存,因此几乎不占额外显存。
EagleProposer复用主模型的Embedding与LMHead,只额外训练一个轻量的Auto-regression Head,接受率显著高于Medusa/普通小草稿模型。
MTP vs Speculative Decoding:后者是推理时的加速技巧,MTP是训练时的目标改进;但MTP训练出的辅助头可被用于投机解码。
投机解码在密集模型上几乎是免费午餐,但碰上MoE模型就变得别扭。验证一批投机token的时候,每个token可能激活不同的专家子集,反而削弱了MoE本来靠批处理省下来的那点优势。
https://zhuanlan.zhihu.com/p/651359908
大模型推理妙招—投机采样(Speculative Decoding)
LLM Inference的性能评估主要有以下几个方面:
- Time To First Token (TTFT)
- Time Per Output Token (TPOT):解码阶段总耗时 / 生成token数
- Latency:模型为用户生成完整响应所需的总时间。latency = (TTFT) + (TPOT) * (the number of tokens to be generated)
- Throughput:一个推理服务器每秒可以为所有用户和请求生成的输出token数量。
- TBT(Time Between Tokens):第i+1个token时间戳 − 第i个token时间戳。流式/对话场景(逐token吐字)更关心TBT。
https://www.databricks.com/blog/llm-inference-performance-engineering-best-practices
LLM Inference Performance Engineering: Best Practices
PD分离
一次用户请求,实际上既包含prefill,也包含decode。一个是计算密集型,一个是访存密集型。
prefill(用户输入)和decode(模型输出)的token量在不同场景下也是不一样的。如果是简单对话场景,通常模型的decode输出会更多一些,而如果是超长上下文场景,用户先上传一本几十万字的书再进行问答,这本书的prefill会直接起飞。在Agent场景下,大量预设的prompt也会占据非常多的prefill,不过prompt的prefill有不少机会可以提前算好KV而无需每个用户请求单独重复计算。
当整个推理系统服务几千万用户时,一个batch的几十个用户请求只是开胃菜。每个用户会不间断地和大模型进行交互,发出大量请求,但这些请求的间隔时间短则几秒,长则几分钟几小时。考虑人机交互的频率,一个用户请求结束后,对应的KV-cache继续常驻在高速内存中实际意义不大。
这个从今年年中开始,各家都陆续上了PD分离方案(如MoonCake)。
Prefilling阶段是计算密集型,少量Query就可以打满GPU,大量Query反而会增加首token延迟;Decoding阶段是访存密集型,必须依赖大量Query提高GPU计算利用率。因此可以通过多台机器处理Prefilling、单台机器处理Decoding的PD分离方案,实现综合效率最大化、首token延迟(TTFT)最低、DecodeSpeed(TPS)最高。

Rubin CPX,是专门为推理阶段prefill准备的低成本卡。prefill阶段所需带宽较小,配置“瘦带宽”而“肥容量”的GDDR7,显然更为合适。与此同时,英伟达与Groq达成了200亿美元战略授权协议。“Groq 风味”的硅——英伟达正在将其整合进自身推理路线图——将承担高速decode引擎的角色。
https://www.zhihu.com/question/1949040585416636414
如何看待英伟达最新发布的Rubin CPX及相应的上下文理解/生成分离设计?
训练分三个环节,每个环节的瓶颈不一样:
- Forward(前向传播):计算形态上确实和Prefill很像,大矩阵乘,compute-bound。
- Backward(反向传播):需要读取Forward阶段保存的activation,计算量是Forward的两倍,访存量也更大。
- Optimizer update(优化器更新):逐参数的逐元素操作,读写权重、梯度、一阶动量、二阶动量。这一步完全是访存密集的。
再加一个很多人忽略的:分布式通信。训练要做AllReduce、ReduceScatter、All-to-All,这些都吃互联带宽,和Prefill、Decode都不是一回事。
大规模强化学习的pipeline里,Prefill和Decode是混布的,模型要生成、评估、更新、再生成,工作负载在推理和训练之间反复切换。如果硬件被物理分成Prefill池和Decode池,KV Cache和hidden state在两个池之间来回迁移,延迟和抖动都会上来。
所以training是不做PD分离的。同样的理由,AF分离在training中也是无意义的。
至于Expert分离,业界一般将MoE层”分片”(Sharded)到不同设备上,而Attention层则”复制”(Replicated)到所有设备。
此外,训练阶段也不需要KV Cache。
训练是强同步、周期性、批处理的执行流,核心瓶颈在梯度同步的通信开销和流水线气泡;
推理是异步、随机到达、延迟敏感的执行流,核心瓶颈在尾延迟、KV Cache管理和动态调度;
后训练尤其是强化学习后训练,则把生成、奖励、更新三条异构链路耦合在一起,系统压力更多表现为长尾轨迹、样本陈旧度和多资源池协同。
https://www.zhihu.com/question/2029953946404541284
为什么英伟达认为Training≈Prefill华为却把Training和Decode放一起,谁错了?
AF分离
Expert权重是存储巨无霸(数百GB到TB级),但每次只激活1-5%,Attention的KV Cache是带宽巨无霸,但参数量很小。把两者绑在同一台机器上,存储和带宽互相拖累。
AF分离架构将Attention层和Expert层物理拆分,部署在不同的GPU集群上。Attention Cluster专注于维护KV Cache和计算Attention,Expert Cluster则专注于存储专家权重和计算FFN。
AF分离引入了高频的跨节点通信,每一层的Attention输出都需要发送给Expert集群,Expert计算完后再发回。这种通信模式是M-to-N的,且数据包极小、频率极高。最大的问题变成了,每一层都要在 Attention机器和Expert机器之间来回倒腾Token。
代表性的工作比如Janus, 设计了Adaptive Two-Phase Communication,先在Attention节点内部,利用超高带宽的NVLink,把发往同一个Expert机器的Token聚合起来,打成一个大包。再通过InfiniBand网络,把大包发给Expert节点。Attention和Expert分离了,调度器就可以在Expert集群中动态选择负载最低的Expert Replica来处理请求,实现了微秒级的负载均衡。
vLLM
https://docs.vllm.ai/en/latest/
Easy, fast, and cheap LLM serving for everyone
Piecewise CUDA Graph是vLLM中用于解决传统CUDA Graph在动态场景下局限性的一种优化策略。
标准CUDA Graph要求输入tensor的shape、地址、类型完全固定,否则会报错。
在LLM推理中,batch size、seq len、KV cache布局经常变化,导致整张图无法复用。
因此,vLLM将模型按“稳定区域”切成多个片段,每个片段内部仍满足CUDA Graph的静态要求。
LLM System
RAG
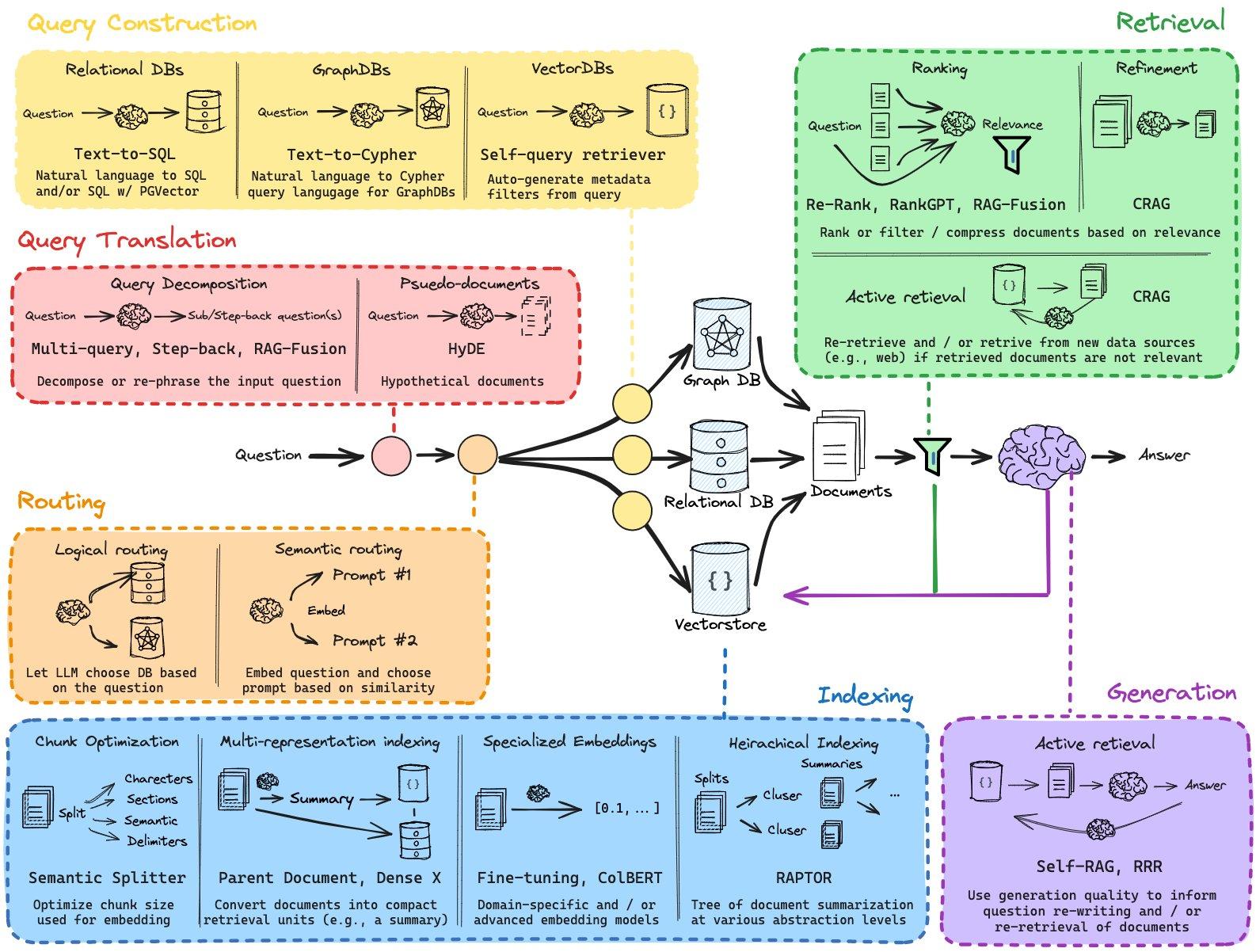
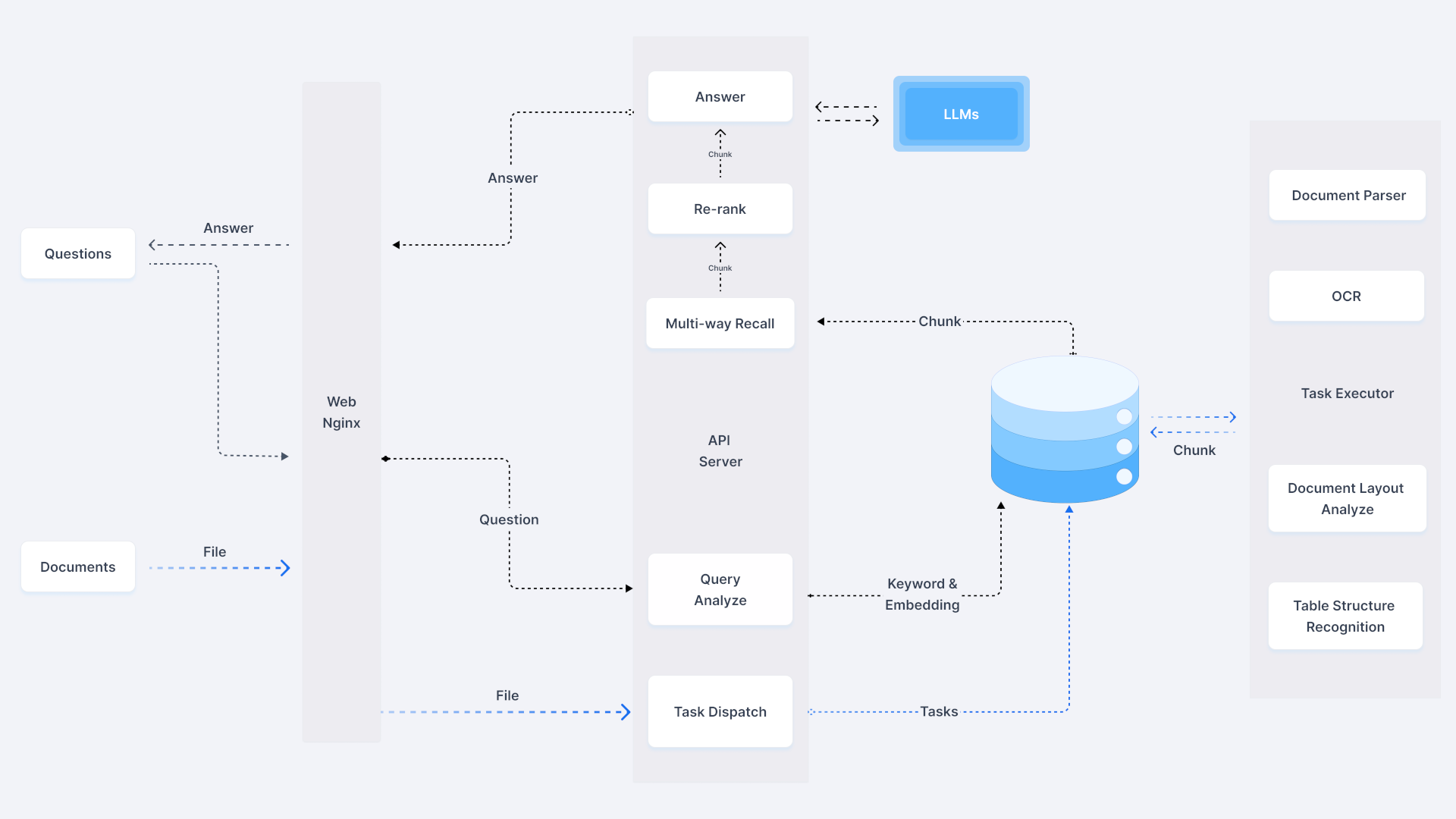
Retrieval Augmented Generation(检索增强生成):通过检索获取相关的知识并将其融入Prompt,让大模型能够参考相应的知识从而给出合理回答。因此,可以将RAG的核心理解为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案。
https://zhuanlan.zhihu.com/p/668082024
一文搞懂大模型RAG应用
https://blog.csdn.net/v_JULY_v/article/details/137711599
RAG进阶之通用文档处理:从RAGFlow、TextMonkey到mPLUG-DocOwl 1.5
https://zhuanlan.zhihu.com/p/695299235
RAG路线图: Reliable, Adaptable, and Attributable Language Models with Retrieval
Pooling models是一类把可变长度序列“压缩”成固定长度向量的模型,也常被称为sentence embedding模型。
它们的核心动作就是pooling:先把输入文本用Transformer编码成一系列token向量,然后对这些向量做一次pool操作,得到一个整体表征(embedding),用来做下游的检索、聚类、分类、重排等任务,是RAG、向量数据库、语义搜索的基石。
假设有一个10w的外部数据,我们的原始输入Prompt长度为100,长度限制为4k,通过查询-检索的方式,我们能将最有效的信息提取集中在这4k的长度中,与Prompt一起送给大模型,从而让大模型得到更多的信息。此外,还能通过多轮对话的方式不断提纯外部数据,达到在有限的输入长度限制下,传达更多的信息给大模型。
https://blog.csdn.net/qq_40491305/article/details/130898052
一文看懂LlamaIndex用法,为LLMs学习私有知识

您的打赏,是对我的鼓励
