Attention » Attention(九)——Attention进阶, Transformer进阶
2024-10-09 :: 6997 WordsBERT进阶(续)
https://mp.weixin.qq.com/s/cyNcVNImoCOmTrsS0QVq4w
用Siamese和Dual BERT来做多源文本分类
https://mp.weixin.qq.com/s/uv74FKtUNtgjIBQZbsX7Qw
你finetune BERT的姿势可能不对哦?
https://mp.weixin.qq.com/s/BvM5zx-3XrsZj8BQ5WEa4A
一文带你了解MultiBERT
https://mp.weixin.qq.com/s/mFRhp9pJRa9yHwqc98FMbg
BERT在美团搜索核心排序的探索和实践
https://mp.weixin.qq.com/s/MPGF3tkNn3PBA_7S-fo9eg
谷歌新模型突破BERT局限:NLP版“芝麻街”新成员Big Bird长这样
https://zhuanlan.zhihu.com/p/165893466
BERT及其变种
https://mp.weixin.qq.com/s/5HZULHPI3-HJypvAMXEOcQ
MT-BERT在文本检索任务中的实践
https://mp.weixin.qq.com/s/0aZdGzcGW5ZA020rhX0qSQ
BERT4Rec:使用Bert进行序列推荐
https://mp.weixin.qq.com/s/fr-THgOeaTspKsv_hXnU2Q
CogLTX:将BERT应用于长文本
https://www.cnblogs.com/zhouxiaosong/p/11397655.html
使用BERT模型生成token级向量
https://mp.weixin.qq.com/s/JLP4-5IR6HPK4SRQoC9FAQ
BERT预训练实操总结
https://mp.weixin.qq.com/s/FuO8zY3XoIF-s6_8aXAusw
BERT相关模型汇总梳理
https://zhuanlan.zhihu.com/p/348373259
史上最细节的自然语言处理NLP/Transformer/BERT/Attention面试问题与答案
https://mp.weixin.qq.com/s/vFdm-UHns7Nhbmdoiu6jWg
谷歌终于开源BERT代码:3亿参数量,机器之心全面解读
https://zhuanlan.zhihu.com/p/58425003
从Word2Vec到Bert,聊聊词向量的前世今生(一)
https://mp.weixin.qq.com/s/SfMIKfF_B4agFCHN_U_mzQ
BAM!利用知识蒸馏和多任务学习构建的通用语言模型
https://mp.weixin.qq.com/s/6G5Mu7-1omGtQ_9Gt9lUBw
基于预训练自然语言生成的文本摘要方法
https://mp.weixin.qq.com/s/yysnPauB22YgprpOi1ZWSQ
深入理解BERT Transformer,不仅仅是注意力机制
https://mp.weixin.qq.com/s/kFABJJ3fBC48-4DXK8PERQ
10大任务超越BERT,微软提出多任务深度神经网络MT-DNN
https://mp.weixin.qq.com/s/jlGfxkT_o9sgFlUuR_x5Tw
微软开源用于学习通用语言嵌入的MT-DNN模型
https://mp.weixin.qq.com/s/D68YzjYvpc2epGWFBP6rIQ
谷歌实习生新算法提速惊人!BERT训练从三天三夜,缩短到一个小时
https://mp.weixin.qq.com/s/iDGofh_ycWJzfqQriPEXGQ
如何用Python和BERT做中文文本二元分类?
https://zhuanlan.zhihu.com/p/91052495
当BERT遇上知识图谱
https://mp.weixin.qq.com/s/wQW-JT-sGMj60OtXwTssyQ
BERT模型推理加速总结
Attention进阶
Sliding Window Attention
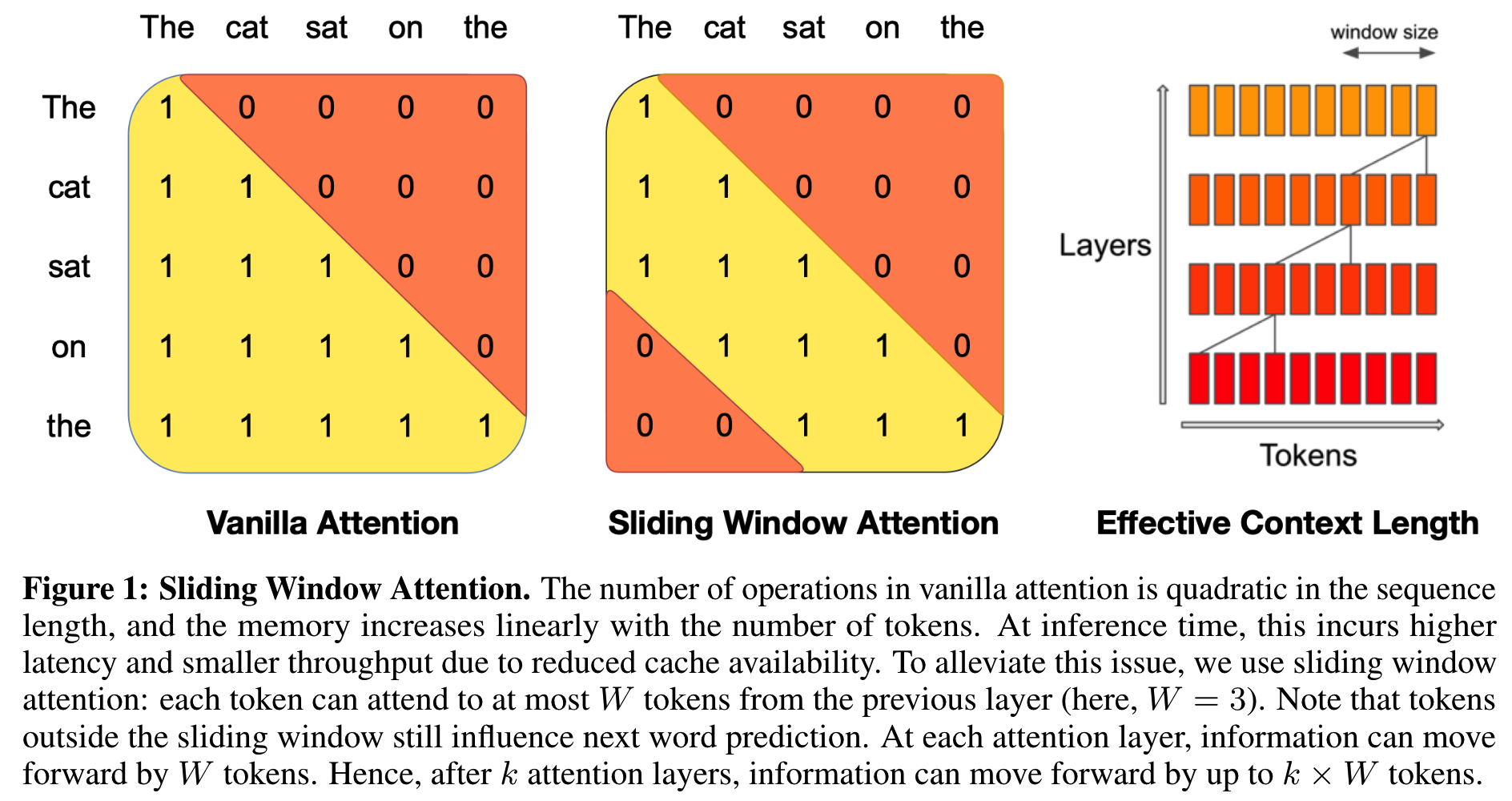
上图是SWA和普通Attention使用的Mask的区别。SWA能显著提高训练和推理的速度,同时性能掉的也不多。

https://zhuanlan.zhihu.com/p/687349083
稀疏注意力计算:Sliding Window Attention
参考
https://mp.weixin.qq.com/s/wrmjMLPuvpLIcF5VQBqZxg
最新“注意力机制Attention”大综述论文,66页pdf
https://mp.weixin.qq.com/s/rrbwItXt-1EaGiqtDEGvog
为节约而生:从标准Attention到稀疏Attention
https://mp.weixin.qq.com/s/MzHmvbwxFCaFjmMkjfjeSg
遍地开花的Attention,你真的懂吗?
https://mp.weixin.qq.com/s/e_LEhLf2Rh-1zkEBmqS4nA
NLP这两年:15个预训练模型对比分析与剖析
https://mp.weixin.qq.com/s/LAInpFPa-3R1rfv6idILnw
注意力机制发展如何了,如何学习它在各类任务中的应用?
https://zhuanlan.zhihu.com/p/40920384
真正的完全图解Seq2Seq Attention模型
https://mp.weixin.qq.com/s/ZSzHOu6uowRSoWrqB7vOaQ
深度学习注意力机制-Attention in Deep learning-附101页PPT
https://mp.weixin.qq.com/s/FlA1YrR0sLQGJoJZnSXpRw
DeepMind:深度学习注意力与记忆机制,附70页ppt
https://mp.weixin.qq.com/s/_mBa-GTdILrvluJtegz8fw
南洋理工大学:注意力神经网络,Attention Neural Networks,78页ppt
https://mp.weixin.qq.com/s/pKxqPB9qIGmE_PslPa6EyA
长文详解Attention的前世今生
https://mp.weixin.qq.com/s/2kFZAmb_WnTNYUXT_jVMqg
Attention注意力机制的前世今生
https://mp.weixin.qq.com/s/eq1iTyKguQm5t6Xoc7KUgw
一文搞懂NLP中的Attention机制
https://zhuanlan.zhihu.com/p/106662375
More About Attention
https://mp.weixin.qq.com/s/MFxQSUMFNRXjdLQwzveO4w
深度学习中的注意力机制
https://mp.weixin.qq.com/s/vkyPwsaxH-SvHqQx09VhVw
深度学习中的注意力机制(二)
https://mp.weixin.qq.com/s/fbAAA7fO2voP_v-NsavQew
深度学习中的注意力机制(三)
https://mp.weixin.qq.com/s/CftkSOmAx0UTtCixdxj6_A
深度学习中的注意力机制(完结篇)
https://mp.weixin.qq.com/s/Qs6tm50YvzHaJv2rh60WMw
撩一发深度文本分类之RNN via Attention
https://mp.weixin.qq.com/s/MMIZGHTKM5FrvNE6ucQRYQ
33页最新《自然语言处理中神经注意力机制综述》论文
https://mp.weixin.qq.com/s/Q0Ft5bWTuiZUIQSTk7X6ZQ
图解神经机器翻译中的注意力机制
https://mp.weixin.qq.com/s/D7GQ8DRzss9ppP6pyAs1qA
从0到1再读注意力机制
https://mp.weixin.qq.com/s/K_VRt0B9-Xw7YJndmb4WZg
Attention!注意力机制模型最新综述
https://mp.weixin.qq.com/s/hzwp5oGspdtDyNBmq8sMsw
HAN:基于双层注意力机制的异质图深度神经网络
https://mp.weixin.qq.com/s/SBrLPZjx2RdBwZpPQQ5DXQ
HAN:异构图注意力网络
https://mp.weixin.qq.com/s/0EDN-ILeL_diZ1G11ikwjw
T5模型:NLP Text-to-Text预训练模型超大规模探索
https://zhuanlan.zhihu.com/p/89719631
T5: Text-to-Text Transfer Transformer阅读笔记
https://mp.weixin.qq.com/s/X1mLXPzJU7k_ANMzvVPxjA
BERT、RoBERTa、DistilBERT与XLNet,我们到底该如何选择?
https://mp.weixin.qq.com/s/GGRORF5EfJ5xzMLwAsJt5w
从词袋到Transfomer,NLP十年突破史
https://zhuanlan.zhihu.com/p/125145283
Rethink深度学习中的Attention机制
https://mp.weixin.qq.com/s/fxEg8UOa3MeJ6qx5SjEHog
NLP领域中各式各样Attention知识系统性的梳理和总结
https://mp.weixin.qq.com/s/_5YaZdYa8bTFiAzHyrMFBg
理解卷积神经网络中的自注意力机制
https://mp.weixin.qq.com/s/y_hIhdJ1EN7D3p2PVaoZwA
阿里北大提出新attention建模框架,一个模型预测多种行为
https://mp.weixin.qq.com/s/Yq3S4WrsQRQC06GvRgGjTQ
打入神经网络思维内部
https://mp.weixin.qq.com/s/MJ1578NdTKbjU-j3Uuo9Ww
基于文档级问答任务的新注意力模型
https://mp.weixin.qq.com/s/_3pA8FZwzegSpyz_cK63BQ
Self-Attention GAN中的self-attention机制
https://mp.weixin.qq.com/s/l4HN0_VzaiO-DwtNp9cLVA
循环注意力区域实现图像多标签分类
https://mp.weixin.qq.com/s/zhZLK4pgJzQXN49YkYnSjA
自适应注意力机制在Image Caption中的应用
https://mp.weixin.qq.com/s/uvr-G5-_lKpyfyn5g7ES0w
基于注意力机制,机器之心带你理解与训练神经机器翻译系统
https://mp.weixin.qq.com/s/ANpBFnsLXTIiW6WHzGrv2g
自注意力机制学习句子embedding
https://mp.weixin.qq.com/s/49fQX8yiOIwDyof3PD01rA
CMU&谷歌大脑提出新型问答模型QANet:仅使用卷积和自注意力,性能大大优于RNN
https://mp.weixin.qq.com/s/c64XucML13OwI26_UE9xDQ
滴滴披露语音识别新进展:基于Attention显著提升中文识别率
https://mp.weixin.qq.com/s/7OYY3L7gL4wVv_EjoosOHA
如何增强Attention Model的推理能力
https://mp.weixin.qq.com/s/9Kt6_DfeYRnhsb10aCSFGw
FAGAN:完全注意力机制(Full Attention)GAN,Self-attention+GAN
https://mp.weixin.qq.com/s/lZOIK5BRXZrmL_Z9crl6sA
机器翻译新突破!“普适注意力”模型:概念简单参数少,性能大增
https://mp.weixin.qq.com/s/jRfOzKO6OlQLokIzipbqUQ
为什么使用自注意力机制?
https://zhuanlan.zhihu.com/p/339123850
关于attention机制的一些细节的思考
https://mp.weixin.qq.com/s/n4mzHSweOT-vDWBGs0XFbw
卷积神经网络中的自我注意
https://mp.weixin.qq.com/s/h7sLwVXb_UI8jvJU-oe3Cg
Google AI提出“透明注意力”机制,实现更深层NMT模型
https://mp.weixin.qq.com/s/1LYz5SH5rVnPPJ0tZvRQAA
从各种注意力机制窥探深度学习在NLP中的神威
https://zhuanlan.zhihu.com/p/33078323
数字串识别:基于位置的硬性注意力机制
https://mp.weixin.qq.com/s/-gAISWjSiG6ccPuOPAEg3A
五张动图,看清神经机器翻译里的Attention!
https://mp.weixin.qq.com/s/aixpv9t1PLPRWUP6PvZ0EQ
用自注意力增强卷积:这是新老两代神经网络的对话
https://mp.weixin.qq.com/s/i3Xd_IB7R0-QPztn-pgpng
遍地开花的Attention,你真的懂吗?
https://zhuanlan.zhihu.com/p/151640509
注意力机制在推荐系统中的应用
https://mp.weixin.qq.com/s/-SU5cNbklI31WLmTawZJIQ
自注意模型学不好?这个方法帮你解决!
https://mp.weixin.qq.com/s/K5EbO0djcXHN4K5LQiMh5g
Triplet Attention机制让Channel和Spatial交互更加丰富
https://mp.weixin.qq.com/s/C4f0N_bVWU9YPY34t-HAEA
UNC&Adobe提出模块化注意力模型MAttNet,解决指示表达的理解问题
https://mp.weixin.qq.com/s/V3brXuey7Gear0f_KAdq2A
基于注意力机制的交易上下文感知推荐,悉尼科技大学和电子科技大学最新工作
https://mp.weixin.qq.com/s/2gxp7A38epQWoy7wK8Nl6A
谷歌翻译最新突破,“关注机制”让机器读懂词与词的联系
https://zhuanlan.zhihu.com/p/25928551
用深度学习(CNN RNN Attention)解决大规模文本分类问题-综述和实践
Transformer进阶
https://mp.weixin.qq.com/s/MjCIAlDWyHPLj_sGSPc4rg
复旦邱锡鹏组最新综述:A Survey of Transformers
https://mp.weixin.qq.com/s/-Y7Qy-5aJNJ5bx8QJf3k2w
Transformer及其变种
https://mp.weixin.qq.com/s/nSokDcIkOSSrRnhHCuu4Mg
Transformer家族简史(PART I)
https://mp.weixin.qq.com/s/p919Kfv-1GSDM6u6FpnBsA
Transformer家族简史(PART II)
https://mp.weixin.qq.com/s/M0zLw9hA5xzontKB7Zj23Q
Memory Transformer,一种简单明了的Transformer改造方案
https://mp.weixin.qq.com/s/FJeZ8X9gtyciqCTs9zvlLA
Transformer是CNN是GNN是RNN,Attention is all you need!
https://mp.weixin.qq.com/s/d1qqRw7sWyLdoyfnqMBdJQ
深度自适应Transformer
https://mp.weixin.qq.com/s/UowNtBm_hqnes-Lz3POXGQ
Transformers中的Beam Search高效实现
https://mp.weixin.qq.com/s/KdKbOrjeeo7Db095V7mSFA
Transformer之自适应宽度注意力

您的打赏,是对我的鼓励
