Attention » Large Language Model(三)——LLAMA, Chinchilla Law
2024-03-23 :: 5178 WordsLLM大乱战(续)
最早的盘古应该是原语音语义实验室蒋欣老师和首席科学家刘群老师等带团队开发的,好像是mindspore太烂了,没训好。
后来唐睿明(原推荐搜索实验室主任)为了升职接姚老师,就去抢了蒋老师的位置,本来好像是应该尚立峰(现主任)来管。但是好像被唐打压了,一直不给机会参与大模型,甚至开会都不叫。唐不懂大模型,搞得更烂了,就那个底子上来就要训230b,据说ppt还有2.6T大模型。不过他跟上面关系好,还一直特别听话,只会逼著大家加班,每天晚上拉著汇报,工作日不准坐飞机。现在唐离职了,尚回来管,听那边的朋友说好了一些,但是还是天天攻关出方案训新的模型。
为了掩盖技术的无能,唐睿明选择了一种更原始、更残酷的方式:让团队成员通宵达旦地“人肉盯防”,一旦损失函数(loss)出现异常,立刻手动干预。就这样,靠着工程师的血肉之躯,硬是制造出了“0 loss震荡”的完美PPT,再次呈报给领导,作为其“技术领导力”的又一铁证。
当上大模型负责人后,唐睿明的野心进一步膨胀,将语音语义、决策推理等多个团队的成员尽数收入其“四纵”麾下,其实际负责人尚利峰等人被彻底架空,沦为有名无实的光杆司令。
王云鹤这人怎么说呢,年轻气盛,刚上来,领导支持就很强势,对大模型略懂,毕竟号称搞了什么小的大模型,内部都嘲笑这个属于华为专有名词。据说135b两波团队打得很凶,高压情况下,都看中了那块业务吧,套壳也是很有可能的,毕竟天天在心声上当演员。
王云鹤2018年博士毕业,经历不到7年时间,于2025年2月中旬,从原本的小模型实验室主任,正式顶替姚骏,被任命为诺亚方舟实验室主任(这一位置的前任包括大家耳熟能详的杨强、李航等,王云鹤可谓德不配位)。
王云鹤还主导引进了Fisher Yu这一劣迹斑斑、PUA女学生致死的所谓计算机科学家来诺亚当吉祥物。
华为在一次公开的大模型演示中,工作人员不小心按到了ctrl+c退出了python,当时程序刚好跑在time.sleep(6)这行代码下,直接报出错误,连带着time.sleep(6)这行代码一起返回来了。被人质疑是提前准备好了答案,time.sleep(6)用来混时间,假装模型在输出。
https://www.zhihu.com/question/1925157415541801408
如何看待“盘古之殇”一文爆料华为盘古大模型涉嫌“套壳、续训、洗水印”?
https://gitcode.com/ascend-tribe/ascend-cluster-infra/tree/main/HighAvailability
HW大规模集群技术报告
https://github.com/knemik97/Manifesto-against-the-Plagiarist-Yunhe-Wang
讨贼王云鹤檄文
当年华为自己没有靠谱的团队,外包给别人训练了盘古。
现在当年训练盘古的人出来做自己的模型,这个模型就是KIMI。
去查下循环智能就知道了,盘古算是华为委托他们做的,ChatGPT火了之后,杨植麟把循环智能的人拉出来成立的moonshot。
此前就一直传闻张予彤在月之暗面的融资过程中“帮了不少忙”,收了不少融资费用,更有甚者直接点破,说kimi就是一个夫妻店。
中国模型4小龙:deepseek,qwen,豆包,kimi。
“大模型六小虎”(月之暗面、百川智能、智谱AI、零一万物、MiniMax、阶跃星辰)
“杭州六小龙”,指的是“游戏科学、深度求索、宇树科技、云深处科技、强脑科技和群核科技”这六家近期崛起于杭州,处于技术前沿、深具行业影响力的科企。
https://www.zhihu.com/question/654072307
如何看待月之暗面创始人杨植麟减股套现千万美金?
https://zhuanlan.zhihu.com/p/19272031682
DeepSeek创始人梁文锋
姚顺雨/姚顺宇,都是清华毕业的,一个去了OpenAI,一个去了DeepMind。实际上都是“尧舜禹”的谐音。
https://www.zhihu.com/question/1984925319061267264
姚顺雨出任腾讯首席AI科学家,罗福莉担任小米大模型负责人,如何看待95后站上舞台中央的趋势?
参考:
https://www.zhihu.com/question/584132646
中国的大语言模型“悟道2.0”参数是GPT-3十倍,是否中国在大语言模型训练技术上已经远远超过美国?
https://zhuanlan.zhihu.com/p/463352552
稀疏性在机器学习中的发展趋势——Sparsity,稀疏激活,高效计算,MoE,稀疏注意力机制
https://zhuanlan.zhihu.com/p/254821426
乘风破浪的PTM:两年来预训练模型的技术进展(2020年之前的主流技术)
https://zhuanlan.zhihu.com/p/597586623
通向AGI之路:大型语言模型(LLM)技术精要
https://mp.weixin.qq.com/s/eV_9Mi2879w_gfoyiSm8Ug
LLM全景图(The Landscape of LLM)
https://www.zhihu.com/question/604592470
前两个月国产类ChatGPT大模型如雨后春笋,为何最近都没声音了?
https://mp.weixin.qq.com/s/oqhi58NcEVH1oVrW2p4xlQ
大模型参数高效微调技术原理综述(一)-背景、参数高效微调简介
https://mp.weixin.qq.com/s/fUAUr9X3XLndfjga2QIHbA
大模型参数高效微调技术原理综述(二)-BitFit、Prefix Tuning、Prompt Tuning
https://mp.weixin.qq.com/s/f4l04f78F507JRrCawnV8w
大模型参数高效微调技术原理综述(三)-P-Tuning、P-Tuning v2
https://mp.weixin.qq.com/s/nUAcCz6mcgGuUeuTfgqmOQ
大模型参数高效微调技术原理综述(四)-Adapter Tuning及其变体
https://mp.weixin.qq.com/s/N_N6RqKB9pjZ1tozfM5f5A
大模型参数高效微调技术原理综述(五)-LoRA、AdaLoRA、QLoRA
https://mp.weixin.qq.com/s/M2nds_FJBXooi08qDU-4yA
大模型参数高效微调技术原理综述(六)-MAM Adapter、UniPELT
https://mp.weixin.qq.com/s/P_AmTa4s8dOyc_0fZBgNPA
大模型参数高效微调技术原理综述(七)-最佳实践、总结
https://zhuanlan.zhihu.com/p/618695885
LLaMA, Alpaca, ColossalChat系列模型研究
https://zhuanlan.zhihu.com/p/638809556
大模型高效微调综述上:Adapter Tuning、AdaMix、PET、Prefix-Tuning、Prompt Tuning、P-tuning、P-tuning v2
https://zhuanlan.zhihu.com/p/651564985
主流大语言模型从预训练到微调的技术原理
LLAMA
![]()

代码:
https://github.com/facebookresearch/llama
有用的LLAMA模型:
https://huggingface.co/TheBloke/Llama-2-7B-Chat-GPTQ
https://huggingface.co/Trelis/Llama-2-7b-chat-hf-sharded-bf16
Inference:
https://clay-atlas.com/blog/2023/09/21/huggingface-transformers-streaming/
使用HuggingFace Transformer中的TextStreamer和TextIteratorStreamer來實現串流式(stream)輸出生成token
各类开源LLM打榜:
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
参考:
https://github.com/jacoblee93/fully-local-pdf-chatbot
一个本地版本的阅读PDF的chatbot
https://s-tm.cn/2023/06/10/SaveModelSharding/
使用HuggingFace transformers进行模型分片存储
https://www.zhihu.com/question/653373334
如何看待Meta发布Llama3,并将推出400B+版本?
https://mp.weixin.qq.com/s/VU_qUQEjqUNHd0UK6RLM9g
一文带你了解LLAMA(羊驼)系列
GEMMA
官网:
https://www.kaggle.com/models/google/gemma
Llama 3
llama 3是Meta于2024年发布的LLM。
论文:
《The Llama 3 Herd of Models》
本论文发布于2024.7,它实际上是Llama 3.1的技术报告。

https://blog.csdn.net/v_JULY_v/article/details/140659420
一文速览Llama 3.1——对其92页paper的全面细致解读:涵盖语言、视觉、语音的架构、原理
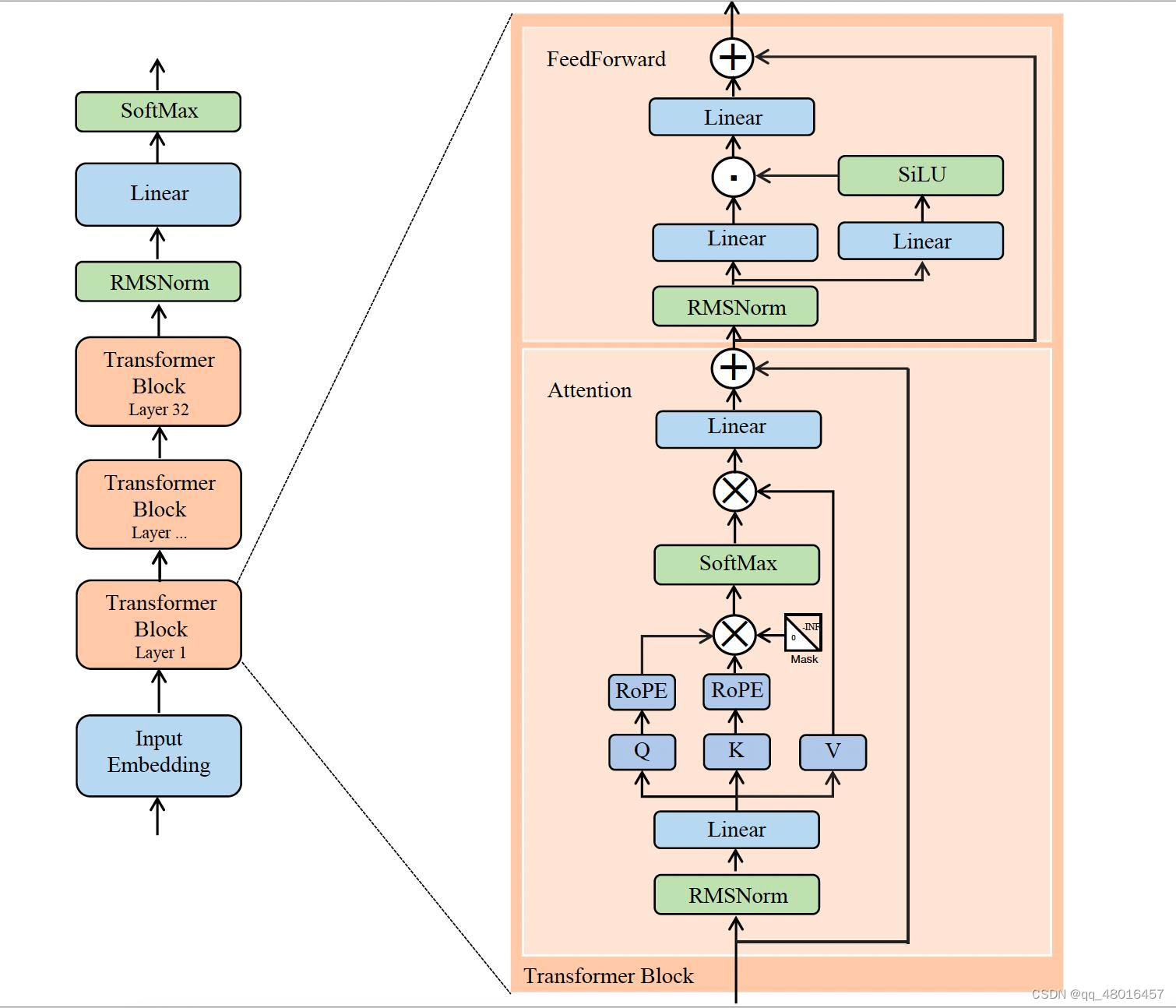
和原始的transformer只在第一个block之前进行位置编码不同,llama 3的每个block都会进行位置编码,这是为了在整个模型中持续保持对相对位置信息的感知能力。
ROPE移动到了QKV生成之后,且只对QK做ROPE。
苏神的blog讲述了为什么不对V做ROPE的原因:
https://kexue.fm/archives/10862
第二类旋转位置编码
GPT-J
GPT-J是一个由EleutherAI开发的自然语言处理(NLP)模型,基于GPT-3的架构,拥有6B个参数。它在800GB的开源文本数据集上进行训练,具有强大的语言生成和理解能力。
Chinchilla Law
最为知名的规模定律包括“Kaplan定律”和“Chinchilla定律”。
Kaplan定律指出,在固定计算量的前提下,扩大模型规模通常比增加数据量更为有效;
而Chinchilla定律则认为,模型规模和数据量同样重要。
DeepMind研究了在给定算力预算下训练Transformer语言模型的最佳模型大小和tokens数量。
在LLaMA-1预训练时候,从各种开源数据集,凑够了1.4T的tokens。按照Chinchilla Law,应该使用1,400B (1.4T) tokens来训练参数量大小为70B的LLM最佳。即:每个参数需要大约20个文本token。
https://zhuanlan.zhihu.com/p/627821763
训练LLM需要多少数据?
https://www.zhihu.com/question/628395521
如何看待微软论文声称ChatGPT是20B(200亿)参数量的模型?
6B模型可以在在12/16/24G显存的消费级显卡部署和训练。如果一个公司的模型不打算在消费级显卡部署,通常不会训6B这个规模。而且通常还会有一个1.4b或者2.8b,这个是比较适合在手机、车载端量化部署的尺寸。
13B模型按照4k长度组织数据,数据并行=2,刚好占满一个8卡机,并且可以量化部署在A10甚至4090。
下一档也不是130B,目前更大模型有16B、34B、52B、56B、65B、70B、100B、130B、170B、220B这几个规模,基本都是刚好占满某种规格的算力,要么是训练要么是推理。如果需要加快训练速度,只需要倍增卡数即可。比如我们训7B模型以8卡为单位,8x8卡训,70B模型以80卡为单位,80x6卡训。
https://www.zhihu.com/question/627258986
现在LLM的大小为什都设计成6/7B、13B和130B几个档次?

您的打赏,是对我的鼓励
