Attention » Large Language Model(一)——ChatGPT, GPT-4
2023-06-18 :: 4763 WordsChatGPT
官网:
https://chat.openai.com/chat
ChatGPT本身并没有论文,大部分是基于InstructGPT这篇论文:
https://openai.com/blog/instruction-following/
Aligning Language Models to Follow Instructions
基座预训练(Base pretrain)
SFT微调(Supervised Fine-Tuning):Fine-tuning是Post-train的子集。Post-train是一个更宽泛的概念,包含SFT、RLHF、DPO等多个阶段,而”微调”通常特指SFT这一步。
奖励函数训练(Reward Modeling, RM),最常用的是基于排序的奖励函数建模(Ranking-Based Reward Modeling,RBRM)
基于人类反馈的强化学习(RLHF,基于RM/RBRM进行PPO强化学习训练)
与人类对齐(Align AI with human values)
思维链 (Chain-of-thought,CoT) 是指令示范的一种特殊情况,它通过引发对话代理的逐步推理来生成输出。简单的说就是Let’s think step by step,指令示范不仅可以是QA对,也可以是一段连续的对话。
指令微调 (Instruction Fine-Tuning,IFT)

红蓝对抗 (red-teaming):红队测试在过去指用于测试安全漏洞的系统对抗攻击。随着LLM的兴起,该术语已经超越了传统的网络安全范围,并在日常使用中演变为描述AI系统的多种探测、测试和攻击。
https://zhuanlan.zhihu.com/p/602458131
解读ChatGPT背后的技术重点:RLHF、IFT、CoT、红蓝对抗
模型数据集可分为六类,分别是:维基百科、书籍、期刊、Reddit链接、Common Crawl和其他数据集。
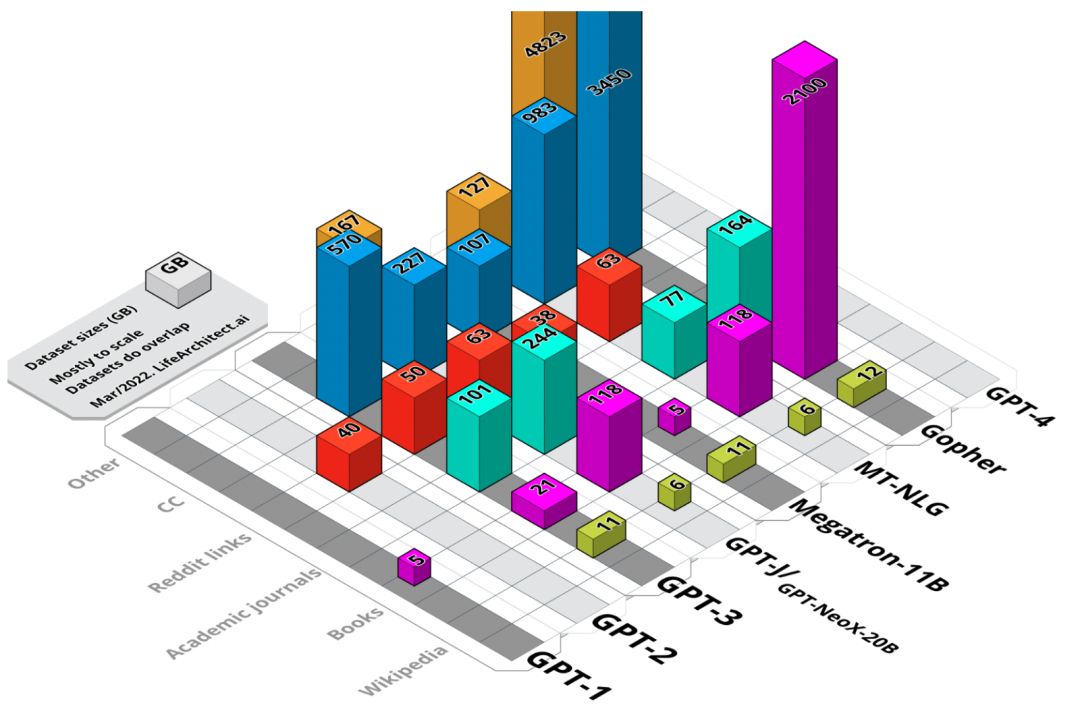
上图展示了各大模型所使用的数据来源。
数据语言: 主要是英语~46%, 俄, 德, 日与中文都是~5%左右。
除了文本之外,ChatGPT还利用了github的代码进行训练。有一些研究者认为ChatGPT展现出了初级推理能力,要归功于其使用代码作为语言数据训练,这些进化出的初级逻辑思维链,在中文上也有体现。
参考:
https://zhuanlan.zhihu.com/p/590655677
ChatGPT特点、原理、技术架构和产业未来
https://zhuanlan.zhihu.com/p/651780908
大模型中的人工反馈强化学习详解
https://mp.weixin.qq.com/s/L8E-dd9988Prbxau5awFtw
ChatGPT怎么突然变得这么强?华人博士万字长文深度拆解GPT-3.5能力起源
https://mp.weixin.qq.com/s/FPws8Gk18pW-TRcorlTczg
ChatGPT研究框架
https://www.zhihu.com/question/575481512
为什么chatgpt的上下文连续对话能力得到了大幅度提升?
https://www.zhihu.com/question/560134313
为什么强化学习里很少有预训练模型(Pretrained Model)?
https://www.zhihu.com/question/570431477
ChatGPT的训练集来自哪里?
https://www.zhihu.com/question/570189639
如何评价OpenAI的超级对话模型ChatGPT?
https://mp.weixin.qq.com/s/_ipboVExouPNtGhvKnJX_g
ChatGPT的技术体系总结
https://mp.weixin.qq.com/s/1fSxWdgfyAaFPBXMGhBV2Q
且看Chat GPT如何应对职场PUA
https://zhuanlan.zhihu.com/p/607847588
复现ChatGPT的难点与平替
https://zhuanlan.zhihu.com/p/601044938
nanoGPT源码阅读
https://zhuanlan.zhihu.com/p/608705255
GPT-3+RL全流程训练开源整理
https://zhuanlan.zhihu.com/p/609795142
ChatGPT原理详解+实操(1)—-SFT(GPT模型精调)
https://zhuanlan.zhihu.com/p/610147705
ChatGPT原理详解+实操(2)—-RM(reward model)
微软小冰
微软内部之前有个类似ChatGPT的项目,叫微软小冰,几个负责人都是那种技术栈和技术思路非常老旧的老人,在微软内部吸血吸了很多年,微软后来体面的裁掉了这个团队,转头去投了OpenAI 10亿美金。
这个被裁团队出来之后,一阵包装,说是微软为了他们更好的发展,所以让他们独立出来,然后去VC那融了好多钱。就在去年12月份,投资人纷纷对比了ChatGPT和小冰的智能化程度。对比效果简直辣眼睛,小冰那也叫智能?
小冰的技术原理,走的是传统NLP原理那一套,已经过时了,没有使用深度学习,基于知识图谱回答,学习的知识非常有限。
ChatGPT的出现打了两种人的脸:一种是对强人工智能保持悲观态度,认为强人工智能很长时间内都不可能出现的;一种是对超大模型持怀疑态度,认为通过超大模型来实现人工智能是错误道路的。
在2022年11月30日之前,市面上有大大小小的互联网或IT企业需要进行文本处理,相应地,也就需要雇佣大量的NLP工程师们来解决相关的问题。
绝大多数的NLP工程师们所做的工程项目,主要是针对某些特定任务提出一个具体的模型,进行有针对性的数据标注,然后再制作模型。简而言之,就是以NLP子任务独立进行研究开发。比如分词、实体识别、文本分类、相似度判别、机器翻译、文摘系统、事件抽取,等等,不一而足。
也就是说,NLP产业界实际上处于一种手工业模式,你干你的,我干我的,针对不同的企业、不同的需求,需要不断地定制模型、定制数据来完成工作。
NLP中,还有一部分内容:知识图谱。知识图谱这个概念专门用来记录现实世界中的客观存在的事务的关联关系,对于NLP任务也极为重要。更准确地讲,应当叫做领域知识图谱,几乎没有哪个机构可以做出一个通泛的图谱来供应用。
但知识谱图属于有多少人工,就有多少智能的最典型代表。知识图谱做一万年做不到GPT3的水平,就像蒸汽机做的再好也驱动不了登月火箭。
ChatGPT已经完全抹去了传统NLP业态中,需要分不同子任务、分不同领域数据场景的手工业模式,而是直接采用大模型,以对话形式,直接形成了大一统,进入了机器时代。类似于传统的手工纺织女工,完全由机器替代了。很多NLP子领域不再具备独立研究价值。
评价NLP模型的效果,应当从两方面入手:
一方面,是评价模型对自然语言本身的拟合,比如,前后语句连贯、通顺、符合正常人类的叙述习惯,能够理解反问、反讽、情绪、基本世界观的构建和逻辑推断。客观讲,ChatGPT已经做到了极致,它的语言表达水平,比很多人的作文能力都强非常多。
另一方面,是评价模型对知识、事实类信息的拟合,这块能力ChatGPT还无法很好胜任,比如模型会告诉我3+13=23,汪小菲的姐姐是大S,谷歌的CEO是库克,等等,大家也都明白,大量的博客、文章、段子,讨论过很多了,不再赘述。
目前,这些事实、知识,是由知识图谱来解决的。但以笨拙的实体、关系、属性等为基本概念所作的构建,显然是没有前途的。
BERT以前的时代,人们热衷于在结构上做文章,各种+attention/gating/lattice/knowledge module,换来在一个有限集合的任务上的提升。
BERT时代,模型的结构逐渐固定下来,大家通过引入不同的训练目标/学习任务(如对比学习、领域偏置)在pretrained model的基础上进一步提升各个domain上的任务性能。
近两年到现在:训练目标也逐渐固定下来了(next token prediction),变成需要优化哪方面的能力就构造什么样的数据,或者提供一个可靠的奖励信号去引导模型自己向我们期待的方向做exploration。
参考:
https://zhuanlan.zhihu.com/p/158009816
开域聊天机器人-微软小冰的技术介绍(现实篇)
https://mp.weixin.qq.com/s/wBsh9dmMPks04X2pDB8Ang
沈向洋等重磅论文:公开微软小冰系统设计,迄今最详细!
https://www.zhihu.com/question/583134530
微软解散元宇宙团队投资近900亿搞ChatGPT,如何从商业角度解读此举?
https://zhuanlan.zhihu.com/p/605673596
ChatGPT这么强,会影响NLPer的就业环境吗
https://www.zhihu.com/question/575391861
ChatGPT印证了模型大一统的可行性,这在未来五年会对NLP从业者带来怎样的冲击?
GPT-4
2023.3.15 OpenAI推出GPT-4。
GPT-4可以接受图像和文本输入,而GPT-3.5只接受文本。
官网:
https://openai.com/research/gpt-4
技术报告:
https://arxiv.org/abs/2303.08774
GPT-4 Technical Report
由于该技术报告更多的是效果报告,而非原理介绍。因此最有价值的反而是稍早之前的Kosmos-1模型的论文:
https://arxiv.org/abs/2302.14045
Language Is Not All You Need: Aligning Perception with Language Models
2023.11.6 GPT-4 Turbo:支持128k上下文,相当于300页文档,输入价格大降2/3,速率限制翻倍。
3月16日,百度推出“文心一言”,可惜效果惨不忍睹。。。股价已暴跌近10%。
2022年某统计显示互联网上开放信息中文占比仅1.3%,而英文占比63%,其中高质量部分优势更大,比如论文。
模型的基础能力强吊打一切,语种只是上层表达。
RLHF论文中的训练数据英文占比99%+,西、法、德语还占了剩下的大部分,中文估计就是0.0x%这个级别,效果大家都体验到了,中文和其他小语种能力的提升同样也非常显著,这很强的证明这种训练方法是让模型学到了跨越语种的隐含信息。
4月7日,阿里云在微信公众号官宣:自研大模型“通义千问”开始邀请用户测试体验。
写一段关于酒的文字,不能出现“酒”字。
只有GPT4做到了。GPT3.5提到了红酒杯,出现了一次酒。国内几个模型开篇就是“酒是xxxx”,拿酒当了主语。
http://www.199it.com/archives/1611000.html
新华社研究院:人工智能大模型体验报告
如果严格来论,目前国内的自研大模型,不论是零一万物的Yi,还是百川智能的Baichuan,或者阿里旗下的通义千问,架构上和LLaMA都是一致的。
大家遥远的记忆中的Start-Copy Lee又回来了。
https://www.zhihu.com/question/630152920
如何看待李开复零一万物开源Yi大模型被指抄袭LLaMA?

您的打赏,是对我的鼓励
