Attention » Large Language Model(二)——AR vs AE, LLM大乱战
2024-03-14 :: 4635 WordsGPT-4(续)
参考:
https://www.zhihu.com/question/589639535
OpenAI发布GPT-4,有哪些技术上的优化或突破?
https://mp.weixin.qq.com/s/iw0wESsyP8nkPuFkj_EkOg
OpenAI正式推出多模态GPT-4
https://www.zhihu.com/question/589937459
3月16日百度举办“文心一言”发布会,现场有哪些信息值得关注?
https://www.zhihu.com/question/589941496
百度正式推出“文心一言”,然而港股股价已暴跌近10%,客观来说其能力与ChatGPT相较如何?
AR vs AE
自回归模型,是统计上一种处理时间序列的方法,用同一变数例如x的之前各期,亦即\(x_1\)至\(x_{t-1}\)来预测本期\(x_t\)的表现,并假设它们为一线性关系。因为这是从回归分析中的线性回归发展而来,只是不用x预测y,而是用x预测x自己,所以叫做自回归。
AR: Autoregressive Lanuage Modeling,又叫自回归语言模型。它指的是,依据前面(或后面)出现的tokens来预测当前时刻的token,代表模型有ELMO、GTP等。
\[\text{forward:}p(x)=\prod_{t=1}^Tp(x_t|x_{<t})\] \[\text{backward:}p(x)=\prod_{t=T}^1p(x_t|x_{>t})\]-
缺点:它只能利用单向语义而不能同时利用上下文信息。ELMO通过双向都做AR模型,然后进行拼接,但从结果来看,效果并不是太好。
-
优点:对自然语言生成任务(NLG)友好,天然符合生成式任务的生成过程。这也是为什么GPT能够编故事的原因。
AE:Autoencoding Language Modeling,又叫自编码语言模型。通过上下文信息来预测当前被mask的token,代表有BERT,Word2Vec(CBOW)。
\[p(x)=\prod_{x\in Mask}p(x_t|context)\]-
缺点:由于训练中采用了MASK标记,导致预训练与微调阶段不一致的问题。此外对于生成式问题,AE模型也显得捉襟见肘,这也是目前为止,BERT为数不多没有实现大的突破的领域。
-
优点:能够很好的编码上下文语义信息,在自然语言理解(NLU)相关的下游任务上表现突出。
针对AR和AE的不同特点,又将前者称为Causal language models,后者称为Masked language models或者Prefix language models。
Causal:每个token只能看到在它之前的token信息,而看不到在它之后的token。
Masked:完形填空。
2023.3
ChatGPT的出现,为自然语言生成任务找到了商业化的路径。有鉴于此,Google也不得不在BERT上对AR模型,做了一些有损逼格的妥协。。。囧
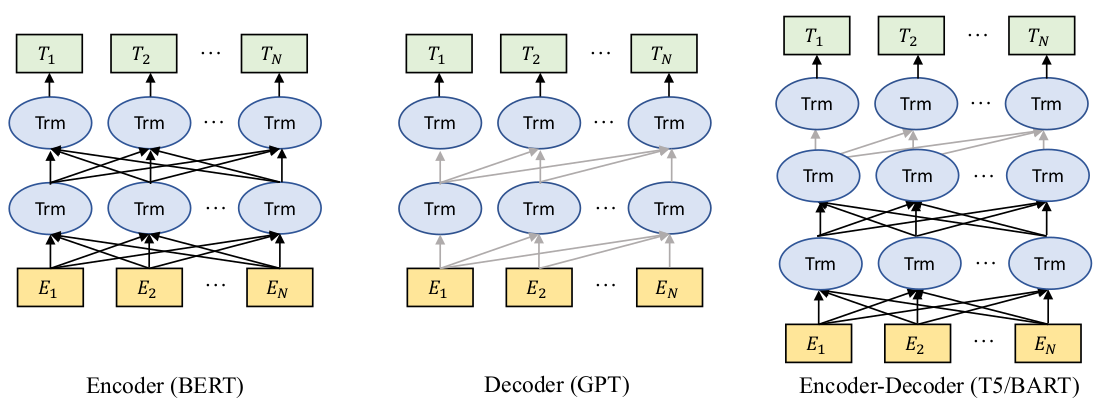
deep encoder+shallow decoder
参考:
https://mp.weixin.qq.com/s/n6F6MTjrUCmvEoaLiVZpxA
更深的编码器+更浅的解码器=更快的自回归模型
https://mp.weixin.qq.com/s/pe2E69Gpw0nT9sSHvtBGSg
自回归与非自回归模型不可兼得?预训练模型BANG全都要!
https://www.zhihu.com/question/588325646
为什么现在的LLM都是Decoder only的架构?
https://www.zhihu.com/question/592545459
大模型都是基于Transformer堆叠,采用Encoder或者Decoder堆叠,有什么区别?
LLM大乱战
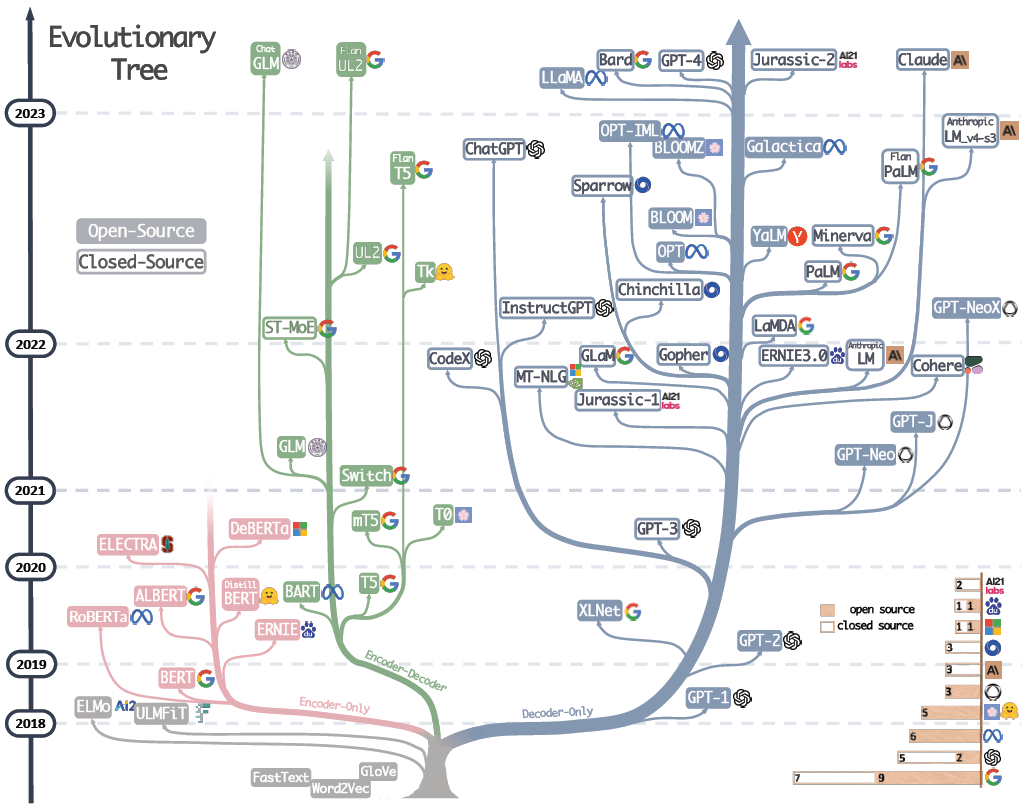
在LLM进化树中,BERT(Encoder-Only)、T5(Encoder-Decoder)、GPT(Decoder-Only)分别代表了不同的架构方向。那为什么在大模型时代,曾经风光无限的BERT家族和T5家族会逐渐没落了?
从纯算法模型结构上,Google的T5是比GPT更加优雅的神经网络模型结构, 但是由于T5的模型结构不是线性的,因为在Decoder和Encoder之间有复杂的连接关系(即对应的Cross Attention或者叫做 Cross Condition),导致T5在真正大规模堆叠的时候,实际上在工程领域,很难通过分布式并行高效的执行起来。因此,在目前已知的分布式并行优化上,T5很难通过规模化扩展模型的规模,Scale到千亿参数以上。这就是AI系统反过来影响算法发展,对算子作出的一种选择作用。
目前预训练大模型成本居高( GPT-4 训练一次的成本超过 5000W 美金),再往上翻倍探索下一个FLOPs数量级也变得十分困难。因此百亿级别和千亿级别的 MoE 架构开始慢慢成为了大模型时代考虑的下一个主流方向.
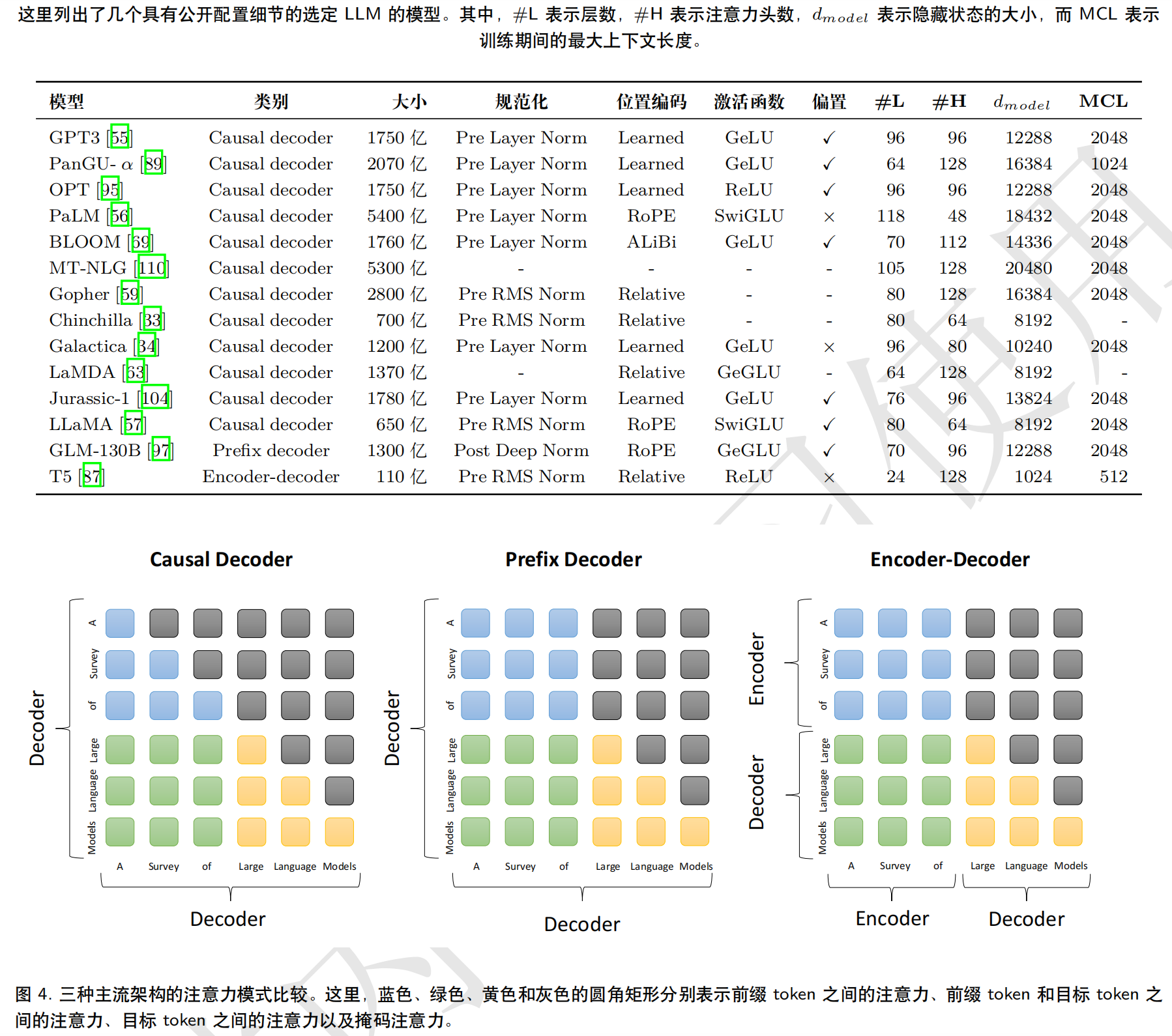
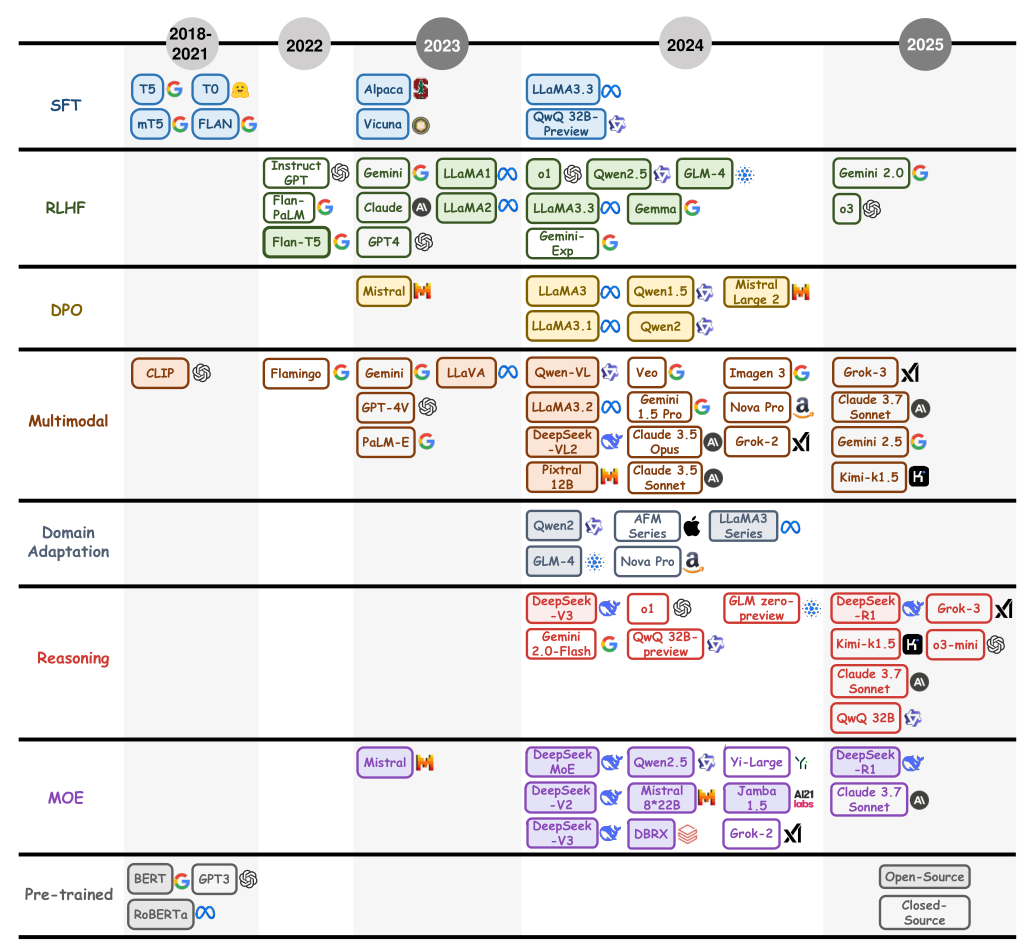
https://arthurchiao.art/blog/llm-practical-guide-zh/
大语言模型(LLM)综述与实用指南(Amazon,2023)
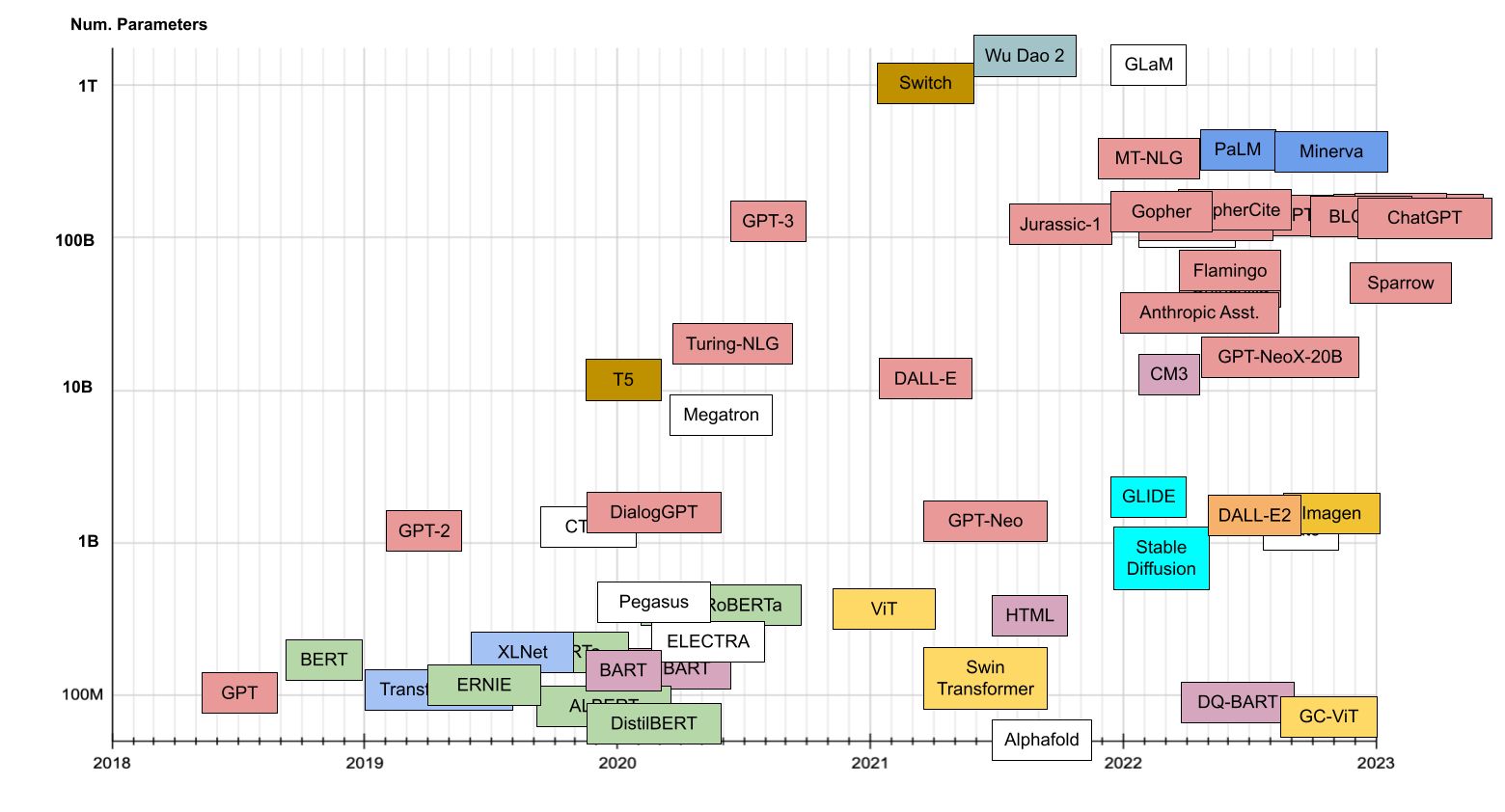
OpenAI的GPT 3的规模为175B,Google的LaMDA规模为137B,PaLM的规模为540B,DeepMind的Gogher规模为280B。
国内也有中文巨型模型,比如清华&智谱GLM规模130B,华为“盘古”规模200B,百度“文心”规模260B,浪潮“源1.0”规模245B。
然而,OpenAI的中小模型(如 6B~13B)的性能已经远超一众超大模型(如130B的GLM和175B的OPT)。由于实力的不对等,OpenAI、Google、DeepMind等LLM头部玩家可能不再会公开最前沿的LLM研究进展(转为挤牙膏模式)。
悟道2.0是一个基于MoE的稀疏模型,总参数量超过万亿,存一个checkpoint 20T。模型是神威上训练的,那玩意没有GPU或者CUDA,是神威自己的一套底层架构,因此适配起来非常困难。这个项目更像是一个国产硬件上训练巨大模型的尝试,项目启动之初就知道不可能投入到产品。
其次,稀疏模型的参数量和普通模型没有太大的可比性。
175B级别的训练的成本非常高。例如2020年GPT-3的单次训练成本约460万美元,总训练成本达1200万美元,如果推算到2023,国内单次训练成本约662-1170万RMB。以2022年为例,OpenAI运行成本为5.44亿美元,其中约有2亿多美元是工资/劳务费。
国内这一堆利润导向的“AI研究”公司,阿里的达摩院甚至还闹出过自负盈亏这种笑话,让这些公司花费大量时间和金钱去做预训练语料库,估计比让恒大还清债务还难。
当初微软为了帮助OpenAI训练,在2020年给OpenAI搭建了一个有285000核CPU和10000个V100 GPU的超算环境。
Q:微软调度了1万张卡给OpenAI做训练,商汤的反馈是我们国内最多也就调动2000张卡,这个技术有难度吗?
A:我目前了解到这一块国内目前没有哪个达到1万张量级的,不可能的,现在没有这水平。现在的确从百度视角来看,现在几千张卡在测试就不错了。从技术积累来说,涉及到集群做调度还是有一些协同性的难度。我认为包括商汤、百度,离微软的差距还是短时间内无法追上的。
国内先搞一波小参数的大模型,PR一定要cover机器之心、新智元、量子位,然后宣称自己的130b模型超越了gpt4,并在自己的榜上发布测评结果,成功超越gpt4。最后一堆商业公司来买130b的模型,这就算是创业成功了,毕竟一套价格不菲,几千万。
国内的研究者总是发布达到chatgpt4 106%能力的工作,人家一更换测评数据集就泯然众人矣了。
4月份业界就有传闻说字节想花上百万美金从OpenAI挖人,结果面试官被OpenAI反挖走了。
百度的数据团队也非常强,数据采集、数据清洗都是相当专业的。单是数据增强,一个月就花几千万的OpenAI API调用费用。
在初创公司已经发布的大模型中,只有Moonshot的模型水平超过了GPT-3.5。并没有直接照抄LLaMA的架构,而是做了很多工程上的优化。

https://www.zhihu.com/question/608763410
国内AI大模型已近80个,哪个最有前途?
很多中间任务本身是为了服务下游高级任务,被拆解出来的,结果ChatGPT直接解决高级任务,中间任务自然也就不需要了。过去那一套,POS、句法树、依存都不用做了,现在都没看太多人提了,甚至乔姆斯基体系最近又被喷了。
中间层还不光是中间任务,还包括LLM中间训练部分的,比如模型结构、损失函数、优化器啊。
有段时间,各种魔改Transformer、优化器、损失函数。但到现在常用模型结构和Attention Is All Your Need中也没差太多,小改了LN、activation,而优化器则主要就修复了Adam实现的bug,成了AdamW. 结构方面出于推理效率考量的用一用MQA和GQA。
https://mp.weixin.qq.com/s/vfsB5t3r5dBACKQx6FshVw
选择你的道路:LLM时代指南

数据泄露(data contamination)在大模型时代可以说是极难避免的。随着大模型训练数据规模的扩大,保证训练数据与常用benchmark之间没有重叠变得几乎不可能。
https://zhuanlan.zhihu.com/p/665426752
大模型是如何在评测中“作弊”的?
大模型开源有几个等级,开源程度从低到高:
- 仅模型开源(技术报告只列举了Evaluation)。主要利好做应用的公司(继续训练和微调)和普通用户(直接部署)技术报告开源训练过程。
- 比较详尽的描述了模型训练的关键细节。利好算法研究。训练代码开源/技术报告开源全部细节。
- 包含了数据配比的核心关键信息。这些信息价值连城,是原本需要耗费很多GPU资源才能得到的Know-how。
- 全量训练数据开源。其他有算力资源的团队可以基于训练数据和代码完全复现该模型。训练数据可以说是大模型团队最核心的资产。数据清洗框架和流程开源。
- 从源头的原始数据(比如 CC 网页、PDF 电子书 等)到 可训练的数据的清洗过程也开源, 其他团队不仅可以基于此清洗框架复现数据预处理过程,还可以通过搜集更多的源(比如基于搜索引擎抓取的全量网页)来扩展自己的数据规模,得到比原始模型更强的基座模型。
实际上大部分的模型开源诸如LLaMa2、Mistral、Qwen等,只做到Level-1,像DeepSeek这样的可以做到Level-2。而Level-4及以上的开源一个都没有。
LLM时代的典型特征:学习速度跟不上知识的更新速度(下载速度跟不上模型的开源速度)。
DeepSeek估值时,对标的是OpenAI,其估值区间被估算在10亿美元至1500亿美元之间。
根据“路边消息社”报道,现在想约见梁文锋,需要先报省委办公厅。一般人见不到梁文锋。网上还传出了“大年三十特警陪同回家,村口警察巡逻”的消息。

您的打赏,是对我的鼓励
