Attention » Large Language Model(四)——MoE
2025-02-22 :: 5373 WordsChinchilla Law(续)
当batch size较小时,更新方向(即对真实梯度的近似)会具有很高的方差,导致的梯度更新主要是噪声。
当batch size非常大时,我们从训练数据中抽样的任何两组数据都会非常相似(因为它们几乎完全匹配真实梯度)。
所以就有了Gradient Noise Scale Law。
https://zhuanlan.zhihu.com/p/666997679
大Batch训练LLM探索
Meta在LLaMA的观点是:给定模型的目标性能,并不需要用最优的计算效率在最快时间训练好模型,而应该在更大规模的数据上,训练一个相对更小模型,这样的模型在推理阶段的成本更低,尽管训练阶段的效率不是最优的(同样的算力其实能获得更优的模型,但是模型尺寸也会更大)。
就算GPU管够,大模型一次训练也依然耗时巨大,而能够决定模型最终效果的环节非常多,所以合理的做法是先通过训小参数的Draft模型进行调试,跑通并打磨整个链路,等到都弄好之后再往上扩大参数量,逐级扩增——这是Scaling Law的基本玩法。
https://zhuanlan.zhihu.com/p/667489780
解析大模型中的Scaling Law
GPT之前走过一段弯路,它放弃了继续把模型做大,转而去研究后训练算法。事实证明这是舍本逐末,结果导致Anthropic拥有了全世界最大的模型。然后一举把vibe coding给打通了。
MoE
Mixture of Experts(MoE)
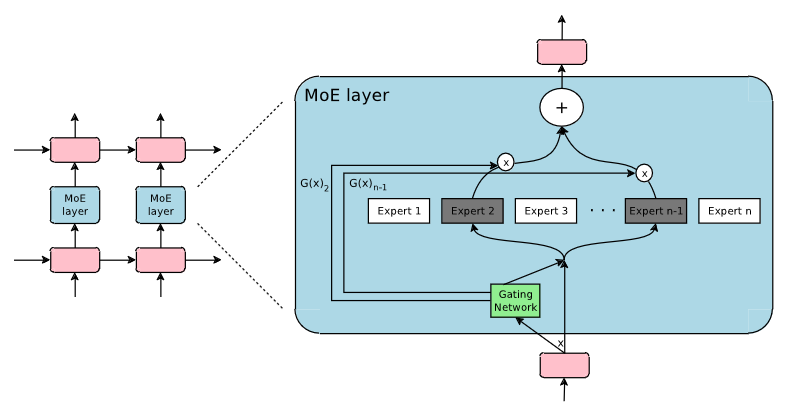
![]()
挑出模长最大的k个向量来逼近n个向量之和:模长越大的向量,在求和过程中越不容易被抵消,从而作用越突出。
https://kexue.fm/archives/10699
MoE环游记:从几何意义出发
开源项目:
https://github.com/XueFuzhao/OpenMoE
https://github.com/laekov/fastmoe
目前的LLM(特别是 MoE)通过“条件计算”(Conditional Computation)来扩展容量,但实际上模型是在用昂贵的神经网络计算去“模拟”知识检索过程。而Engram引入了一个独立的、低成本的“条件记忆”模块,让模型拥有了原生的、O(1)复杂度的查表能力(Lookup)。
https://www.zhihu.com/question/1994233409871050526
如何评价DeepSeek发布梁文锋署名论文,提出“条件记忆”及Engram记忆检索架构?有哪些亮点?
https://mp.weixin.qq.com/s/XQSEg2_8_1lFqWdHVG6TVA
Switch Transformer: 高效稀疏的万亿参数Transformer
https://zhuanlan.zhihu.com/p/362525526
深入解读首个万亿级语言模型Switch Transformer
https://zhuanlan.zhihu.com/p/676980004
使用PyTorch实现混合专家(MoE)模型
https://huggingface.co/blog/zh/moe
混合专家模型(MoE)详解
https://zhuanlan.zhihu.com/p/662518387
MOE并行
https://zhuanlan.zhihu.com/p/1431483173
聊聊MoE实验性工作Upcycling Large Language Models into Mixture of Experts
https://zhuanlan.zhihu.com/p/672712751
大模型LLM之混合专家模型MoE(上-基础篇)
https://zhuanlan.zhihu.com/p/673048264
大模型LLM之混合专家模型MoE(下-实现篇)
https://zhuanlan.zhihu.com/p/2047396525731586071
MoE架构优化与GroupedGemm Kernel设计
Mixtral
Mixtral是由Mistral AI团队推出的MoE模型,参数大小为47B。
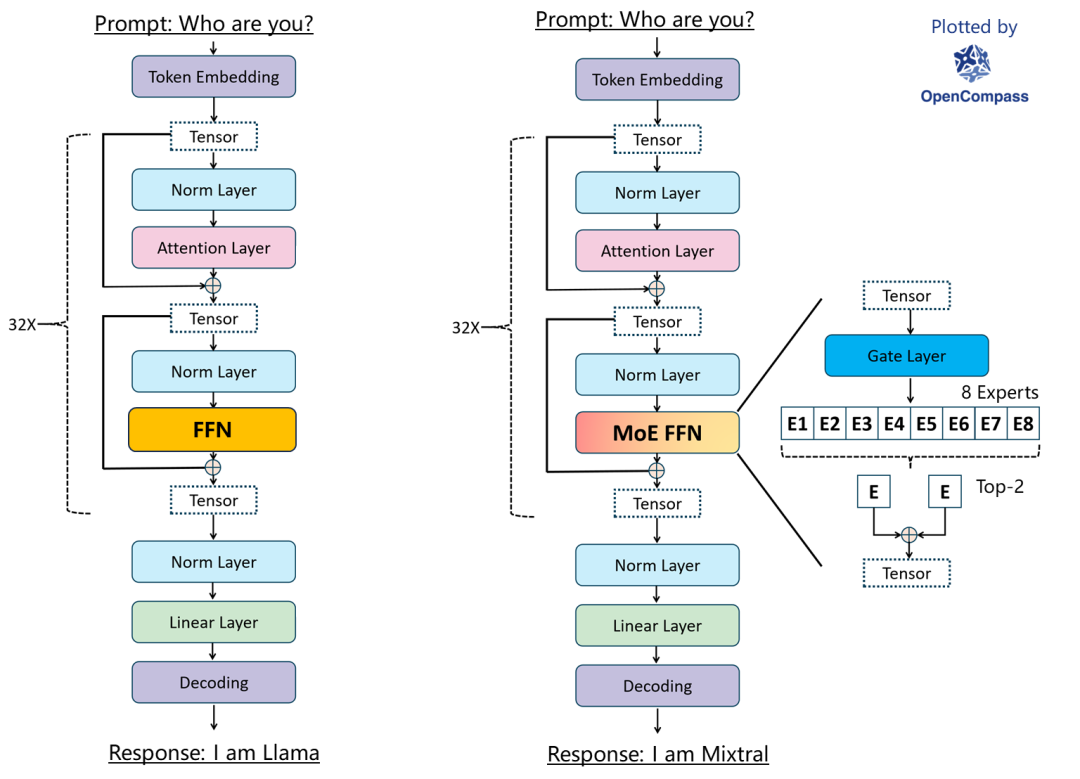
https://zhuanlan.zhihu.com/p/676010571
欢迎Mixtral-当前Hugging Face上最先进的MoE模型
DeepSeek
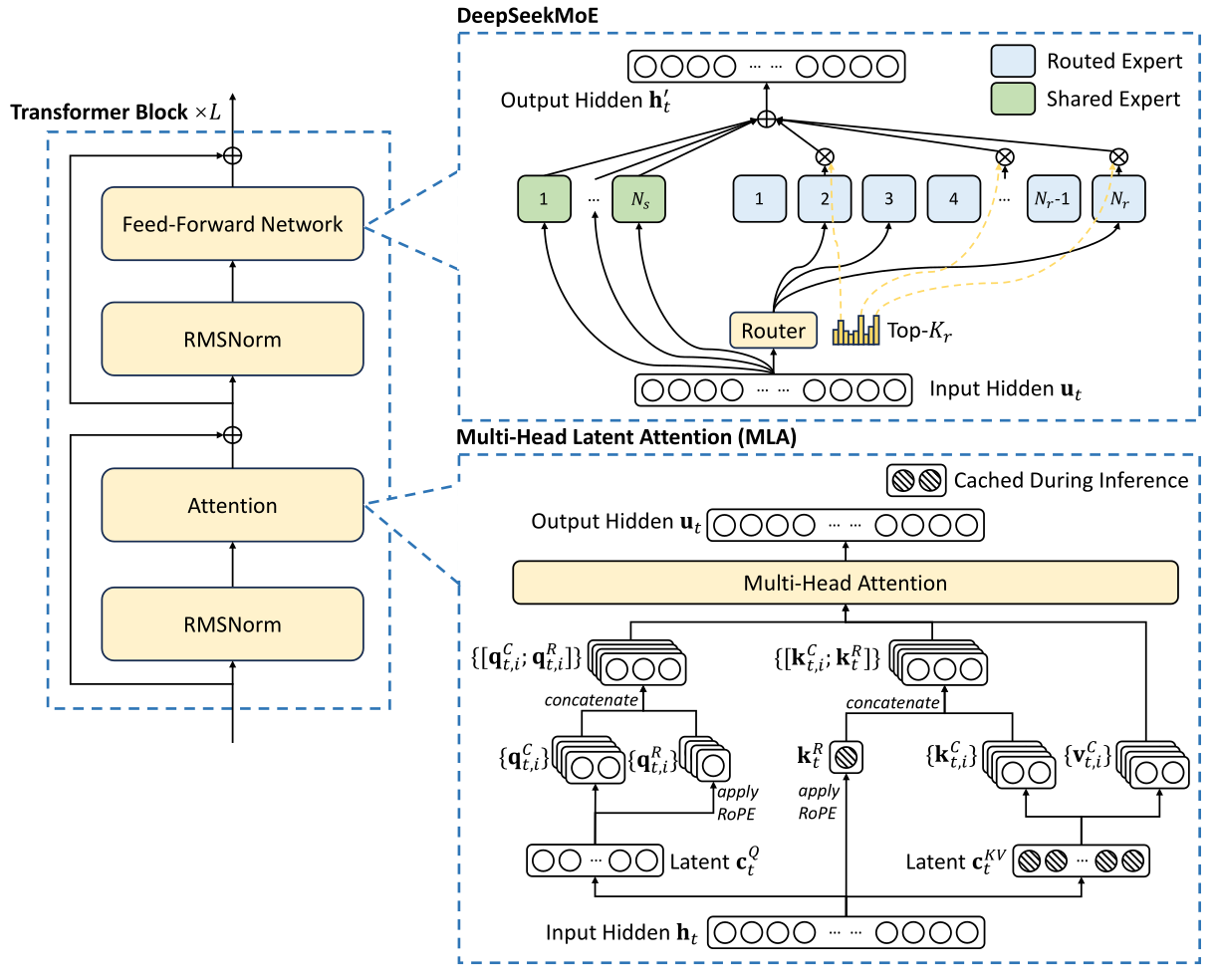
《DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models》
《DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model》
《DeepSeek-V3 Technical Report》
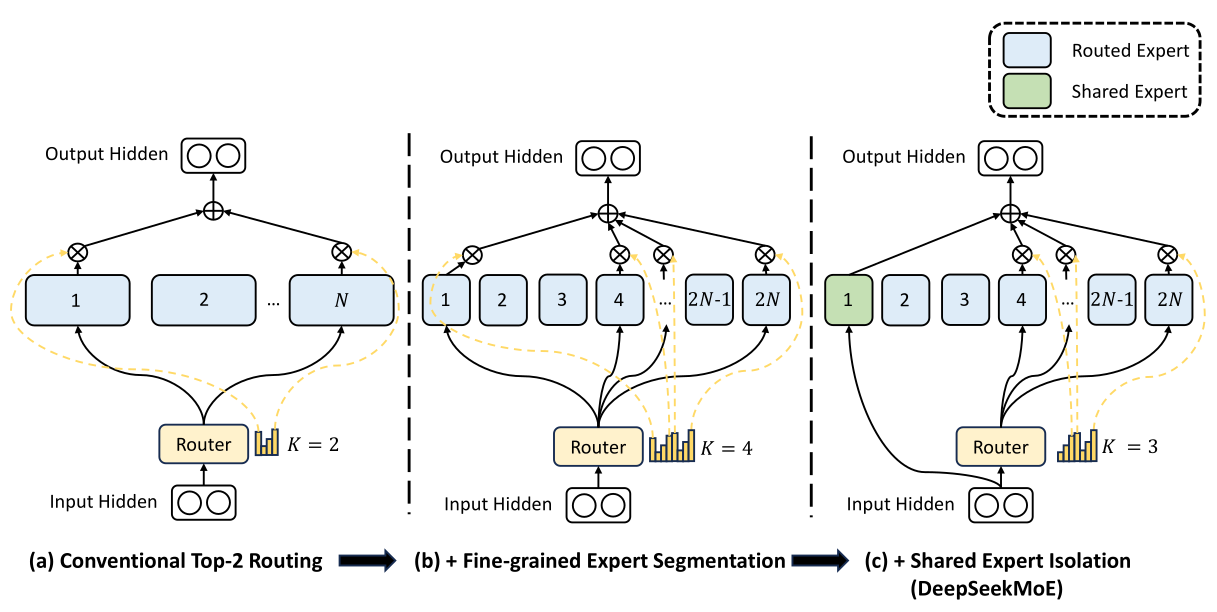
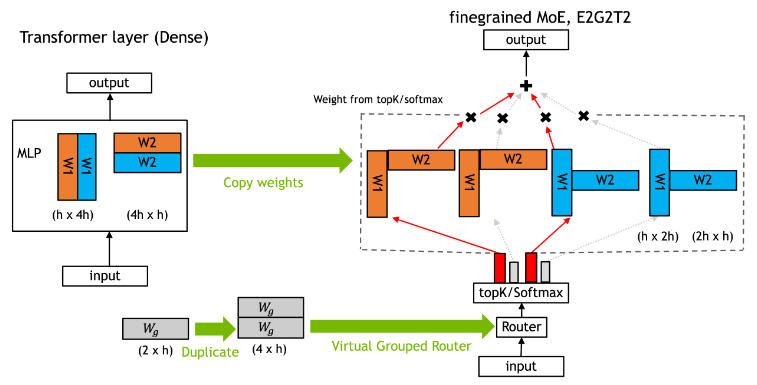
DeepSeek认为在同等专家参数量和计算成本不变的前提下,更多数量的小专家,比数量少的大专家好。这种更精细的专家分割使得激活专家的组合更加灵活且适应性更强。
专家路由事实上引入了一个不连续的门控函数(对梯度计算不友好),这导致梯度下降优化方法在MoE训练中表现不佳,甚至出现“路由崩溃”,即模型容易陷入始终为每个Token激活相同的少数专家的窘境,而不是将计算合理的传播到所有的可用专家。这也是MoE模型训练的难点。
传统的规避路由崩溃的方法是强制“平衡路由”,即通过训练策略让每个专家在足够大的训练批次中被激活的次数大致相等。这一策略也就是“辅助损失”。但这种强制性的辅助损失会由于训练数据的结构不均衡特征,导致同领域的专家能力分散到不同的专家模块之中,极度损害MoE模型的性能。理想的MoE应该有一些经常访问高频通用信息,并具备其他访问较少的专业领域专家。如果强制平衡路由,将失去实现此类路由设置的能力,并且必须在不同的专家之间冗余地复制信息。
DeekSeek采用了“增加共享专家+无辅助损耗负载平衡”的方法解决这一问题。
无辅助损耗负载均衡(Auxiliary-Loss-Free Load Balancing)方法是将特定于专家的偏差项添加到路由机制和专家亲和力中。偏差项不会通过梯度下降进行更新,而是在整个训练过程中持续监控并进行调整以确保负载平衡。如果训练中某个专家没有获得合理的命中次数,可以在每个梯度步骤中微调偏差项增加命中概率。
PS:辅助loss本质上只是路由策略,而不是样本的真实loss,过分加重前者,显然会导致整个模型的性能下降。
MoE架构的本质是模型参数分布式存储,MoE减少计算量的代价可能是不同专家模型的参数重复和总参数量增加,这往往也意味着更大更贵的HBM成本。外界传言的MoE模型可以更小,其实是指的MoE模型蒸馏的Dense模型可以兼顾参数量和推理(Reasoning)性能。
DeepSeek选择Llama和Qwen系列开源大模型进行蒸馏,使相应的Dense模型也能获得推理能力。例如DeepSeek-R1-Distill-Qwen-7B,实际上就是模型结构采用Qwen-7B,而对模型参数进行了蒸馏。
https://zhuanlan.zhihu.com/p/21208287743
DeepSeek是否有国运级的创新?(上)从V3到R1的架构创新与误传的2万字长文分析
https://zhuanlan.zhihu.com/p/21755758234
DeepSeek是否有国运级的创新?(下)从V3到R1的架构创新与误传的2万字长文分析
https://mp.weixin.qq.com/s/WFJxnTF9fGIIXPA7GQ5V2w
详细谈谈DeepSeek MoE相关的技术发展
https://blog.csdn.net/v_JULY_v/article/details/145429696
一文速览DeepSeek-R1的本地部署——可联网、可实现本地知识库问答:包括671B满血版和各个蒸馏版的部署
https://blog.csdn.net/v_JULY_v/article/details/145406756
一文速览DeepSeekMoE:从Mixtral 8x7B到DeepSeekMoE(含MoE架构的实现及DS LLM的简介)
https://zhuanlan.zhihu.com/p/27181462601
DeepSeek-V3 / R1 推理系统概览
https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-reasoning-llms
A Visual Guide to Reasoning LLMs
deepseek r1的推理性价比方案实际上在两端。要么是上万并发度的大集群,deepseek的320 GPU作为最小部署单元就是这样一个极端,要么是单用户并发度价格做得足够低。
存储需求671GB起步,但给一个请求生成一个token只需要读37GB的数据。如果并发度提高,那么多个请求对应多份37GB的数据。这就造成了tps和并发度基本呈反比关系。
但是因为所有请求的访存都是落在这个671GB范围内的,而不是batchsize x 37GB,所以当并发度增加到一定程度,tps衰减就收敛了。
如果超大超稀疏的MoE模型成为主流,那么“云上面向大并发的分布式推理”和“本地面向中小并发的推理”在架构上就要开始分岔了,需要分别演进。
https://www.zhihu.com/question/2030966008312231624
如何评价deepseek最新发布的deepseek v4模型?(2026.4.24)
https://www.cnblogs.com/emergence/p/19922100
DeepSeek-V4:迈向高效的百万Token上下文智能
https://www.zhihu.com/question/1997334245450981959
如何评价DeepSeek V4架构?
https://blog.csdn.net/v_JULY_v/article/details/160744266
DeepSeek-V4——迈向百万token上下文:保留V3的MoE和多token预测机制,提出混合注意力机制(CSA/HCA)、流形约束超连接mHC(替代残差)、Muon优化器(取代AdamW)
Sparse Attention
MoE主要是对FFN(expert)进行稀疏化,相应的还有Sparse Attention。
https://www.zhihu.com/question/12616022631
DeepSeek新论文NSA注意力机制,有哪些信息值得关注?
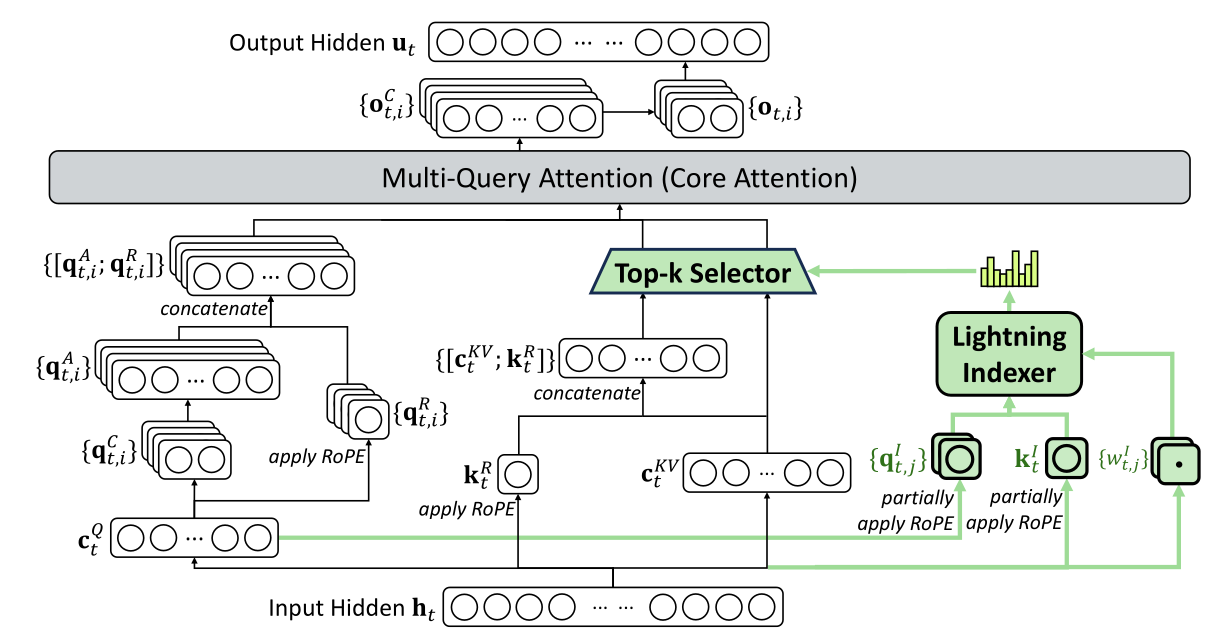
长上下文Transformer的核心痛点是注意力机制的\(O(L^2)\)复杂度和随之而来的显存/带宽压力。所有稀疏注意力的本质都是在回答一个问题:我们能否在不计算完整注意力矩阵的情况下,依然找到那些最重要的Key-Value对?
DSA(DeepSeek Sparse Attention)的思想非常直观:增加一个极其便宜的“粗评分器”(即索引器),先对“所有历史token”做一次极轻量的打分和排序,选出Top-k个最有潜力的候选者。然后,再把“真正昂贵”的主注意力计算聚焦在这Top-k个候选者上。通过这种方式,将注意力的开销从\(O(L^2)\)近似降低到\(O(Lk)\),其中\(k \ll L\)。
https://zhuanlan.zhihu.com/p/1956149979077911247
DeepSeek V3.2 Sparse Attention技术深度剖析与潜在改进
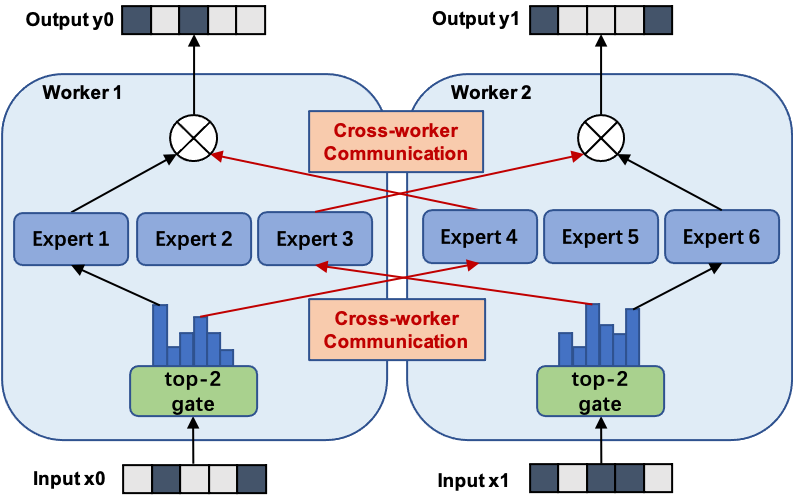
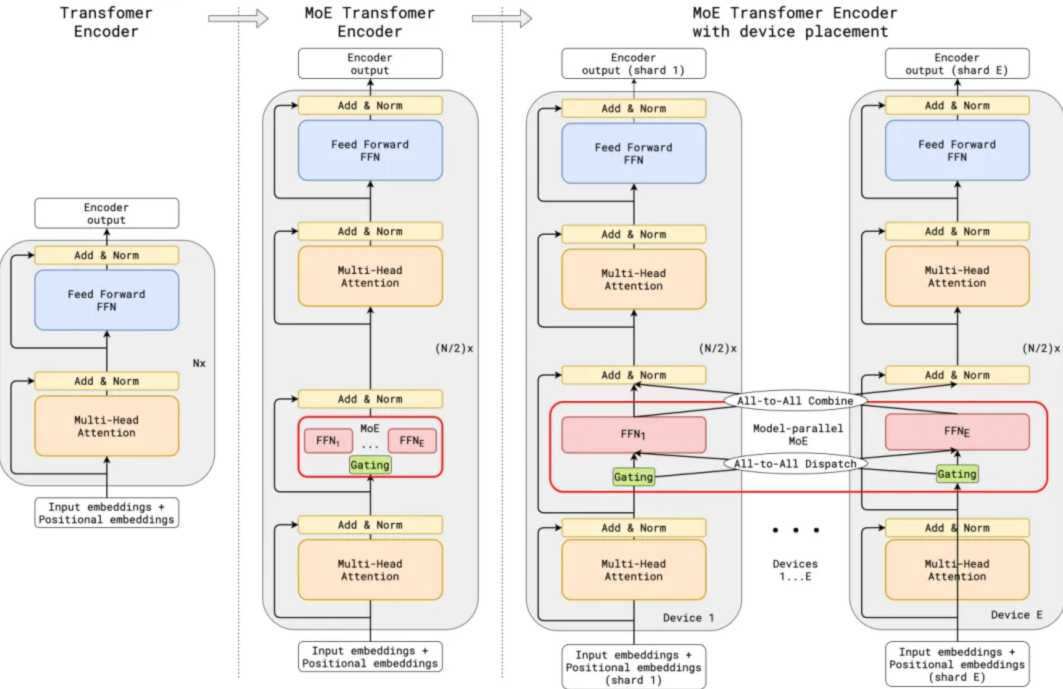
Expert Parallelism
Expert-Parallel vs. Token-Parallel
MoBA:Mixture of Block Attention
https://github.com/deepseek-ai/DeepEP
deepseek官方的EP库
PPLXAll2AllManager是vLLM为了解决Expert Parallelism场景下MoE模型的跨GPU专家tensor交换,而引入的一个通信调度器(All-to-All管理器)。
DeepEPHTAll2AllManager和DeepEPLLAll2AllManager是vLLM在集成DeepEP(DeepSeek Expert Parallel)通信框架时,为MoE模型推理引入的两类分层All-to-All通信调度器。
它们把原来单一的All-to-All拆成两层:
- HT(High-Throughput)层——节点内GPU之间大批量、高吞吐交换;
- LL(Low-Latency)层——节点间跨机NVLink/IB网络低延迟交换。
EPLB:Expert parallelism load balancer

您的打赏,是对我的鼓励
