AI » Hadoop
2016-10-12 :: 5931 WordsHadoop
最近(2016.4),参加公司组织的内部培训,对Hadoop有了一些认识,特记录如下。
IOE

在Google开发GFS之前,业界主流的数据库方案是IOE,即:IBM大型机+Oracle数据库+EMC存储设备。
这套方案的主要缺陷在于:
1.服务上限有限。单个机器再强也有上限,对于PB级数据有时会力不从心。
2.IOE方案是商用的专有方案,价格高昂。
概述
Hadoop项目由Doug Cutting创建。Doug Cutting也是Lucene项目的创建者。
PS:Lucene是我2007年学习搜索引擎技术时,所接触到的开源项目。回想起来,简直恍如隔世啊。
官网:
http://hadoop.apache.org/
官方文档:
http://hadoop.apache.org/docs/current/
广义的Hadoop包含一个庞大的生态圈:
http://cqwjfck.blog.chinaunix.net/uid-22312037-id-3969789.html
Hadoop初探之Hadoop生态圈
http://www.360doc.com/content/14/0113/17/15109633_345010019.shtml
Hadoop的“生态圈”
狭义的Hadoop包含如下组件:
Hadoop Common
Hadoop Distributed File System(HDFS)
Hadoop YARN
Hadoop MapReduce
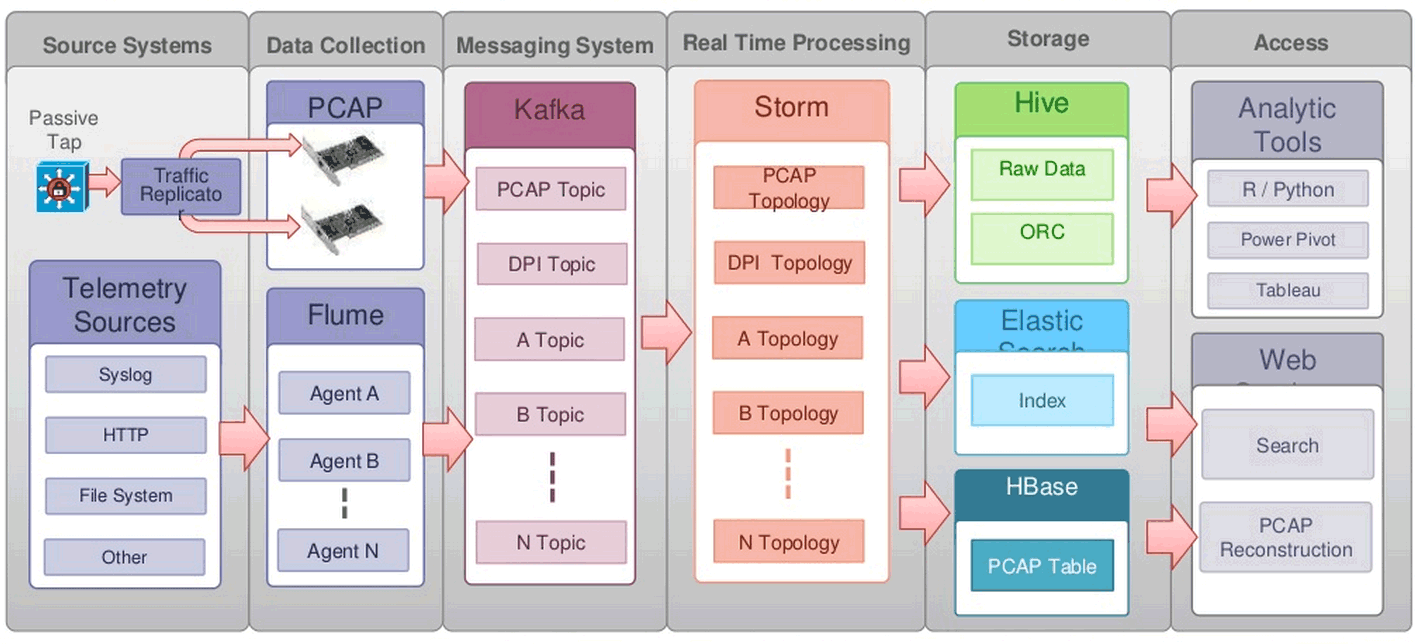
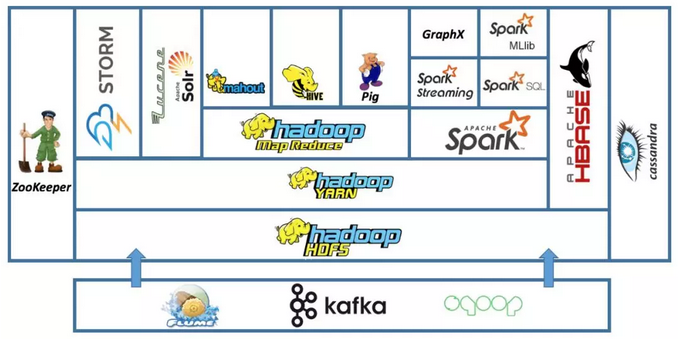
架构
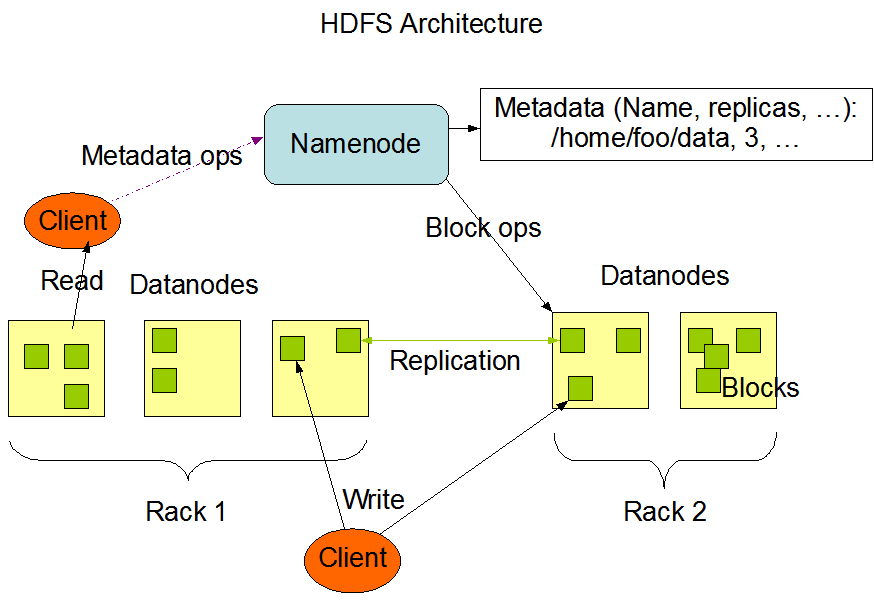
HDFS 1.0:
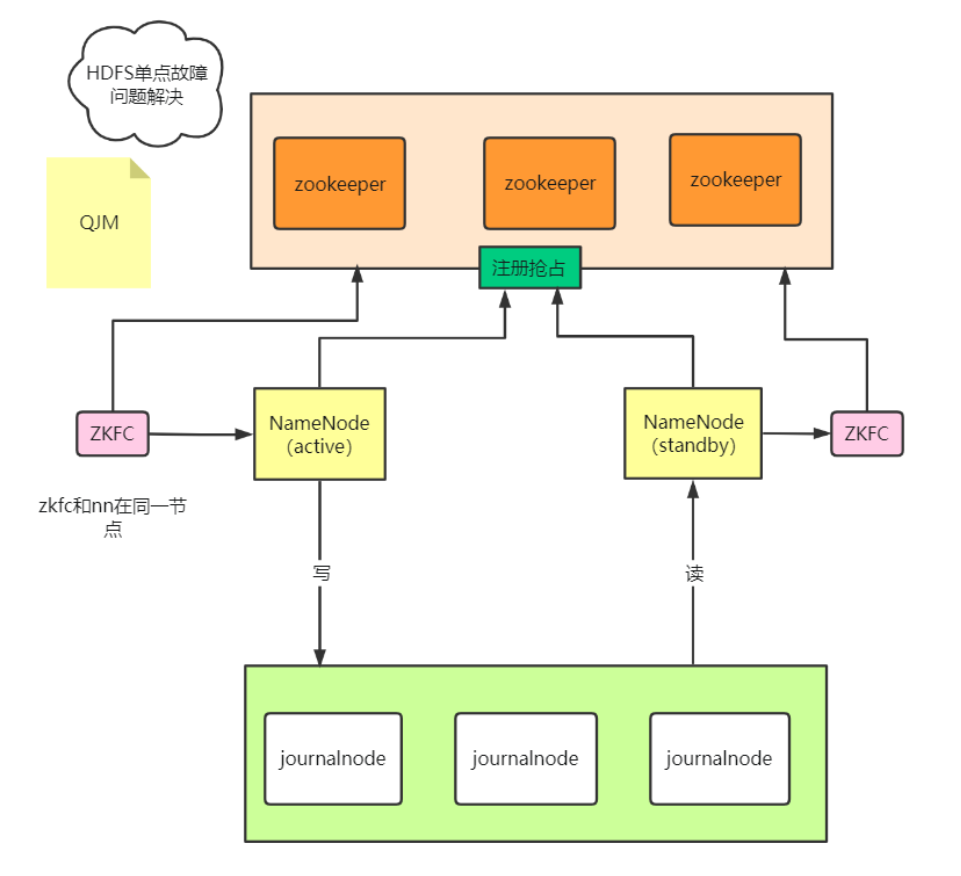
HDFS 2.0:
HDFS 3.0:
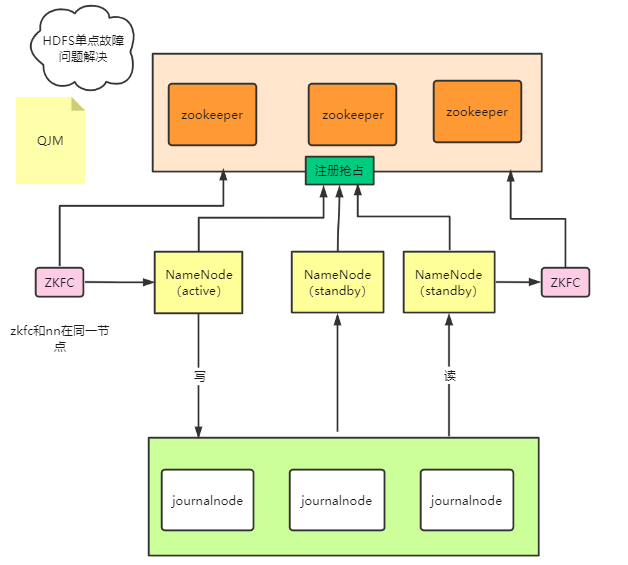
https://mp.weixin.qq.com/s/0QnxGLL66BW_BL-IBr5jDA
Hadoop之HDFS架构演进之路
编译
Hadoop目前不在Ubuntu的官方软件仓库中,无法使用apt安装。使用源代码编译Hadoop的相关步骤,可在源码包的BUILDING.txt中找到。这里仅作为补遗之用。总的来说,如无必要还是直接下载bin包比较好,编译还是很麻烦的。
安装FindBugs
Hadoop的大部分软件依赖,都可以使用apt安装。BUILDING.txt里已经写的很详细了。
FindBugs是一个Java代码的静态分析检查工具。它的官网:
http://findbugs.sourceforge.net/index.html
它的安装方法有3种:
1.源代码安装。下载源代码之后,运行ant build,然后设定相关路径,以供Hadoop使用。
2.apt安装。FindBugs目前不在Ubuntu 14.04的软件仓库中,而在Ubuntu 15.10的软件仓库中,需要设置源方可安装。这种方法也需要设定相关路径,以供Hadoop使用。
2.maven安装。
mvn compile findbugs:findbugs
这种方法最简单。安装完成之后的FindBugs位于maven repository中,而后者通常在~/.m2/repository/下。
这种方法的好处是:由于Hadoop使用maven编译,maven安装之后,可以免去设置路径的步骤。但坏处是:其他不用maven的程序,无法使用该软件。
这一步只要不出下载不成功之类的错误,就算成功。错误留给下一步来解决。
PS:maven下载的文件,大约有180MB,且多为小文件,初次运行相当费时。
编译Hadoop
mvn package -Pdist -DskipTests -Dtar
这里一定要-DskipTests,原因是test不仅速度非常慢,会导致系统响应缓慢,而且即使是官方代码,也不一定能通过所有的test case。
编译的结果在hadoop-dist/target下
安装
Hadoop有Single Node和Cluster两种安装模式。一般的部署,当然采用后者。得益于Java的可移植性,Hadoop甚至可以部署到由Raspberry Pi组成的集群中。
前者主要用于开发和学习之用。这里只讨论前者。
Single Node又可分为两种模式:Standalone和Pseudo-Distributed。前者一般仅用于检验程序逻辑的正确性,因为这种模式下,并没有Hadoop常见的各种节点和HFS的概念,所有的程序都运行在一个Java进程中。而后者在配置和运行方面,与Cluster已经相差无几。
http://www.cnblogs.com/serendipity/archive/2011/08/23/2151031.html
hadoop配置含义
CDH
Cloudera’s Distribution Including Apache Hadoop,简称CDH,是目前用的比较多的Hadoop版本,相比于Apache官方的Hadoop来说,有以下优点:
1.CDH基于稳定版Apache Hadoop,并应用了最新Bug修复或者Feature的Patch。Cloudera常年坚持季度发行Update版本,年度发行Release版本,更新速度比Apache官方快,而且在实际使用过程中,CDH表现无比稳定,并没有引入新的问题。
2.CDH支持Yum/Apt包,Tar包,RPM包,Cloudera Manager四种方式安装,可自动处理软件包之间的依赖和版本匹配的问题。
官网:
www.cloudera.com/downloads/cdh.html
何时使用hadoop fs、hadoop dfs与hdfs dfs命令
hadoop fs:使用面最广,可以操作任何文件系统。
hadoop dfs与hdfs dfs:只能操作HDFS文件系统相关(包括与Local FS间的操作),前者已经Deprecated,一般使用后者。
这些命令的选项大部分与linux shell相同,差异点主要在于:
1.HDFS->Local FS。
hadoop fs -get
1.Local FS->HDFS。
hadoop fs -put
服务端口
Hadoop自带了一些web服务端口,如下表所示:
| 默认端口 | 设置位置 | 描述信息 |
|---|---|---|
| 8020 | namenode RPC交互端口 | |
| 8021 | JT RPC交互端口 | |
| 8080 | Storm UI | |
| 50030 | mapred.job.tracker.http.address | JOBTRACKER的HTTP服务器和端口 |
| 50070 | dfs.http.address | NAMENODE的HTTP服务器和端口 |
| 50010 | dfs.datanode.address | DATANODE控制端口,主要用于DATANODE初始化时,向NAMENODE提出注册和应答请求 |
| 50020 | dfs.datanode.ipc.address | DATANODE的RPC服务器地址和端口 |
| 50060 | mapred.task.tracker.http.address | TASKTRACKER的HTTP服务器和端口 |
| 50075 | dfs.datanode.http.address | DATANODE的HTTP服务器和端口 |
| 50090 | dfs.secondary.http.address | 辅助DATANODE的HTTP服务器和端口 |
jps
jps是Java提供的虚拟机进程查看工具。
使用方法:
jps -ml
查到的进程,可用如下方法kill:
kill -9 <进程号>
和hadoop有关的进程包括:
| 名称 | 说明 |
|---|---|
| QuorumPeerMain | ZooKeeper Daemon |
| DataNode | HDFS Data Node |
| HRegionServer | Hbase Region Server |
| HMaster | Hbase Master |
| NodeManager | YARN Node Manager |
| ResourceManager | YARN Resource Manager |
| nimbus | Storm nimbus |
| supervisor | Storm supervisor |
其他JDK工具还有:
jshell:交互式的Java命令行工具。
jcmd:一个强大的工具集。
jhsdb:一个可视化的Java内存调试工具。
jmap:查看堆信息。
jstack:查看栈信息。
jstat:一个JVM监控工具
参考:
https://www.cnblogs.com/noKing/p/9457541.html
JDK常用命令行工具
MapReduce编程
map-reduce:把任务map到计算资源上去,得到结果之后reduce。
教程:
https://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
MapReduce Tutorial
Hadoop生态
Hive可以简单理解为,Hadoop之上添加了自己的SQL解析和优化器,写一段SQL,解析为Java代码,然后去执行MR,底层数据还是在HDFS上。
这看起来挺完美,但问题是程序员发现好慢啊。原因是MR,它需要频繁写读文件。这时基于内存的Spark出现了,Spark是替代MR的,它会为SQL生成有向无环图,加上各种算子和宽窄依赖的优化,使得计算速度达到了新的高度。
快递员每天都只给你派送一件快递,你拿到之后钱货两清。然后突然一天快递员给你送一千件到你楼下,你下楼一件一件搬,快递员还得等你搬完才能回去,这得等到啥时候。聪明的你马上想到了,放快递柜呀,你有时间慢慢搬不就行了,也不占用快递员的时间了。
这就是消息队列,Kafka就是起这样的作用:异步、解耦、消峰。数据一般会抛到kafka或RocketMQ,可以保存一段时间。然后下游程序再去实时拉取消息来计算。
Spark Streaming则是实时数据来一小批,它就处理一小批。所以本质上讲,Spark Streaming 还是批处理,只不过是每一批数据很少,并且处理很及时,从而达到实时计算的目的。
真正世界里的实时数据肯定不是像Spark Streaming 那样一批一批来的,而是一个一个的事件。对此,Flink帮助我们解决了这些问题。
流计算的思路是,如果要达到更实时的更新,我何不在数据流进来的时候就处理了?比如还是词频统计的例子,我的数据流是一个一个的词,我就让他们一边流过,一边开始统计了。流计算很牛逼,基本无延迟,但是它的短处是,不灵活,你想要统计的东西必须预先知道,毕竟数据流过就没了,你没算的东西就无法补算了。因此它是个很好的东西,但是无法替代数据仓库和批处理系统。
KV Store就是说,我有一堆键值,我能很快速滴获取与这个Key绑定的数据。比如我用身份证号,能取到你的身份数据。这个动作用MapReduce也能完成,但是很可能要扫描整个数据集。而KV Store专用来处理这个操作,所有存和取都专门为此优化了。
KV Store的理念是,基本无法处理复杂的计算,大多没法JOIN,也许没法聚合,没有强一致性保证(不同数据分布在不同机器上,你每次读取也许会读到不同的结果,也无法处理类似银行转账那样的强一致性要求的操作)。但是丫就是快。极快。
https://www.zhihu.com/question/27974418
如何用形象的比喻描述大数据的技术生态?Hadoop、Hive、Spark 之间是什么关系?
参考
hadoop那个年代,网络和io设备性能很差,分布式系统的架构比具体用什么语言实现更重要,用Java实现hadoop也可以理解。现在这些硬件都大幅更新了,瓶颈会逐步转移到内存和计算,cpp会重新占领基础设施。
https://mp.weixin.qq.com/s/Koz2xOnmVgKFeCr2Xqe9VQ
YARN,母系社会的运行架构
https://mp.weixin.qq.com/s/goXmXMc8JyAgU_GKyWXDzw
白话Hadoop架构原理
https://mp.weixin.qq.com/s/s-kOquVbIuJAMSQqkfmaAA
Hadoop之HDFS简介
https://mp.weixin.qq.com/s/0qgaJnZjYsf0WP2z5yGgrg
面试集锦:HDFS
https://mp.weixin.qq.com/s/9A0z0S9IthG6j8pZe6gCnw
YARN在字节跳动的优化与实践
https://mp.weixin.qq.com/s/6rtkmwjfI_Cl-hYMrDOOyA
取代HDFS?Ozone在腾讯的最新研究进展
https://mp.weixin.qq.com/s/_AumiAx9wbpOZCGMdf0Arw
字节跳动10万节点HDFS集群多机房架构演进之路
https://www.zhihu.com/question/303101438
mapreduce为什么被淘汰了?

您的打赏,是对我的鼓励
