AI » CUDA(二)
2025-02-27 :: 6271 WordsCUDA
Warp(续)
Warp采用下图的策略来调度thread:

- Stalled:由于指令/数据没有准备好,或者其他原因,导致thread处于等待的状态。
- Eligible:万事俱备,只待执行。
- Selected:被选中执行的thread。
https://zhuanlan.zhihu.com/p/266633373
详解CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid
https://www.zhihu.com/question/35361192
CUDA为什么要分线程块和线程网格?
https://www.zhihu.com/question/652642080
CUDA如何调度kernel到指定的SM?
https://zhuanlan.zhihu.com/p/1937580325774526286
GPU硬件调度:从TBS到Warp调度器
Warp函数通过直接操作线程的寄存器来实现数据交换,而不是通过内存访问。因此,数据交换非常快速,延迟极低。
https://zhuanlan.zhihu.com/p/669917716
束内表决函数(Warp Vote Function)
https://zhuanlan.zhihu.com/p/669957986
束内洗牌函数(Warp Shuffle Functions)
https://zhuanlan.zhihu.com/p/670290502
束内匹配函数(Warp Match Functions)
https://zhuanlan.zhihu.com/p/670534280
束内规约函数(Warp Reduce Functions)
https://zhuanlan.zhihu.com/p/652255520
束内规约与块内规约问题
https://zhuanlan.zhihu.com/p/646998011
CUDA编程中的并行规约问题
Warp Specialization:在同一个线程块内,让不同的Warp承担不同的专门角色/任务,形成生产者-消费者流水线,从而最大化硬件利用率和隐藏延迟。
在早期的GPU上可以手动用分支实现,而在新的GPU上,越往后异步计算的部分越多。
__global__ void warp_specialization_kernel(int* global_mem) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (threadIdx.x < 32) {
// Producer warp
} else {
// Consumer warp
}
}
和warp内的分支会导致warp divergence不同,不同的warp的分支是没有这个性能问题的。
pingpong就是N=2的multi-stage,所以这个问题等价于为什么在Ampere NStage=2不够了。
Warp-Specialization的优势是在计算访存流水上的调度更灵活,劣势是代码写起来更麻烦。直到Ampere它的优势都不足以让人忍受它的劣势,而Hopper上Warp-Specialization变成了一种必须要使用的技术。
Warp Specialization本质就是SIMD,多线程的消费者-生产者模型,英伟达早已悄悄实现SIMT+SIMD混编架构,并且无缝切换。
NV为了做好Warp Specialization,还添加了寄存器动态分配/回收的功能:整个SM一个大寄存器池,Warp之间完全动态借还;Producer释放的寄存器,Consumer立刻能用。
https://www.zhihu.com/question/11261005710
为什么Hopper架构上warp-specialization比multi-stage要好?
CTA:Cooperative Thread Array,即协作线程数组。它是由一组线程组成的集合,这些线程可以执行相同的程序,并且能够相互通信。CTA是CUDA中线程组织的基本单元,通常被称为线程块(Thread Block)。
CTA提供了同步点,允许开发者在需要时对CTA内的所有线程进行同步,例如使用__syncthreads()函数。
和Thread Block密切相关的概念还有Data Block,用于规划数据的访存。
Ampere及之前:Grid → CTA → Warp → Thread
Hopper/Blackwell:Grid → CTA → Warpgroup → Warp → Thread
新增的Warpgroup做为Tensor Core的编程接口单位。
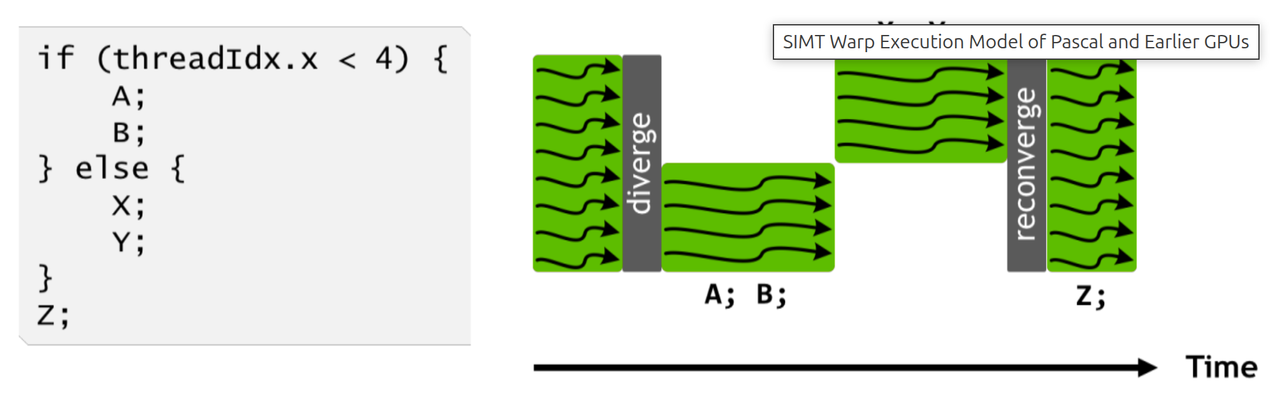
Volta之前:隐式warp lockstep
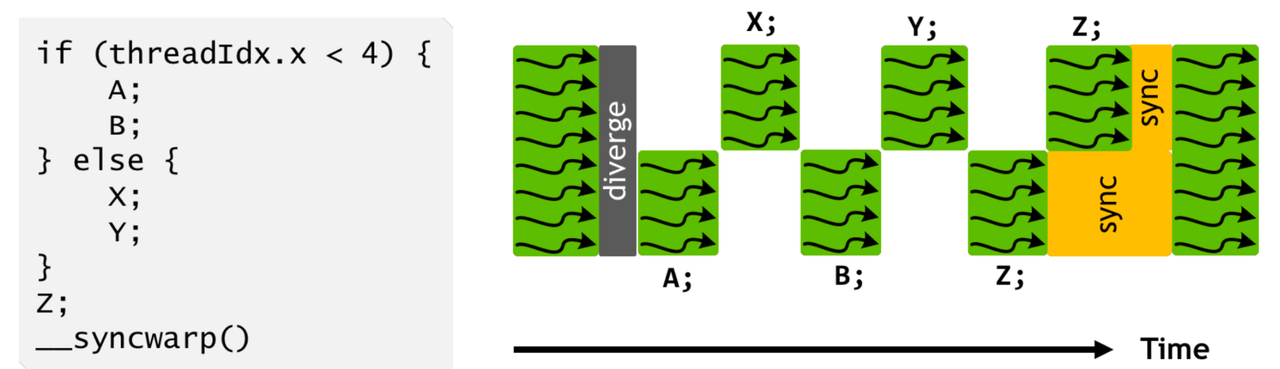
Volta之后:ITS下的execution split
Memory Coalescing
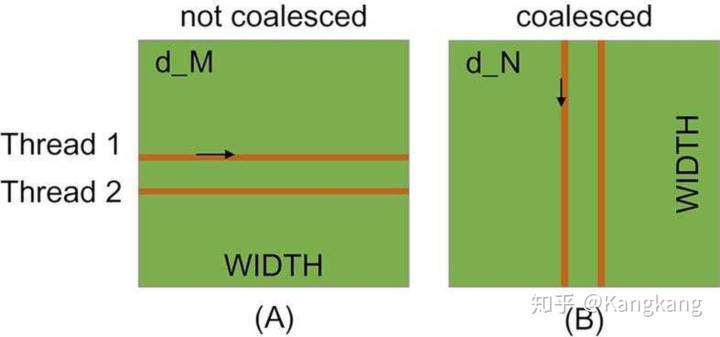
Memory Coalescing合并发生在不同线程之间,而不是线程内部的不同迭代之间。
warp中的所有线程都执行相同的指令,它们在任何时候都在同时执行第k次迭代。因此,一个线程在其生命周期内是否读取整行数据并不重要。重要的是,wrap内的所有线程在每次内存访问时可以合并。
在上图中,矩阵M内存访问模式是低效的,而矩阵N的访问模型是高效的。
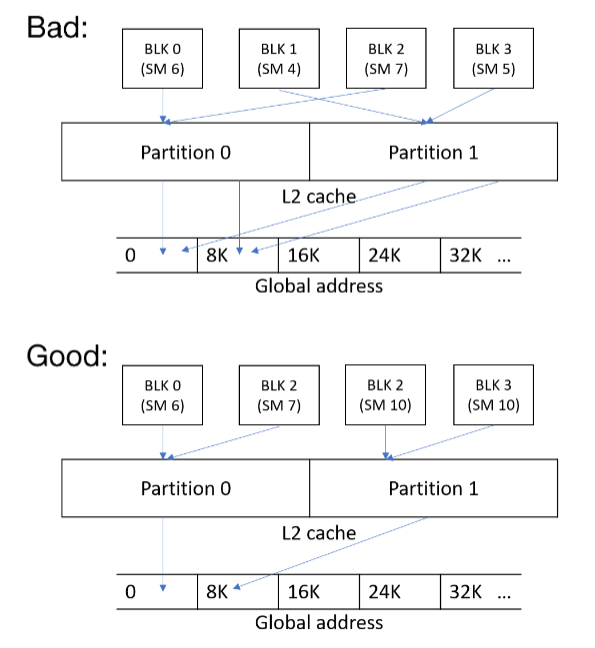
在更高层的L2 Cache上也有类似的情况:
Async Proxy
Async Proxy是Hopper架构中专门处理异步操作的硬件代理(agent),涵盖TMA、WGMMA、DSMEM等所有异步操作。
Debug
nvcc -g -G -o test metrixMul.cu
-g: debug host code.-G: debug device code.
给VSCode安装Nsight扩展。
launch.json:
{
"name": "CUDA C++: Launch",
"type": "cuda-gdb",
"request": "launch",
"program": "${fileDirname}/test",
}
https://zhuanlan.zhihu.com/p/508810115
Visual Studio Code的CUDA环境
Profile
NVIDIA System Management Interface (NSMI): 即nvidia-smi。
NVIDIA Nsight Systems (NSYS)
NVIDIA Data Center GPU Manager (DCGM)
NVIDIA Management Library (NVML): NVML为GPU硬件数据提供了编程接口,开发者可以通过编程的方式访问GPU的各项数据,其中就包含GPU利用率,nvidia-smi和DCGM的背后就是NVML,推荐高级开发者使用。
cuda的调试主要使用ncu和nsys两个工具。
NCU侧重于内核级别的性能分析,例如显示不同block size内核函数的执行时间、执行的吞吐量、带宽分析等。
而Nsight System提供了更全面的系统级性能分析。包括CPU和GPU之间的交互、内存操作、内核执行时间等。它可以帮助开发者发现性能瓶颈,例如GPU饥饿、不必要的GPU同步、CPU并行度不足等问题。还提供了对多节点性能的分析,这对于数据中心和集群环境中的性能优化尤为重要。
nsys的UI版本的可执行文件名字叫做nsys-ui,同理还有ncu-ui。
官方文档:
https://docs.nvidia.com/nsight-systems
https://docs.nvidia.com/nsight-compute
显存被占用,但是nvidia-smi里看不到进程:
sudo fuser -v /dev/nvidia*
kill所有使用显卡的进程即可。
nsys profile /data/miniforge3/envs/torch_3.12/bin/python3.12 -m llm_train
Occupancy = 当前活跃warp数 / SM支持的最多warp数
GEMM是典型的计算密集型算子,每个线程需要大量寄存器来缓存矩阵块(tile),导致每个block的线程数受限。
https://fkong.tech/posts/2023-11-19-torch-gpu-util/
如何把PyTorch的GPU利用率提升到100%?
https://dev-discuss.pytorch.org/t/using-nsight-systems-to-profile-gpu-workload
Using Nsight Systems to profile GPU workload
https://blog.csdn.net/m0_61864577/article/details/140618800
NsightComputeProfiling入门
https://blog.csdn.net/weixin_40777649/article/details/140379222
nsightcompute进阶
https://zhuanlan.zhihu.com/p/2007511954252653705
TCA51%,MFU不足8%——GPU的隐藏性能损耗
https://zhuanlan.zhihu.com/p/1981436859470074335
推理性能优化:GPU/NPU Profiling阅读引导
Sparse Matrix
从Ampere架构之后,NV引入了Sparse Matrix。它的具体格式如下图所示:
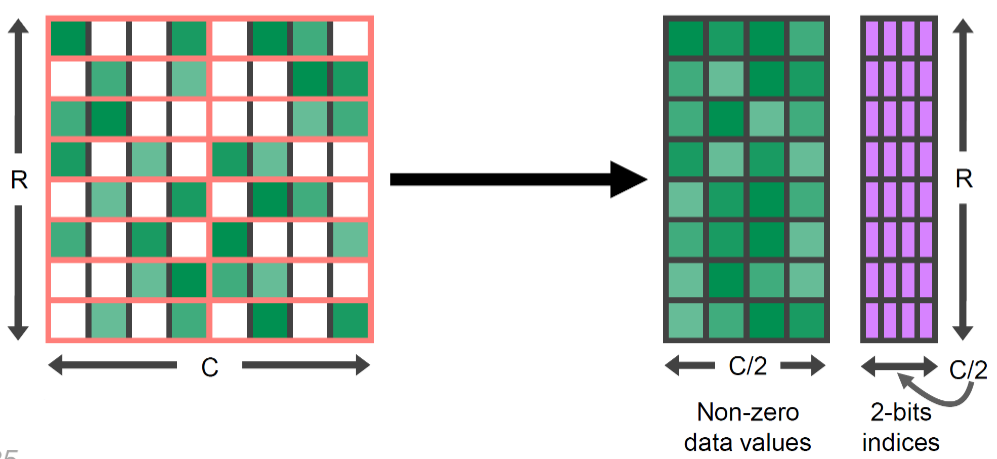
这里要求每4个连续的值里,最多有2个非0值,也被称为2:4稀疏。
Multi Stream
Hyper-Q是GPU从Kepler架构后,Nvidia提出的硬件特性,允许多个CPU线程或进程同时加载任务到一个GPU上,实现CUDA kernels的并发执行。
CUDA实战
安装:
http://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
GPU版本的leetCode:
https://www.leetgpu.com/
${CUDA_HOME}/targets/x86_64-linux/lib/stubs/文件夹下有常见的libcuda.so、libcublas.so等动态链接库,但是里面只有函数名,没有函数实现。所以文件大小很小。当我们的代码在一台没有GPU的机器上编译时,可以动态链接到这些stubs库,这样就能够正常编译。编译结束得到的二进制文件可以部署到其它有GPU的机器,在运行时它们就会链接到正确的动态链接库。
vectorAdd<<<4096, 256, 0, s0>>>表示内核函数vectorAdd将在GPU上以4096个块执行,每个块包含256个线程,总共有4096x256个线程。
0表示为这个内核函数分配的动态共享内存的大小,单位是字节。s0指定关联的stream。
遇到cudaXX找不到:
export CPATH=/usr/local/cuda/targets/x86_64-linux/include:$CPATH
export LD_LIBRARY_PATH=/usr/local/cuda/targets/x86_64-linux/lib:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda/bin:$PATH
nvcc编译cuda程序,不运行device(GPU)部分代码的解决方案:指定GPU的arch。
nvcc ./xxx.cu -o xxx -arch sm_90 -Wno-deprecated-gpu-targets
执行环境标识符:
__global__:在CPU调用父函数,子函数在GPU执行(异步)。用__global__修饰的一般就是内核(kernel)函数。__device__:在GPU调用父函数,子函数在GPU执行。 由__device__修饰的函数可以被由__global__和__device__修饰的函数调用。__host__:在CPU调用父函数,子函数在CPU执行。
__global__函数的参数可以使用结构体,但有一些限制和注意事项:
-
结构体必须是简单结构体(POD类型):这意味着结构体不能包含构造函数、虚函数或继承。
-
需要在GPU上分配结构体内存:通常需要在GPU上分配结构体的内存,并将数据从主机端复制到设备。
// 没有 __restrict__,编译器不知道a和b是否指向同一地址
__global__ void add(int* a, int* b, int* c, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
c[i] = a[i] + b[i]; // 编译器:不确定 a[i] 和 c[i-1] 是否重叠,需保守处理
}
}
// 明确告诉编译器:a、b、c 指向的内存互不重叠
__global__ void add(int* __restrict__ a,
int* __restrict__ b,
int* __restrict__ c, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
c[i] = a[i] + b[i]; // 编译器可以放心优化,缓存值到寄存器
}
}
https://developer.download.nvidia.cn/assets/cuda/files/NVIDIA-CUDA-Floating-Point.pdf
IEEE 754 mode(default): -ftz=false -prec-div=true -prec-sqrt=true
fast mode: -ftz=true -prec-div=false -prec-sqrt=false
在fast模式中,非规格化数将被转换为零,并且除法和平方根运算不会被计算到最接近的真实值的浮点数值。
当浮点异常发生时,NVIDIA的GPU不会触发trap handlers,也没有指示上溢、下溢或者denormal的标志位。
#pragma unroll指令建议编译器完全展开for循环。如果N是一个常量,编译器会尝试将循环体展开N次。如果N不是一个常量或者太大而无法完全展开,编译器可能会忽略这个指令,或者展开一定次数的迭代。

您的打赏,是对我的鼓励
