AI » CUDA(一)
2024-09-09 :: 5953 WordsCUDA
CUDA是NVIDIA最早推出的通用数学运算库。除了基本的数学运算之外,还提供了一些工具包:
cuBLAS:线性计算库。除了基本版的API之外,它还包括以下扩展:
- cuBLASXt适合处理非常大的矩阵和多GPU操作。
- cuBLASLt提供了一定程度的灵活性,适合中等大小的矩阵。
- cuBLASDx则提供了更高的灵活性和控制,适合在设备端执行小规模的矩阵操作和融合操作。
NVBLAS:多GPU版的cuBLAS。
cuFFT:FFT计算库。
nvGRAPH:图计算库。(这里的图是数学图论中的图,和DL框架中的计算图是两回事。)
cuRAND:随机数生成库。
官方文档:
https://docs.nvidia.com/cuda/pdf/CURAND_Library.pdf
cuSPARSE;稀疏矩阵计算库。
cuSOLVER:解线性方程的计算库。包括解稠密方程的cuSolverDN、解稀疏方程的cuSolverSP和矩阵分解的cuSolverRF。
官方文档:
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
https://github.com/nvidia/cccl
CUDA Core Compute Libraries (CCCL)
https://cuda.godbolt.org/
nvcc online compiler
NVIDIA DALI
NVIDIA DALI是一个GPU加速的数据增强和图像加载库,为优化深度学习框架数据pipeline而设计,而其中的NVIDIA nvJPEG是用于JPEG解码的高性能GPU加速库。
代码:
https://github.com/NVIDIA/dali
Tensor Core
Tensor Core是Nvidia GPU自Volta架构开始,专门为深度学习矩阵运算设计的计算单元。
CUTLASS:另一个线性计算库,专为Tensor Core设计。
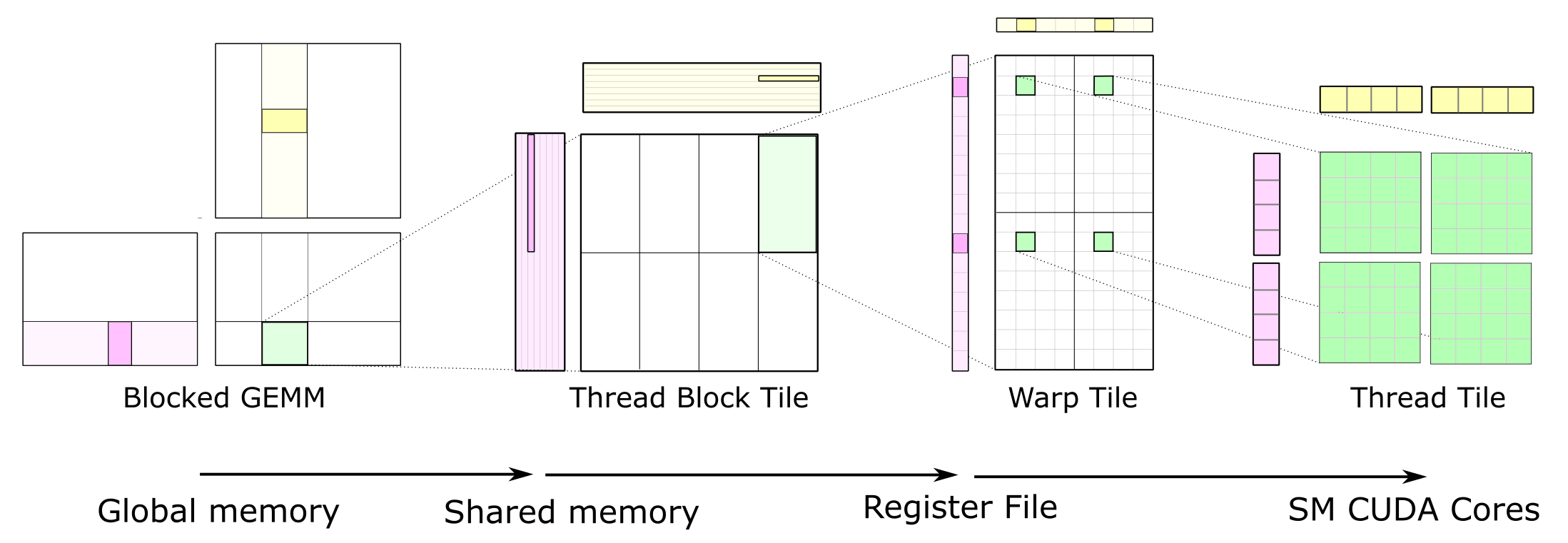
类似的东西还有Arm的SME、Intel的AMX等。

CUTLASS主要基于以下指令:
- MMA(Matrix Multiply-Accumulate)
- WMMA(Warp Matrix Multiply-Accumulate):WMMA是针对Tensor Core设计的,它在warp级别(即32个线程)上执行矩阵乘法运算。
- WGMMA(Warp Group Matrix Multiply-Accumulate):WGMMA是WMMA的扩展,提供了更广泛的矩阵尺寸和数据类型的支持。对并行计算的控制也更为精细。
- TMA(Tensor Memory Accelerator):用于在global memory和shared memory之间搬运数据。
- BMMA(Binary Matrix Multiply-Accumulate):提供按位操作的矩阵乘法。
- UMMA(Unified Mixed-precision Matrix-multiply Accumulate)
- MMA时代的mma.sync是同步指令,导致计算流水线和访存流水线必须严格耦合。编译器必须插入大量的DEPBAR(依赖栅栏)或者依靠硬件Scoreboard阻塞,导致指令发射(Issue)停顿。
- WGMMA时代的wgmma.mma_async利用mbarrier实现生产者-消费者模型。Warp依然需要发射指令,但计算在后台运行。这使得Warp可以继续发射Global Memory Load (TMA) 指令,真正实现了 Compute-Memory Overlap。
- UMMA时代的tcgen05彻底变成一条标量指令,它使用过程中不占用Warp的发射槽位,就类似于给Tensor Core挂载了一个独立的DMA引擎。一旦配置好,Tensor Engine独立运转,SM中的Warp可以去处理完全不相关的其他指令。
在这个过程中,计算粒度从warp(32 thread)->warp group(4x32thread)->Single-Thread Orchestration。
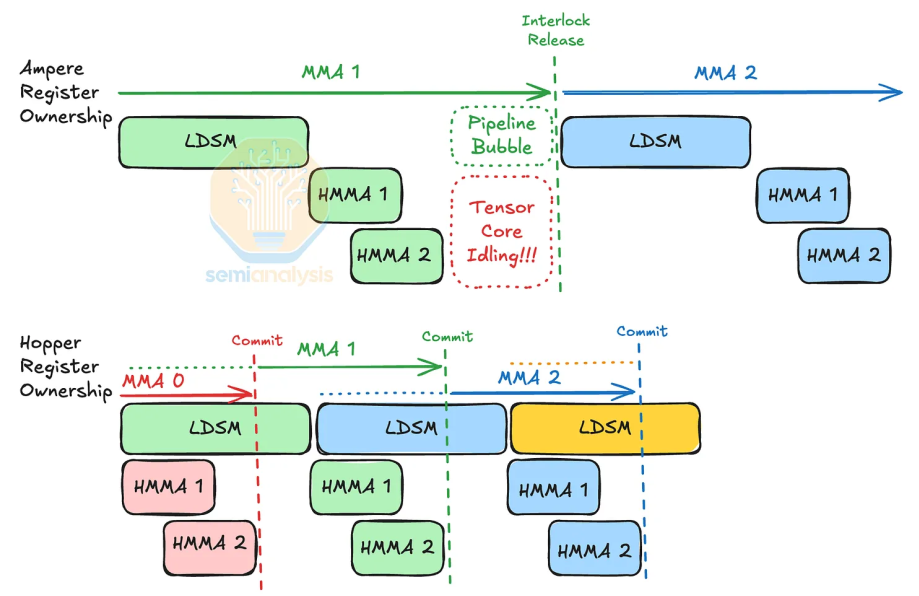
Blackwell架构里的Tensor Memory(TMEM)是一块专门为第五代Tensor Core运算设计的片上SRAM,位于每个SM内部,容量256 KB,大小与SM的寄存器文件相当。用于存放MMA指令的输入矩阵A和输出矩阵D,替代寄存器保存累加器,极大的缓解了寄存器的压力。
warp指令:一条被warp内32个线程集体发射、在SIMD流水线上锁步(lock-step)执行的指令。只要warp里任意一条线程被阻塞(例如访存等待),整条warp指令就暂停,32线程一起等待——这就是SIMT的“掩码+锁步”执行模型。
标量指令:它的“发射许可”不再检查“当前warp的32线程是否都到达”,而是任意一条线程跑到这条指令时,就可以独自把一次矩阵运算请求丢给Tensor Core,然后继续往下走。其他线程即使因为分支divergence没跑到这里,也不会阻塞这次提交。
https://www.zhihu.com/question/10639310321
如何看待第5代Tensor Core?
CuTe,全称为”collection of C++ CUDA template abstractions for defining and operating on hierarchically multidimensional layouts of threads and data”,是一个处理嵌套layout的模板抽象的集合,其并不提供现成算子支持,而是给出数据结构,使得复杂的线性代数计算得以加速。
https://dingfen.github.io/2024/08/18/2024-8-18-cute/
深入CUTLASS之CuTe详解
https://zhuanlan.zhihu.com/p/699255051
cute TiledMMA
Linear Layouts: Robust Code Generation of Efficient Tensor Computation Using F2
这篇论文使用F2群上的计算,来寻找register->thread->warp并行模型下的最优数据layout。
https://mp.weixin.qq.com/s/PDFshzgcj_udaFu3aJr1tQ
该论文的中文版
参考:
https://mp.weixin.qq.com/s/pPjPLqgXZ8iCPS42vXJpuQ
NVIDIA Tensor Core深度学习核心解析
https://mp.weixin.qq.com/s/Qfbc2iQnXacOqOGIrpRQRw
Tensor Core究竟有多快?全面对比英伟达Tesla V100/P100的RNN加速能力
https://www.zhihu.com/question/451127498
英伟达GPU的tensor core和cuda core是什么区别?
https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/
CUTLASS: Fast Linear Algebra in CUDA C++
https://zhuanlan.zhihu.com/p/663092747
cute之MMA抽象
https://zhuanlan.zhihu.com/p/712451053
cutlass GEMM流水线——single-stage、pipelined、multi-stage
https://research.colfax-intl.com/cutlass-tutorial-wgmma-hopper/
CUTLASS Tutorial: Fast Matrix-Multiplication with WGMMA on NVIDIA® Hopper™ GPUs
https://zhuanlan.zhihu.com/p/1945136522455122713
NVIDIA TMA全面分析
https://www.aleksagordic.com/blog/matmul
Inside NVIDIA GPUs: Anatomy of high performance matmul kernels
https://zhuanlan.zhihu.com/p/1996740631024924636
Swizzle工作原理
https://www.zhihu.com/question/667972067
cuda的swizzle是怎么实现bank conflict free的?
https://zhuanlan.zhihu.com/p/2007020183127094121
Blackwell Gemm实现
https://zhuanlan.zhihu.com/p/2007758781354897660
CUTLASS 教程:Blackwell GEMM-使用线程块cluster
Tile IR
Tile based的编程,逐渐替代传统的SIMT编程,成为LLM时代的首选。
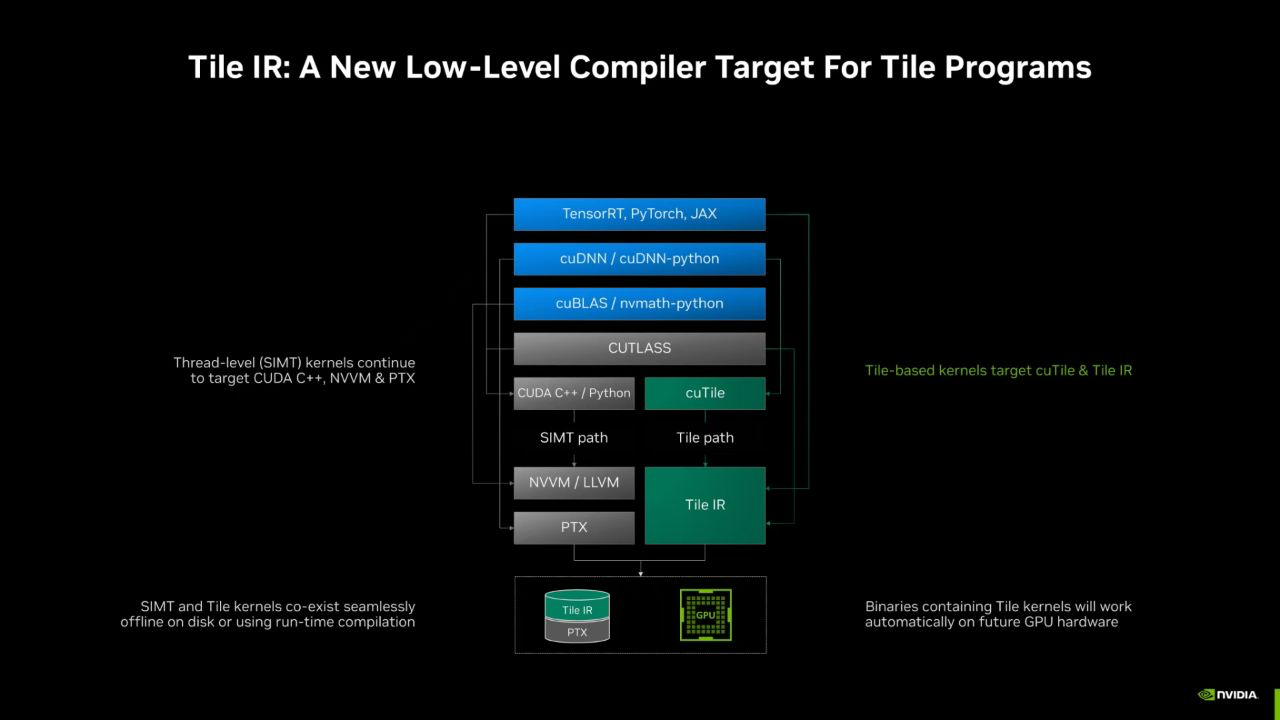
PTX
PTX (Parallel Thread Execution) 是NVIDIA GPU的伪指令集,之所以加个伪字,主要是因为这个指令集并不是真的硬件指令集,而仅仅是个抽象指令集。
该抽象指令集可以屏蔽不同架构显卡之间的指令差异。

nvvm ir->PTX->SASS->runtime/jit->片上调度。
官网:
https://docs.nvidia.com/cuda/parallel-thread-execution/index.html
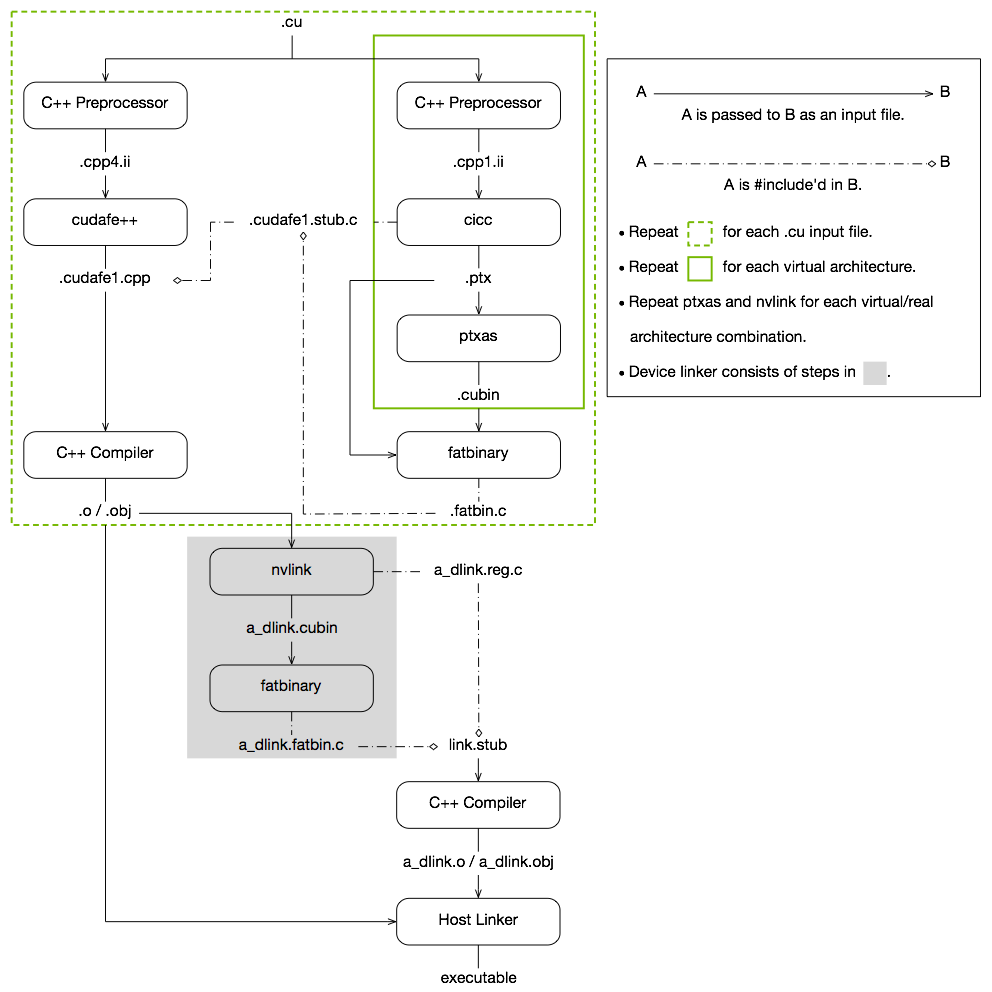
gcc和llvm都有特定的pass可以生成PTX代码。
CICC(CUDA Integrated Compiler Command)是CUDA Toolkit中的一个编译器组件,它负责将CUDA代码编译成PTX代码。
cudafe++是CUDA编译过程中的一个组件,它的主要作用是将CUDA特有的C++扩展转换成标准C++结构。
ptxas:和gcc中的as类似,也是一个汇编器。ptxas的作用是将PTX代码编译成SASS(Streaming Assembler)代码。
nvrtc:Runtime Compilation Library,用于在程序运行阶段把CUDA C++源码(以字符串形式给出)即时编译成PTX或CUBIN,从而无需事先用nvcc离线编译即可加载并执行GPU内核。
官方文档:
https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html
NVIDIA GPU真正的指令集,被称作SASS。
和.ptx文件相对应,SASS的二进制格式为.cubin文件。但是由于后者是真正的硬件指令,在各架构之间不通用,所以还有一个.fatbin文件,可以打包不同架构的bin。
https://zhuanlan.zhihu.com/p/161624982
SASS指令集概述
https://www.zhihu.com/question/639210103
为什么没人去做CUDA逆向和反编译?
Thrust
Thrust是一个C++库,它提供了对GPU加速并行算法的便捷访问。
它对标的是STL和TBB(Threading Building Blocks),后者是Intel开源的并行计算的C++模板库。
CUB是一个底层CUDA C++模板库,为CUDA开发者提供可组合、高性能的原语,提供了Scan、Sort、Reduce、Histogram等操作的模板。
Thrust的底层实际调用CUB进行优化。
访存
从Ampere架构开始,引入了异步访存指令。
同步版本的流水线访存就是ld.global到registers,然后st.shared写入到共享内存,它们都会阻塞计算指令,但是warp scheduler会通过warp切换,让其他已经eligible的warp继续执行(本质上还是ILP),因此,一般同步版本最多开双流水(double-buffer),因为需要额外的寄存器进行prefetch,占用率不会太高,计算没法更好地掩盖访存的延迟。
异步版本是硬件层面的异步指令(cp/store.async),本身计算和访存单元就是可以独立运行的,有了异步层级的指令支持后,可以充分发挥这一特点,指令不会阻塞计算指令,但是需要fence/barrier等同步手段,因此,warp可以继续执行下去(如果条件允许),此外,这些指令需要消耗额外的寄存器进行预取,直接global->shared或者shared->global,一般可以开2-4条流水。
https://zhuanlan.zhihu.com/p/709750258
Tensor Memory Access(TMA)
Device to Device (DtoD):指的是在单个GPU内部进行的内存拷贝。
Peer to Peer (PtoP):指的是从一个GPU到另一个GPU的内存拷贝,这种情况仅发生在多GPU系统中。
RR (Read-Read):表示连续的读操作。
RW (Read-Write):表示读写混合操作。
Generic Addr是一种不携带任何状态或附加信息来声明它属于哪个状态空间的指针。在CUDA C++中,与C++一样,指针就是指针,它们没有额外的装饰或元信息。在PTX或SASS中,CUDA GPU具有状态空间系统,这是一种分区寻址结构。例如,shared就是一个状态空间。
Warp
在织布机上,warp(经线)是纵向固定、张力较高的主线,它们平行排列在织机上。weft/weave(纬线)是横向穿梭交织的线。纺织业是人类历史上最早的大规模并行处理技术。
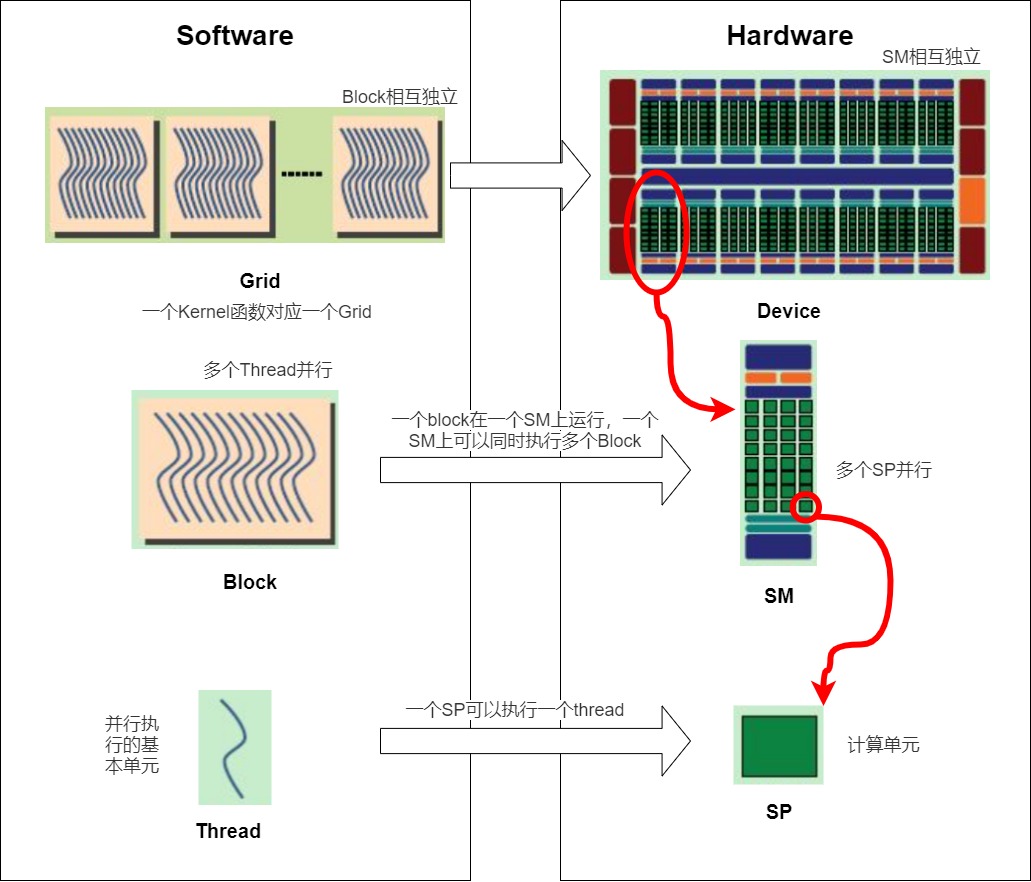
一个SP可以执行一个thread,但是实际上并不是所有的thread能够在同一时刻执行。Nvidia把32个threads组成一个warp,warp是调度和运行的基本单元。warp中所有threads并行的执行相同的指令。

您的打赏,是对我的鼓励
