Attention » Large Language Model(五)——1M context, 大力出奇迹, LLM Architecture, VLM
2025-09-12 :: 4988 WordsMoE
Expert Parallelism(续)
AMD和Red Hat的实践都强调过,专家铺得越开,跨节点通信的故障半径就越大,一个节点出问题可能拖垮一片。所以生产上反而倾向于用不太大的EP组,把Prefill和Decode的路径严格隔离开。
KTransformer
KTransformers由清华大学团队提出,可以在模型运行过程中灵活的将专家模型加载到CPU上,同时将MLA/KVCache卸载到GPU上,从而深度挖掘硬件性能,实现更低的显存运行更大尺寸的模型。
参考:
KTransformer部署高性能DeepSeek R1模型实战
1M context
目前(2026年)主流模型的context长度一般在128K以上,新出的模型普遍都在1M以上。
多模态、Agent都是消耗token的大户,即使1M也未必是终点。短序列时代,Attn后面的FFN占用了80%的计算量,然而到了LLM的长序列时代,Attn开始占据计算量的大头。
CSA & HCA
CSA:Compressed Sparse Attention
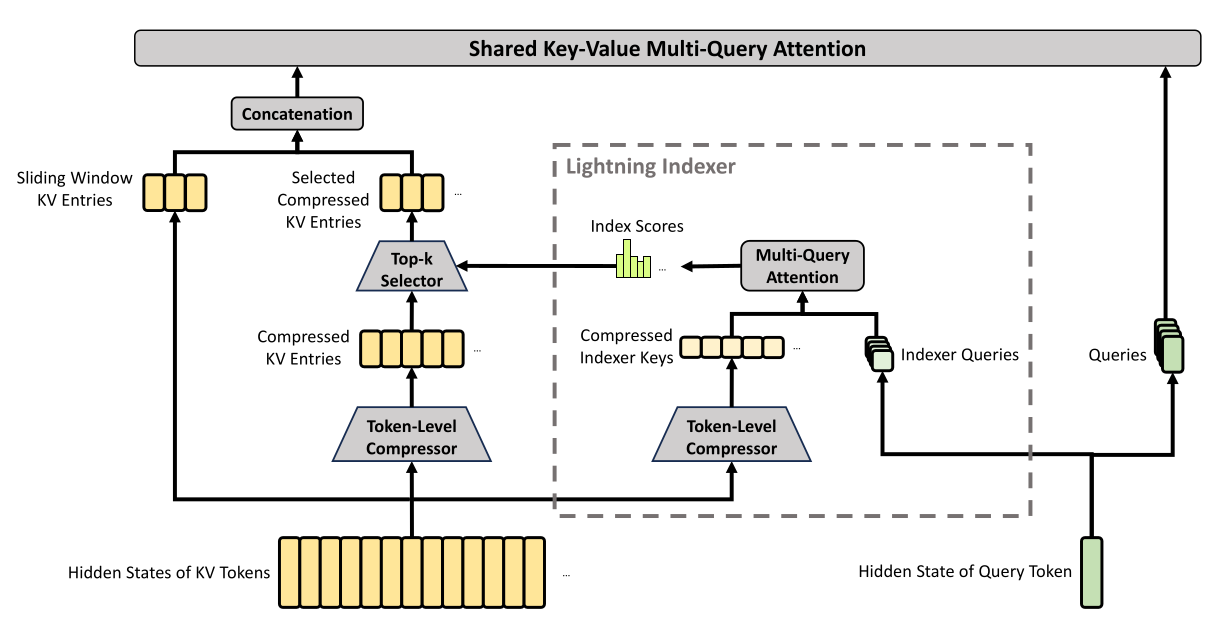
CSA首先将每m个令牌的KV Cache压缩为一个条目,随后应用DeepSeek稀疏注意力实现进一步加速。
HCA:Heavily Compressed Attention
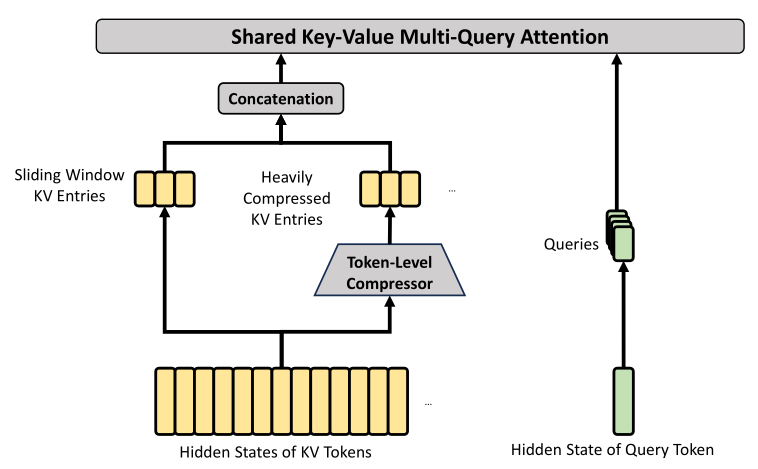
HCA采用更激进的KV Cache压缩方式,连DSA都省了。
压缩后的KV Cache和Sliding Window之后最近的KV Cache一道送入MQA,这从原理上等效于,保留最近的N个token,再压缩历史token。这样便可兼顾长短期的记忆。
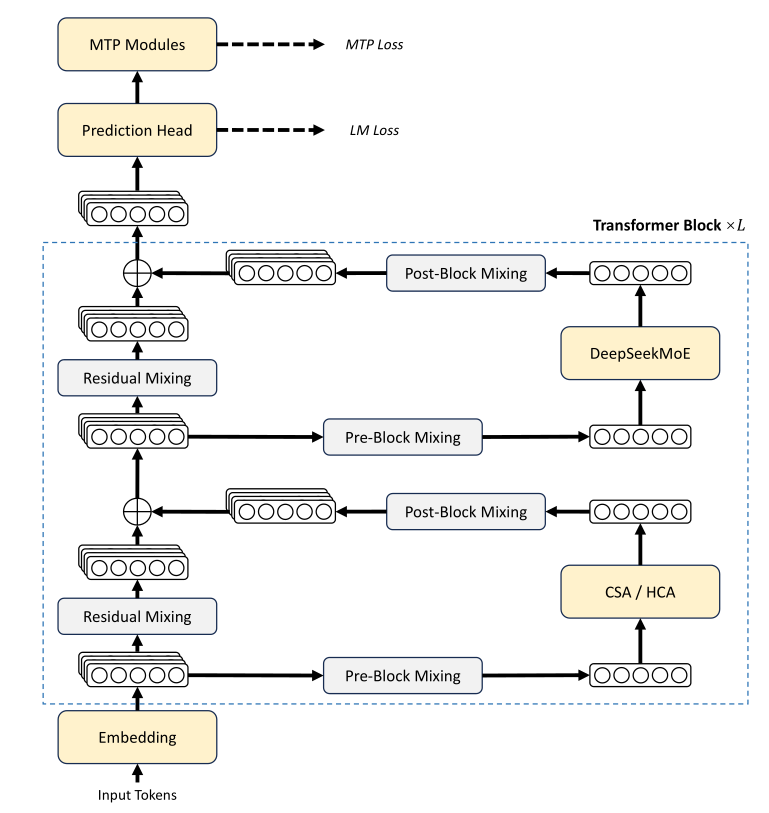
上图是DeepSeek v4的网络结构图,DeepSeek认为交错使用CSA和HCA效果更好。
https://zhuanlan.zhihu.com/p/2031133178354716993
DeepSeek Attention之从V3 MLA到V4 CSA+HCA
MiMo-V2
小米的MiMo-V2采用了另一种方法压缩KV Cache:
Sliding Window Attn开始部分取代Full Attn。小米MiMo-V2-Pro将混合比例从1:5提升至1:7(即8层中1层FA,7层SWA)。SWA没有自己的KV tensor,而是复用FA层的KV tensor,从而大大减少了KV Cache的使用量。
MLA在Chat时代很优秀,也能省KV Cache,对长文也算不错;但MLA是为当时H系列芯片“访存/计算比”做的极致临界设计,导致结构上“没有可发挥空间”。很难再叠加MTP(Multi-Token Prediction)技术来进一步加速推理。
MLA本质上是MQA和MHA之间的折衷,在MQA都被嫌弃不够激进的今天,MLA的前景可想而知了。
MQA/GQA/MLA:仅单层内头维度压缩,时序、层数无优化。
SWA + 多层共享KV + GQA:时序(SWA)+ 层数(层共享)+ 头维度三维压缩
Deepseek v4和小米MiMo-V2对于KV Cache的压缩/复用,将KV Cache缩小到前代的10%,显存消耗只有前代的约2%。
Router
早些年MoE的Router在作为Gate去乘到Expert上时,基本都是用Softmax激活,直到现在它仍是MoE的标准形式之一。不过,为了配合Loss-Free负载均衡,DeepSeek将激活函数改成了Sigmoid,并证明了这也是一个颇有竞争力的方案,这引发了大家对Router形式更深入的思考和尝试。
即便在Softmax内讨论,也有着两种略微不同做法:是先Softmax再选Top-k,还是先选Top-k再Softmax呢?
https://kexue.fm/archives/11782
MoE环游记:9、门控归一化之争
大力出奇迹
Richard Sutton在《苦涩的教训》(2019)中指出:算力是第一性,通用方法 + 大规模计算必然赢过人工设计。
大力出奇迹派主张与其研究网络结构之类的奇技淫巧,不如老老实实的堆算力。
照Sutton的说法就是:“如果没有智能,先把算力翻3个数量级再说,如果还不行,那就6个。”
从严格的科研角度,这些话实际上和骗子/宗教已经没有区别了——你看不见皇帝的新装,那是你不够聪明,你先6个核桃补补脑,而不是怀疑这件衣服。
但是架不住人家一直在赢:从早期深度学习碾压传统机器学习、大模型碾压小模型、MoE超大基座碾压精调小底座,每一次路线之争,最后赢的全是“堆规模、堆算力、堆数据”的大力派。
<1B参数模型:只能完成简单任务,没有涌现能力(emergent abilities)。
1B+参数模型:能胜任聊天、收集资料、编写代码的任务。但是决策并解决问题的能力弱,不能胜任agent之类的生产力任务。例如,debug code时,容易束手无策,或者越改越烂。
1T+参数模型:Agent时代的必选。
聊天不是生产力的刚需,客户付费意愿较低。而Agent则相反,商业客户宁可给高性能AI付出高额费用,也不愿使用廉价的弱智替代品。所以Anthropic营收反超OpenAI。Anthropic的token已经成为战略物资。
zhihu问题:为什么特朗普、孙宇晨、傅盛纷纷入局AI中转站卖Token了?
Pre-train vs Post-train:预训练是”无监督/自监督”在海量文本上学语言规律;后训练是”有监督/强化学习”在精选数据上学行为和偏好。
小米MiMo-V2-Pro技术报告指出他们在Pre-train和Post-train上分配的算力达到1:3。
由于有监督的数据获取成本太高,DRL成为Post-train阶段的显学。
Post-train重要性也不宜夸大。
OpenAI在GPT-4→5阶段刻意放弃“堆规模”,转all in 后训练(RLHF/对齐/推理技巧)。
事实证明这是舍本逐末,结果导致Anthropic拥有了全世界最大的模型。然后一举把vibe coding给打通了。
Anthropic模型有10T参数,Google Gemini有5T参数,国内仅有1T参数。
2026年,大模型竞争重新回到“拼基座规模 + 原生能力”的原点,典型案例:OpenAI的救赎之作GPT-5.5,1.5T参数,还是远远落后于Anthropic。
网友评论:OpenAI的小模型路线吃瘪这一点很少有人知道,这也是检验一个人了解程度的关键细节。GPT-5.5和GPT-5是完完全全不一样路线的模型。
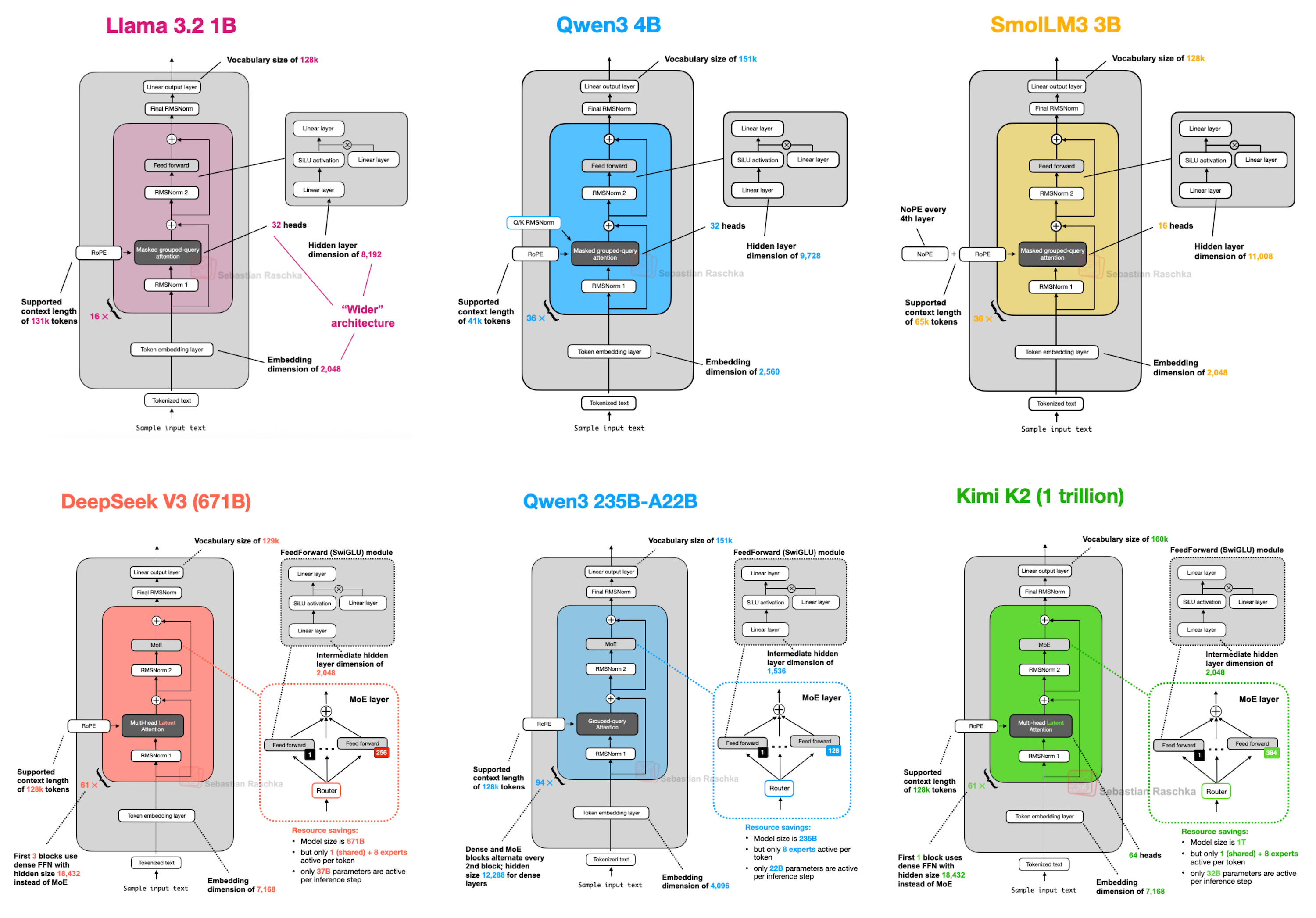
LLM Architecture
https://sebastianraschka.com/blog/2025/the-big-llm-architecture-comparison.html
The Big LLM Architecture Comparison
https://sebastianraschka.com/llm-architecture-gallery/
更多LLM结构图
中文版:
https://zhuanlan.zhihu.com/p/1971937330051940822
2024-2025年开源LLM架构革新全览:MoE、注意力机制与归一化层的进化
LLM命名规则
- VL:Vision-Language
- VLA:Vision-Language-Action
- AVL:Audio-Vision-Language
- E4B:E,Effective有效参数,Dense+PLE。4B,排除嵌入查表权重后,全程参与计算的参数。
- A4B:A, Active激活参数,MoE混合专家。4B,每次token动态路由选中、临时参与计算的专家参数。
Gemma 4
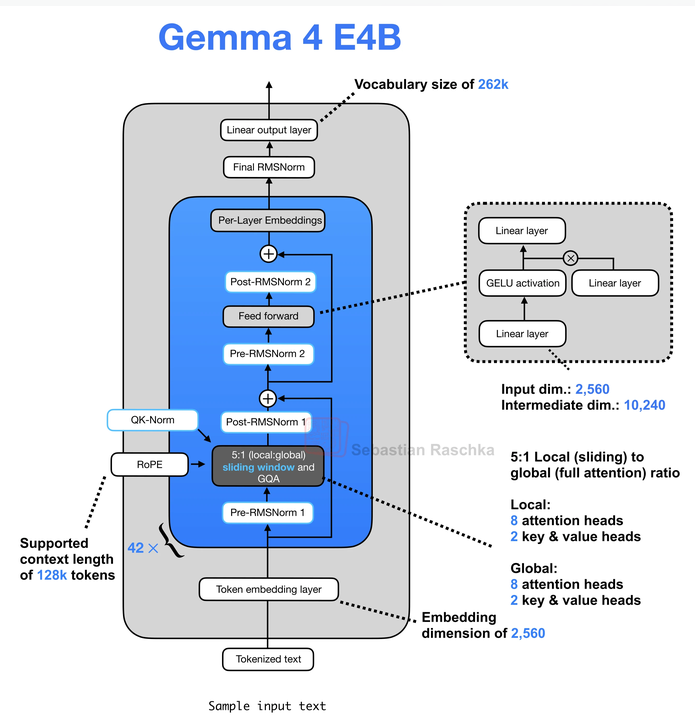
Per-Layer Embedding:
- 常规LLM(Gemma2、LLaMA 等)只有输入头部唯一一张全局嵌入表。
- PLE把超大词表向量存为静态只读查找表。推理阶段根据token ID,直接取出表格里预先存好的浮点向量。
- PLE不是在模型最开头只查一次,而是每一个 Transformer 解码器层,都附带一张小型词嵌入查表。
- 超大PLE嵌入表可以放在手机闪存(UFS/eMMC),不需要全部加载进高速NPU/RAM,用到哪个token就临时读取对应向量,宝贵的高速内存只放需要浮点计算的主干参数。
- MoE实现计算稀疏,PLE实现存储稀疏。
从Gemma4技术报告披露的消融数据可以看出,DeepMind做过稠密+PLE、MoE+传统嵌入、稠密无PLE三组对照,唯独没有公开MoE+PLE的权重,社区推测多半是收益不足以覆盖部署成本。
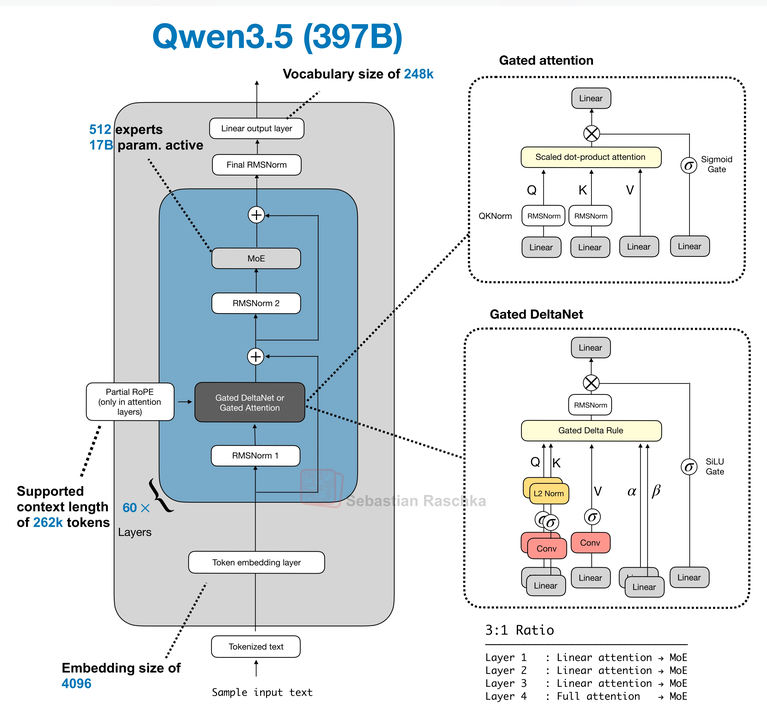
Qwen 3.5
Kimi K2
官方技术报告:
https://moonshotai.github.io/Kimi-K2/
参考:
https://www.zhihu.com/question/1927140506573435010
Kimi发布首个万亿参数开源模型K2模型,哪些信息值得关注?
VLM
https://zhuanlan.zhihu.com/p/702811733
Vision-Language Models (VLMs)多模态大模型一年多的进展与思考-2406
Qwen 2.5-VL
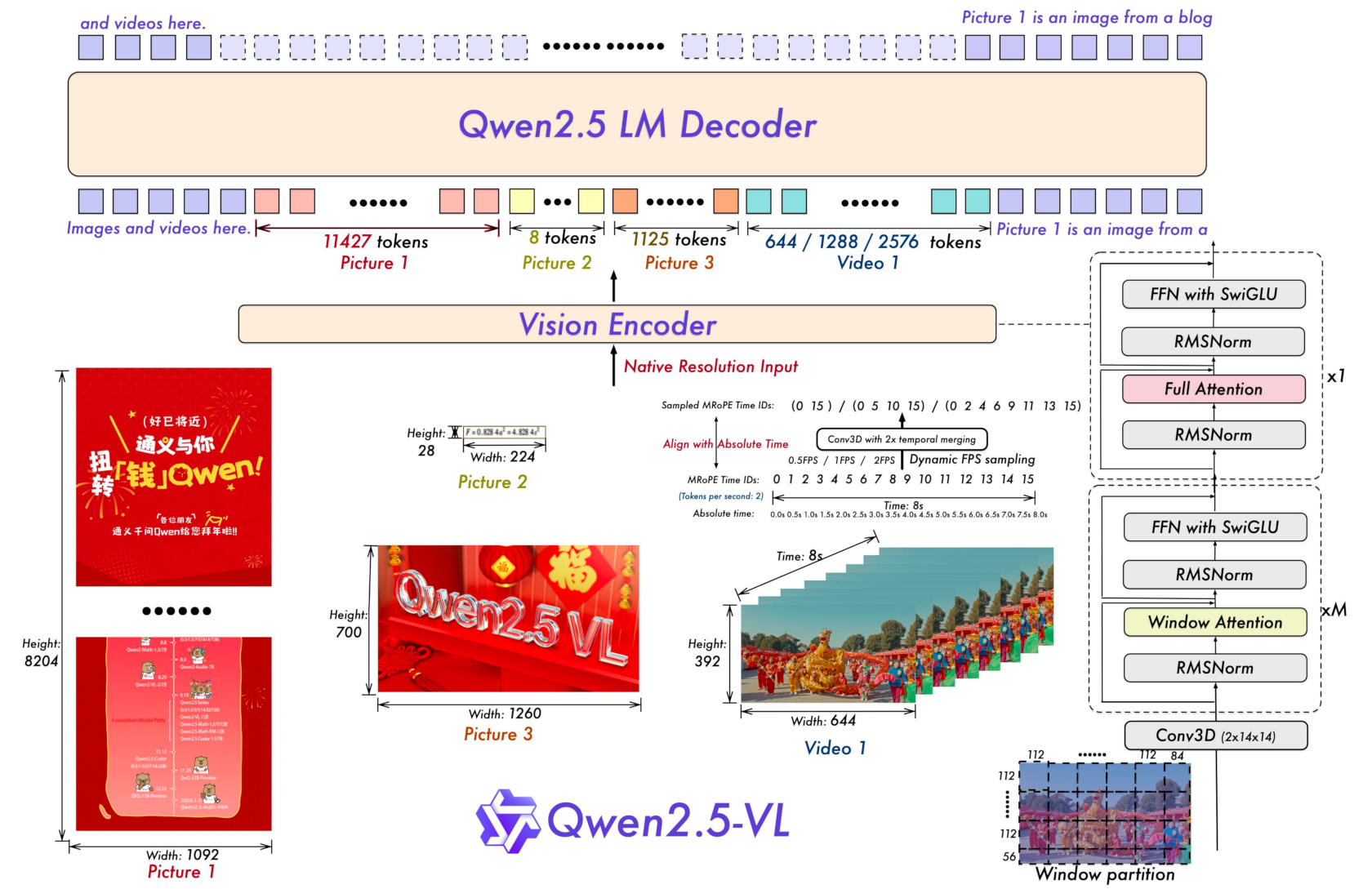
该模型将视觉Token包裹在<|vision_start|>、<|vision_end|>标签内,嵌入文本Token中,实现了对于任意尺寸、数量的图片/视频的支持。
此外该模型还引入了多模态旋转位置嵌入M-RoPE,以更好地处理视频中的时间信息。
https://blog.csdn.net/v_JULY_v/article/details/145560246
一文通透Qwen2.5 VL:从Qwen-VL、Qwen2-VL到Qwen2.5-VL
Qwen 3-VL
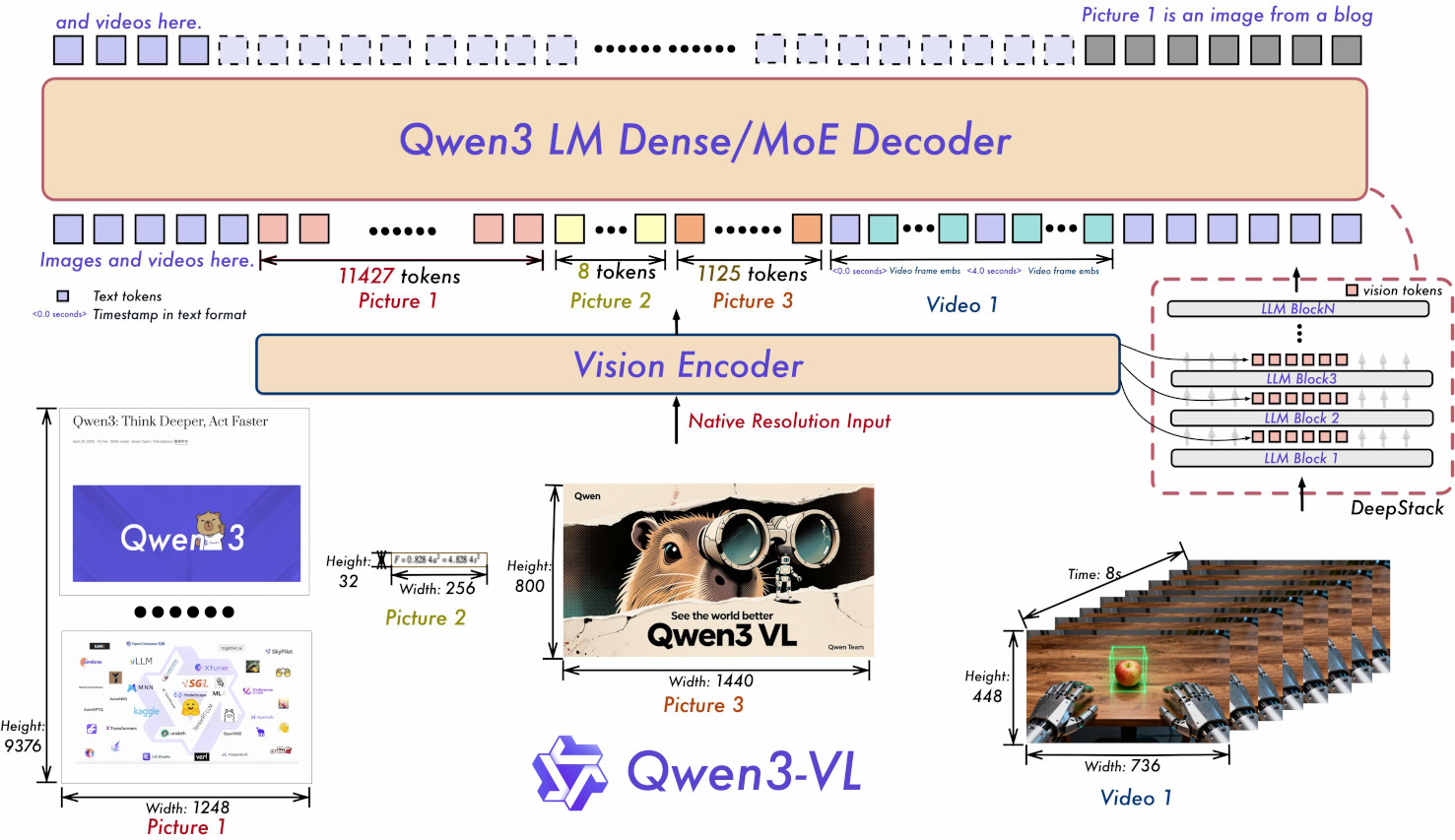
https://blog.csdn.net/v_JULY_v/article/details/160890094
一文通透Qwen3-VL——在交错式MRoPE、DeepStack、文本时间戳对齐机制的基础上,先预训练,再后训练(即分别SFT、蒸馏、RL)
DeepSeek-OCR
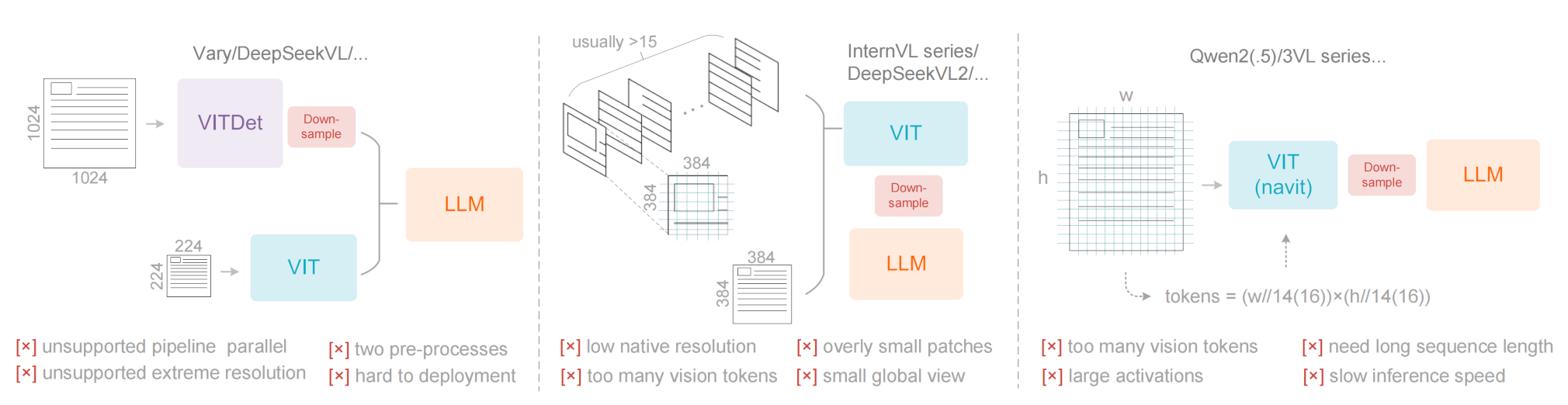
当前开源VLM主要采用三类视觉编码器,如上图所示。
第一类是由Vary代表的双塔架构,利用并行的SAM编码器,通过增加视觉词汇参数来实现高分辨率图像处理。该方法虽然可以控制参数量和激活内存,但存在显著缺点:需要对图像进行两次预处理,增加了部署复杂度,并使训练过程中编码器流水线并行性变得困难。
第二类是以InternVL2.0为代表的分块(tile-based)方法,通过将图像分割为小块并并行处理,从而在高分辨率设置下降低激活内存消耗。虽然这种方法能够支持极高分辨率,但由于原生编码器分辨率通常较低(低于512×512),导致大尺寸图像被过度切分,产生大量视觉Token,存在明显局限性。
第三类是以Qwen2-VL为代表的自适应分辨率编码,采用NaViT框架,通过基于patch的切分直接处理完整图像,无需tile并行。虽然该编码器能灵活适应多种分辨率,但在处理大尺寸图像时,会消耗大量激活内存,易导致GPU显存溢出,并且训练时序列打包需要极长的序列长度。过长的视觉Token序列会显著降低推理的预填充和生成速度
如何评价DeepSeek-OCR-2模型?
https://blog.csdn.net/v_JULY_v/article/details/154699042
DeepSeek-OCR——上下文视觉压缩:同等长度下,通过更少的视觉token解决长上下文处理难题

您的打赏,是对我的鼓励
