Chip » GPU通信技术, 光通信
2025-09-18 :: 4712 WordsGPU通信技术
集合通信的底层实现,正从早期的消息语义(显式 Send/Receive、RDMA,适用于Scale-Out松耦合场景)全面转向内存语义(隐式 Load/Store/Atomic,统一地址空间),NVLink、UALink、OISA、SUE等主要新兴协议均采用后者。
如果统一内存真的要成为超节点的软件基础,它首先就不能只是“远端显存也能被看到”这么简单。软件真正关心的,不是地址能不能指到远端,而是指过去之后,系统究竟承诺了什么:这次写入什么时候对别人可见,先后的顺序会不会被打乱,原子操作是不是仍然成立,一次同步到底是在等待本地完成、对端完成,还是整个系统都进入同一个可见状态。只有这些承诺被讲清,远端资源才可能在软件里表现得像一种稳定资源;否则,再高的带宽和再大的地址空间,也只会把“不确定性”更快地扩散到更大的系统里。
如果承诺太弱,软件就不敢把远端资源当成稳定资源;如果承诺太强,硬件和协议又会迅速背上难以承受的复杂度与代价。
DMA搬运是今天最常见的跨GPU通信模式。传统场景对互联的要求是”大带宽、可批量”,DMA/RDMA语义足以胜任。
LDST访存则是正在快速增长的新范式。FLUX等算子融合框架将通信操作内嵌到计算Kernel中——SM核心在计算过程中直接通过Load/Store指令读写远端GPU的HBM,不再有独立的拷贝阶段。这消除了Kernel间的同步屏障和中间缓冲区拷贝,对小规模推理和延迟敏感场景尤其重要。但这意味着互联必须支持SM发出的每一笔Load/Store/Atomic操作都能正确到达远端并保序返回。
NCCL等集合通信不再依赖外部DMA拷贝组装AllReduce,转而下沉复用硬件原生LDST原语,通信逻辑彻底融入计算流。
当前行业正在寻找的”甜点区”,很可能是”区域强一致 + 全局弱一致”的分层模型。
释放一致性(Release Consistency)模型——这是CUDA Memory Model和HSA Memory Model共同采用的弱序内存模型。
Throughput(吞吐量)
Goodput(有效吞吐量)
AI超节点的存储体系是高度分层化与异构化的:片上L1/L2 Cache、高带宽显存(HBM)、DDR主存、PCIe/CXL扩展内存以及本地NVMe/SSD,性能与容量跨越数个数量级。
内存池化技术从系统层面打破这种割裂状态。常规模型训练(几十亿至百亿参数)通常只需要HBM + DRAM两级池化,超大规模训练需要HBM+DRAM+SSD三级池化(ZeRO-Infinity)。
通信范式,正在从“对称、规则、全体参与”的集合通信(Allreduce/Allgather/Alltoall),转向“非对称、稀疏、图状、按需点对点” 的图通信(Graph Communication)(例如MoE)。
α–β–γ模型:
\[T(m) = \alpha + \beta \cdot m + \gamma \cdot f(m)\]- α:启动延迟 / 固定开销
- β:单位数据传输时间
- γ:每操作/每消息额外开销
常见变体还有Hockney、LogGP等。
Die To Die
Universal Chiplet Interconnect Express (UCIE)是一种开放的行业标准互连,可在芯粒(Chiplet)之间提供高带宽、低延迟、节能且具有成本效益的封装连接。由英特尔、AMD、Arm、台积电和三星等众多行业巨头推动。
UCIe从PCIe扩展而来,是个分层协议,协议层支持PCIe 6.0及CXL 2.0/3.0的生态。
Blackwell采用的是一种叫做NV-HBI(High Bandwitdth Interface)的技术,带宽高达10TB/s。
共享数据
共享数据很简单,OpenGL时代的persistent map,让驱动去做同步、做数据搬运,从而给开发者营造“数据随时可得”的假象(当然也可能的确就是随时可得),这就已经达到共享数据的要求了。
共享地址的难度则增加了一些,其目标是为了让你在CPU上跑的链表能直接在GPU等地方使用。x64时代到来使得内存地址扩充到48位,而且CPU上已经全面虚拟地址,GPU也要跟着加上地址转换的能力。
共享物理内存则明确表明,实现了上两者的独显(OpenCL的SVM就是前两个要求)也要被排除。那就基本是核显Only(主机的架构也可以看作是核显)。
https://www.zhihu.com/question/430936274
苹果的统一内存和集成显卡与CPU共用内存有什么区别?
https://www.zhihu.com/question/22233341
CPU与GPU之间是如何通信的?
RDMA
RDMA网卡(Remote Direct Memory Access,这是一种硬件的网络技术,它使得计算机访问远程的内存时无需远程机器上CPU的干预)已经可以提供50~100Gbps的网络带宽和微秒级的传输延迟。
目前许多以深度学习为目标应用的GPU机群都部署了这样的网络。
UCX是一个建立在RDMA等技术之上的用于数据处理和高性能计算的通信框架,RDMA是其底层核心之一。
OpenUCX是UCX的一个开源实现。
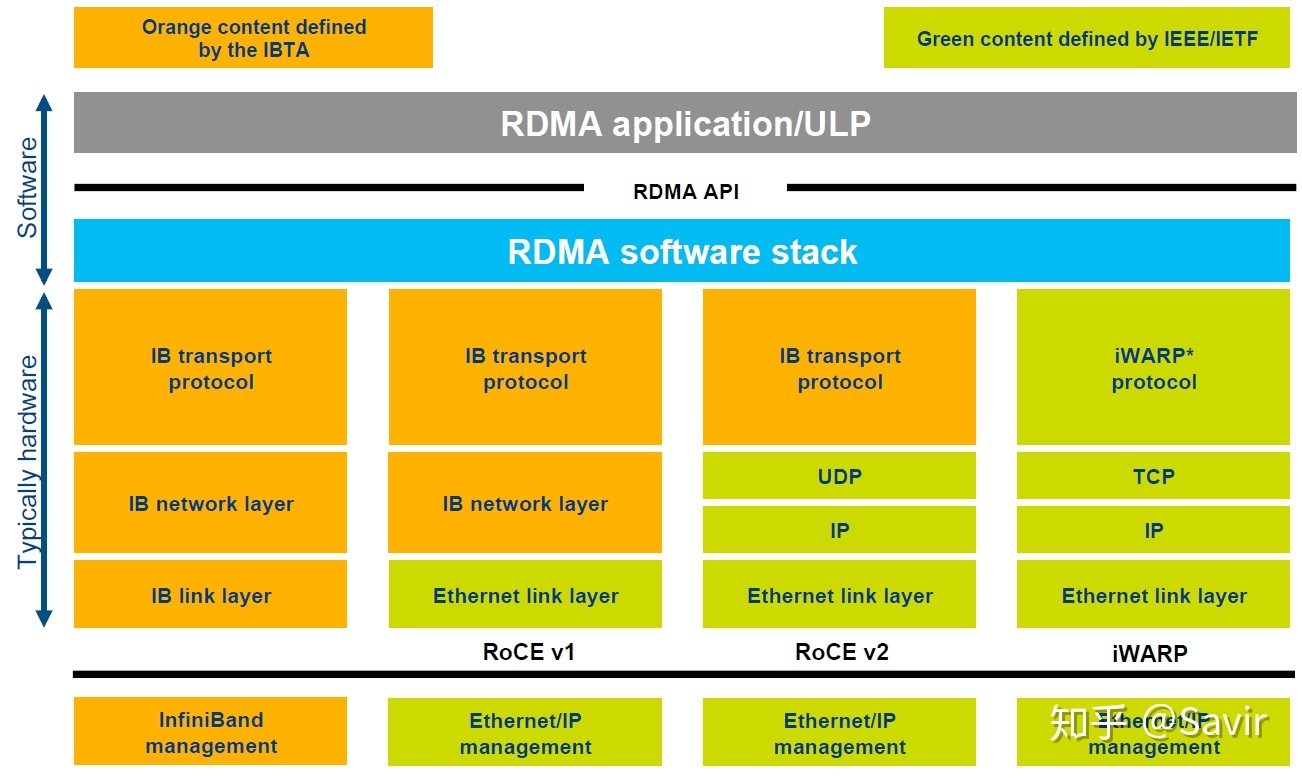
RDMA包含Infiniband(IB),RDMA over Converged Ethernet(RoCE)和internet Wide Area RDMA Protocol(iWARP)。三种协议都符合RDMA标准,使用相同的上层接口,在不同层次上有一些差别。
InfiniBand(直译为“无限带宽”技术,缩写为IB)是一个用于高性能计算的计算机网络通信标准,它具有极高的吞吐量和极低的延迟,用于计算机与计算机之间的数据互连。相当于是面向HPC的以太网的替代品。
Mellanox Technologies是一家InfiniBand制造商,于2020年被Nvidia收购。
| 名称 | 时间 | 带宽 |
|---|---|---|
| ConnectX-5 | 2016 | 100Gbps |
| ConnectX-6 | 2020 | 200Gbps |
| ConnectX-7 | 2022 | 400Gbps |
| ConnectX-8 | 2024 | 800Gbps |
官网:
https://www.openucx.org/
NIXL:NVIDIA Inference eXecution Layer
| 对比点 | NIXL | NCCL | UCX |
|---|---|---|---|
| 目标场景 | 推理KV cache、activation搬运 | 训练/推理的集合通信 | 通用网络抽象 |
| 语义 | 1-sided RDMA put/get 为主 | 集合 allreduce/bcast | 灵活但需自己实现 put/get |
| GPU 零拷贝 | 一等公民 | 需要 GPUDirect RDMA | 需额外配置 |
| 推理友好 | 针对 decode 阶段优化 | 主要用于训练 | 通用,推理需二次封装 |
参考:
https://mp.weixin.qq.com/s/_xcE8RUs0m4gwk3kxpe9jA
基于HTM/RDMA的可扩展内存事务处理系统
https://www.zhihu.com/column/c_1231181516811390976
一个RDMA方面的专栏
https://www.zhihu.com/question/422501188
什么是InfiniBand,它和以太网的区别在于什么?
https://www.cnblogs.com/allcloud/p/8945544.html
InfiniBand 与Intel Omni-Path Architecture
https://zhuanlan.zhihu.com/p/580035183
RoCE vs Infiniband vs TCP/IP
光通信
光互连是物理距离较远的芯片的首选。隔壁的PCIE系列也类似,PCIE 6将是最后一代使用电线的标准,未来的PCIE 7+也将转向光通信。
OCS是谷歌自研的数据中心光交换机。通常数据中心内数据交换是光电混合网络,设备之间的主要互联通过光缆/铜缆/光电转换器件、以及交换机ASIC/Serdes/PCIE/NVLink等链路实现。与过去在网络层之间多次将信号“从电转换为光,再到电”不同,OCS是一种全光学的连接方案,通过MEMS阵列结合光环路器、波分复用光模块实现光路的灵活切换、以达到直接通过光信号组建交换网络的目的。
SFP(Small Form-factor Pluggable)和QSFP(Quad Small Form-factor Pluggable)是光纤通信中常用的两种光模块接口类型。最近几年还出现了OSFP封装方式。
光模块的单价比较高,通常单个光模块可以到几千甚至几万人民币。由于每个Port都要使用光模块,因此光模块的数量基本与GPU的数量成正比,通常可以达到GPU的4-6倍,因此,仅光模块的成本就很高。
南北向(North-South)流量:指的是来自数据中心外的流量,不仅包含来自或访问互联网的流量,也包含和其他数据中心的流量。
东西向(East-West)流量:指的是来自同一数据中心的流量,比如数据中心中不同Server相互访问的流量。在现在的数据中心中,这一部分流量是大头,通常至少占70%-80%。
有些场景也会使用ToR Switch(Top-of-Rack,柜顶交换机),通常是作为Leaf Switch。因为和Server在一个机柜内,其布线会更加简单。
在DGX SuperPod中,由于数据量巨大,因此存储系统是与计算节点分开的,Storage Rack负责管理前者。
CPO(Co-Packaged Optics):把光引擎挪到交换机封装里,替代可插拔光模块。
OIO(In-Package Optical I/O):把光引擎挪到计算芯片(GPU/ASIC)封装里,替代电I/O。需全新硅光、3D封装,产业链要从头建。
NV预计将在2027年左右,使用OIO替换NVLink铜线,为此还投资了Ayar Labs(光I/O独角兽)。
https://mp.weixin.qq.com/s/gFalBUQGzezAuXdJfn1n2A
关于光通信的最强进阶科普
https://zhuanlan.zhihu.com/p/527363951
光通信、光芯片产业链
https://mp.weixin.qq.com/s/zbe2om-czwGbVBkFsPAwGw
万卡GPU集群互联:硬件配置和网络设计
https://zhuanlan.zhihu.com/p/617099215
封装内光学I/O与共封光学器件的区别(In-Package Optical I/O versus Co-Packaged Optics)

您的打赏,是对我的鼓励
