Attention » Attention(八)——BERT进阶
2023-03-28 :: 7247 WordsBERT进阶
UniLM
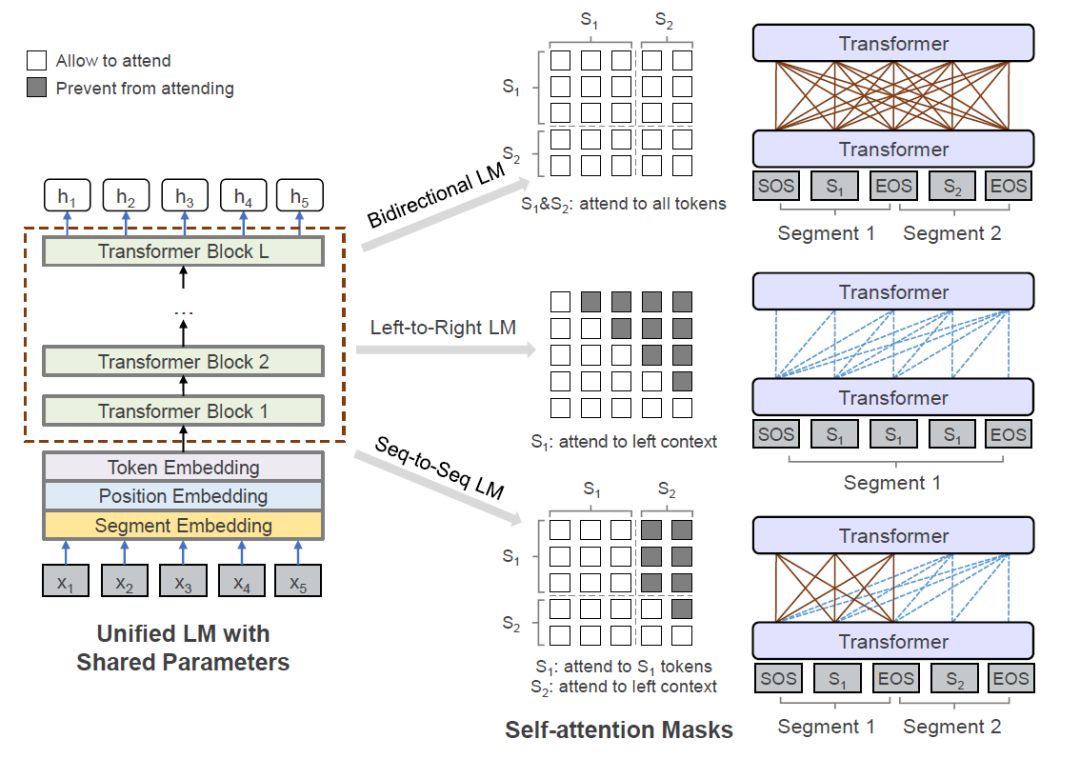
| Encoder注意力 | Decoder注意力 | 是否共享参数 | |
|---|---|---|---|
| GPT | 单向 | 单向 | 是 |
| UniLM | 双向 | 单向 | 是 |
| T5 | 双向 | 单向 | 否 |
https://mp.weixin.qq.com/s/m_FU4NmjUsvxusRidDb-Xg
UniLM:一种既能阅读又能自动生成的预训练模型
https://mp.weixin.qq.com/s/yyUPqxpfBwUSRbwM6SSAcQ
UniLM论文阅读笔记
https://mp.weixin.qq.com/s/RjeuHXa8O3MzSpTOuOHMkQ
站在BERT肩膀上的NLP新秀们:XLMs、MASS和UNILM
https://mp.weixin.qq.com/s/UEBKSKEkZTbpR49_Rh50Jg
微软统一预训练语言模型UniLM 2.0解读
Electra
https://mp.weixin.qq.com/s/dFT7KKMH56unkOEA9H4Kuw
吊打BERT Large的小型预训练模型ELECTRA终于开源!真相却让人…
https://mp.weixin.qq.com/s/6i9eQISKsWU0jawKzWg8nQ
超越bert,最新预训练模型ELECTRA论文阅读笔记
https://mp.weixin.qq.com/s/lkB1xn6G2P5Nivj7DcYg5w
Electra: 判别还是生成,这是一个选择
参考
https://www.zhihu.com/question/298203515
如何评价BERT模型?
https://mp.weixin.qq.com/s/Fao3i99kZ1a6aa3UhAYKhA
全面超越人类!Google称霸SQuAD,BERT横扫11大NLP测试
https://mp.weixin.qq.com/s/INDOBcpg5p7vtPBChAIjAA
最强预训练模型BERT的Pytorch实现
https://mp.weixin.qq.com/s/SZMYj4rMneR3OWST007H-Q
解读谷歌最强NLP模型BERT:模型、数据和训练
https://mp.weixin.qq.com/s/8uZ2SJtzZhzQhoPY7XO9uw
详细解读谷歌新模型BERT为什么嗨翻AI圈
https://zhuanlan.zhihu.com/p/66053631
BERT
https://mp.weixin.qq.com/s/WEbJnO04DOrsxUbzpgL66g
BERT源码分析(PART I)
https://mp.weixin.qq.com/s/iXjE7KoyvFQ8uekLKRK4jw
BERT源码分析(PART II)
https://mp.weixin.qq.com/s/DxBC_x5ZWC6SECfnwDGnVg
BERT源码分析(PART III)
https://mp.weixin.qq.com/s/kI_k_plZbRzmdeXxt2_2WA
从Transformer到BERT模型
https://mp.weixin.qq.com/s/Bnk0nIjBdb58WVJEY8MqnA
NLP中各种各样的编码器
https://mp.weixin.qq.com/s/CofeiL4fImq98UeuJ4hWTg
预训练BERT,官方代码发布前他们是这样用TensorFlow解决的
https://mp.weixin.qq.com/s/HOD1Hb70NhTXXCXlopzfng
BERT推理加速实践
https://mp.weixin.qq.com/s/0luHJsw7WWJskJWGThR5qg
使用BERT做文本摘要
https://mp.weixin.qq.com/s/IY8J09LvDAr8owYffKi5Dw
五问BERT:深入理解NLP领域爆红的预训练模型
https://zhuanlan.zhihu.com/p/106901954
BERT, ELMo, & GPT-2: 这些上下文相关的表示到底有多上下文化?
https://mp.weixin.qq.com/s/mkDmn4zy_s87kiiDIkx0VQ
NLP的12种后BERT预训练方法
https://www.zhihu.com/question/327450789
Bert如何解决长文本问题?
https://mp.weixin.qq.com/s/QTELpbr480AJsBINm-FHKQ
代码也能预训练,微软&哈工大最新提出CodeBERT模型,支持自然-编程双语处理
https://mp.weixin.qq.com/s/ZEWCcxTEuEMvQ5__t3gkBg
BERT技术体系综述论文:40项分析探究BERT如何work
https://mp.weixin.qq.com/s/OsfeAA_tbzAddh1eunwx2w
关于BERT,面试官们都怎么问
https://mp.weixin.qq.com/s/e3n_16uB-qGeGSaGwzlBDw
这群工程师,业余将中文NLP推进了一大步(中文预训练模型)
https://mp.weixin.qq.com/s/V4pbjP5na1OYp-TorUik8g
详聊如何用BERT实现关系抽取
https://mp.weixin.qq.com/s/s5YIG6rBEy6fZkFLh-CzoA
后BERT时代生存指南之VL-BERT篇
https://zhuanlan.zhihu.com/p/113326366
如何训练并使用Bert
https://mp.weixin.qq.com/s/dmHxEkmVFXcCGhv8eH91Tw
从Word2Vec到BERT:上下文嵌入(Contextual Embedding)最新综述论文
https://mp.weixin.qq.com/s/g6-NjoFMPpxjsh38X-wTFQ
BERT,GPT-2这些顶尖工具到底该怎么用到我的模型里?
https://mp.weixin.qq.com/s/N6xBFZ82dkSGCbj6vC5nLQ
上下文预训练模型最全整理:原理、应用、开源代码、数据分享
https://mp.weixin.qq.com/s/-6XpuO7_ve_EdSPCMeWE7g
Attention isn’t all you need!BERT的力量之源远不止注意力
https://mp.weixin.qq.com/s/Y2bs2QegRadSR7lbiFFnWg
BERT一作Jacob Devlin斯坦福演讲PPT:BERT介绍与答疑
https://zhuanlan.zhihu.com/p/62308732
浅谈Bert:语言理解中的预训练编码器
https://mp.weixin.qq.com/s/1Cz6js4kYdvc8g4oKjVPeA
BERT烹饪之法:fintune的艺术
https://mp.weixin.qq.com/s/nVM2Kxc_Mn7BAC6-Pig2Uw
BERT模型的标准调优和花式调优
https://mp.weixin.qq.com/s/FwmEIZ3ugeZBbLIGHmH-_g
BERT之后,GLUE基准升级为SuperGLUE:难度更大
https://mp.weixin.qq.com/s/SDVxn3Ra1dKmr-XgKNg5IA
罗玲:From Word Representation to BERT
https://mp.weixin.qq.com/s/-bh8BL4LxnevS8xnW5U9ZA
中科院自动化所提出BIFT模型:面向自然语言生成,同步双向推断
https://mp.weixin.qq.com/s/7yCnAHk6x0ICtEwBKxXpOw
序列到序列自然语言生成任务超越BERT、GPT!微软提出通用预训练模型MASS
https://mp.weixin.qq.com/s/7sIUaSON53hsXUJjq8uVUA
马聪:NLP中的生成式预训练模型
https://mp.weixin.qq.com/s/Jrs8okgVAh0fymIq-jCqgA
模型压缩与蒸馏!BERT的忒修斯船
https://mp.weixin.qq.com/s/UNHu1eVNorWWKbDb0XBJcA
模型压缩与蒸馏!BERT家族的瘦身之路
https://mp.weixin.qq.com/s/oD_Vibp4Ygraix23K_oV2Q
BERT在58搜索的实践
https://mp.weixin.qq.com/s/bqvEeCyX8pqhJQfCUvUkEw
图解BERT:通俗的解释BERT是如何工作的
https://mp.weixin.qq.com/s/yPq1cGnhcbaNLOjadj91pw
Bert时代的创新:Bert在NLP各领域的应用进展
https://mp.weixin.qq.com/s/l-de0vfx-L24g58IxK-NKQ
Jeff Dean强推:可视化Bert网络,发掘其中的语言、语法树与几何学
https://mp.weixin.qq.com/s/nlFXfgM5KKZXnPdwd97JYg
哈工大讯飞联合实验室发布基于全词覆盖的中文BERT预训练模型
https://zhuanlan.zhihu.com/p/70389596
一批高质量中文BERT预训练模型请查收(上)
https://mp.weixin.qq.com/s/h1VUSY7_UZF3PmjSN0DMSg
从One-hot, Word embedding到Transformer,一步步教你理解Bert
https://zhuanlan.zhihu.com/p/132554155
超细节的BERT/Transformer知识点
https://mp.weixin.qq.com/s/UJlmjFHWhnlXXJoRv4zkEQ
虽被BERT碾压,但还是有必要谈谈BERT时代与后时代的NLP
https://mp.weixin.qq.com/s/e4dgIdwzDzcLSkdgr1yZpg
LeCun力荐:Facebook推出十亿参数超大容量存储器
https://mp.weixin.qq.com/s/zXXtbuSvyMOkgrWJwB83kg
预训练语言模型的最新探索
https://mp.weixin.qq.com/s/WzGa5XVi2Op4Lz-1uQXfxQ
SpanBERT:提出基于分词的预训练模型,多项任务性能超越现有模型!
https://zhuanlan.zhihu.com/p/76912493
nlp中的预训练语言模型总结(单向模型、BERT系列模型、XLNet)
https://mp.weixin.qq.com/s/pYSs6NhIAB6DuwNnKZhkZQ
Bert改进:如何融入知识
https://mp.weixin.qq.com/s/in5SDWlQg8ts4E8DTmHxMQ
BERT在推荐系统领域可能会有什么作为?
https://mp.weixin.qq.com/s/kJhOrz0VaYc-k-6XJS02ag
8篇论文梳理BERT相关模型进展与反思
https://mp.weixin.qq.com/s/hI9XAiqKaHLq-Z9JkaWA_A
解决自然语言歧义问题,斯坦福教授、IJCAI卓越研究奖得主提出SenseBERT模型
https://mp.weixin.qq.com/s/55B0ToIKDusiPI5farR19w
NLP这两年:15个预训练模型对比分析与剖析
https://mp.weixin.qq.com/s/SPfa17p3QetZXCC01DwmQA
解密BERT
https://zhuanlan.zhihu.com/p/72805778
BERT的演进和应用
https://mp.weixin.qq.com/s/9YuBY0wLLVQ8ZrT9fiNICA
语音版BERT?滴滴提出无监督预训练模型,中文识别性能提升10%以上
https://mp.weixin.qq.com/s/OXkXjPHhaMXsKw2YevV6sw
邱锡鹏:从Transformer到BERT–自然语言处理中的表示学习进展
https://mp.weixin.qq.com/s/dV4RkxZOC9o2BxNi0GljKQ
谷歌最强NLP模型BERT官方中文版来了!多语言模型支持100种语言
https://zhuanlan.zhihu.com/p/49271699
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
https://mp.weixin.qq.com/s/k_33UK1RkMyHn6TSudU6Kg
详解谷歌最强NLP模型BERT
https://mp.weixin.qq.com/s/d2MZQbamdo0EC_MVtf-HZA
BERT详解:开创性自然语言处理框架的全面指南
https://mp.weixin.qq.com/s/pD4it8vQ-aE474uSMQG0YQ
两行代码玩转Google BERT句向量词向量
https://mp.weixin.qq.com/s/osmUZxAAX3x-oTHYJbzemA
谷歌BERT模型fine-tune终极实践教程
https://mp.weixin.qq.com/s/XmeDjHSFI0UsQmKeOgwnyA
小数据福音!BERT在极小数据下带来显著提升的开源实现
https://mp.weixin.qq.com/s/HXYDO5PM8UIoXgEPGe8p-w
图解当前最强语言模型BERT:NLP是如何攻克迁移学习的?
https://mp.weixin.qq.com/s/zz3j9HEuzw5e92MQXxSQsA
遗珠之作?谷歌Quoc Le这篇NLP预训练模型论文值得一看
https://mp.weixin.qq.com/s/IN4YfoZnlBozwEFdhSvLZg
用可视化解构BERT,我们从上亿参数中提取出了6种直观模式
https://mp.weixin.qq.com/s/s1bQFdA6gtoHeeQMJKQ8UQ
Bert时代的创新:Bert应用模式比较及其它
https://mp.weixin.qq.com/s/zqlWx3e4LOJ3_Zy2DEbCjw
从语言模型看Bert的善变与GPT的坚守
https://mp.weixin.qq.com/s/LngE10Hnqe9bgFzpNfUwLQ
NLP中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert
https://mp.weixin.qq.com/s/MgLLPEY3ynJGkuTgnIXndQ
站在BERT肩膀上的NLP新秀们(PART I)
https://mp.weixin.qq.com/s/nIT3GIU0dUIYyGChxsiOWw
Google BERT应用之《红楼梦》对话人物提取
https://mp.weixin.qq.com/s/dcp_ANYijRmicMYX7OpJmA
如何用最强模型BERT做NLP迁移学习?
https://mp.weixin.qq.com/s/DR4SkgOfUT7KYiaXm5NynQ
跨语言版BERT:Facebook提出跨语言预训练模型XLM
https://mp.weixin.qq.com/s/epjjHmlmMFhWtRO_cCUITA
用BERT进行多标签文本分类
https://mp.weixin.qq.com/s/Wk6gvOS_Qnud6ib1esMFXA
加入Transformer-XL,这个PyTorch包能调用各种NLP预训练模型!
https://mp.weixin.qq.com/s/GqqU3Ixht1BzMnQeRYQEqQ
谷歌NLP深度学习模型BERT特征的可解释性表现怎么样?
https://mp.weixin.qq.com/s/2f91Ksj19rk_emoFpEmPfA
从BERT看大规模数据的无监督利用
https://mp.weixin.qq.com/s/hF4EcKqmaTm_gemxX7Kftg
BERT的嵌入层是如何实现的?
https://mp.weixin.qq.com/s/CdjNQKSNuklVUsXe4InSoA
FastBERT:放飞BERT的推理速度
https://zhuanlan.zhihu.com/p/132361501
BERT是如何分词的
https://mp.weixin.qq.com/s/Tld9V1jdmWs06zNxiJNkZg
BART&MASS自然语言生成任务上的进步
https://mp.weixin.qq.com/s/G995ulqe6Ifxml_AJqapAw
BERT在小米NLP业务中的实战探索
https://www.cnblogs.com/gczr/p/12874409.html
Sentence-BERT: 一种能快速计算句子相似度的孪生网络
https://mp.weixin.qq.com/s/0hUNG6tC-hlfyTJtuzwU5w
NLP中的Mask全解

您的打赏,是对我的鼓励
