Attention » Attention(六)——Attention in CV & RS, State Space Model
2020-05-04 :: 6633 Words轻量化Transformer(续)
https://mp.weixin.qq.com/s/sNv9UirZJ6xT3zf8XhJaRg
FastFormers:实现Transformers在CPU上223倍的推理加速
https://mp.weixin.qq.com/s/6RUvMR-fjzB5PkZBQ4YFNQ
BERT模型压缩:量化、剪枝和蒸馏
https://zhuanlan.zhihu.com/p/576495529
Fast and Effective!一文速览轻量化Transformer各领域研究进展
Linformer
https://mp.weixin.qq.com/s/IOc-gxOa6a415Hf1VBmiQw
“Linformer”拍了拍“被吊打Transformers的后浪们”
https://mp.weixin.qq.com/s/cDQW5992hTaeGoA7zL7Vzg
Linformer: 线性复杂度的Attention
Self-Attention 加速方法一览:ISSA、CCNet、CGNL、Linformer
Attention in CV & RS
《Attention Mechanisms in Computer Vision: A Survey》
https://github.com/MenghaoGuo/Awesome-Vision-Attentions
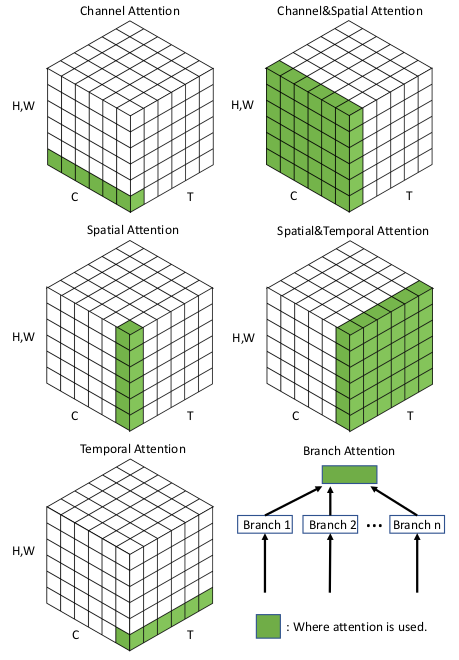
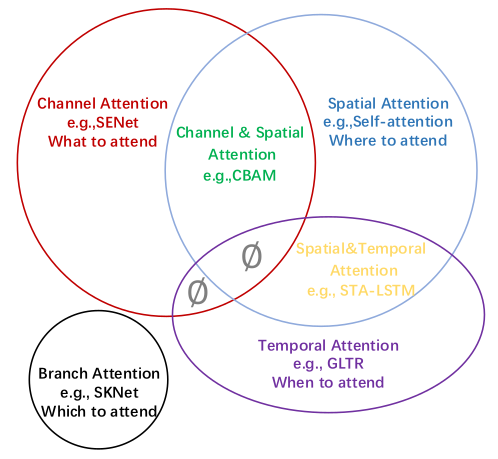
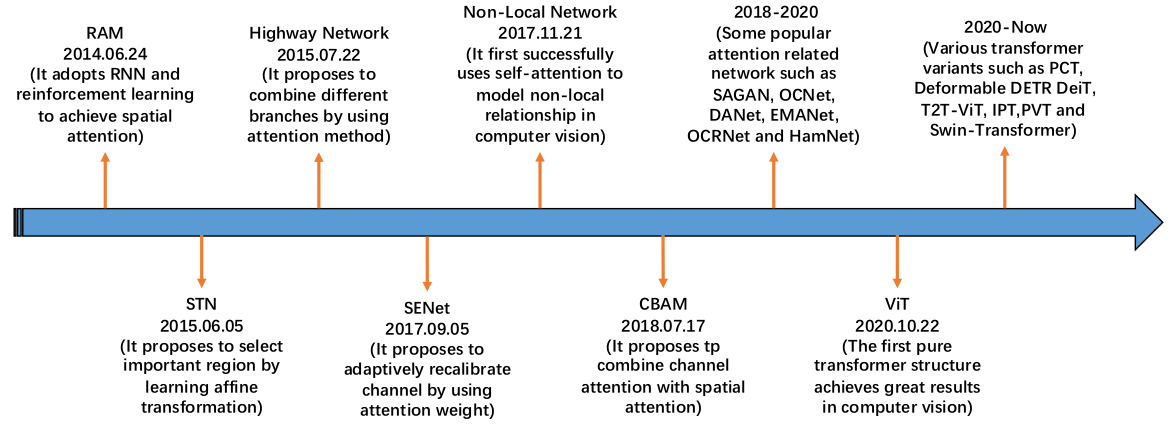
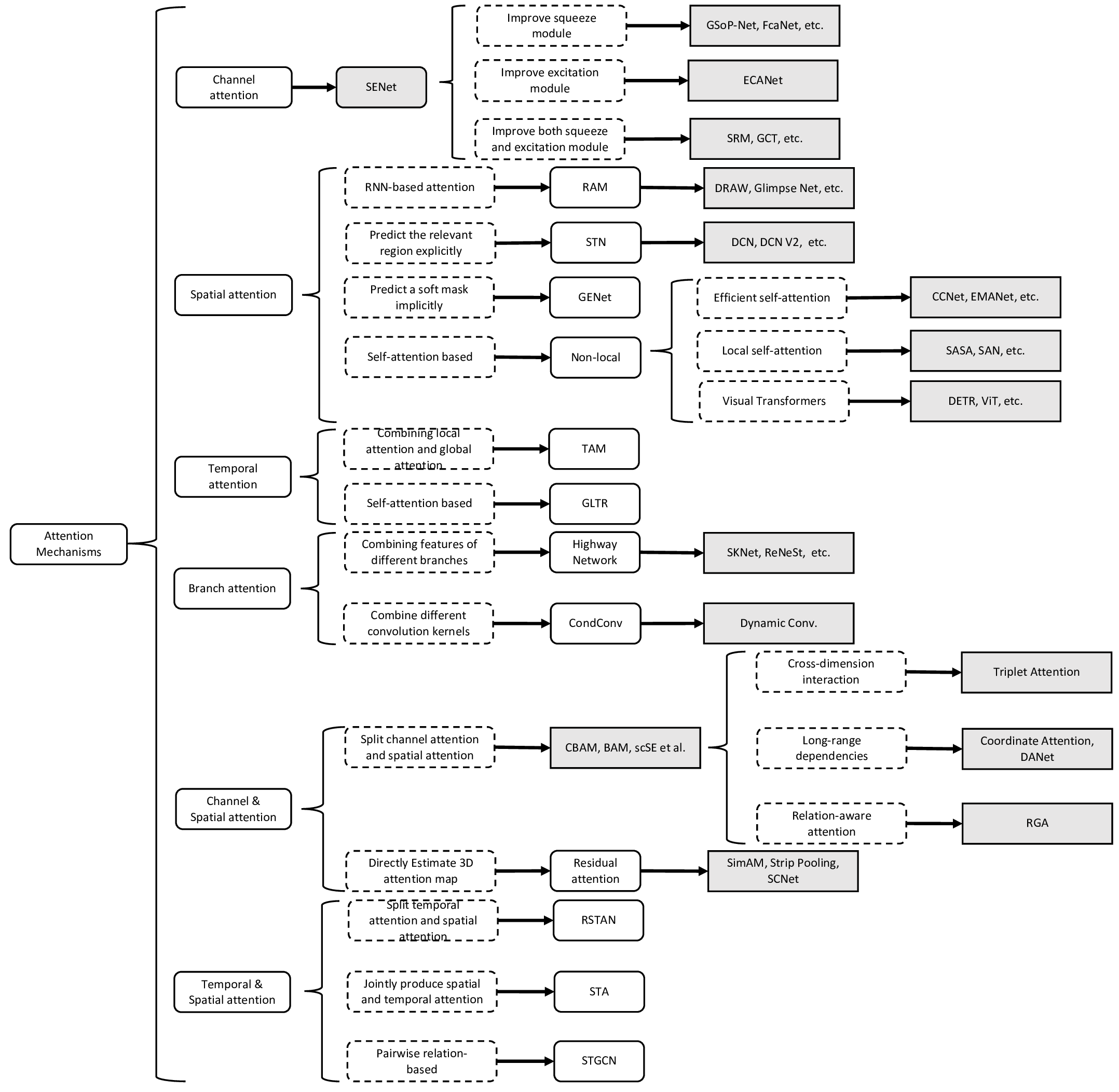
和Normalization一样,Attention应用于CV领域也有不同的花式。
ViT
上面这些主要还局限于Layer级别的替换,在这里Attention无非是Conv的平替而已。
而下面的ViT则是从体系层面对CNN的一种颠覆了。
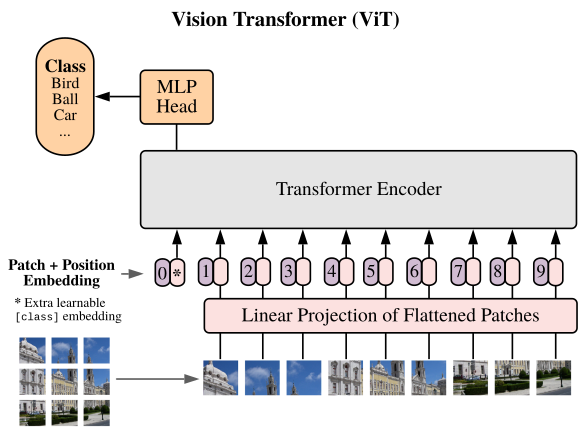
ViT借鉴了NLP的一些做法,将图片分成若干小块,每一块就是一个词向量。这样就把一个CV问题变成了NLP问题。
ViViT在ViT的基础上增加时间维度以处理视频。
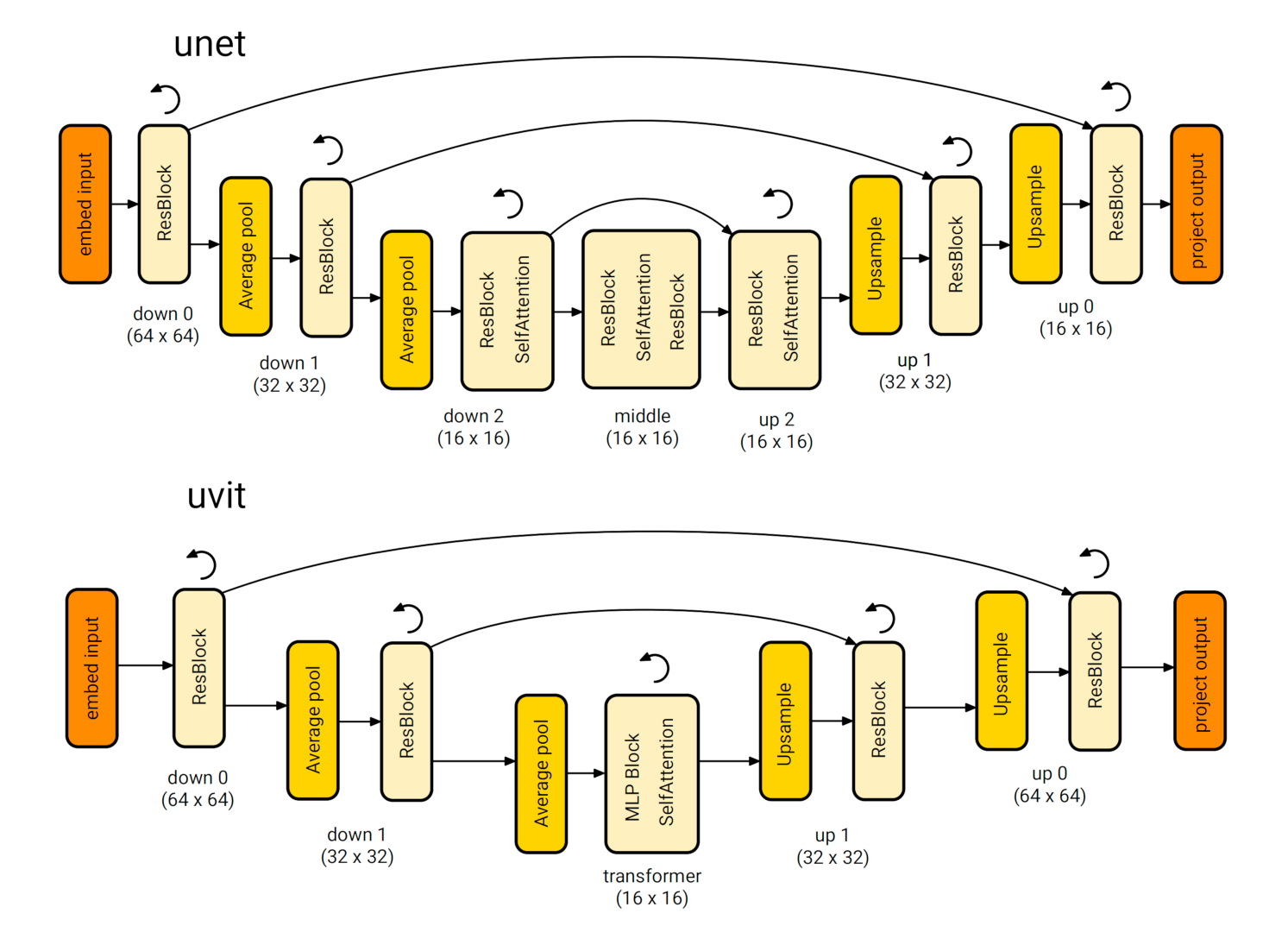
U-ViT = U-Net + ViT
ViT模型中的高范数伪影(High-Norm Artifacts)是指在Vision Transformer训练完成后,模型输出特征图中出现的一类异常token——它们的L2范数显著高于其他正常token(可达平均值的2-10倍),通常出现在低信息量的背景区域或图像角落。
《Vision Transformers Need More Than Registers》
https://zhuanlan.zhihu.com/p/1943279068654056673
最强视觉自监督模型DINO系列超详细解读:DINO / DINOv2 / DINOv3
Masked Autoencoders
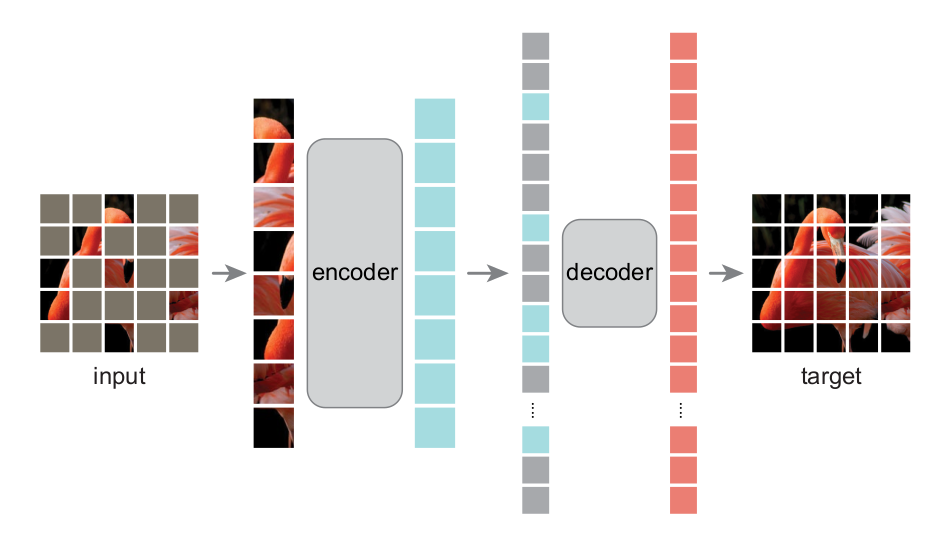
何恺明的MAE也是类似的套路。
https://mp.weixin.qq.com/s/x-ruExbM9T8EIv2gZW0Nnw
视觉预训练新范式MAE
https://www.zhihu.com/question/498364155
如何看待何恺明最新一作论文Masked Autoencoders?
https://mp.weixin.qq.com/s/CxEvEZ9AiEfB1TFFjev0aA
NLP和CV的双子星,注入Mask的预训练模型BERT和MAE
Swin Transformer
![]()
Swin Transformer的改进:
1.考虑了不同的分辨率。
2.除了分类之外,还可以接入目标检测等后续任务。
3.对MSA(multi-head self attention)进行了改进。提出了W-MSA和SW-MSA,也就是Window版本的MSA和滑动Window版的MSA。
https://mp.weixin.qq.com/s/t_J0MODtWzfnJse0aNGyWg
Swin Transformer对CNN的降维打击
https://mp.weixin.qq.com/s/8x1pgRLWaMkFSjT7zjhTgQ
图解swin transformer
https://zhuanlan.zhihu.com/p/361366090
CV+Transformer之Swin Transformer
https://mp.weixin.qq.com/s/z_ILLmNx3cbJI1B-M028vQ
Swin Transformer重磅升级!Swin V2:向更大容量、更高分辨率的更大模型迈进
DETR

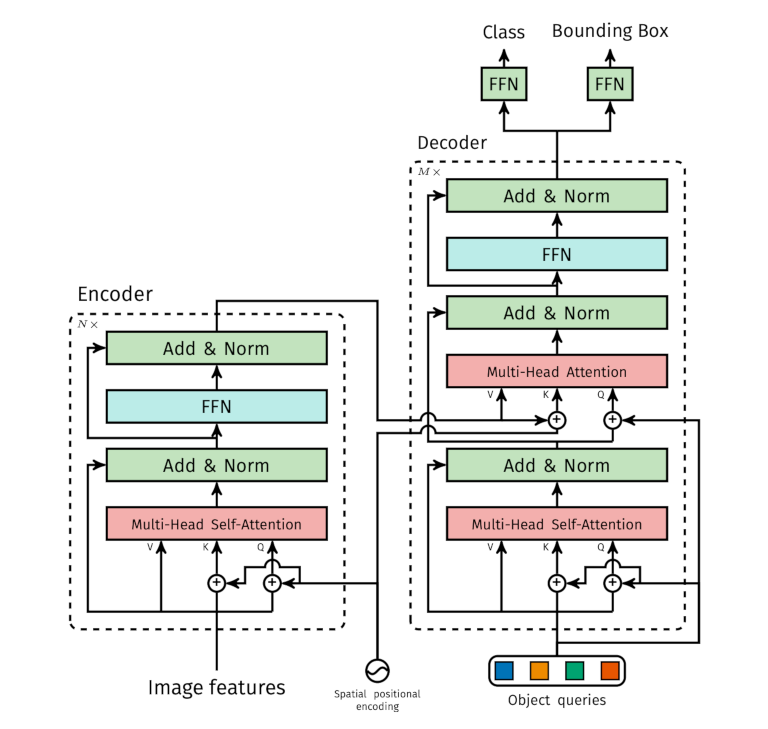
上图中的Object queries是训练数据集中的物体类别的Embedding,其本身也是需要训练的。
训练之后的推理阶段,根据每个Object query,生成一个class+bound box。显然和NLP任务不同,这里没有先后依赖,是一个可以并行的过程。
https://mp.weixin.qq.com/s/b5Ont9vHPeCPnAjuDGv5Bg
Facebook开源新思路!DETR:用Transformers来进行端到端的目标检测
https://mp.weixin.qq.com/s/eHZGiyeZG36Dg6JV1boEeA
语言模型“不务正业”做起目标检测,性能还比DETR、Faster R-CNN更好
BEVFormer

BEV(Bird’s-eye-view)
Deformable Attention
GridSample
https://zhuanlan.zhihu.com/p/543335939
万字长文理解纯视觉感知算法——BEVFormer
https://zhuanlan.zhihu.com/p/538490215
一文读懂BEVFormer论文
https://zhuanlan.zhihu.com/p/629792598
一文看懂BEVFormer技术及其背后价值
https://www.zhihu.com/question/521842610
自动驾驶BEV感知有哪些让人眼前一亮的新方法?
https://zhuanlan.zhihu.com/p/509207308
特斯拉AI DAY感知详解
https://zhuanlan.zhihu.com/p/633483313
BEV系列一:BEV介绍和常用BEV算法简介
参考
https://mp.weixin.qq.com/s/PD2YnFb6yleDEMhz3ahFSQ
计算机视觉”新”范式: Transformer
https://mp.weixin.qq.com/s/wAy3VsOIHxR948eOuXghmA
使用Transformers创建计算机视觉模型
https://zhuanlan.zhihu.com/p/288758894
CV注意力机制论文阅读笔记
https://mp.weixin.qq.com/s/bMOLo9FXpPsOrD9j4CNHYg
清华&南开最新“视觉注意力机制Attention”综述论文,带你全面了解六大类注意力机制方法
https://mp.weixin.qq.com/s/VBWak2bREDHidZe1EExKLA
中科院计算所最新“视觉Transformer”综述论文,带你全面了解最新CV分类、检测/分割方法
https://mp.weixin.qq.com/s/M3VRlz8-McbTbp9VcctU0w
如何让BERT拥有视觉感知能力?两种方式将视频信息注入BERT
https://mp.weixin.qq.com/s/-eBL9gFbAGFtmqkLMAoUTw
文本+视觉,多篇Visual/Video BERT论文介绍
http://mp.weixin.qq.com/s/Bt6EMD4opHCnRoHKYitsUA
结合人类视觉注意力进行图像分类
https://mp.weixin.qq.com/s/POYTh4Jf7HttxoLhrHZQhw
基于双向注意力机制视觉问答pyTorch实现
http://blog.csdn.net/leo_xu06/article/details/53491400
视觉注意力的循环神经网络模型
https://mp.weixin.qq.com/s/JoTzaInn_uAA9oZgMcfskw
计算机视觉技术self-attention最新进展
https://zhuanlan.zhihu.com/p/32928645
计算机视觉中的注意力机制
https://zhuanlan.zhihu.com/p/56501461
计算机视觉中的注意力机制
https://zhuanlan.zhihu.com/p/32971586
图像描述:基于项的注意力机制
https://zhuanlan.zhihu.com/p/33158614
图像识别:基于位置的柔性注意力机制
https://mp.weixin.qq.com/s/tVKEJ9rqlMaZ9bx6ngIelw
自注意力机制在计算机视觉中的应用
https://mp.weixin.qq.com/s/Di-TbseiezMBc-MUYoEFHg
CV领域的注意力机制
https://mp.weixin.qq.com/s/7ETHeN2xV_hEwkDxrhJyNg
用Attention玩转CV,一文总览自注意力语义分割进展
https://mp.weixin.qq.com/s/G4mFW8cn-ho3KGmbw5sSTw
计算机视觉中注意力机制原理及其模型发展和应用
https://mp.weixin.qq.com/s/gar7zcl68W4oKnFPLFekoQ
Attention增强的卷积网络
https://zhuanlan.zhihu.com/p/308301901
3W字长文带你轻松入门视觉transformer
https://mp.weixin.qq.com/s/MZo3LFyzXp-qpi5jEOQS5Q
FPT:又是借鉴Transformer,这次多方向融合特征金字塔
https://mp.weixin.qq.com/s/N2PAgp-epq4i9CLll1nzJA
华为联合北大、悉尼大学对Visual Transformer的最新综述
https://mp.weixin.qq.com/s/cLPMJm4u67QDsJg0IkmYFQ
解析Vision Transformer
https://www.zhihu.com/question/437495132
如何看待Transformer在CV上的应用前景,未来有可能替代CNN吗?
https://mp.weixin.qq.com/s/hn4EMcVJuBSjfGxJ_qM3Tw
搞懂Vision Transformer原理和代码,看这篇技术综述就够了
https://mp.weixin.qq.com/s/ozUHHGMqIC0-FRWoNGhVYQ
搞懂Vision Transformer原理和代码,看这篇技术综述就够了(二)
https://mp.weixin.qq.com/s/dysKMpOXAjSRgb5xGDO3FA
搞懂Vision Transformer原理和代码,看这篇技术综述就够了(三)
https://mp.weixin.qq.com/s/EXtTUh4_w07Kc7hfBBMBiw
搞懂Vision Transformer原理和代码,看这篇技术综述就够了(四)
https://mp.weixin.qq.com/s/MyRJl_QsO2X1yF4akPGktg
搞懂Vision Transformer原理和代码,看这篇技术综述就够了(五)
https://mp.weixin.qq.com/s/FIilwbLzYk4av8w11VgJeQ
计算机视觉中的Transformer
https://mp.weixin.qq.com/s/2BECepucUdzLYlyU1aM7bA
网络架构设计:CNN based和Transformer based
https://mp.weixin.qq.com/s/k-pe1qTelVmvcwY6hmSi4A
Transformer是巧合还是必然?搜索推荐领域的新潮流
https://mp.weixin.qq.com/s/rATLyYBgo2nWY4rKXmgV5w
来自Transformer的降维打击:ReID各项任务全面领先,阿里&浙大提出TransReID
https://mp.weixin.qq.com/s/aWzHpeNS3OUrjrbEvnI87g
用Pytorch轻松实现28个视觉Transformer,开源库timm了解一下
https://mp.weixin.qq.com/s/J7Fw-T1tYSqi9_vx8VSqYA
TimeSformer:视频理解所需的只是时空注意力吗?
https://mp.weixin.qq.com/s/dHWc0MFwuyLMsCoBGN353Q
PVT:可用于密集任务backbone的金字塔视觉transformer
https://mp.weixin.qq.com/s/DKWSeRu_ThMf_vf9j1GCbQ
PoseFormer:首个纯基于Transformer的3D人体姿态估计网络,性能达到SOTA
https://mp.weixin.qq.com/s/O-xcsIHufrPQKPQGNcKjkg
视觉子领域中的Transformer
https://mp.weixin.qq.com/s/IeQdvz8DrNAULy2k7oFgWw
Transformers在计算机视觉概述
https://mp.weixin.qq.com/s/H2GZgnR8jN5ztUACiowpZQ
Vision Transformer新秀:VOLO
https://mp.weixin.qq.com/s/_ETbYLu6qklaxJ2dv-xeSA
计算机视觉中的Transformer,98页ppt
https://mp.weixin.qq.com/s/XHnt5MRa52IeJKK6nfDb8Q
Vision Transformer学习笔记1
https://mp.weixin.qq.com/s/RhBK0szHORt7XHyoMEVnSA
Vision Transformer学习笔记2: Swin Transformer
https://mp.weixin.qq.com/s/faYB3JCoUfTw_zSVxrKJzA
最新“视频Transformer”2022综述
https://github.com/NVIDIA-Merlin/Transformers4Rec
NVIDIA推出的RS库
State Space Model
S3 & S4
RNN的状态变量:\(h_{t}=tanh \left(W h_{t-1}+U x_{t}\right)\),其中的tanh不是线性计算,导致无法采用“矩阵运算结合律”进行并行优化。
于是有了SSM(S3):
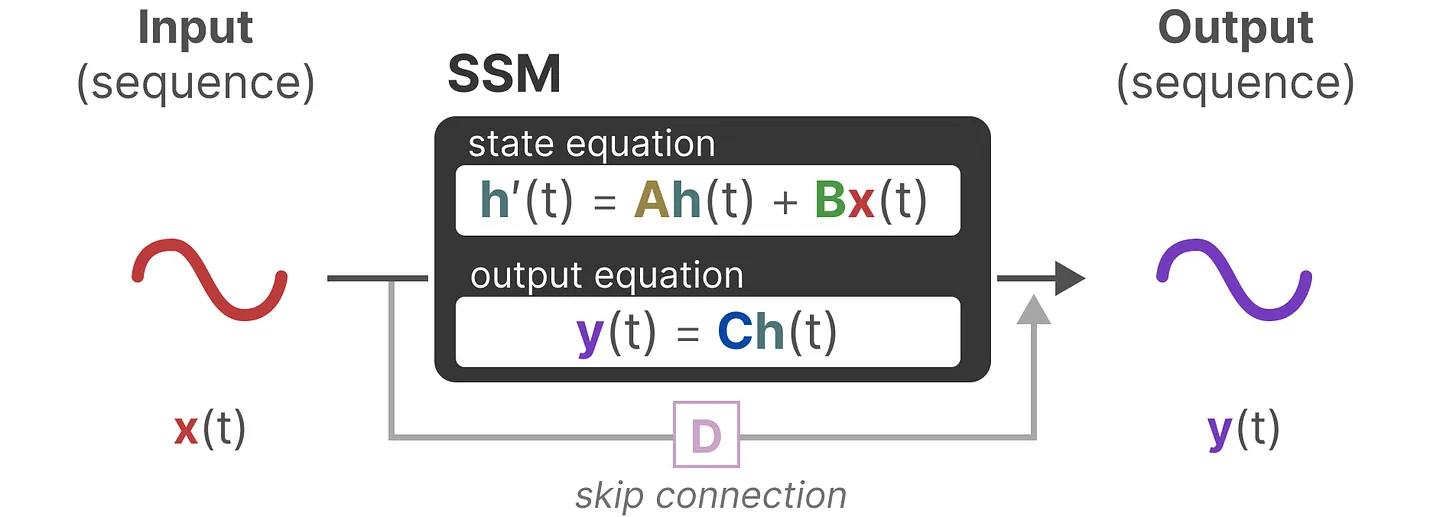
SSM将tanh替换成了一个待学习的参数矩阵C。
Structured State Space Model(S4)在S3的基础上做了一些改进之后发现,这个公式实际上就是一个Kalman Filter,而后者使用卷积加速已经是很成熟的套路了。
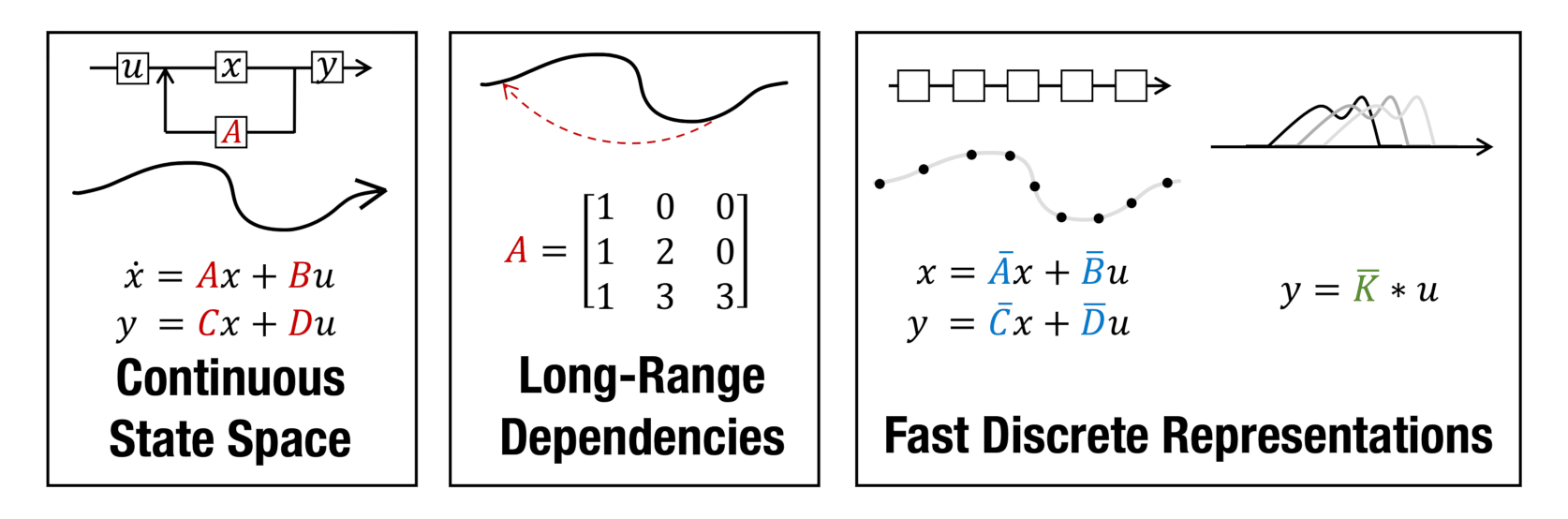
因此可以将SSM的训练改为CNN的并行模式:
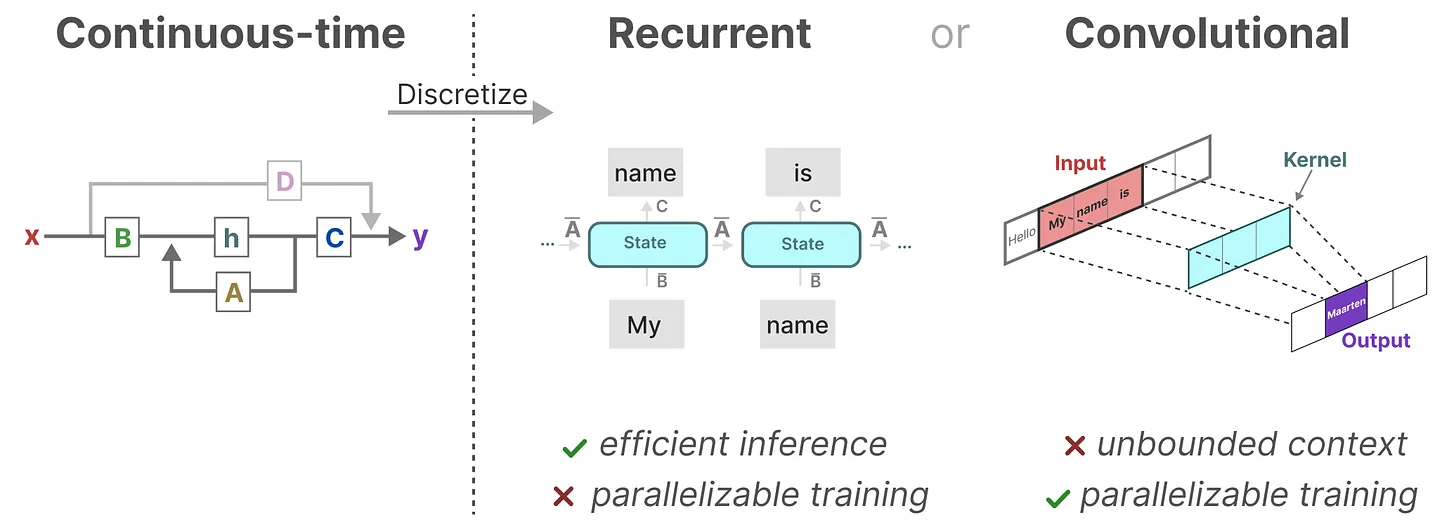
序列模型的效率与效果的权衡点在于它们对状态的压缩程度:
- 高效的模型必须有一个小的状态(比如RNN或S4)
- 而有效的模型必须有一个包含来自上下文的所有必要信息的状态(比如transformer)
S5:Simplified State Space Layers for Sequence Modeling
S3 & S4,包括后面提到的Mamba、RWKV等,通常都被划分为linear attention路线。

您的打赏,是对我的鼓励
