Attention » Attention(四)——预训练语言模型进化史, BERT, ELMo
2019-07-11 :: 5983 WordsTransformer(续)
https://mp.weixin.qq.com/s/RrIUxwkRaGxzJo0hIx3SIA
TTSR:用Transformer来实现端到端的超分辨率任务
https://mp.weixin.qq.com/s/N1I4mGKzsHJiAluZL17sDQ
Transformers是一种图神经网络
https://mp.weixin.qq.com/s/mFqkCfzmWi7pxelC1vMJBQ
nlp中的Attention注意力机制+Transformer详解
https://zhuanlan.zhihu.com/p/648127076
三万字最全解析!从零实现Transformer
预训练语言模型进化史

Sesame Street(芝麻街)是是美国公共广播协会(PBS)制作播出的儿童教育电视节目,该节目于1969年11月10日在全国教育电视台(PBS的前身)上首次播出。它是迄今为止,获得艾美奖奖项最多的一个儿童节目。
从ELMO开始,一系列的预训练语言模型皆以该剧中的角色命名,甚至ERNIE还有清华和百度两个版本。。。
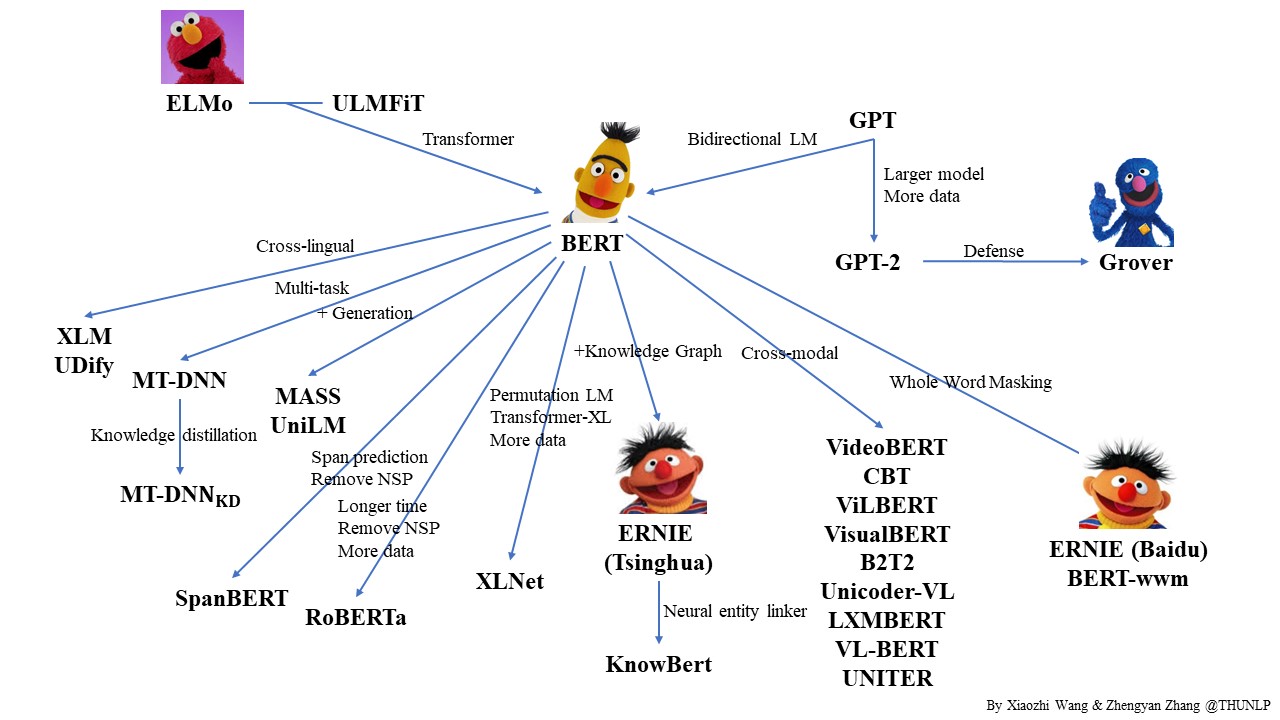
- 传统word2vec无法解决一词多义,语义信息不够丰富,诞生了ELMO。
- ELMO以lstm堆积,串行且提取特征能力不够,诞生了GPT。
- GPT 虽然用transformer堆积,但是是单向的,诞生了BERT。
- BERT虽然双向,但是mask不适用于自编码模型,诞生了XLNET。
- BERT中mask代替单个字符而非实体或短语,没有考虑词法结构/语法结构,诞生了ERNIE。
- 为了mask掉中文的词而非字,让BERT更好的应用在中文任务,诞生了BERT-wwm。
- Bert训练用更多的数据、训练步数、更大的批次,mask机制变为动态的,诞生了RoBERTa。
- ERNIE的基础上,用大量数据和先验知识,进行多任务的持续学习,诞生了ERNIE2.0。
- BERT-wwm增加了训练数据集、训练步数,诞生了BERT-wwm-ext。
- BERT的其他改进模型基本靠增加参数和训练数据,考虑轻量化之后,诞生了ALBERT。
https://mp.weixin.qq.com/s/kwKZfNSYTzc-PGKxTxm8-w
复旦大学:最新《预训练语言模型》2020综述论文
https://zhuanlan.zhihu.com/p/115014536
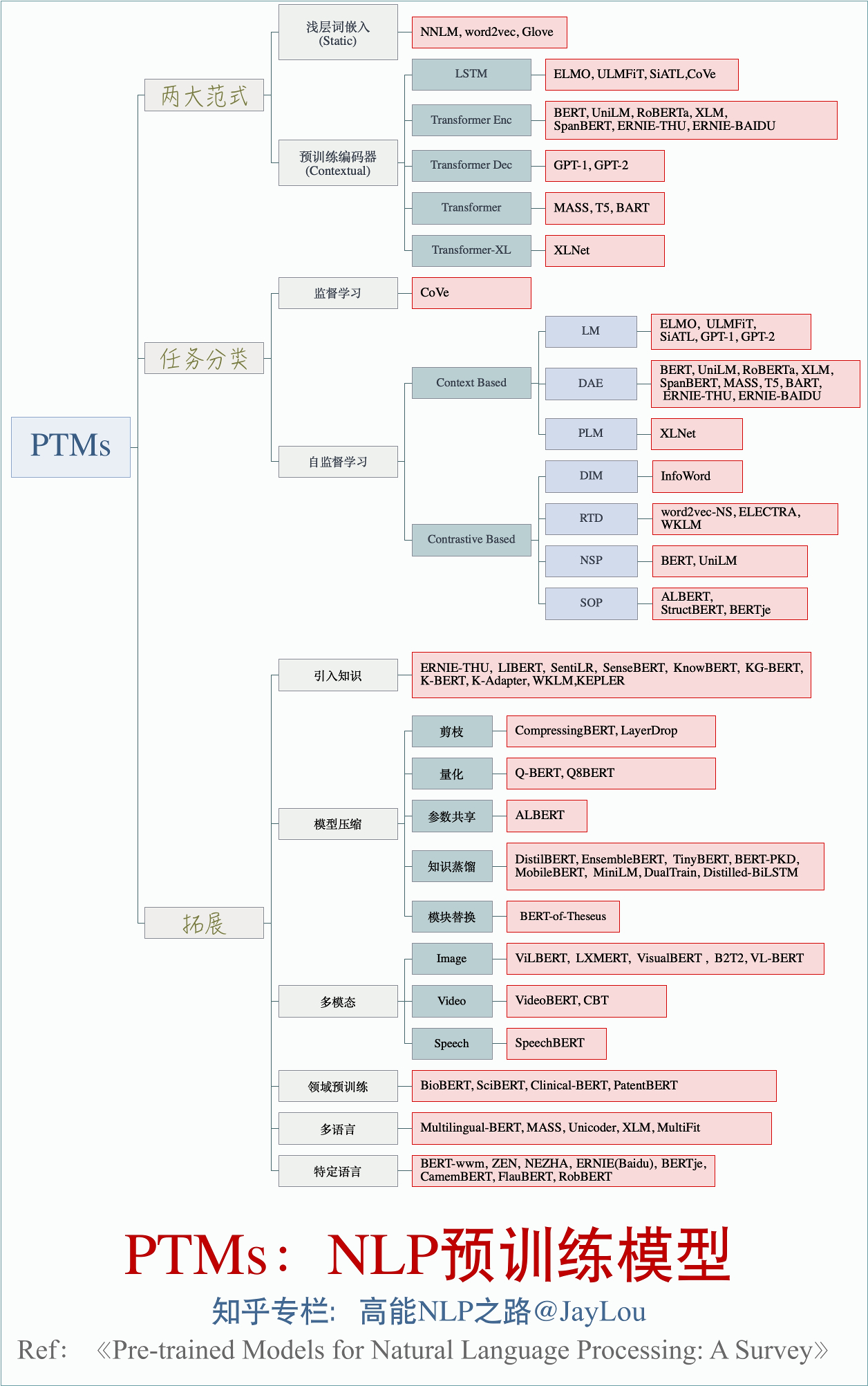
全面总结!PTMs:NLP预训练模型
https://mp.weixin.qq.com/s/WNsJ9WZdYxvT1UTYwjLTyg
按照时间线帮你梳理10种预训练模型
https://mp.weixin.qq.com/s/WDXGCC_MPK_sBCj4Bx6EDw
从静态到动态,词表征近几十年发展回顾
https://mp.weixin.qq.com/s/vW8jglstKsR7OSbyjexKrQ
自然语言处理嵌入:语义向量表示理论与进展,从Word2Vec到BERT,163页pdf
https://mp.weixin.qq.com/s/tokxh7Conb-hajj8pnr2fA
Google BERT作者Jacob斯坦福亲授《上下文词向量与预训练语言模型: BERT到T5》43页ppt
https://mp.weixin.qq.com/s/FRfjOSbnquQeFSBDI1FWwg
6个你应该用用看的用于文本分类的最新开源预训练模型
https://mp.weixin.qq.com/s/UVeWDavdHxmziUWW39jrkA
原理篇一:从one-hot到Word2vec
https://mp.weixin.qq.com/s/JSWw5RBgQoW-PrfIhbMtjQ
原理篇二:从ELMo到ALBERT
https://zhuanlan.zhihu.com/p/69290203
Transformer结构及其应用详解–GPT、BERT、MT-DNN、GPT-2
https://mp.weixin.qq.com/s/Jf0uKIjwaBbzNCB7IiTjpA
预训练模型专辑(一)
https://mp.weixin.qq.com/s/pl27hVrphiFHYqZU85KGFw
预训练模型专辑(二)
https://zhuanlan.zhihu.com/p/145701656
预训练语言模型们(上)
https://zhuanlan.zhihu.com/p/146193549
预训练语言模型们(下)
https://mp.weixin.qq.com/s/BhcnTmSje983MYT_alEiiw
一文盘点预训练神经语言模型
https://mp.weixin.qq.com/s/RKA_RxTQkIeJX3_VIKJiRQ
周明:预训练模型在多语言、多模态任务的进展
https://mp.weixin.qq.com/s/3fmZs1sFNW4IGmtql4KsVQ
邱锡鹏:自然语言处理中的预训练模型,90页ppt
https://mp.weixin.qq.com/s/irb_-T1T9sthW888hP6L4w
清华、复旦、人大联合推出43页预训练模型综述
预训练语言模型的前世今生
https://mp.weixin.qq.com/s/1ixYjJN-bJPGrr7v-4d7Rw
萌芽时代
https://mp.weixin.qq.com/s/g4jEVU3BkRem-DYXCn5eFQ
风起云涌
https://mp.weixin.qq.com/s/U8f0cXoPrN32PM3944Oqkg
十分钟了解文本分类通用训练技巧
https://mp.weixin.qq.com/s/uAJ_05g0Zo33mgygTnow1Q
银色独角兽GPT家族
https://mp.weixin.qq.com/s/2_MXIEk5-JP5KwsV6al9XQ
BERT,开启NLP新时代的王者
https://mp.weixin.qq.com/s/sMocYFvESXoBGtX_NWmQkQ
百度出品ERNIE合集,问国产预训练语言模型哪家强
https://mp.weixin.qq.com/s/uOGNoePkwfeixTtI4q4t8Q
MT-DNN(KD) : 预训练、多任务、知识蒸馏的结合
https://mp.weixin.qq.com/s/MXZ3ygSqwyXqOH1PrWEGqg
Transformer-XL超长上下文注意力模型
https://mp.weixin.qq.com/s/6XX2tkp2dbIEKqumnIQWbg
跨语种语言模型
https://mp.weixin.qq.com/s/U1O3j4FBRdiwlRjjlzbWJQ
XLNet:公平一战!多项任务效果超越BERT
https://mp.weixin.qq.com/s/f6RwSHz3Nc68oipHdYDVTw
RoBERTa: 捍卫BERT的尊严
https://mp.weixin.qq.com/s/fneyUitoQL6ZqX3xU9WpDg
跨模态语言模型
https://mp.weixin.qq.com/s/vgEKI9HjWDpkeSZQT2d8Qg
ENRIE(Tsinghua):知识图谱与BERT相结合,为语言模型赋能助力
https://mp.weixin.qq.com/s/hLt2SnVovrLeNpuMUH1OSg
预训练模型的技术演进:乘风破浪的PTM
BERT
概述
论文:
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
代码:
https://github.com/google-research/bert
BERT算的上是Google暴力美学的新作了(2018.10)。如果用家用显卡GTX 1080Ti的话,大概需要几个月的训练时间。幸好Google已经提供了预训练的模型:
https://github.com/google-research/bert/blob/master/multilingual.md
这里有一个使用预训练模型的参考代码:
https://github.com/macanv/BERT-BiLSMT-CRF-NER
这里有一个可视化工具:
https://github.com/jessevig/bertviz
Tool for visualizing attention in the Transformer model(BERT, GPT-2, XLNet, and RoBERTa)
https://github.com/thunlp/PLMpapers
预训练语言模型关系图+必读论文列表,清华荣誉出品
老规矩,最佳教程还是推荐Jay Alammar的:
http://jalammar.github.io/illustrated-bert/
图解BERT
https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/
A Visual Guide to Using BERT for the First Time
https://poloclub.github.io/transformer-explainer/
TRANSFORMER EXPLAINER
基本结构
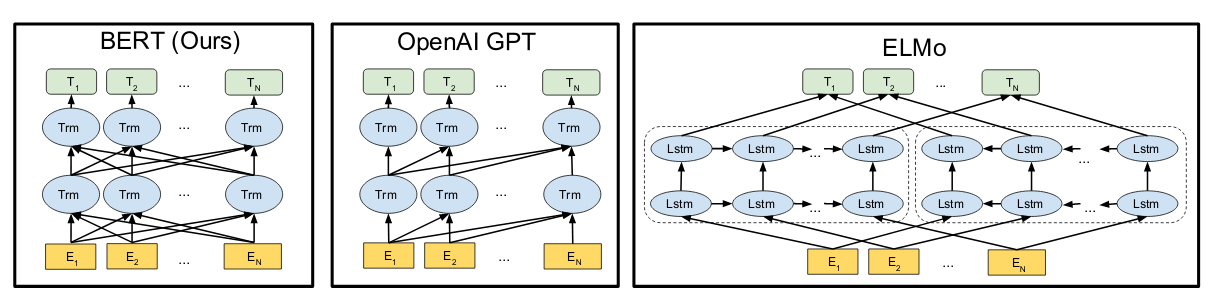
上图是BERT的网络结构图。
BERT是Bidirectional Encoder Representations from Transformers的缩写。从这个名字可以看出它将Transformer中的encoder作为一个基本单元,然后采用了类似双向RNN的方式,做了一个双向的Transformer的结构。
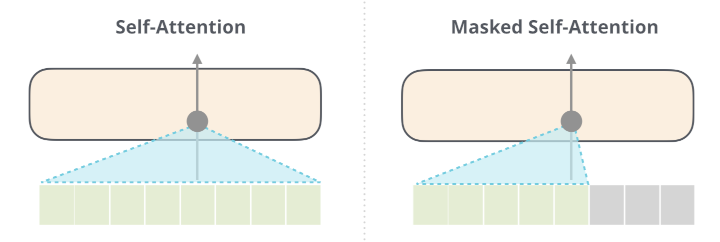
无论双向,还是单向,其实结构都是一样的,差别仅仅在于有无Mask遮住后面的内容而已。
pre-training
BERT的强大,主要不在网络结构上。上面提到的GPT 1.0虽然输给了BERT,但网络更深、向量维度也更大的GPT 2.0却赢了BERT,可见单向或者双向的Transformer,并不是问题的关键。让这些模型真正强大的原因主要在于pre-training。
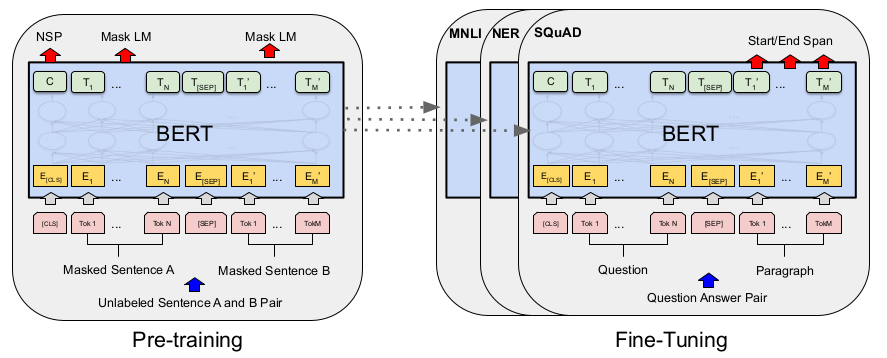
上图是BERT的pre-training和fine-tuning的结构图。
所谓的pre-training其实就是海量文本的无监督学习。
如何进行无监督学习呢?
BERT主要用了两个任务:
-
Masked Language Model,MLM。随机盖住一句话的某个词,让NN去预测这个被盖住的词。
-
Next Sentence Prediction,NSP。预测下一段话。
这两个任务,算是NLP的老任务了。但在传统的NLP pipeline中,属于非常下游的任务。BERT利用它们的特点,进行无监督学习,算是一个很大的突破了。
海量文本
BERT以及后来的GPT 2.0取得重大突破的关键,还在于海量的训练文本。
BERT拥有3.3亿个参数,训练数据包括:BooksCorpus(800M words)和English Wikipedia(2500M words)
GPT 2.0拥有15亿个参数,训练数据除了上述之外,还包括了800M个网页的文本。
如此海量的参数和数据,注定了这些模型的训练是一个超费算力的过程。NLP的游戏规则将变成:
-
土豪大科技公司靠暴力上数据规模,上GPU或者TPU集群,训练好预训练模型发布出来,不断刷出大新闻。通过暴力美学横扫一切,这是土豪端的玩法。
-
而对于大多数人来说,你能做的是在别人放出来的预训练模型上,做小修正,或者刷应用,或者刷各种榜单,逐步走向了应用人员的方向,这是大多数NLP从业者,未来几年要面对的dilemma。
fine-tuning
fine-tuning是针对实际业务数据进行的微调。下图展示了在若干任务中进行fine-tuning的网络设计。
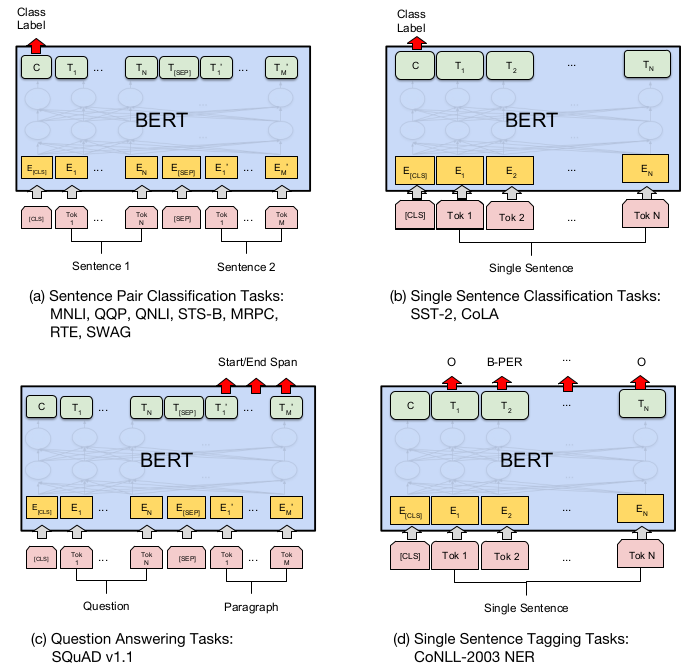
其他NLP任务的网络设计,可以参看后面《GPT》一节的配图。
值得一提的是,GPT 2.0的实践表明:海量的无监督训练已经能达到很好的效果,fine-tuning只是锦上添花而已。
事实上,在CV领域也可以看到,通过海量图片训练出的预训练网络,比随机初始化有效率多了。
input embeddings
BERT对于input embeddings也做了改进。(如下图所示)
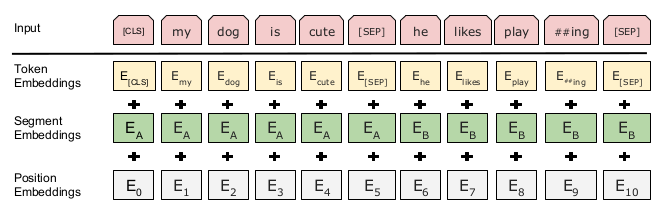
其中,Segment Embeddings用于区分输入中的不同句子。这一方案的使用,使得输入文本不再局限于一句话之内,从而大大增加了输入文本的长度,对于获得文本的全局信息,很有好处。
NMT
BERT的论文并未提到执行NMT任务时的网络结构,但从下面的论文:
《Incorporating BERT into Neural Machine Translation》
可以看出NMT的网络结构仍然是和Transformer类似的seq2seq结构:
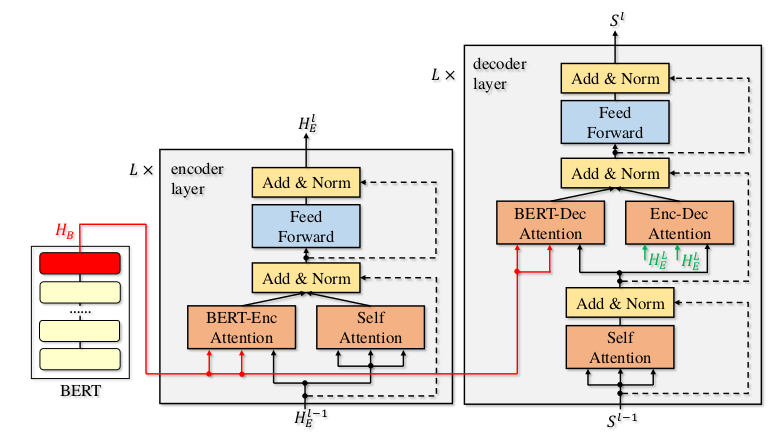
也就是说,仍然有decoder部分,仍然不能完全并行。
ELMo
https://mp.weixin.qq.com/s/I315hYPrxV0YYryqsUysXw
NLP的游戏规则从此改写?从word2vec, ELMo到BERT
https://mp.weixin.qq.com/s/VL09dIQE6kAUzj5-CRFoXA
ELMo的朋友圈:预训练语言模型真的一枝独秀吗?
https://mp.weixin.qq.com/s/1nZV6wXzeIxIAAovFOageA
手把手教你用ELMo模型提取文本特征
https://mp.weixin.qq.com/s/S3dISq03PDXPvFsL4xjzNQ
通俗理解ELMo
https://zhuanlan.zhihu.com/p/37684922
ELMo
https://mp.weixin.qq.com/s/i7EJSNzDsNNbK2YA_YNu8g
词向量与ELMo模型
https://mp.weixin.qq.com/s/qbXZGiKYEuTI-2l4iYZlbQ
图文并茂带你细致了解ELMo的各种细节

您的打赏,是对我的鼓励
