AI » Hbase, 多维数组的行优先和列优先
2019-07-18 :: 4466 WordsHbase
官网:
http://hbase.apache.org/
快速开始:
http://hbase.apache.org/book.html#quickstart
启动脚本:
1.HDFS
sbin/start-dfs.sh
2.Hbase
bin/start-hbase.sh
参考:
http://www.cnblogs.com/cenyuhai/
这个blog专注于hadoop、hbase、spark。
http://www.cnblogs.com/nexiyi/p/hbase_shell.html
HBase的常用Shell命令
http://www.cnblogs.com/Dreama/articles/2219190.html
Hadoop+HBase伪分布式安装配置
https://sourceforge.net/projects/haredbhbaseclie/
HareDB HBase Client是一个Hbase的Web GUI客户端,比较好用。
基本概念
HBase以表的形式存储数据。表有行和列组成。列划分为若干个列族/列簇(column family)。
| Row Key | column-family1 | column-family2 | column-family3 | |||
| column1 | column2 | column1 | column2 | column3 | column1 | |
| key1 | ||||||
| key2 | ||||||
| key3 | ||||||
如上图所示,key1,key2,key3是三条记录的唯一的row key值,column-family1,column-family2,column-family3是三个列族,每个列族下又包括几列。比如,column-family1这个列族下包括两列,名字是column1和column2。
HBase中,将一个Column Family中的列存在一起,而不同Column Family的数据则分开。
不要在一张表里定义太多的column family。目前Hbase并不能很好的处理超过2~3个column family的表。因为某个column family在flush的时候,它邻近的column family也会因关联效应被触发flush,最终导致系统产生更多的I/O。
吐槽一下。既然2~3个column family的表都支持的不好,那么似乎表明column family在现阶段只是一个设计的概念,离实用尚有距离。这样做的用意,大概是期待有一天Hbase把这个特性做好之后,上层应用可以无须修改吧。
参考:
https://mp.weixin.qq.com/s/ElmuT_Z2UIavFKUlSM7rZw
HBase RowKey与索引设计
HBase架构
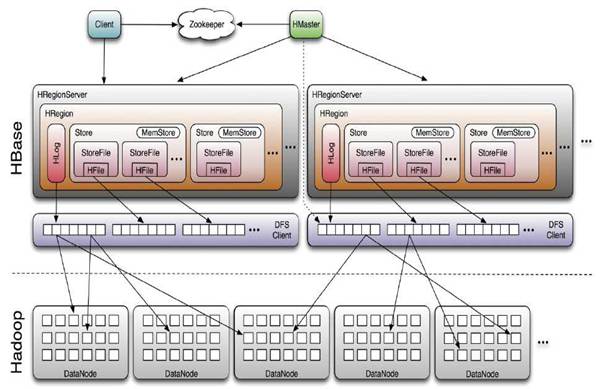
HBase在物理上是HDFS上的文件,因此它也是主从结构的。
常用的HBase Shell命令
这些命令可在hbase的控制台输入。进入控制台:
bin/hbase shell
| 名称 | 命令表达式 |
|---|---|
| 查看当前用户 | whoami |
| 创建表 | create ‘表名称’, ‘列名称1’,’列名称2’,’列名称N’ |
| 添加记录 | put ‘表名称’, ‘行名称’, ‘列名称:’, ‘值’ |
| 查看记录 | get ‘表名称’, ‘行名称’ |
| 查看表中的记录总数 | count ‘表名称’ |
| 删除记录 | delete ‘表名’ ,’行名称’ , ‘列名称’ |
| 删除一张表 | 先要禁用该表,才能对该表进行删除,第一步 disable ‘表名称’ 第二步 drop ‘表名称’ |
| 查看所有记录 | scan “表名称” |
| 查看某个表某个列中所有数据 | scan “表名称” , [‘列名称:’] |
| 更新记录 | 就是重写一遍进行覆盖 |
二级索引
原生态的HBase由于是按列存储的key-value对,原则上只能通过key查询value,因此无法创建主键之外的索引。然而,二级索引在当前的数据应用中,已经相当普遍了。如何解决这一问题呢?
方法一:将需要创建键的若干列的内容放到key中。比如,某数据表需要对日期和地点建索引,则key的值可以写成“2017-北京”这样的形式。
这个方法的缺点在于,放入key中的列相当于是行存储结构,会降低查询效率。设想一下,如果所有列都放到key中,那么实际上这个数据表就退化成了普通的按行存储的关系数据库了。
一般来说,采用方法一的数据表其key中包含的列数不应超过10个。
方法二:外挂二级索引库。目前主要实现的方案有ITHBase,IHBase,CCIndex,华为二级索引和360二级索引等。这些方案的实现细节虽有差异,但原理上都差不多,即:在数据本身之外,创建专门的数据结构用于存放二级索引。
细节可参考:
http://blog.csdn.net/dhtx_wzgl/article/details/49423979
HBase学习之二级索引
参考
https://mp.weixin.qq.com/s/ucQgmb1NkdyfAw6wDTyWYg
阿里HBase又放出了哪些大招?
https://mp.weixin.qq.com/s/BICJgyv2Y8r0j5Jjw6weRw
大数据查询——HBase读写设计与实践
https://blog.csdn.net/odailidong/article/details/41794403
Hbase万亿级存储性能优化总结
https://mp.weixin.qq.com/s/kJbeuu3zqRxQxVN38Z4asA
你应该知道的HBase基础,都在这儿了
https://mp.weixin.qq.com/s/Bl1NT-pgSseImLEd9f6xzA
Apache HBase的现状和发展
https://mp.weixin.qq.com/s/xWNSI9jZVIYaGxdBsSB8gw
快手HBase在千亿级用户特征数据分析中的应用与实践
https://mp.weixin.qq.com/s/pQbsGxM59fgQMYH54ETk7Q
面试集锦-HBase
https://mp.weixin.qq.com/s/vyF0VAF8xjEWrBnS1_DtkA
用HBase做高性能键值查询?
多维数组的行优先和列优先
这里以numpy为工具,介绍一下多维数组的行优先(Row-Major)和列优先(Column-Major)的概念。
首先我们生成一个3x4的数组:
arr = np.arange(12).reshape(3,4)
它的形状是这样的:
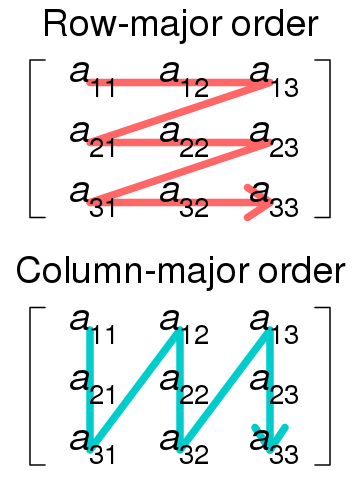
如果我们按照C语言的方式存储它,也就是行优先存储的话,那么在内存中,它的形状是这样的:

这种存储方式又被称作C contiguous array。
另一派存储方式,也就是列优先存储,它的代表是Fortran语言。上面的数组在内存中的形状就是这样的了:

这种存储方式又被称作Fortran contiguous array。
上述描述也可用下图表示:
numpy对这两种方式都支持,而且还巧妙的利用了两者之间的差异,对运算进行了简化。
arr2 = arr.T
比如上述转置操作,你以为numpy真的做了转置运算吗?其实不然。
>>>arr.flags.f_contiguous
False
>>>arr2.flags.f_contiguous
True
看到没,这里仅仅设置了一个标志而已。
类似的还有np.transpose这样的操作,也是设置一个标志而已。但有的情况下,函数会要求数组元素在内存中的连续性,这时就需要使用np.ascontiguousarray处理之。
C和Fortran的这种差异,实际上是上世纪60年代,两大IT巨头AT&T和IBM之间战争的结果,并深远的影响了后来的软件。比如在通用计算领域,主要采用C格式,而数值计算领域,则多采用Fortran格式。
典型的例子是Matlab。它最早是作为一些Fortran数学库的封装而存在的,因此很自然的采用了Fortran格式。OpenGL、OpenVX之类的接口,实际上也沿袭了这种路径依赖。
Fortran作为最早的高级语言(1957年),至今仍有很强的生命力,这主要归功于:
1.对数组、复数等数值计算的原生支持。这些语法糖,对于非程序员的科技人员很友好。
2.没有指针等复杂特性。这一点既降低了上手的门槛,又对于编译器优化(尤其是现在比较流行的并行计算优化)很有好处。普通科技人员即使没有经过特殊的程序训练,也可以写出非常高效的程序。
FORTRAN有一条规则,名叫i到n规则 :如果不明确定义变量类型,那么第一次使用这个变量时,凡是以i、j 、k 、l、m、n开头的变量,为整型变量,凡是不以这些字母开头的变量,为实型变量。
https://www.zhihu.com/question/24890607
为什么习惯使用i、j、k等作为循环变量?
https://mp.weixin.qq.com/s/S4KDsiwK7FChShUkgjZzjg
仅剩1位73岁开发者苦撑!能求解超复杂物理方程式的计算程序,要没人维护了
对于同样的内存布局,我们只需要颠倒下标就可以进行行/列优先的转换:
例如Caffe的默认格式是: NCHW,行优先。
而OpenVX是:WHCN,列优先。
两者在内存中的布局是完全相同的。
到了TensorFlow,内存布局问题有了更进一步的抽象。TF将内存布局称为physical dimensions,而将数组下标称为logical dimensions。
定义如下术语:
- the most minor physical dimension (fastest varying index)
- the last the most major (slowest varying index)
使用minor_to_major的方式表示logical dimensions。
例如:
f32[8,100,100,4]{3,0,2,1},其中[8,100,100,4]表示logical dimensions,{3,0,2,1}表示minor_to_major。则the most minor index为3,也就是the most minor physical dimension为4。

您的打赏,是对我的鼓励
