AI » OpenVX, Kubernetes
2017-09-05 :: 5528 WordsOpenVX
Khronos Group
Khronos Group是一个行业组织,创建开放标准以实现并行计算、图形、视觉、传感处理和动态媒体在各种平台和设备上的编写和加速。Khronos标准包括Vulkan, OpenGL, OpenGL ES, WebGL, OpenCL, SPIR-V, SYCL, WebCL, OpenVX, EGL, OpenMAX, OpenVG, OpenSL ES, StreamInput, COLLADA和glTF。
OpenSL:音频的硬件加速接口。
简单来说,Khronos的任务就是创建一个统一的硬件和软件之间的API,这样无论软件厂商,还是硬件厂商,都能各行其道,互不干扰了。
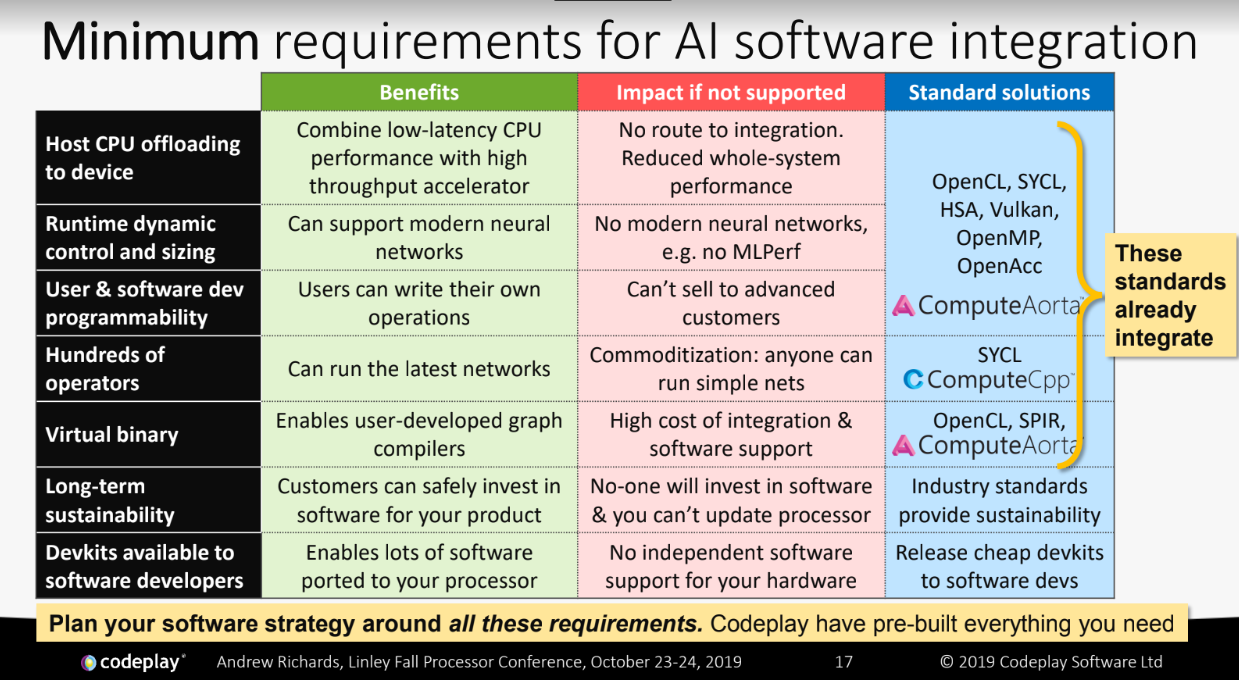
概述
官网:
https://www.khronos.org/openvx/
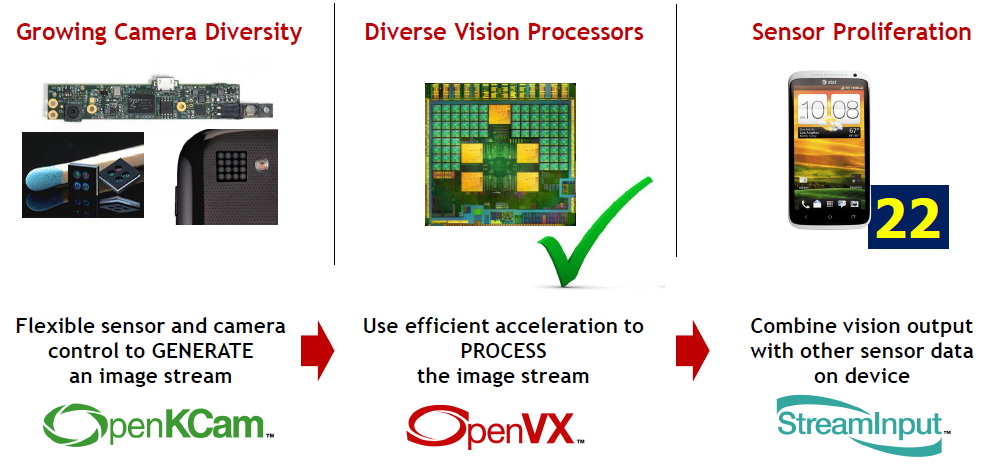
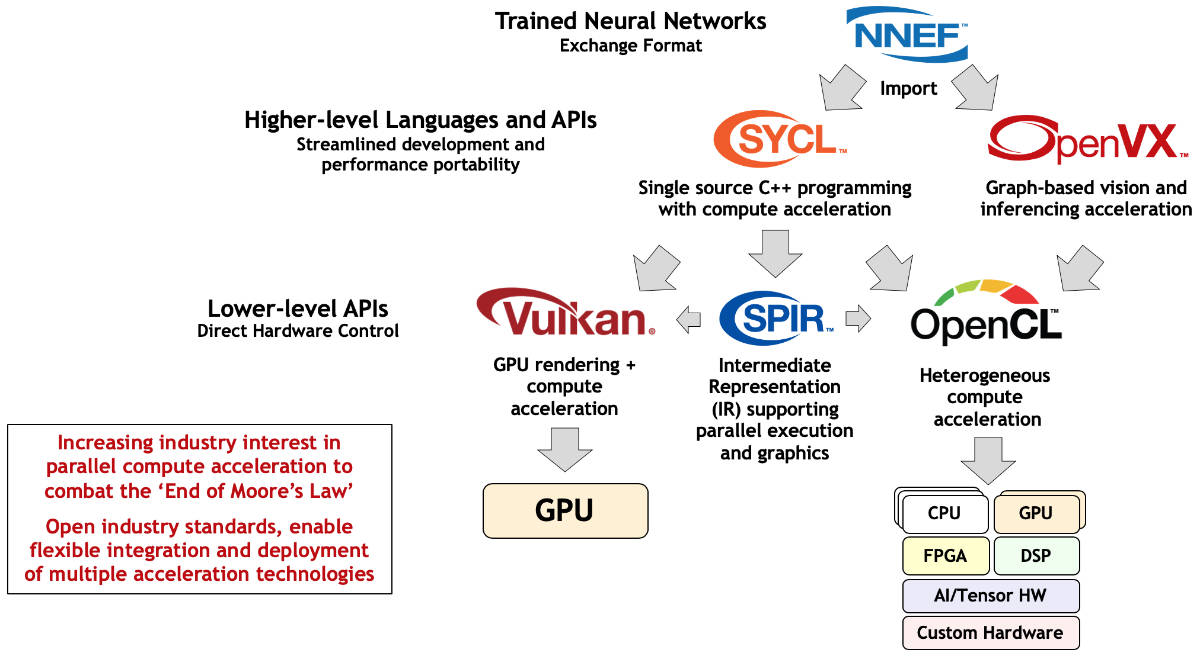
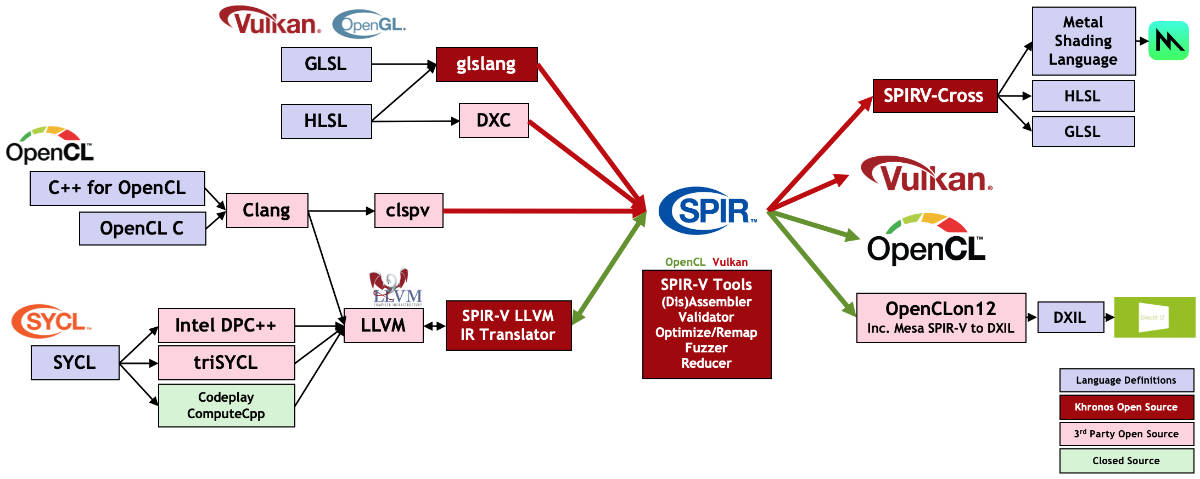
上图给出了OpenVX的主要用途,以及它和Khronos其他兄弟项目之间的关系。
OpenVX本身也是一个系列标准。它包括:
OpenVX:一个传统的CV接口。提供包括直方图、Harris、Canny等特征算子的API。
OpenVX SC(Safety Critical):安全版的OpenVX。
OpenVX NN Extension:专门用于提供NN加速方面的API。目前主要集中于CNN的加速,即卷积、池化等操作,对其他NN支持有限。此外,这些API主要用于预测,而非训练。
Khronos官方提供了一个OpenVX的软件参考实现,用于软硬件厂商的测试工作。
相关API文档和参考实现(sample code)参见:
https://www.khronos.org/registry/OpenVX/
Graph mode
Graph mode是OpenVX NN提出的一个基本概念,与之相对的则是原先VX/CL/GL系列标准的immediate mode。
尽管VX标准至今影响力有限,但Graph mode的概念却被越来越多的硬件厂商所接受,比如NVIDIA。
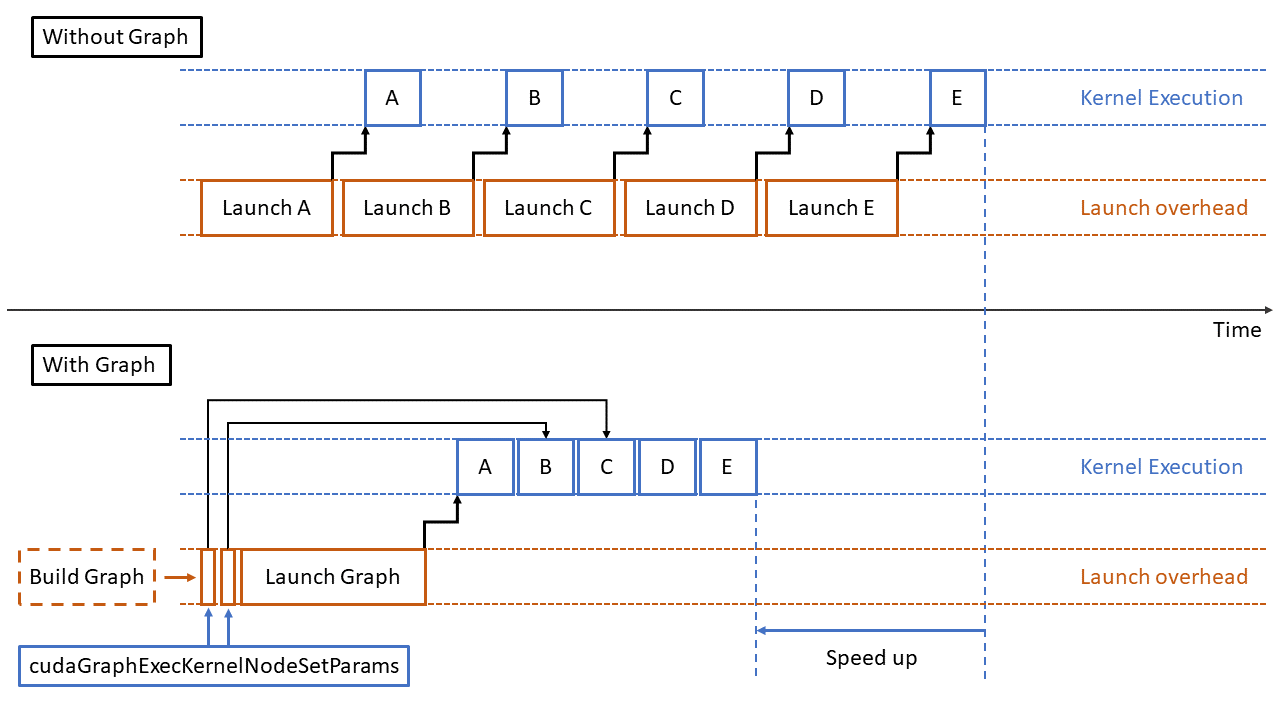
使用Graph的好处如上图所示,它主要减少了Launch阶段所需要的时间。
参考:
https://developer.nvidia.com/blog/constructing-cuda-graphs-with-dynamic-parameters
Constructing CUDA Graphs with Dynamic Parameters
https://blog.csdn.net/qq_38505858/article/details/124290876
OpenVX的立即模式(immediate mode)和图模式(graph mode)和示例讲解
Host & Device
和OpenGL类似,一般将CPU称作Host,而将GPU称作Device。App运行在Host上,而硬件加速由Device实现。
Device上的内存一般不能直接访问,需要使用vxCreateScalar、vxCreateTensor之类的API,将相关数据传到Device上。
类似的,有些API也分为Host版本和Device版本,前者用于Host和Device之间的数据交换,而后者用于Device内部数据的交换。
比如,vxCreateTensorAddressing和vxCreateTensorView,都是选择tensor的某一部分,前者是Host API,而后者是Device API。
数组的存储格式
和OpenGL一样,OpenVX中的tensor,也是列优先存储的。而C语言是行优先存储的。
行优先/列优先的概念参见《多维数组的行优先和列优先》,亦可参考下文:
http://blog.csdn.net/zhoxier/article/details/8058176
数组按行/列存储
OpenVG
OpenVG是针对诸如Flash和SVG的矢量图形算法库提供底层硬件加速界面的免授权费、跨平台应用程序接口API。
官网:
https://www.khronos.org/openvg/
OpenVG和OpenGL 3D的差异:
1.OpenVG能实现的功能,OpenGL 3D都能实现,后者的功能要强大的多。
2.OpenGL 3D的基本图元是三角形,而OpenVG的基本图元是Path,也就是闭合曲线。通常来说,Path的顶点要远少于三角形。例如,绘制一个圆形,要用很多三角形拟合,但使用Path的话,用3段Bézier curve就可以表示了。
3.OpenVG支持物体任意缩放而不失真,而OpenGL 3D中的物体在大分辨率下会有锯齿。
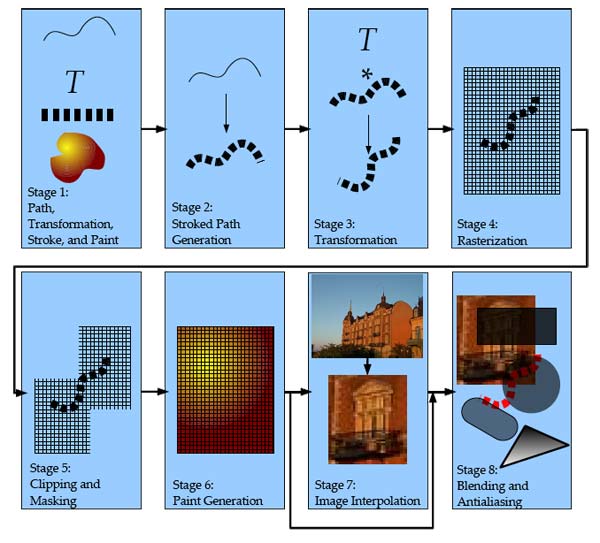
上图是OpenVG的pipeline。
一般将主打OpenVG API的显卡称为2.5D GPU。它既包含了2D GPU绘制矩形、线条的功能,同时也有一定的纹理处理的能力,而后者一般是3D GPU的配置。
Vulkan
Vulkan是OpenGL的升级版本。
在OpenGL中Context和单一线程是绑定的,所以所有需要作用于Context的操作,例如改变渲染状态,绑定Shader,调用Draw Call,都只能在单一线程上进行。
Vulkan中不再需要依赖于绑定在某个线程上的Context,而是用全新的基于Queue的方式向GPU递交任务,并且提供多种Synchronization的组件让多线程编程更加亲民。
OpenGL(ES)从来也没很好地解决过硬件设备本身的能力差异问题。
Vulkan:设备都不一样,就别假装自己上层能一样了,上层是否要一样,就让开发者自己决定吧。
Vulkan与Metal、DirectX12并称为三大现代图形API。
OGL:非常老的API,包袱重。如果想做手机端,可以用GLES,相对来说干净很多;
D3D11:状态API,有非常强大完善的驱动支持,易用并且性能非常高。并且有延迟状态模式,和D3D12很多情况下打的有来有回;
D3D12:命令机式的API,完全异步的操作模式,开始把GPU作为异步硬件的更多细节呈现给程序员,难用;
Vulkan:同上,但是全平台。因为没有D3D那么多的包袱,设计更加符合GPU行为。但加入了很多TBD/TBR概念,且信号量复杂,更加难用;
Sample:
https://github.com/KhronosGroup/Vulkan-Samples
教程:
https://vulkan-tutorial.com/
RHI:Render Hardware Interface
参考:
https://zhuanlan.zhihu.com/p/20712354
Vulkan-高性能渲染
https://www.zhihu.com/people/snowfox-68/posts
一个Vulkan的专栏
https://www.zhihu.com/question/456407362
跨平台图形编程的未来会是怎么样的?
https://zhuanlan.zhihu.com/p/456417172
关于实时渲染和图形API的一些学习资料收录
https://zhuanlan.zhihu.com/p/598557707
Vulkan渲染流程总结
https://zhuanlan.zhihu.com/p/417561163
UE4/UE5的RHI(Vulkan为例)
RenderDoc
RenderDoc是一种图形调试器,目前可用于Windows、Linux、Android、Stadia和Nintendo Switch上的Vulkan、D3D11、D3D12、OpenGL和OpenGL ES开发。
它可以分析图形的执行流程,也逆向提取游戏里的Shader、模型、贴图等信息。
官网:
https://renderdoc.org/
OpenMax
一个免费的跨平台抽象软件层,用于加速在嵌入式和移动设备上的多媒体应用程序中捕获和呈现音频、视频和图像。
但是在目前实际应用中,大部分硬件厂商主要提供算法功能,通常也以OMX IL层组件接口方式提供。所以OMX IL层的标准使用最多,DL层几乎没有厂商提供。而AL层是应用逻辑层,大部分系统也都有自己的多媒体框架,也比较少使用AL层接口。
https://zhuanlan.zhihu.com/p/366810565
OpenMax (OMX) 开发入门
DRM
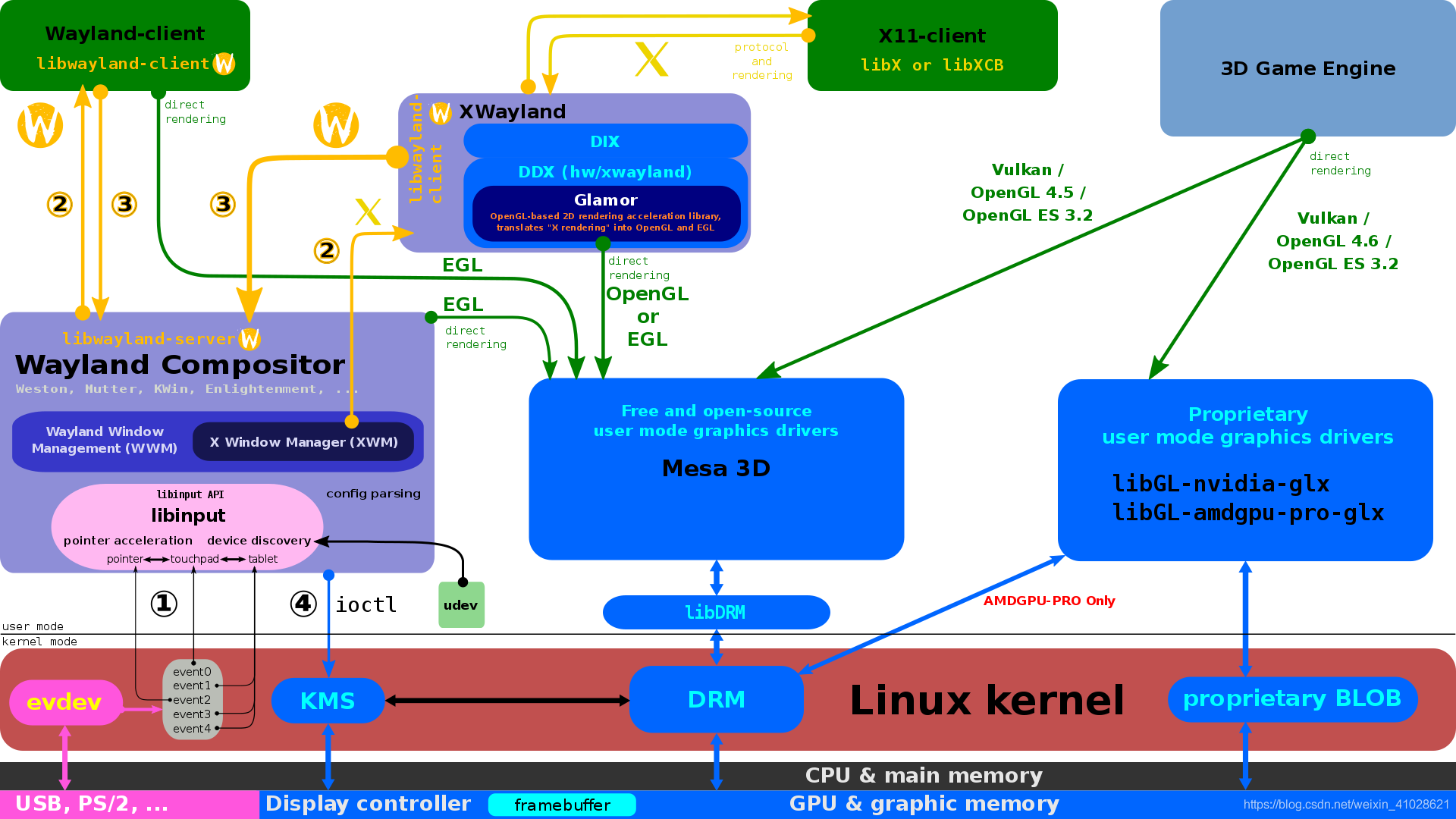
DRM是Linux内核层的显示驱动框架,它把显示功能封装成open/close/ioctl等标准接口,用户空间的程序调用这些接口,驱动设备,显示数据。
https://blog.csdn.net/weixin_41028621/article/details/110202300
Libdrm库
DDX/DRI/Glamor
DDX是X Server的2D驱动模块。
DRI的主要作用是让X客户机和X服务器直接控制硬件用的。Linux OpenGL 3D的支持就是通过DRI实现的。其最流行的实现就是Mesa了。
Glamor是一个统一的接口,用于GPU加速2D/3D应用。
SPIR-V
SPIR-V是一种用于GPU通用计算和图形学的中间语言。
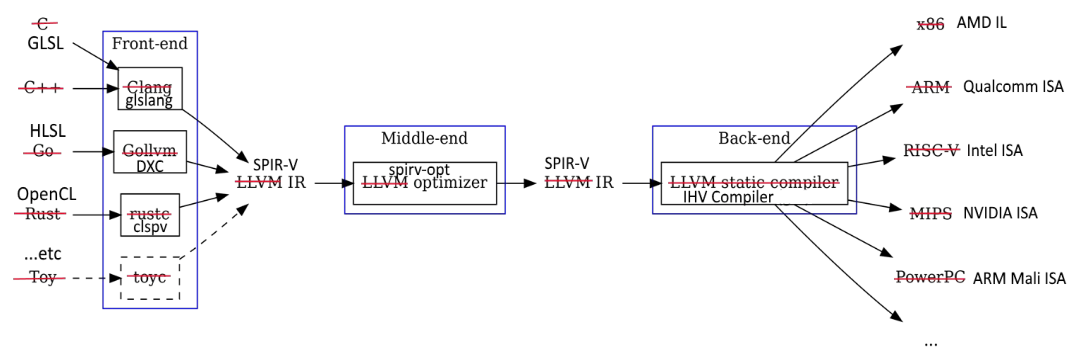
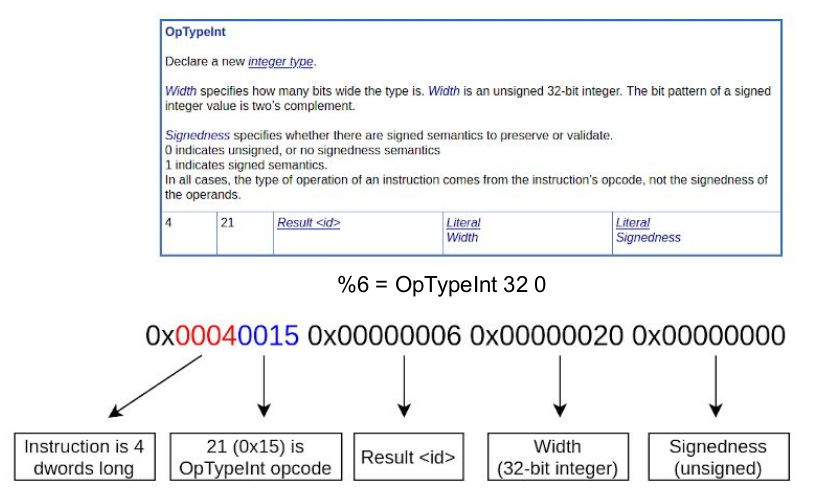
SPIR-V的二进制的,编组方式类似汇编语言。上图是一个简单的示例。
当然SPIR-V从本质上说,还只是IR,并不是机器码。上例是一个int类型的声明,体现了一切皆ID,就连类型声明也是ID的设计哲学。
而C语言,只有编译阶段有类型的概念,真到链接的时候,就已经只剩下符号表了。机器码就更不可能有类型,这种高级语言才有的特性。
DirectX也有类似的东西:DXIL(DirectX Intermediate Language)。
https://blog.csdn.net/qwertyu1234/article/details/50163847
SPIR-V研究:编译器基本原理
Kubernetes
Kubernetes是Google开源的容器集群管理系统,基于Docker构建一个容器的调度服务,提供资源调度、均衡容灾、服务注册、动态扩缩容等功能套件。因为Kubernetes中K和s之间有8个字母,因此又简称为K8s。类似的还有internationalization被称为i18n。

官网:
https://kubernetes.io/
Kubernetes还有个ML的工具集叫KubeFlow。
https://github.com/kubeflow/kubeflow
参考:
https://arthurchiao.art/blog/borg-omega-k8s-zh
Borg、Omega、K8s:Google 十年三代容器管理系统的设计与思考
https://mp.weixin.qq.com/s/HEUIWK4skqMge8oziQg6Nw
kubernetes简介和实战
http://violetgo.com/blogs/2015/10/14/k8s.html
docker学习笔记(k8s)
https://mp.weixin.qq.com/s/wwwB8OHQmbwqmKKE8Lyv-w
容器技术演化史
https://mp.weixin.qq.com/s/LpNlUlXpt2poRKXEvuIDjw
Kubernetes NetworkPolicy工作原理浅析
https://mp.weixin.qq.com/s/s5eDSQF6mFt2F9_nVtYemQ
PaaS将吞噬云计算?Kubernetes的市场冲击波
https://mp.weixin.qq.com/s/19xreKtNlllfFx43eUGhuQ
如何使用Kubernetes轻松部署深度学习模型
https://mp.weixin.qq.com/s/4e9l-GP22T-myP54hJJjPA
Kubernetes如何打赢容器之战?
https://mp.weixin.qq.com/s/iTfHv8EFx4O4G1sNxsuMkg
再见,Yarn!滴滴机器学习平台架构演进
https://mp.weixin.qq.com/s/CmHok-9gKVrHfiXpYUQ4nw
浅析Kubernetes资源管理
https://mp.weixin.qq.com/s/zzn61ADe2RA7K0L4-EMAOA
你真的需要Kubernetes吗?
https://mp.weixin.qq.com/s/2TRVWe01jHUtOioW31ukeg
如何轻松学习Kubernetes?
https://developer.aliyun.com/article/754267
31篇技术文章,带你从零入门K8s
https://mp.weixin.qq.com/s/mr_D_AA0zdux8F_10iRIHg
自动化弹性伸缩如何支持字节跳动百万级核心错峰混部
https://zhuanlan.zhihu.com/p/339008746
Kubernetes入门&进阶实战
https://mp.weixin.qq.com/s/LQY4Dw8-OwS52gt2HtBT8w
备份和迁移Kubernetes应用程序利器-velero

您的打赏,是对我的鼓励
