AI » 天池大赛, Petuum
2017-02-08 :: 4777 Words简介
天池大数据竞赛是由阿里巴巴集团主办,面向全球科研工作者的高端算法竞赛。官网:
https://tianchi.shuju.aliyun.com/
和它类似的比赛,最著名的当属国外的kaggle大赛。其官网:
https://www.kaggle.com/
但是,kaggle官网在国外,国内无论注册还是登录,都比较麻烦。
还有KDD挑战赛:
http://www.kdd.org/kdd-cup
这是ACM主办的年度数据竞赛。
此外,国内的同类竞赛还有:
http://www.datafountain.cn/
京东、搜狗投放的赛事。
https://biendata.com/
知乎投放的赛事。
https://challenger.ai/
由创新工场、搜狗、今日头条联合发起。
https://mp.weixin.qq.com/s/LgFpuRXfKtxS1tlPApgp8w
国内NLP竞赛平台一览
我之前虽然参加了其中的“广东航空大数据创新大赛——机场客流量的时空分布预测”(2016.9~2016.11),然而由于首次参赛,各项准备和工具都不纯熟,仰仗队友给力,最终获得了第318名。
注意:手机登录天池网站的时候,浏览器必须选择手机模式,否则无论账号密码正确与否,都无法正常登录。
口碑商家客流量预测
概况
本次“口碑商家客流量预测”大赛由蚂蚁金融服务集团,IJCAI 2017,阿里云主办。
IJCAI是International Joint Conferences on Artificial Intelligence Organization的缩写,属于人工智能领域顶级会议之一。
比赛的内容和数据参见:
https://tianchi.shuju.aliyun.com/competition/introduction.htm?spm=5176.100066.333.4.0eh92S&raceId=231591
数据分析工具
主办方提供了大约2G的原始数据。这个数据量采用Hadoop+Spark无疑是大才小用了。但是,数据库尤其是SQL语言,在数据的整理和初步分析中的地位是无可替代的。因此,这里我选择了MySql数据库。
机器学习库的语言有两个选择:R或python。考虑到以后研究tensorflow的需要,我选择了python语言,这个相对来说更通用、更熟悉一些。
数据的预处理
将官方提供的csv数据导入数据库。这里全部使用SQL语言。
1.根据官方提供的数据格式建立table。
2.使用load语句导入csv文件。
数据的初步分析
这里首先对user_pay和user_view两张表进行粗粒度的统计。比如,统计两表中最热的10家店铺的类型。
这里发现一个有趣的事实:用户浏览数量最多的是火锅店,前10家中占到了9家,而用户购买最多的却是快餐店和便利店。
这实际上暗合《机器学习(十六)》中提到的显式反馈和隐式反馈的区别。
因为隐式反馈的数据有效性(这里指单位数据中包含的有效信息的数量,也可称作信息丰度)不如显式反馈,所以通常需要有多出1到2个数量级的隐式反馈数据,才能得到足够的信息以辅助预测显式反馈。
而官方的数据正好相反,隐式反馈数据的数量只有显式反馈的十分之一,且并不包含待预测时间段的数据。因此,user_view实际上是没什么用的数据。
select count(distinct user_id) from user_pay;
select count(*) from user_pay;
其次,对用户行为进行分析。诚如论坛某网友指出的,这批数据平均下来一个用户还不到4条交易记录(19583949个用户,69674110条交易记录),这都能找出规律,那就不是人而是神了。
针对这样的分析,为了便于计算,我们新建了shopcount表用于存放店铺的客流数据,而忽略客流本身的其他信息(这里主要是user_id)。
新建shopcount表之后,计算效率得到极大的提升,原来从user_pay中查询一个店铺的客流信息需要2分钟左右的时间,而现在不到1秒钟。
数据建模初步
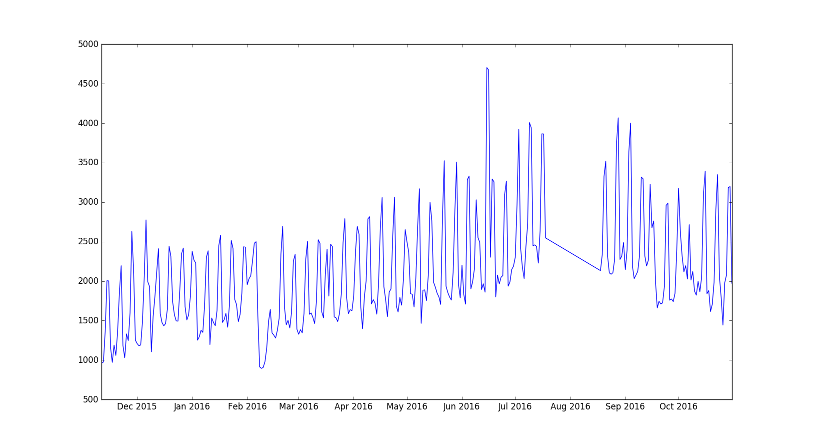
上图是其中一家店铺的客流数据。从直观上来看,这样的波形十分类似信号处理领域中的:一个低频信号叠加一个高频信号。
因此,该数据的模型可定义为:
\[f=f_{low}+f_{high}\tag{1}\]其中,\(f_{high}\)表示高频信号。通过测量两个波峰的间隔,不出意料的,这个时间间隔是一周。这与人们的日常常识也是吻合的。
\(f_{low}\)表示低频信号,也就是每周平均客流量的长期变化函数。
数据清洗
对于图中数据波形不规则的地方,稍加留意就可以发现:不规则的数据主要出现在节日,尤其是春节、五一和国庆。而待预测的时间段不在重大节日期间。因此,需要将上述时段的数据排除在统计之外。
数据建模进阶
公式1需要进一步细化为可执行的算法。考虑到一周的客流数据是离散数据,因此\(f_{high}\)拟合的一种最简单的方法就是:
1.统计每周一的数据,计算周一的均值\(D_1\)。
2.按照第1步的方法,统计周二、周三、……、周日的均值\(D_2,\dots,D_7\)。
3.令
\[D=\frac{D_1+\dots+D_7}{7}\]则\(f_{high}\)的离散采样为:
\[\{\frac{WD_1}{D},\dots,\frac{WD_7}{D}\}\tag{2}\]其中W表示基数,它的值由\(f_{low}\)来确定。
我们可以从另一个角度来观察公式2。如果把客流分为固定客流和变化客流的话,则客流模型也可写作:
\[f=f_{fix}+f_{alter}\]如果将周最小客流值\(D_{min}\)定义为\(f_{fix}\)的值的话(假设1),可以观察到\(\frac{D_{min}}{D}\)的值,并不随D的大小变化而有显著改变。也就是说平均客流的一定比例转化为了固定客流。假定这个转化比例不变(假设2),则可推出公式2的结论。
\(f_{low}\)(也就是公式2中的W)就没有那么规律了,这里我做了如下尝试:
Method 1
令\(W=W(-1)=W(0)=W(1)\)。待预测时间段为2周,我们将其中的第1周的客流均值记作\(W(0)\),第2周的记作\(W(1)\)。其他的可以此类推。
这种方法的Loss为0.085647。
Method 2
Method 1相当于是\(f_{low}\)在\(W(-1)\)处进行常数展开。为了更精确的描述函数,我们亦可考虑进行一次项展开。即:
\[W(0)=W(-1)+W'(-1),W(1)=W(0)+W'(-1)\]\(W'(-1)\)原则上可以用\(W(-1)-W(-2)\)获得,但是由于数据的短期波动性较大,这样求得的斜率稳定性很差,不适合用于预测。
可以对W使用FIR滤波和IIR滤波,然后用滤波值计算,以获得稳定的斜率。
Method 2的最终结果并不理想,无论是沿着梯度方向,还是相反方向都得不到更好的结果。但是针对W的FIR滤波和IIR滤波取得了较好的结果。
最终Loss为0.08500277。
天气因素
论坛上有网友提供了相关的天气数据。经过我的分析,恶劣天气的确会减少客流量,这也与常识相符。
然而,待预测时段(2016.11.1~2016.11.14)正好是我国气候最好的时段,北方秋高气爽,但又不太冷,南方的雨季和台风季也基本结束。因此,天气因素注定不会有多少发挥的空间。
模型的继续改进
Method 2中的滤波,主要针对的是某些店铺在预测时段之前流量的大起大落。在取得较好的结果之后,促使我思考另一个问题。
我在分析之初就发现,使用10月31日的值作为W值的效果,没有使用之前一周的均值作为W的效果好。那么是否使用更长时间的均值,效果会更好呢?
首先,使用IIR均值或者超过3周以上的FIR均值的情况可以排除,历史效应毕竟是历史效应,不可能一年前的数据和最近的数据影响力相等。
经过实践,我发现:
\[W(0)=\frac{W(-1)+\frac{W(-2)+W(-3)}{2}}{2}\]的效果要优于三周均值和一周均值,这即体现了历史数据的意义,也兼顾了近期数据的重要程度。
修改之后,Loss为0.08331434。
双十一效应
待预测时段虽然没有国家法定节日,但有双十一节,这个在年轻人群中有一定的知名度。而年轻人群也是使用口碑的热点人群。因此,需要对11.11的客流数据,进行一定程度的加成处理。
加成5%的结果的Loss为0.08298507。
加成15%的结果的Loss为0.08309067。
最终,加成9%的结果的Loss为0.08289156。
对于\(f_{high}\)改进的思路
双十一效应的成功,使我打算尝试进一步改进\(f_{high}\)。
尝试使用最近3周的数据,估算D值。结果Loss为0.09959968。
当然这个结果完全在我意料之中,一般来说,D值还是IIR滤波值比较准。
刷榜的终结
采用类似双十一效应的刷榜方式,实际上还可以进一步提高结果,最终我的成绩定格在0.8137。但是,这种方式显然不是我想要的,我不想再这样在没有理论依据的情况下,单纯用凑数字的方式提高成绩,于是我的参赛之旅也就终结于此了(2.21)。况且这种方式也有其极限,我估计其极限最多也就是0.809。想获得更好的成绩,一定要有其他更好的思路才行。
比赛结果及代码
最终结果:第1赛季排名:91 第2赛季排名:166
源代码:
https://github.com/antkillerfarm/antkillerfarm_crazy/blob/master/python/ml/tc/tc0215.py
创建数据库的SQL语句:
https://github.com/antkillerfarm/antkillerfarm_crazy/blob/master/helloworld/mysql/tc.sql
导入数据的SQL语句:
https://github.com/antkillerfarm/antkillerfarm_crazy/blob/master/helloworld/mysql/import.sql
其他相关中间结果表的SQL语句:
https://github.com/antkillerfarm/antkillerfarm_crazy/blob/master/helloworld/mysql/tc_view.sql
尾声
https://mp.weixin.qq.com/s/1T5Iv87JRVdTS66yAzs-DQ
IJCAI获奖团队答辩干货独家放送
https://mp.weixin.qq.com/s/3cER2nr7oiF0IrqDem3bkQ
时间序列异常检测—节假日效应的应对之道
Petuum
Petuum是一个机器学习专用分布式计算框架,是CMU的Eric Xing教授带头的开源项目。
官网:
http://www.petuum.com
参考:
http://liweithu.com/petuum
面向机器学习的分布式计算框架:Petuum

您的打赏,是对我的鼓励
