AI » Kettle, Solr
2016-11-10 :: 5773 WordsKettle
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。这个过程有时又被叫做“数据清洗”。
Kettle是一款国外开源的ETL工具。其官网为:
http://community.pentaho.com/projects/data-integration/
从大的方面来说,Kettle的工作,可分为Job和Trans两类。
Job是个大尺度的工作分类,它操作的对象是文件或数据库级别的。
相对的,Trans只要是些小尺度的工作。它操作的对象是Row,也就是一条记录。
Sqoop是另一个数据转换工具,但是没有IDE,功能也局限于数据格式的转换(仅相当于Kettle中的Trans)。其官网:
http://sqoop.apache.org/
Job可以调用Trans,也可以执行shell、SQL、Sqoop等多种脚本。因此,Kettle和Sqoop的关系不是二选一,而是可以协作的。
Kettle是一个大的工具集,主要包括以下组件:
1.spoon。Kettle的IDE。
2.pan。用于执行Trans文件(以ktr为后缀)。
3.Kitchen。用于执行Job文件(以kjb为后缀)。
命令行执行Job和Trans
pan -file=/path/to/ktr
kitchen -file=/path/to/kjb
参见:
http://www.cnblogs.com/wxjnew/p/3620792.html
官网资料:
http://wiki.pentaho.com/display/EAI/Pan+User+Documentation
http://wiki.pentaho.com/display/EAI/Kitchen+User+Documentation
命令行不仅可以执行Job和Trans,还可以向Job和Trans传递参数。参见pan和kitchen命令的-param选项。
Job和Trans对命令行参数的处理,有相关的插件,参见:
http://blog.csdn.net/scorpio3k/article/details/7872179
文本处理
Kettle的文本处理以“行”为单位。下图是一个实际的使用流程图:
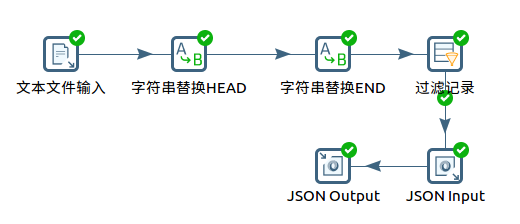
1.原始数据来自网络爬虫抓取的数据,它的主体是一个json文件,然而在每一条记录的前后都有一些特殊的字符串,因此从整体来说,并不是一个合法的json文件。
2.采用“字符串替换”插件,去除非法字符串。这里需要注意的是,由于整个过程是数据流形式的,因此,无法在一个步骤中,同时去掉前后两个字符串,而必须分为两个步骤。
3.替换之后,原先有字符串的行,可能变成空行,这是可以使用“过滤记录”插件。
文件的增量处理
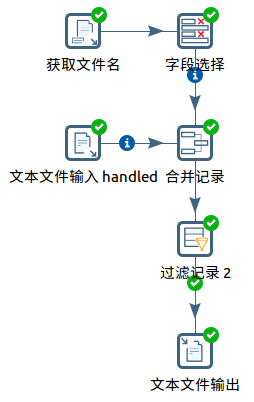
kettle没有提供直接的插件用于增量处理,因此需要自己设计增量处理的方法。
增量处理的方法很多,这里仅展示其中一种方法:
1.获得需要处理文件总表A。
注意:获取某个路径下的文件名,要用正则式,而不是常见的
*.*,*.txt。
对应关系如下:
*.* -> .*
*.txt -> .*\.txt
2.获得已经处理过的文件列表B。这个列表可以来源于数据库,也可来源于文本文件。这里采用后者。
3.使用“合并记录”插件,从A中过滤掉B。“合并记录”插件的flagfield字段,会给出合并的结果。
4.使用“过滤记录”插件,根据flagfield字段的结果,得到过滤后的列表C。C就是真正需要处理的文件列表了。
字段合并操作
Kettle并未提供“字段合并”的插件,因为这个功能如果使用Javascript的话,也就是一行的事情。
调用外部的Java库
1.首先将该库的jar包,放到Kettle的lib文件夹下。
2.其他步骤和一般Java程序没啥区别:import用到的package,然后写代码,over。
HDFS
HDFS的处理比较简单,将普通例子中的本地文件路径,替换为hdfs://形式的hdfs路径即可。
Hbase
Hbase插件中比较费解的是Mapping name这个名词。
从设计初衷来说,kettle本意上是打算利用Mapping将kettle字段映射为Hbase表格的列,从而达到分离两者概念的目的。然而当前的实现中,kettle的所有字段都必须导出到Hbase表格中,不然就会出如下错误:
Can't find incoming field "short_field1" defined in the mapping "mapping_test"
用户对Mapping所做的修改,仅限于修改字段名、设定Key、设定字段类型等。
解决办法:
使用“字段选择”插件过滤掉不必要的字段,然后再导出到Hbase。
参见:
http://forums.pentaho.com/archive/index.php/t-94392
Solr
Solr和Lucene的关系
Lucene是一个基于Java的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。
Solr是一种开放源码的基于Lucene的Java搜索服务器。它是Lucene的子项目,是Lucene面向企业搜索应用的扩展。
简单的说,Lucene是库,而Solr是一个调度Lucene库的Web服务器。
概况
官网:
http://lucene.apache.org/solr/
教程:
http://lucene.apache.org/solr/quickstart.html
网上的资料有些已经很老了,不看也罢。这是官方的Quick Start,必看之。
除了Solr,类似的软件还有senseidb和elasticsearch。参见:
http://www.cnblogs.com/ibook360/archive/2013/03/22/2975345.html
实时分布式搜索引擎比较(senseidb、Solr、elasticsearch)
相关资料:
http://www.solr.cc/blog/
http://blog.csdn.net/aidayei/article/details/6526986
solr中文分词
http://outofmemory.cn/code-snippet/3659/Solr-configuration-zhongwen-fenci-qi
Solr配置中文分词器
http://www.importnew.com/12707.html
全文检索引擎Solr系列—–全文检索基本原理
http://iamyida.iteye.com/category/338597
跟益达学Solr5系列教程
http://iamyida.iteye.com/category/335240
跟益达学Lucene5系列教程
https://mp.weixin.qq.com/s/ydIkoD3e87As_6f96mJkww
搜索那点事儿:Lucene文件存储和读取技术详解
https://mp.weixin.qq.com/s/KPsR3JlRU2g1V1w9CjTaHg
搜索引擎之倒排索引解读
https://mp.weixin.qq.com/s/P_LBnjeau4Au02Qef0OEsQ
搜索引擎核心技术与算法——词项词典与倒排索引优化
https://mp.weixin.qq.com/s/Z_HdxKrAUSa4QtVNpqvx5w
面试官:请介绍搜索引擎背后的经典数据结构和算法
https://mp.weixin.qq.com/s/R36zW4CVKkdiTQ8ZQCwEGw
通用搜索引擎背后的技术点
start命令
Solr的运行需要启动相应的服务程序。启动命令如下:
bin/solr start -e cloud -noprompt
其中的cloud表示SolrCloud示例模式,即在一台PC上启动若干进程的所谓伪分布式模式。除此之外,还有techproducts、dih、schemaless等示例模式。
这些示例模式对于快速了解Solr很有帮助。
Post工具
从本质来说,Solr是一个Web服务器。所有的服务请求都以http post的形式提交给Solr。因此,为了方便使用,Solr项目专门提供了post工具。
post工具在bin文件夹下,是一个Unix shell脚本。对于Windows用户,Solr提供了post.jar可执行文件,它在example/exampledocs下。
SolrCloud概述
这是官方Quick Start的默认模式。我们首先对一些概念进行一下讲解。(相关内容参见《Apache Solr Reference Guide》末尾的术语表)
Cluster: 由若干Node组成的集群,使用Zookeeper进行协调。这是Solr中物理层面的最大单元。
Node: 一个运行Solr的JVM实例。
文件的索引(index)用于对文件资源进行定位,它分为逻辑索引和物理索引两种。从冗余备灾的角度出发,一个物理索引被备份到若干个Node中,而这些不同Node上内容相同的物理索引,由于表示的含义是相同的,因此从逻辑上说,算是同一个逻辑索引。
在Solr中,物理索引被叫做Replica,其中副本个数被称为Replication Factor。一个Node可包含多个Replica。
由于物理索引分散在若干不同Node中,因此,其对应的逻辑索引,也分散在若干不同Node中。这些逻辑索引的其中一个实例被称为Core。因此,Core和Replica是一一对应的(尽管它们的含义不同)。显然一个逻辑索引包含了若干个位于不同Node中的Core。
若干个逻辑索引组成了一个Shard。而若干Shard组成一个Collection。Collection是Solr中逻辑层面的最大单元,类似于其他分布式系统中的Task。
属于同一个Shard的若干个Replica中,有且仅有一个Leader,用于协调索引的更新。

上图是SolrCloud模式默认情况下的图示。
其中包括一个名叫gettingstarted的Collection。这个Collection有两个Shard,每个Shard有两个Replica。
这里来个今年美国大选的梗:
记的以前有人说硅谷的政治正确已经到给程序起名字不能带slave了。所以以前熟悉的master slave模式现在很少用了。现在叫leader follower,也可以叫master worker,就是不能有slave。
Quick Start
这是官方Quick Start的摘要版本,相关步骤不做过多解释。
1.启动Solr。
bin/solr start -e cloud -noprompt
2.查看Solr Admin UI。
http://localhost:8983/solr/
2.创建索引。
bin/post -c gettingstarted docs/
索引文件默认存储在example/cloud下。
3.对索引结果进行查询搜索。
Web方式:
http://localhost:8983/solr/#/gettingstarted/query
HTTP方式:
http://localhost:8983/solr/gettingstarted/select?wt=json&indent=true&q=foundation
Luke
Luke是一个查看Lucene/Solr/Elasticsearch索引文件的工具。其官网为:
https://github.com/DmitryKey/luke
SolrCloud的其他细节
1.配置文件在server/solr/configsets/data_driven_schema_configs下。初次启动SolrCloud时,会复制到example/cloud下,但存储形式未知。
2.每个Replica存储的索引文件一般是不同的,因此使用Luke的时候,如果有些数据查询不到的话,可以到其他Replica下查询。
Solr的配置
1.Node配置
solr.xml
2.Core配置
全局配置:core.properties
Solr配置:solrconfig.xml
数据域配置:schema.xml
IKAnalyzer
IKAnalyzer是一个中文分词器。作者:林良益。
官网:
http://git.oschina.net/wltea/IK-Analyzer-2012FF
作者主页:
https://my.oschina.net/linliangyi/home
github上的fork:
https://github.com/yozhao/IKAnalyzer
参考:
http://blog.csdn.net/frankcheng5143/article/details/52292897
这个网页提供了将IKAnalyzer集成到Solr 6的办法,经测试对Solr 6.3也是适用的。
Solrj
https://wiki.apache.org/solr/Solrj
https://cwiki.apache.org/confluence/display/solr/Using+SolrJ
Lucene
http://lucene.apache.org/core/6_3_0/index.html

您的打赏,是对我的鼓励
