DL acceleration » 并行 & 框架 & 优化(七)——快速Transformer
2024-06-27 :: 5460 WordsKV Cache
MLA(续)
需要注意,上述矩阵吸收的技巧没有考虑ROPE的影响,实际情况还要更复杂一些。
类似的,还有GLA。
https://github.com/deepseek-ai/FlashMLA
deepseek的MLA官方实现
参考:
https://kexue.fm/archives/10091
缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA
https://www.zhihu.com/question/655172528
如何看待DeepSeek发布的MoE大模型DeepSeek-V2?
https://huggingface.co/blog/Junrulu/mla-codebased-analysis
结合Deepseek代码探讨MLA的改进及收益
https://zhuanlan.zhihu.com/p/697781431
还在用MHA?MLA来了DeepSeek-v2的MLA的总结和思考
https://zhuanlan.zhihu.com/p/703862723
大模型KV Cache节省神器MLA学习笔记(包含推理时的矩阵吸收分析)
https://blog.csdn.net/v_JULY_v/article/details/141535986
一文通透DeepSeek V2——通俗理解多头潜在注意力MLA:改进MHA,从而压缩KV缓存,提高推理速度
https://mp.weixin.qq.com/s/uiBPpZDyVhySP8eKKaIygw
再读MLA,还有多少细节是你不知道的
KV Cache Architecture
KV Cache从诞生之初就是一个工程问题,上面主要讨论的是算法优化,而本节则聚焦于Architecture领域。
在Mooncake中,直接利用RDMA和GPUDirect技术,在不同机器的GPU显存、CPU内存之间进行的高速搬运。热数据在HBM,温数据在CPU DRAM,冷数据在SSD。系统像管理数据库一样管理KV Cache。 https://zhuanlan.zhihu.com/p/706791646
Mooncake: Kimi’s KVCache-centric Architecture for LLM Serving
快速Transformer
轻量化Transformer是从计算量/时间/空间的角度出发,对于传统Transformer的优化。但是计算量少,不等于计算速度快:同样的计算量,不同种类的算子,在硬件上的速度也是有差异的,这种差异有时甚至可以到几个数量级。而我们最终的目的终究是速度快,而非计算量少。
因此,本节的快速Transformer主要着眼于软件工程角度,如何更好的利用各种硬件加速Transformer的计算。典型的有NVIDIA的FasterTransformer和腾讯的TurboTransformer。
FasterTransformer
![]()
FasterTransformer作为这一流派的开山鼻祖,其使用的手段,以现在的眼光来看,已经过于平常了。但从工程的角度,它首次揭示了FLOP少,不等于快。
上图是其中的一处优化点,NV将所有非矩阵乘法的运算,都合成一个算子,从而大大减少了算子的数量,以及相应的调度时间。
EffectiveTransformer/ByteTransformer
EffectiveTransformer/ByteTransformer都是ByteDance的作品,基于FasterTransformer的进一步优化。
![]()
![]()
Transformer模型运算中,padding部分带来了的无效计算。比如Bert一个输入Batch的固定句长是64,但平均句长只有40,那么EffectiveTransformer在FasterTransformer的基础上还可以再多获得约1.5倍的加速。
具体的方法就是:对mask矩阵求前缀和,然后根据前缀和矩阵搬运内存,实现删除和恢复padding。
ByteTransformer在此基础上对self attention部分的padding做了优化。
https://zhuanlan.zhihu.com/p/139255930
使用EffectiveTransformer加速BERT
https://www.thepaper.cn/newsDetail_forward_23343189
大幅优化推理过程,字节高性能Transformer推理库获IPDPS 2023最佳论文奖
FlashAttention
代码:
https://github.com/Dao-AILab/flash-attention

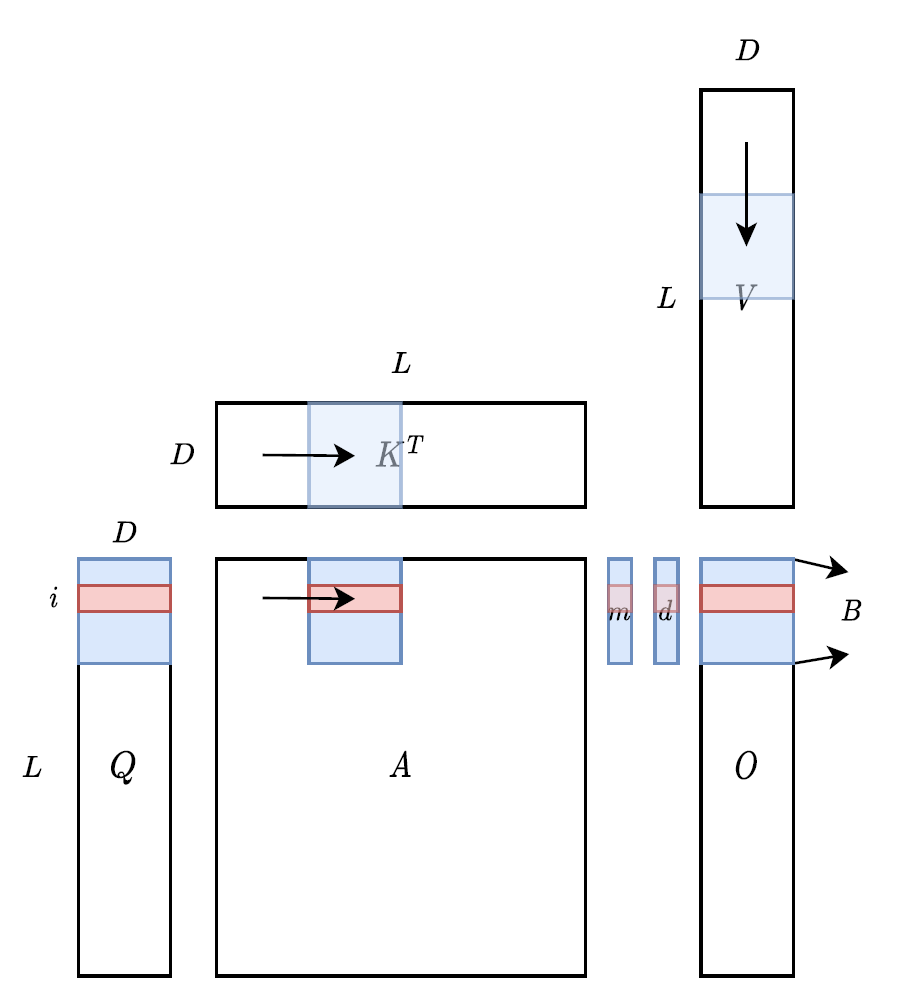
对于self-attention块,除了两个大矩阵乘法是计算受限的,其他都是内存受限的逐点运算。
FlashAttention主要使用分块矩阵的思想,对矩阵乘法进行优化。
分块之后,参与运算的小块可以放入速度更快的存储单元,例如原来的运算需要反复读取HBM,而现在只需要读取一次HBM,然后就可以在SRAM或者Cache中完成所有的运算。
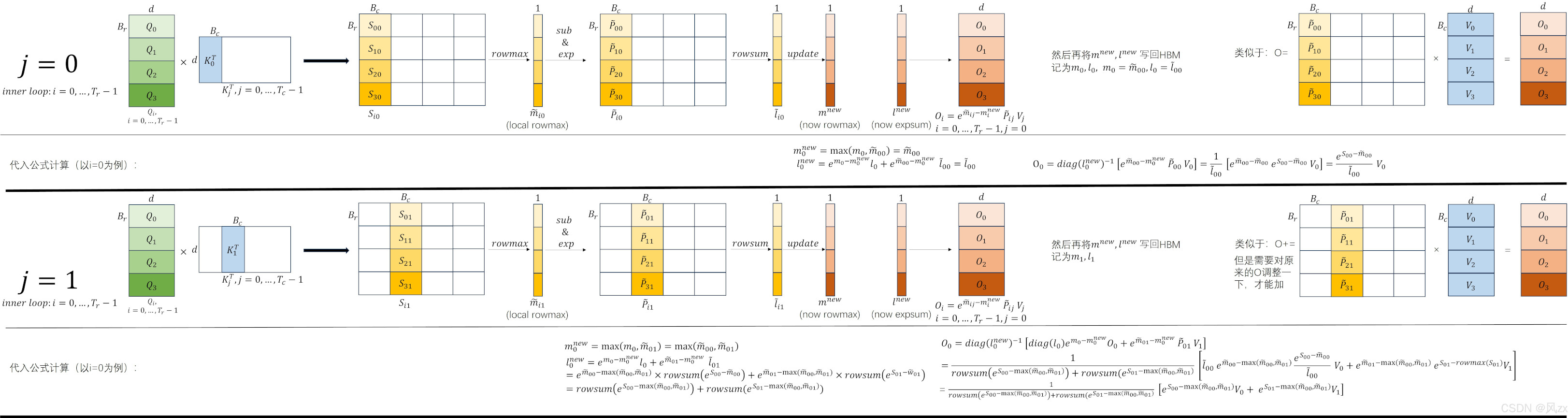
但Self-Attention中有softmax计算,而softmax的分母包含了所有元素相关的求和项,所以对Self-Attention进行分块计算的真正难点在于对softmax的分块计算。
FlashAttention提出了一种叫做Online Softmax的增量算法:我们首先计算一个分块的局部softmax值,然后存储起来。当处理完下一个分块时,可以根据此时的新的全局最大值和全局EXP求和项来更新旧的softmax值。接着再处理下一个分块,然后再更新。当处理完所有分块后,此时的所有分块的softmax值都是“全局的”。
具体计算公式:
for i = 1 to #tiles do: $$m_i^{(local)}\leftarrow max_{j=1}^b(x_i[j])$$ $$m_i \leftarrow max(m_{i-1},m_i^{(local)})$$ $$d_i^{'} \leftarrow d_{i-1}^{'}e^{m_{i-1}-m_i}+\sum_{j=1}^b e^{x_i[j]-m_i}$$ $$o_i^{'}=o_{i-1}^{'}\frac{d_{i-1}^{'}}{d_i^{'}}e^{m_{i-1}-m_i}+\sum_{j=1}^{b}\frac{e^{x_i[j]-m_i}}{d_i^{'}}V[j+(i-1)b,:]$$ end $$O[k,:]\leftarrow o_{N/b}^{'}$$
其他优化点:
-
softmax recomputing。前向保存logsumexp(LSE),反向利用LSE,重新计算softmax。
-
Dropout,前向阶段只保存dropout seed与offset,反向宁愿再算一遍dropout,放弃保存dropout mask。
Online Softmax从思想上显然受到了Welford’s algorithm(1962)的影响。
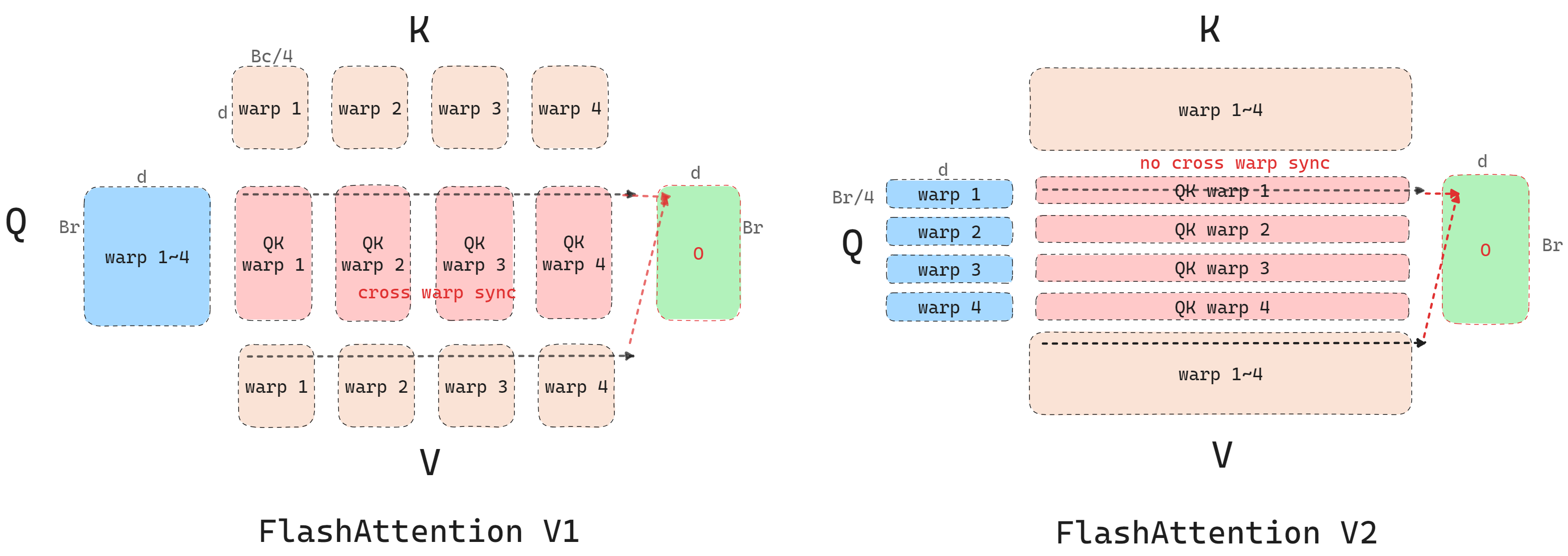
FlashAttention V1里Q在内层循环,而V2里K在内层循环。V1对于计算softmax不友好,因为每次计算的中间结果只是部分和,只有全算完才能释放相关存储。
\(B_r\)和\(B_c\)是FlashAttention分块处理时的分块size。
// vllm-project
test_flash_attn_with_paged_kv
flash_attn_with_kvcache
torch.ops._vllm_fa3_C.fwd
mha_fwd
run_mha_fwd
run_mha_fwd_
run_mha_fwd_hdim128
run_flash_fwd
flash_fwd_kernel
// Dao-AILab
test_flash_attn_output
flash_attn_func
FlashAttnFunc.apply
_wrapped_flash_attn_forward
torch.ops.flash_attn._flash_attn_forward
flash_attn_gpu.fwd
import flash_attn_2_cuda as flash_attn_gpu
mha_fwd
Composable Kernel(ck)是AMD ROCm平台的Flash-Attention实现。
prefill: flash_attn_func
decode: flash_attn_with_kvcache
varlen即变长序列,产生的背景是”数据拼接“,即LLM使用的训练数据集中,长度较短的序列占大多数,这些短序列为了能够符合Transformer固定长度的输入,就要进行padding,序列越短,padding越多,而我们不太想要padding,padding只是无奈之举。此时,我们可以使用varlen特性,简单来说就是将多个短序列拼接成一个长序列,但是还是每个短序列自己内部计算注意力,短序列之间是隔离的,这样减少了padding,节省计算量和显存。

flash_attn中io的默认layout是bshd格式的,这是因为attn之前的MLP的output是bsD的layout,这里的D=(h,d)。如果换成其他layout,则会有transpose操作的开销。
SDPA(Scaled Dot-Product Attention):PyTorch 2.0+引入的、会根据硬件自动挑选最快内核(FlashAttention / Memory-Efficient / C++)的attention API。
https://www.zhihu.com/question/611236756
FlashAttention的速度优化原理是怎样的?
https://blog.csdn.net/v_JULY_v/article/details/133619540
通透理解FlashAttention与FlashAttention2:全面降低显存读写、加快计算速度
https://zhuanlan.zhihu.com/p/668888063
原理篇: 从Online-Softmax到FlashAttention V1/V2/V3
https://zhuanlan.zhihu.com/p/665170554
FlashAttention核心逻辑以及V1 V2差异总结
https://www.cnblogs.com/sasasatori/p/18474946
FlashAttention逐代解析与公式推导
https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
From Online Softmax to FlashAttention
https://zhuanlan.zhihu.com/p/631106302
FlashAttention反向传播运算推导
https://zhuanlan.zhihu.com/p/685020608
flash attention V1 V2 V3 V4 如何加速 attention
https://www.cnblogs.com/rossiXYZ/p/18791822
FlashAttention
FlashDecoding
FlashDecoding是FlashAttention项目的一部分,但由于优化方向有所不同,特别单列出来。

Prefill阶段在Q的seqlen维度以及batch_size维度做并行。

但是在Decoding阶段,是逐token生成,在利用KV Cache的情况下,每次推理实际的queries token数为1,已经无法通过queries进行并行了。
既然,Q和BS无法进一步并行了,那么对K,V进行并行是不是就可以了呢?
- 首先,将K/V切分成更小的块,比如5块;
- 然后在这些K/V块上,使用标准FlashAttention进行计算,得到所有小块的局部结果。
- 最后,使用一个额外的kernel做全局的reduce,得到正确输出。
https://crfm.stanford.edu/2023/10/12/flashdecoding.html
Flash-Decoding for long-context inference
New hardware features on Hopper GPUs - WGMMA, TMA, FP8
https://www.zhihu.com/question/661395457
FlashAttention-3发布!有什么新优化点?
https://zhuanlan.zhihu.com/p/661478232
FlashAttenion-V3: Flash Decoding详解

您的打赏,是对我的鼓励
