DL acceleration » 并行 & 框架 & 优化(八)——LLM Inference
2024-09-26 :: 5462 Words快速Transformer(续)
PagedAttention
PagedAttention是UC Berkeley的作品。

PagedAttention使用分页管理的方式管理KV Cache,将每个序列的KV Cache划分为块,每个块包含固定数量token的K/V。

Parallel Sampling:我给模型发送一个请求,希望它对prompt做续写,并给出三种不同的回答。我们管这个场景叫parallel sampling。
显然这里的prompt部分的KV cache是完全重复。这时可以使用如上图所示的进阶版本,通过类似MMU的逻辑地址和物理地址的映射,来解决存储问题。
这个方法也可以推广到Beam Search、Shared prefix等场景。
https://blog.vllm.ai/2023/06/20/vllm.html
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
https://zhuanlan.zhihu.com/p/691038809
vLLM核心技术PagedAttention原理
FlashAttention v4

-
之前FlashAttention每算完一个tile就“停下来”做一次partial-softmax同步,v4给每一轮分块先估一个“全局共享最大值”,各个tile完全独立地算完再一次性合并,彻底去掉同步点。
-
v4把kernel拆成“算当前tile+预取下一tile”的双缓冲,计算与访存重叠。
-
v4在运行时根据Smem/SM数量、序列长度、batch-size做启发式决策,自动挑并行度与缓冲策略,保证哪种场景都能跑在“屋顶线”附近。
FlashAttention-4
MUFU = MultiFunction Unit,是NV从Maxwell架构开始放在SM里的一个ALU。它只提供5条低精度、单周期的近似指令。
传统Attention实现里softmax是“关键路径”,一旦近似误差放大,就会累积到数值不稳定,所以大家都老老实实调expf。
FlashAttention 4提出了一种分段在线softmax算法:
– 把K维切成若干块,每块先在寄存器里算局部max、局部和; – 只在最后一步才把局部和rescale成全局和; – 这样90%的exp计算只用于比较大小,绝对误差大一点无所谓; – 真正需要精度的rescale次数从\(O(N^2)\)降到\(O(N)\)。
为了H100要做个FlashAttention-3,为了B200要做个FlashAttention-4,为了Rubin要做个FlashAttention-5。只要黄皮衣发卡不停,FlashAttention生意就能一直做下去。
每一代高性能算子都有每一代的要求:
- Flash attention 1:tensor core和vector/SIMT core要能读写同一个SRAM。
- Flash attention 3/DeepGEMM:tensor core和vector/SIMT core要能完全异步。
- Deepseek Sparse Attention:vector/SIMT core需要高效地支持topK,较为高效地支持hadamard transform。
昇腾910(2019 年发布)时代,Cube和Vector仍在同一个AI Core内紧密耦合,共享核心内更直接的片上缓冲/数据通路,Cube/Vector之间协同相对直接。
到910B(约 2023 年前后进入市场)这一代,架构变成更明显的AIC/AIV分离:一个逻辑计算单元内由1个Cube(AIC)和2个Vector(AIV)组成。这个变化缓解了Vector算力跟不上 Cube的问题,但也削弱了原来Cube/Vector之间低延迟协同的本地路径。中间数据通常要经由GM地址空间,并依赖L2 cache承接复用。不过,L2复用效果取决于具体访问模式和cache命中率,通常要等算子实现完成后,再通过trace/profiling工具确认。
2026Q1上市的950PR增加了SSBuffer,用于AIC和AIV的核间通信。
这种固定的1 AIC : 2 AIV物理配比,在面对FA内部BMM与softmax/rescale之间动态波动的算力需求时,缺乏底层硬件级的动态调度与资源倾斜能力。算子工程师只能通过复杂的静态流水线排布去适配不同shape,一旦seq_len、head_dim、tile size偏离调优甜点,就容易产生大量气泡。
NPU上做FA,真正难的经常不是把矩阵乘发出去,而是把copy-in、BMM1、softmax、BMM2、copy-out排成稳定流水。若流水编排不佳,Tensor Core会因等待搬运、Vector计算或同步而大量stall,整体表现成non-matmul bound——主路径被DMA、Vector单元和同步开销占据,而不是传统意义上HBM带宽受限的memory bound。
https://www.zhihu.com/question/1964791844773822881
NPU为什么很难支持FlashAttention?
过去两年,Mamba、RWKV、各种线性注意力架构之所以受到关注,一个核心论点是:Attention的二次复杂度是个根本缺陷,序列越长代价越高,所以需要用线性复杂度的替代方案。
FA4现在证明了虽然Attention的理论复杂度确实是\(O(N^2)\),但当实现层面的常数因子被压缩到极致之后,这个二次方的实际开销比你想象的小得多。
Mamba和RWKV并不是没有价值。但它们的生存空间,正在被FA4这样的工作一寸一寸地压缩。它们需要找到一个”即使Attention再怎么优化也搞不定”的场景来证明自己——目前来看,那个场景还在地平线之外了。
FlashInfer
FlashInfer是由NVIDIA与CMU、UC Berkeley等机构联合开源的GPU专用LLM推理内核库。将FlashAttention、PageAttention、稀疏 Attention、采样、通信等全部打包,并针对LLM推理服务做了 JIT编译、Paged KV-Cache、变长批量调度等工程化增强。
https://zhuanlan.zhihu.com/p/681506469
用FlashInfer加速大语言模型推理中的自注意力操作
Dual Chunk FlashAttention
超长文本(论文、代码库、百万token级对话)在原始预训练窗口外直接推理会严重掉精度。
纯FlashAttention虽然节省显存,但序列长度N增加后仍然O(N²)地吃显存,单卡80 GB也很快就OOM。
DCFA把长序列切成≤预训练长度的chunk,先算chunk内注意力(intra-chunk),再算chunk间注意力(inter-chunk),把显存复杂度压到O(chunk_size²),理论上可以无限外推长度。
Differential FlashAttention
传统Transformer在长上下文时会把大量注意力权重放到“噪声token”上,产生幻觉和上下文丢失。
Differential Transformer:
\[\text{DiffAttn}(X) = \underbrace{\vphantom{\lambda}\operatorname{softmax}\!\left(\frac{Q_{1}K_{1}^{\!\top}}{\sqrt{d_{k}}}\right)V}_{\text{主注意力}} - \lambda\,\underbrace{\vphantom{\lambda}\operatorname{softmax}\!\left(\frac{Q_{2}K_{2}^{\!\top}}{\sqrt{d_{k}}}\right)V}_{\text{噪声注意力}}\] \[\lambda = \exp(\lambda_{q1}\!\cdot\!\lambda_{k1}) - \exp(\lambda_{q2}\!\cdot\!\lambda_{k2}) + \lambda_{\text{init}}\]相当于让第二个分支专门学“噪声模式”,然后显式减掉。
但这样就带来两倍KV Cache + 两次FlashAttention计算的开销。于是作者直接写了一个“一次kernel launch里跑两路”的专用CUDA kernel,起名叫Differential FlashAttention。
ThunderKittens
ThunderKittens是一个由HazyResearch团队开发的轻量级、高性能深度学习框架。对长度<1K的序列,ThunderKittens的速度比FlashAttention-2快2-5倍。
代码:
https://github.com/HazyResearch/ThunderKittens
Stream-K
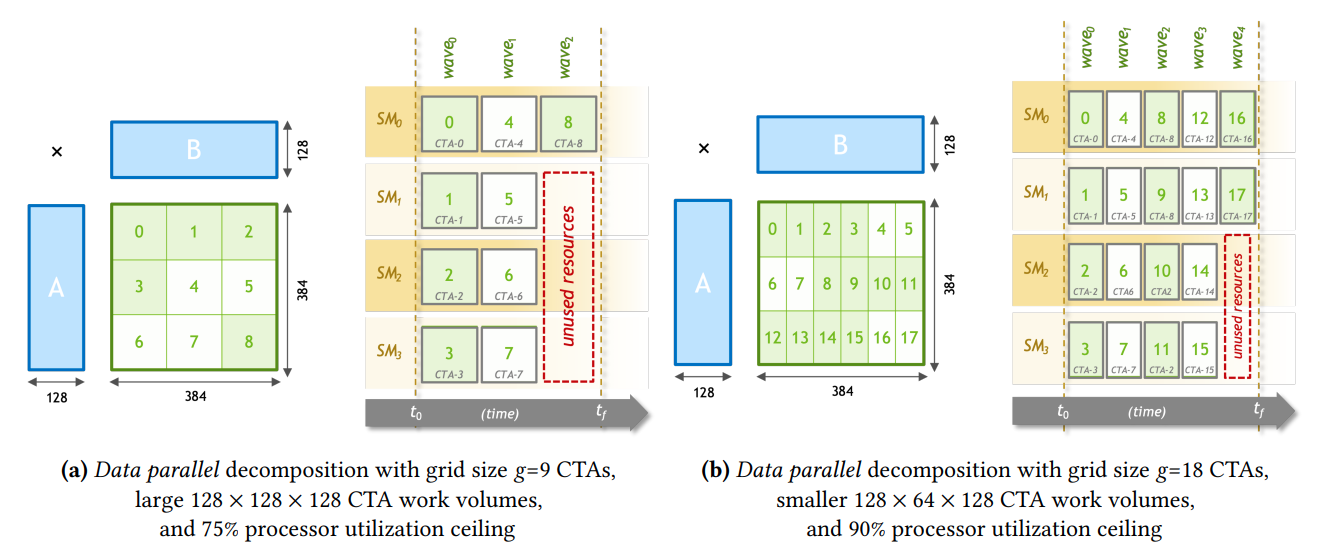
我们将GPU上最经典的切块方式称为Data Parallel,即每一个计算单元都计算输出一个完整的子矩阵,所有计算单元计算的数据互不相干,从而达到并行计算的效果。
如上左图所示,我们将矩阵乘法拆分成9个子矩阵,每一个子矩阵交由一个CTA完成,这样会有9个CTA。假设我们的GPU上只有4个SM,4个SM每一wave都会计算出各自的一个子矩阵。但在最后一wave中我们只剩下一个子矩阵没有计算完成,这样就会导致我们的吞吐量只有75%=9/12。
当然,我们可以将切块变小,比如说切分成18块(如上右图所示),这样能将我们的吞吐量提升到90%=18/20。
但是这样会削弱cache作为暂存器的作用,因为每次从gmem读到smem的数据量都变小了。
我们将这种矩阵的形状不能被计算单元整除的情况称之为Tile Quantization,导致计算单元利用率低的情况称之为Quantization Inefficiency(不是量化的quantization)。
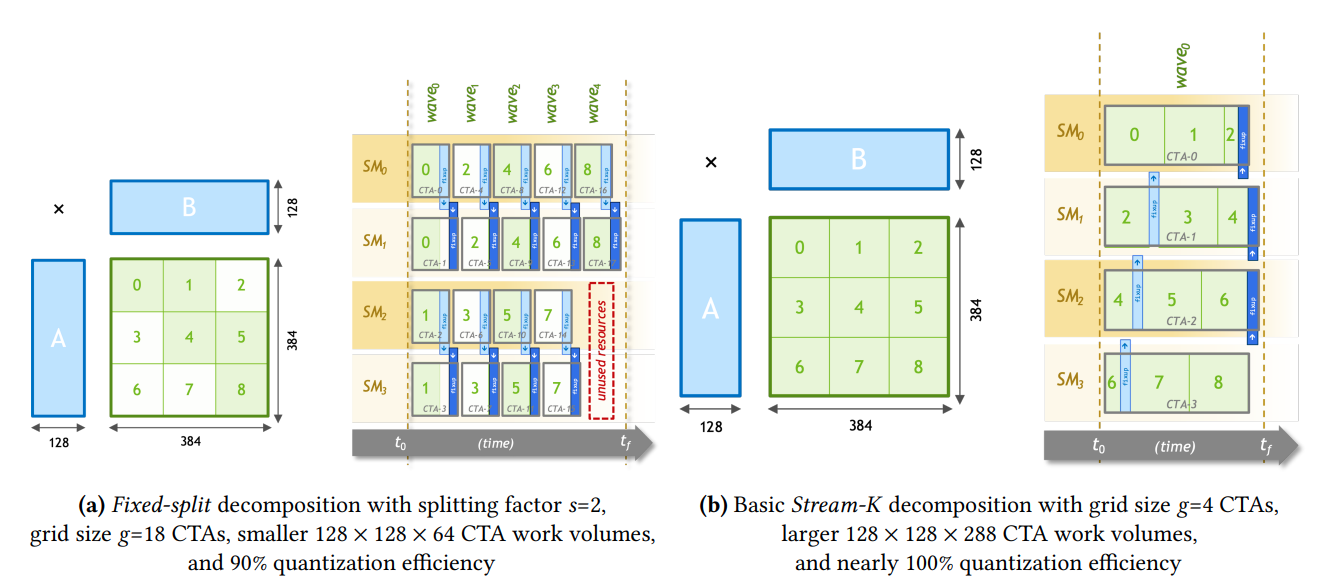
我们也可以通过在累加维度并行来减小分配给每个CTA的任务分配粒度,这样既能够减小Quantization Inefficiency,也能够防止因为切块变小带来的smem数据复用问题。这就是所谓的Split-K(如上左图所示)。FlashDecoding就用到了Split-K的思想。
但这也并不能完美解决Quantization Inefficiency,甚至还会带来一个额外的成本,即需要先将其中一部分数据写到gmem中后再做一次reduce,我们将这个操作称之为fixup。
为此,NV又提出了Stream-K,如上右图所示。简单的说法,就是按照SM的数量划分wave。每个wave可以执行分数个tile的运算,而不是整数个tile的运算。
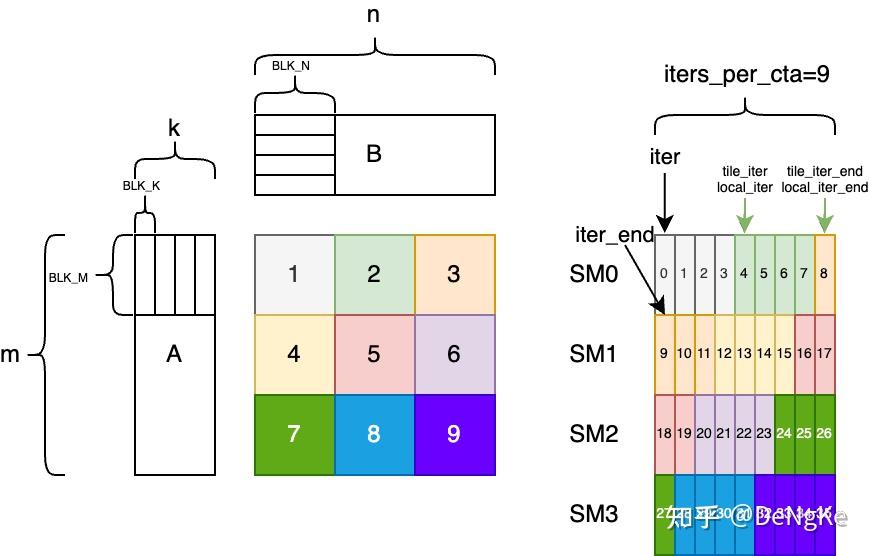
原理就是在tile的基础上,在K上划分sub tile。显然这里的逻辑会变的更加复杂,什么时候要进行累加,什么时候要写到gmem跟其他的SM进行reduce是我们需要进行额外判断的。
参考
https://mp.weixin.qq.com/s/1R_plHqxTLE-Fw3TjYnlJQ
GPU BERT上线性能不合格,看看微信AI的PPoPP论文
https://mp.weixin.qq.com/s/OgTQ3O_6lvOG07U-tjpTDA
如何让Transformer在GPU上跑得更快?快手:需要GPU底层优化
https://zhuanlan.zhihu.com/p/638468472
从FlashAttention到PagedAttention, 如何进一步优化Attention性能
https://blog.csdn.net/v_JULY_v/article/details/144218958
一文通透vLLM与其核心技术PagedAttention:减少KV Cache碎片、提高GPU显存利用率(推理加速利器)
LLM Inference
A Survey on Efficient Inference for Large Language Models
https://zhuanlan.zhihu.com/p/653352979
LLM七种推理服务框架总结
https://zhuanlan.zhihu.com/p/671347964
大模型(LLM)推理框架汇总
https://zhuanlan.zhihu.com/p/642412124
LLM的推理优化技术纵览
https://github.com/DefTruth/Awesome-LLM-Inference
Awesome LLM Inference

您的打赏,是对我的鼓励
