DL acceleration » NN Quantization(三)——量化策略
2024-11-28 :: 6171 Words量化策略
上面主要讲了量化格式,这里再讲一下量化相关的策略问题。
Saturate Quantization
上述各种量化方法都是在保证数值表示范围的情况下,尽可能提高fl或者scale。这种方法也叫做Non-saturation Quantization。
NVIDIA在如下文章中提出了一种新方法:
http://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
8-bit Inference with TensorRT
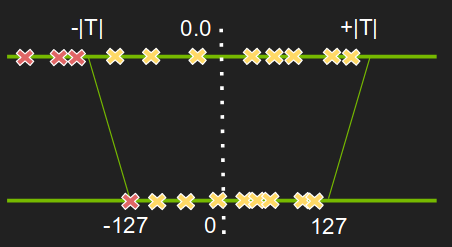
Saturate Quantization的做法是:将超出上限或下限的值,设置为上限值或下限值。
如何设置合理的Saturate threshold呢?
可以设置一组门限,然后计算每个门限的分布和原分布的相似度,即KL散度,选择最相似分布的门限即可。
参考:
https://blog.csdn.net/u013010889/article/details/90295078
int8量化和tvm实现
Trainning Quantization
除了上面这些无条件Quantization之外,训练中的Quantization也是一大类算法。
比如下面提到的PACT量化,不仅对weight进行量化,还通过不断训练,限制每一层tensor的数值范围。
参考:
https://mp.weixin.qq.com/s/7rMnzbvp1hjDLuw_oifbng
我们是这样改进PACT量化算法的
双重量化
过去的量化算法每一层额外附带两个参数,现在的量化算法一般采用了分组量化的方式。例如,取128个参数作为一组,每一组都会额外增加两个参数。
量化参数(最小值、缩放比例)本身还能再进行量化,称为双重量化。QLoRA采用了这种方式。
https://zhuanlan.zhihu.com/p/665601576
用bitsandbytes、4比特量化和QLoRA打造亲民的LLM
per-channel & per-group
一般情况下,一个Tensor共享同一个Scale。有的时候为了提升精度,也可以一个channel共享同一个Scale,这也被称为per-channel quantization。如果不共享Scale,则退化为普通的浮点数表示。
经过观察,在正态分布下,绝对值很大的参数的比例会很少,所以一起归一会使得大多数参数变得很小,从而使得量化过程中的一些数字范围对应的int8没有被充分利用,导致更多的信息丢失。
把参数划分为了小Block,在进行量化的时候,按照block内绝对值最大的数对这个block进行归一化,使得所有参数都落在 [-1, 1] 这个范围,这就是Block-wise Quantization。Block的值如果在内存中连续,则这种quantization也叫做per-group quantization。
Activation Quantization
早期的Quantization一般是W和A采用相同量化格式,然而由于LLM的特殊性(层数深,迭代次数多),Activation的量化一直是一个大问题。W4A16就是目前传统方法所能达到的最好水平了。
seq2seq对于数值精度要求高,这在早期的LSTM时代,就已经很突出了。当时CNN普遍已经8bit量化,但在LSTM中,起码要16bit才能达到可接受的效果。

研究表明,有些Token的异常值会显著高于其他Token,有了之前Weight上的per-channel & per-group的策略,Activation上自然也可以使用per-token的策略。
然而Activation Quantization的这些高阶策略,和输入的内容密切相关,因此并不能进行离线量化,同时量化参数由于是运行时才确定的,相当于是动态图,这给后端的AI硬件的调度带来了一定的挑战。
相关算法:SmoothQuant、ZeroQuant、SpQR。
量化技巧
1.设计模型时,需要对输入进行归一化,缩小输入值的值域范围,以减小量化带来的精度损失。
2.tensor中各分量的值域范围最好相近。这个的原理和第1条一致。比如YOLO的结果中,同时包含分类和bbox,而且分类的值域范围远大于bbox,导致量化效果不佳。
3.最好不要使用ReluN这样的激活函数,死的神经元太多。神经元一旦“死亡”,相应的权值就不再更新,而这些值往往不在正常范围内。
4.对于sigmoid、tanh这样的S形函数,其输入在\(\mid x \mid > \sigma\)范围的值,最终的结果都在sigmoid、tanh的上下限附近。因此,可以直接将这些x值量化为\(\sigma\)。这里的\(\sigma\)的取值,对于sigmoid来说是6,而对于tanh来说是3。
NN硬件的指标术语
MACC:multiply-accumulate,乘法累加。
FLOPS:Floating-point Operations Per Second,每秒所执行的浮点运算次数。
显然NN的INT8计算主要以MACC为单位。
gemmlowp
gemmlowp是Google提出的一个支持低精度数据的GEMM(General Matrix Multiply)库。
代码:
https://github.com/google/gemmlowp
FBGEMM
FBGEMM(Facebook General Matrix Multiplication)是一个专为服务器端推理设计的低精度、高效率的矩阵乘法和卷积库。它提供了小批量大小的高效低精度矩阵乘法,并支持行向量量化和异常感知量化等减少精度损失的技术,以实现极致的计算性能。
代码:
https://github.com/pytorch/FBGEMM
论文
《Quantizing deep convolutional networks for efficient inference: A whitepaper》
Optimizer Quantization
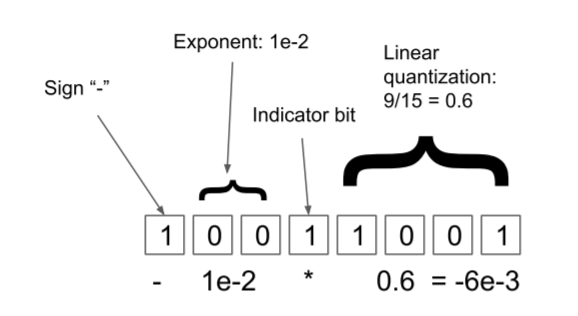
某些特别大或特别小的异常值,对量化会产生较大的精度影响。动态树量化(dynamic tree quantization)就是一种以较低的量化精度损失处理这种情况的方法。
-
首位是符号位
-
符号位后连续的0的数量表示指数大小
-
再之后的第一个值为1的是指示位
-
线性量化区域
指示位是可以动态移动的,通过移动指示位可以灵活选择更大的范围,还是更高的精度。
论文:
8-BIT OPTIMIZERS VIA BLOCK-WISE QUANTIZATION
论文作者为此开发了bitsandbytes库:
https://github.com/bitsandbytes-foundation/bitsandbytes
因为经常使用import bitsandbytes as bnb导入,所以该库又被称为bnb。
参考:
https://www.cnblogs.com/chentiao/p/17388568.html
bitsandbytes–Facebook推出8比特优化器大大减少显存
Pytorch+
https://mp.weixin.qq.com/s/zN3k51g9gjQvc43AH-ypGA
如何通过PyTorch上手Tensor Comprehensions?
https://mp.weixin.qq.com/s/yGtDUbvO2APT88MwcSh8IA
GAN如此简单的PyTorch实现,一张脸生成72种表情
https://mp.weixin.qq.com/s/u9GEDCmR-PT0–0Xf4vKDA
Pytorch的tensorboard食谱帮你可视化误差结果
https://mp.weixin.qq.com/s/HginBrMOfEEWsZKq67u6EA
在Pytorch中构建流数据集
https://zhuanlan.zhihu.com/p/98535650
研究生应当掌握的并行训练方法(单机多卡)
https://zhuanlan.zhihu.com/p/86441879
pytorch多gpu并行训练
https://mp.weixin.qq.com/s/KP4etDrGlJmRAMQmR1mTJA
基于C++的PyTorch模型部署
https://zhuanlan.zhihu.com/p/145427849
PyTorch Parallel Training(单机多卡并行、混合精度、同步BN训练指南文档)
https://mp.weixin.qq.com/s/Y6sJhnmjRwN2uopHgr7nFA
让PyTorch更轻便,这款深度学习框架你值得拥有!
https://zhuanlan.zhihu.com/p/104019160
PyTorch常用代码段
https://mp.weixin.qq.com/s/5Nq3y8hwhQG1UV9lHuBQvA
13个你一定要知道的PyTorch特性
https://mp.weixin.qq.com/s/cKvkvWgVPuq9y1A5q1OPEQ
跟着指南学PyTorch—迁移学习教程
https://mp.weixin.qq.com/s/gJgxh4l0CXTlaJaQ_FS3YQ
PyTorch的数据增强与数据标准化
https://mp.weixin.qq.com/s/Mo7XhRcPkgurmQPJ3Zu1ug
基于PyTorch的计算机视觉框架
https://mp.weixin.qq.com/s/PWABh72t92pUOJufcmzvag
用PyTorch做深度学习实验!Facebook新框架Ax和BoTorch双双开源
https://mp.weixin.qq.com/s/LcwlCai7PMYOBwsLXPS5HA
PyTorch语义分割开源库semseg
https://mp.weixin.qq.com/s/oDYMTb9NWxVsW07FLQKA_Q
万字综述,核心开发者全面解读PyTorch内部机制
https://www.zhihu.com/question/274635237
Pytorch有什么节省内存(显存)的小技巧?
https://mp.weixin.qq.com/s/xe5zmJklT2sqn_zffmyrLg
Sharded:在相同显存的情况下使pytorch模型的参数大小加倍
https://mp.weixin.qq.com/s/maOnO_o5y19X2D-ZnLjsJA
PyTorch中的In-place操作是什么?为什么要避免使用这种操作?
https://zhuanlan.zhihu.com/p/299736532
使用PyTorch 1.6 for Android
https://mp.weixin.qq.com/s/1ugk6uI6lfWEEUvtKIfYNA
9个让PyTorch模型训练提速的技巧!
https://mp.weixin.qq.com/s/kZvdgWqk1KLi790rly3YYQ
Pytorch中的分布式神经网络训练
https://mp.weixin.qq.com/s/biHcUt55-9RfqYJ_Dg_7Tg
TorchMetrics:PyTorch的指标度量库
https://zhuanlan.zhihu.com/p/363319763
PyTorch vs LibTorch:网络推理速度谁更快?
https://mp.weixin.qq.com/s/RBclQdtaA8prvSoUUdhrEQ
机器学习的Pytorch实现资源集合
https://mp.weixin.qq.com/s/zPv-3fMy1rZwAwPqjs7oAA
Pytorch图像分类从模型自定义到测试
https://zhuanlan.zhihu.com/p/46636027
1张图学会PyTorch+TensorFlow+MXNet+TF Eager
https://mp.weixin.qq.com/s/yS9PAw926Y7AsGRW0eHG0Q
基于PyTorch的GAN框架TorchGAN:用架构级API轻松定制GAN项目
https://github.com/CVBox/PyTorchCV
一个基于pytorch的CV框架
https://mp.weixin.qq.com/s/w09hcJof80m2VGwn7SgKmQ
TorchSeg—基于PyTorch的快速模块化语义分割开源库
https://mp.weixin.qq.com/s/TsR-jgO2c2-dbqnk1mEj8w
想读读PyTorch底层代码?这份内核机制简介送给你
https://mp.weixin.qq.com/s/Lzt3LbO6lBbOebNV1d2pLQ
迁移学习不好懂?这里有一个PyTorch项目帮你理解
https://mp.weixin.qq.com/s/7fK6GNyzYTP0fQy7F01fZw
PyTorch深度学习模型训练加速指南2021
https://mp.weixin.qq.com/s/SReuVBN8WIXFlnwho3wqgQ
最详细的Pytorch底层算子扩展总结
https://mp.weixin.qq.com/s/14_pt0_skKYNw2sAK5Zptw
Pytorch底层算子扩展最详细的总结
https://zhuanlan.zhihu.com/p/363317178
模型转换:由Pytorch到TFlite
https://mp.weixin.qq.com/s/Mj7xI5rFTxKaXswYi9_mRQ
我的PyTorch模型比内存还大,怎么训练呀?
https://mp.weixin.qq.com/s/TjCUCbXL3oSgJNYoEltgrg
7个提升PyTorch性能的技巧
https://zhuanlan.zhihu.com/p/275755543
一款全平台轻量级pytorch推理框架Msnhnet
https://mp.weixin.qq.com/s/MJgQqwWa4wyNgtKZaX_ADQ
Tensorboard可视化与Hook机制
https://mp.weixin.qq.com/s/jnV_4REXOR-ema1kOC95Nw
跨越重重“障碍”,我从PyTorch转换为了TensorFlow Lite

您的打赏,是对我的鼓励
