DL acceleration » 并行 & 框架 & 优化(十)——Alpa, Batching
2025-08-26 :: 5435 WordsLLM System(续)
向量数据库
向量搜索在搜索、推荐、NLP等众多应用领域被广泛的使用,典型的互联网业务,包括电商、出行、点评、地图等都大量使用相关技术。随着ChatGPT带来的AI技术应用新热潮,向量数据库又一次地获得了更多的关注。它可以解决LLM不长记性(Memory,记忆)的问题。
普遍认为LLM+Vector Search+API pool会变成复杂AI场景的标准解决方案。
类似Pinecone,Weaviate,Qdrant,Chroma这样的专用向量数据库最初是为了解决ChatGPT的记忆能力不足而出现的Workaround。
最发布的ChatGPT 3.5的上下文窗口只有4K Token,也就是不到两千个汉字。然而当下GPT 4的上下文窗口已经发展到了128K,扩大了32倍,足够塞进一整篇小说了。而且未来还会更大。这时候,用作临时周转的垫脚石——向量数据库SaaS就处在一个尴尬的位置上了。
https://www.zhihu.com/question/603117242
为什么各大VC最近都在投向量数据库?
https://zhuanlan.zhihu.com/p/668509885
向量数据库凉了吗?
Accumulate Gradients
gradient_accumulation_steps用于处理当模型的参数数量超过GPU内存容量时的情况。在训练大型模型时,尤其是在使用较小的GPU进行训练时,可能会遇到内存不足的问题。这时,可以使用梯度累积来分割批次,从而使得每个小批次的计算都在GPU的内存限制范围内。
如果设置了gradient_accumulation_steps=N,那么模型会先对N个批次的数据进行前向和反向传播,将这些批次的梯度累积起来,然后才进行一次权重更新。这样,实际上的批次大小相当于per_device_train_batch_size * N。
Multi-Token Prediction
在训练阶段,一次生成多个后续token,可以一次学习多个位置的label,进而有效提升样本的利用效率,提升训练速度;在推理阶段通过一次生成多个token,实现成倍的推理加速来提升推理性能。
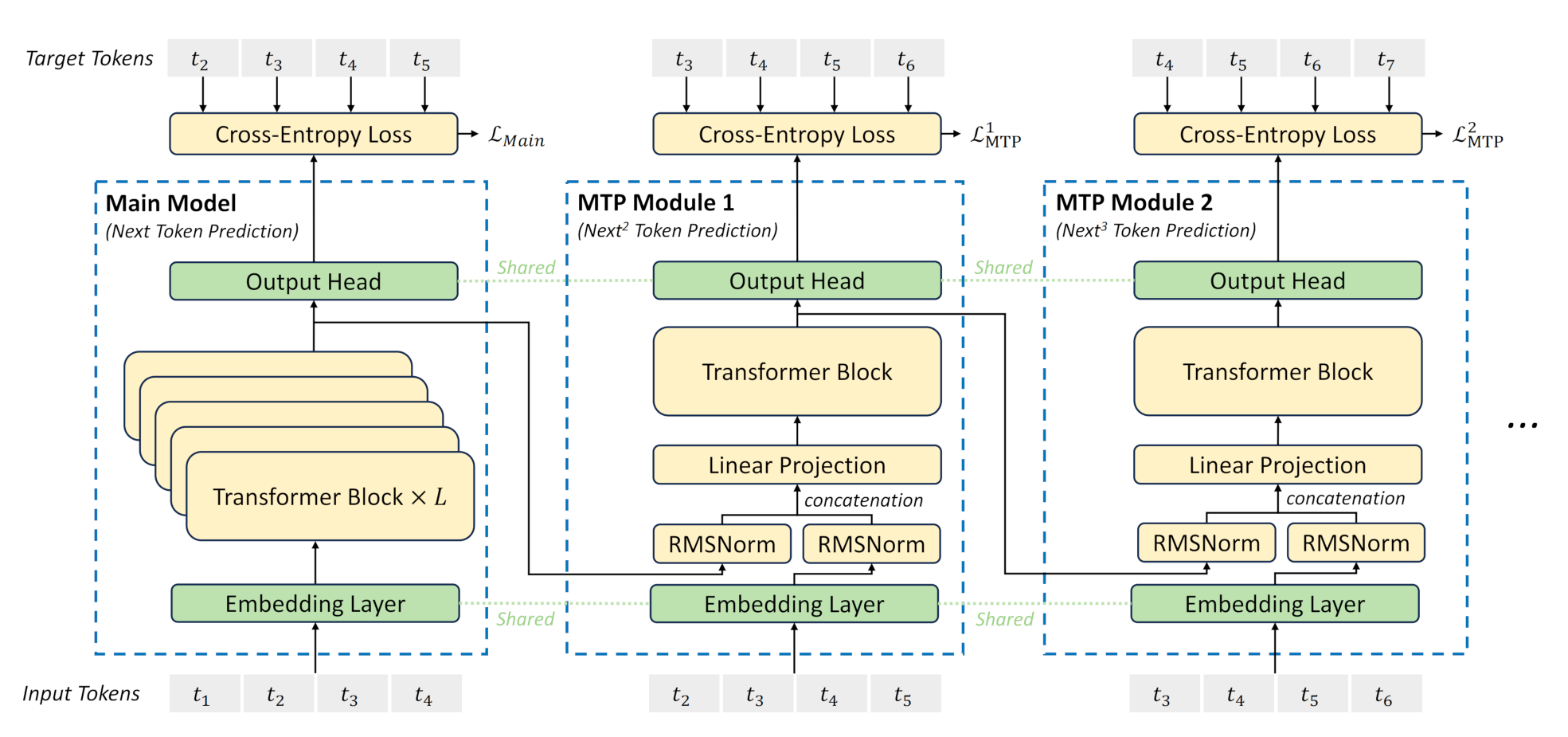
https://zhuanlan.zhihu.com/p/18056041194
MTP(Multi-Token Prediction)的前世今生
https://blog.csdn.net/v_JULY_v/article/details/145374551
一文通透让Meta恐慌的DeepSeek-V3:在MoE、GRPO、MLA基础上提出Multi-Token预测(含FP8训练详解)
Serving
reasoning_content:大模型API中用于返回模型内部推理链条的字段。
大模型服务里类似2x之类的倍率:上下文长度扩展倍数,即模型支持的token上限是原始基础版本的多少倍。处理更长上下文需要更多显存和计算资源,价格通常更高。用户可根据任务选择合适的倍率,避免为短任务支付长上下文溢价。
参考
https://mp.weixin.qq.com/s/39MYrsB3gXpfzTTOgQjDwg
幻方AI DeepSeek模型背后的万卡集群建设
Alpa
Alpa是一个自动探索分布式策略的工具。
论文:
《Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning》
代码:
https://github.com/openxla/xla/tree/main/xla/hlo/experimental/auto_sharding
文档:
https://alpa.ai/index.html
在介绍Alpa之前,先介绍一下Google的optimization库:
https://github.com/google/or-tools
文档:
https://developers.google.com/optimization
ILP可以分为下列几种类型:
(1)纯整数线性规划(Pure integer linear programming):指全部决策变量都必须取整数值的整数线性规划。有时,也称为全整数规划。
(2)混合整数线性规划(Mimed integer linear programming):指决策变量中有一部分必须取整数值,另一部分可以不取整数值的整数线性规划。
(3)0-1型整数线性规划(Zero-one integer linear programming):指决策变量只能了取值0或1的整数线性规划。
ILP相关的库还有pyomo、cyipopt等。
为了评估不同Sharding策略的好坏,我们需要对Sharding策略建立cost model。
这里的cost主要包括:
- Communication cost
- Computation cost
- Memory cost
- Resharding cost
其中,Memory cost为该ILP问题的约束条件,其他几个为决策变量的影响因子。
Resharding cost是不同sharding之间切换产生的开销:

MLIR中有mesh dialect用于描述Sharding Spec:
module @sharding_test {
mesh.mesh @mesh_2d(shape = 4x8)
func.func @matmul_on_operand_shard_batch_and_k(%arg0: tensor<32x1000x4096xf32>, %arg1: tensor<32x4096x8192xf32>) -> tensor<32x1000x8192xf32> {
%sharding_annotated = mesh.shard %arg0 to <@mesh_2d, [[0], [], [1]]> annotate_for_users : tensor<32x1000x4096xf32>
%sharding_annotated_0 = mesh.shard %arg1 to <@mesh_2d, [[0], [1]]> annotate_for_users : tensor<32x4096x8192xf32>
%0 = tosa.matmul %sharding_annotated, %sharding_annotated_0 : (tensor<32x1000x4096xf32>, tensor<32x4096x8192xf32>) -> tensor<32x1000x8192xf32>
%sharding_annotated_1 = mesh.shard %0 to <@mesh_2d, [[0]], partial = sum[1]> : tensor<32x1000x8192xf32>
return %sharding_annotated_1 : tensor<32x1000x8192xf32>
}
}
如何用数学语言表示一个二维的one-hot:
\[\begin{aligned} \forall (v,u) \in E, \ & \forall i \in [0, k_v), & \sum_{j \in [0, k_u)}\mathbf{e}_{vu} [i,j] \leq \mathbf{s}_v[i] \\ & \forall j \in [0, k_u), & \sum_{i \in [0, k_v)}\mathbf{e}_{vu} [i,j] \leq \mathbf{s}_u[j] \\ \end{aligned}\]
参考:
https://zhuanlan.zhihu.com/p/487588274
用ILP和DP自动探索DL分布式策略——Alpa
https://zhuanlan.zhihu.com/p/571836701
Alpa论文解读
Batching
continuous batching
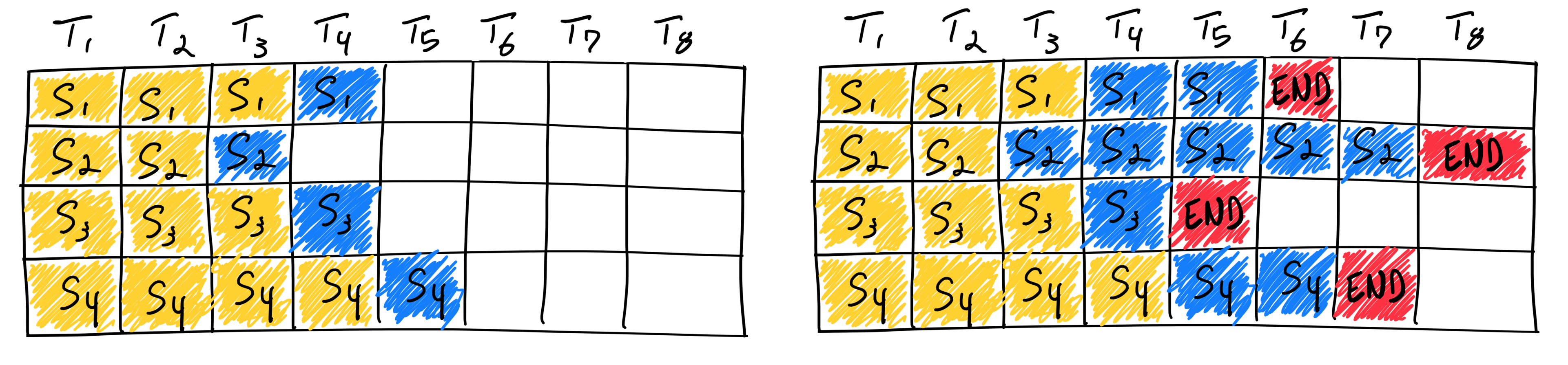
上图是一个通常的多batch的LLM的Inference过程。其中黄色表示用户的prompt,蓝色表示LLM生成的文本,红色表示结束符号。

这是改进后的continuous batching的示意图。
https://www.anyscale.com/blog/continuous-batching-llm-inference
How continuous batching enables 23x throughput in LLM inference while reducing p50 latency
Selective Batching
Selective Batching的核心原理在于:仅对适合批处理的操作执行批处理,不适合批处理的操作则单独处理。
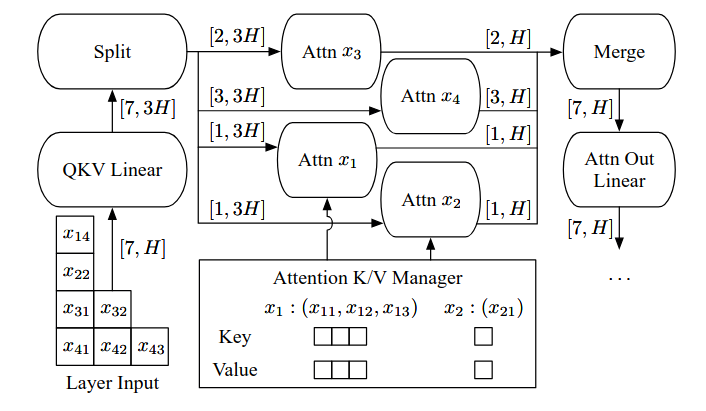
对于preproj、postproj、FFN1和FFN2这类线性变换或归一化操作,它们的计算与序列长度无关,只是在hidden_size维度上做线性转换,并且都需要从显存读取权重。因此,可以将batch内所有token拉平成一个二维张量。
对于Attention操作,由于每个请求的mask、KV cache和token位置可能不同,导致其张量形状不一致,无法直接合并处理。Selective Batching会在进入Attention之前将batch拆分,逐个请求单独计算Attention分数,完成后再将结果合并回统一的张量。
Chunked Prefill
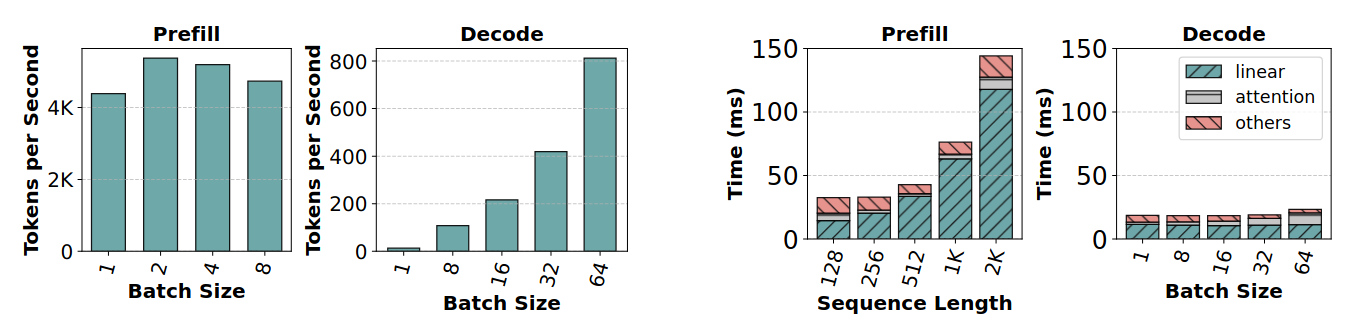
在prefill阶段,即使batch size为1,所有操作的算术强度依然很高。而在decode阶段,这些操作的算术强度下降了两个数量级以上,只有在batch size达到256这种极大值时,decode阶段才开始变得计算密集。
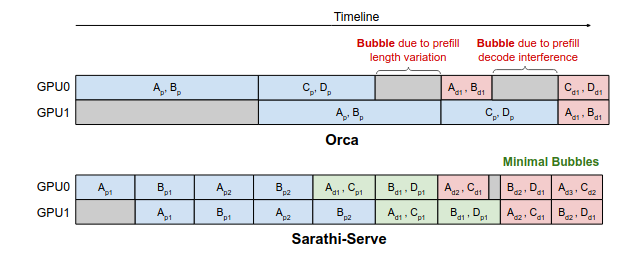
Orca方案尝试在Batch中混合Prefill和Decode请求。但是由于请求具有一定的随机性,Prefill和Decode的计算量不一定平衡,从而产生了pipeline bubbles。
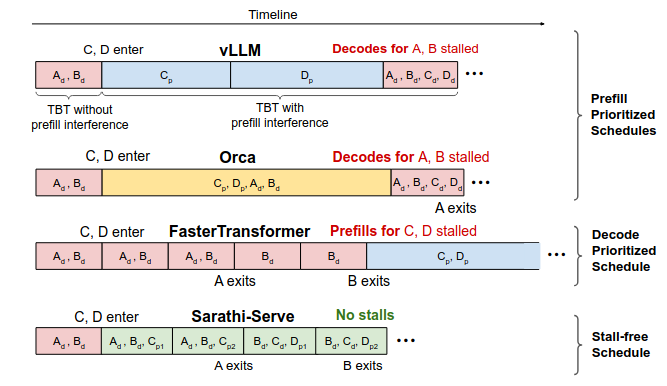
Sarathi-Serve提出了一种兼顾吞吐量与延迟的调度机制,其中包括两个核心设计思想:chunked-prefills(分块预填充)和stall-free scheduling(无阻塞调度)。
- chunked-prefills(分块预填充):将一个prefill请求拆分为计算量基本相等的多个块(chunk),并在多轮调度迭代中逐步完成整个prompt的prefill过程(每次处理一部分 token)。
- stall-free scheduling(无阻塞调度)则允许新请求在不阻塞decode的前提下,动态加入正在运行的batch,通过将所有decode请求与新请求的一个或多个prefill chunk合并,构造出满足预设大小(chunk size)的混合批次。
https://zhuanlan.zhihu.com/p/1928005367754884226
Chunked-Prefills分块预填充机制详解
https://zhuanlan.zhihu.com/p/718715866
基于chunked prefill理解prefill和decode的计算特性
Append
多轮对话情况下,用户第2轮再输入一段文字,系统对这段输入文字做一次新的prefill,然后用把新生成的KV拼接到上一轮cache后面,这个操作被称为Append操作。
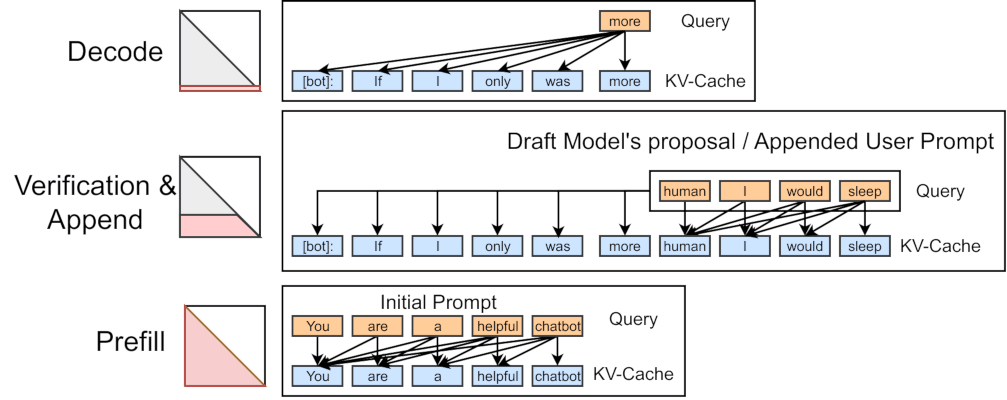
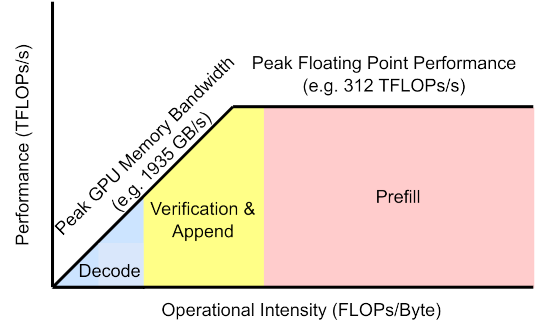
Append操作一般采用Prefix Caching技术进行加速。
RadixAttention使用radix tree,而不是prefix tree。Radix Tree最大的特点就是,它的node,不仅可以是一个单独的元素,也可以是一个变长的序列。具体体现在,在必要的时候,一个已经在Tree中的大node可以动态地分裂成小node,以满足动态shared prefix的需求。
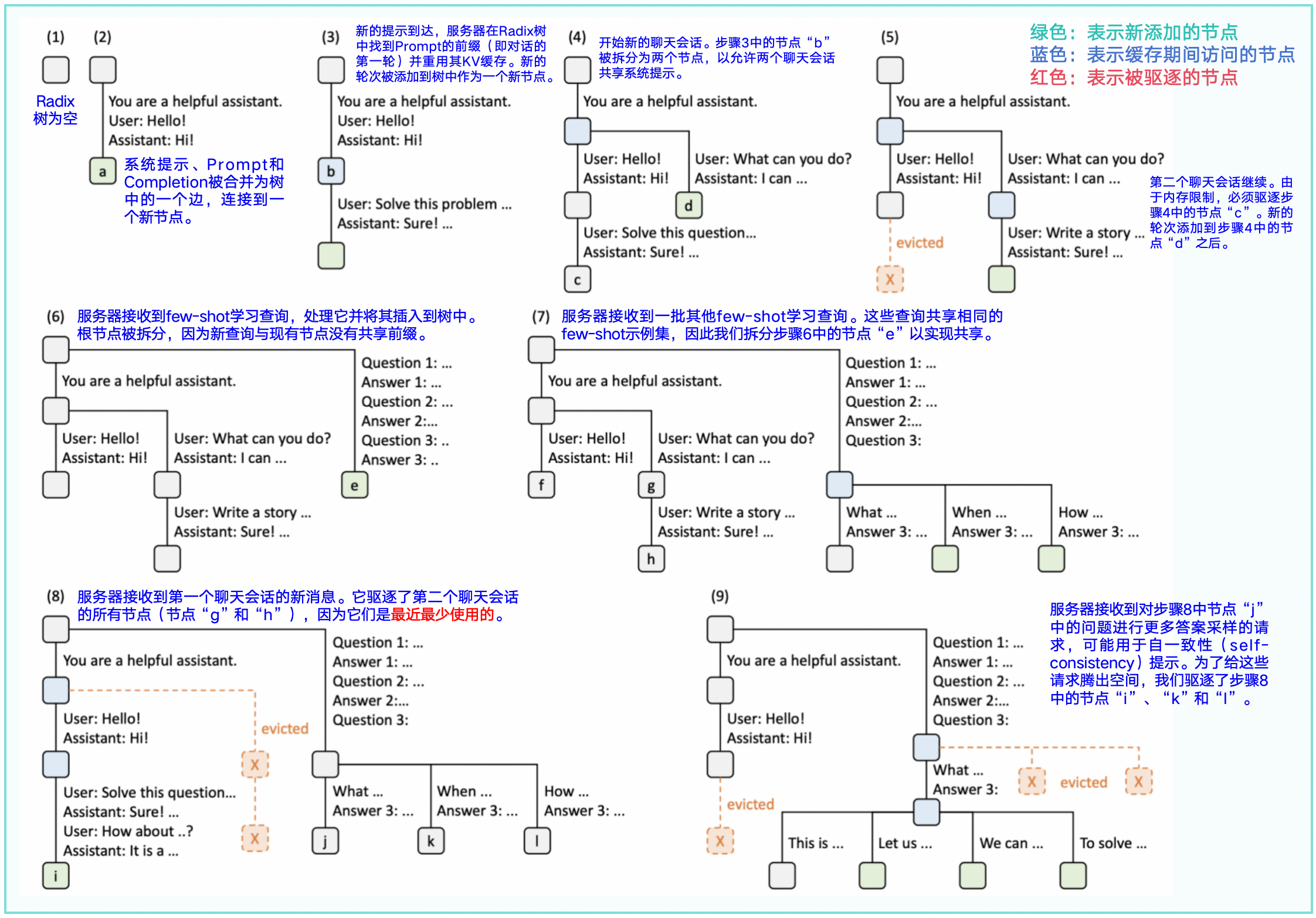
https://zhuanlan.zhihu.com/p/693556044
原理&图解vLLM Automatic Prefix Cache(RadixAttention)首Token时延优化
https://zhuanlan.zhihu.com/p/1890132185966682238
FlashAttentionV1/V2+PageAttentionV1/V2+RadixAttention算法总结

您的打赏,是对我的鼓励
