DL acceleration » 并行 & 框架 & 优化(四)——Pipeline Parallel, 大模型训练, Horovod
2023-03-30 :: 5739 WordsPipeline Parallel
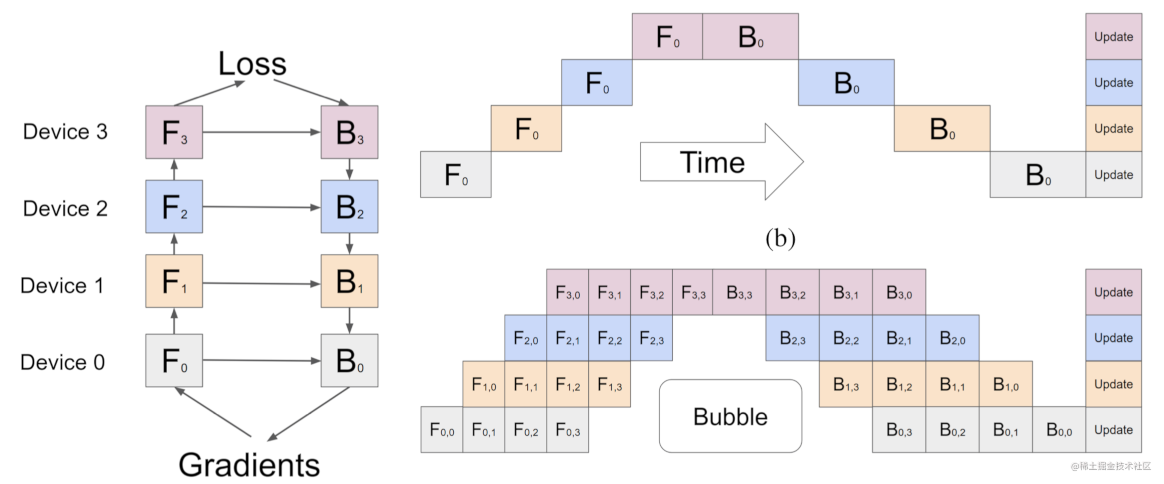
右上图一般称为朴素流水线并行,该方案在任意给定时刻,除了一个GPU之外的其他所有GPU都是空闲的。
所以就有了Micro-batch Pipeline Parallel。将Batch数据分成N份,每次算完1份,就将输出交给下一个GPU,同时开始处理下1个Micro-batch的数据。这里的N一般被称为chunks。
注:模型经过拆分后的上一个rank的stage需要长期持续处于空闲状态,等待其他rank的stage计算完成,才可以开始计算,这极大降低了设备的平均使用率。这种现象被称为并行空泡(Parallelism Bubble)。
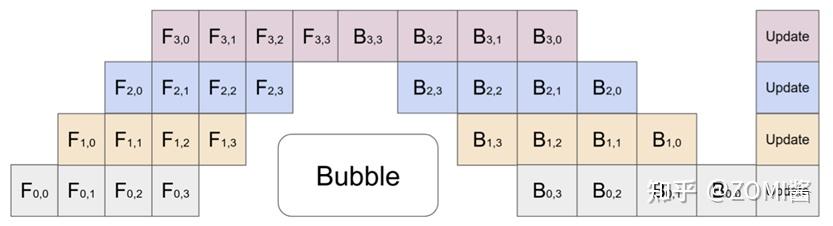
上图这种最简单的Mini-batch Pipeline Parallel,一般称为F-then-B模式,先进行前向计算,再进行反向计算。
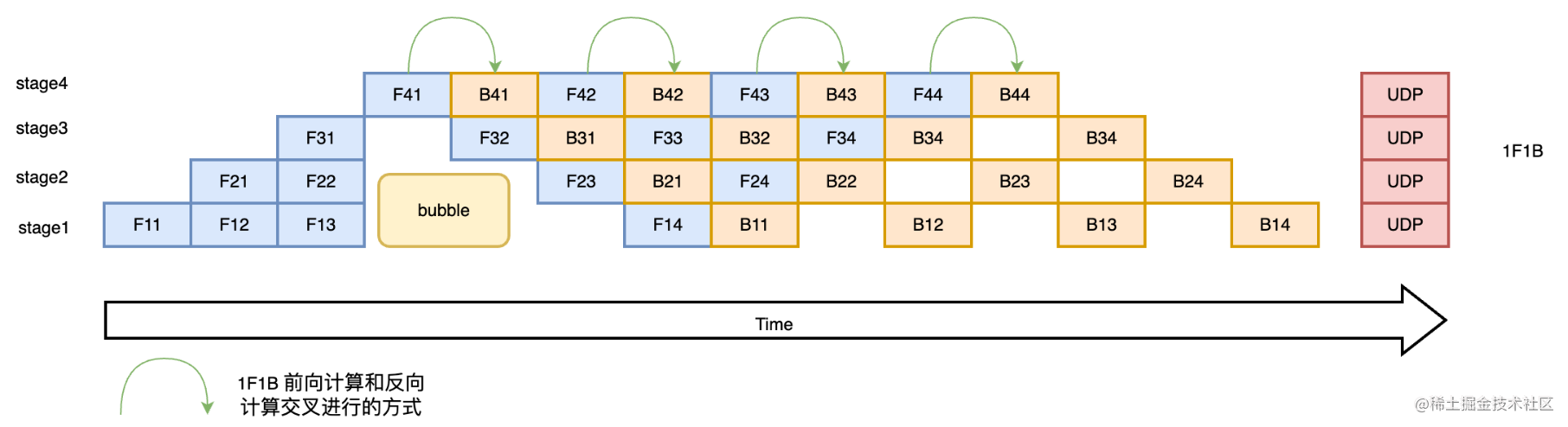
1F1B(One Forward pass followed by One Backward pass)模式,一种前向计算和反向计算交叉进行的方式。在1F1B模式下,前向计算和反向计算交叉进行,可以及时释放不必要的中间变量。
使用1F1B策略时,存在两种调度模式:非交错调度和交错式调度。
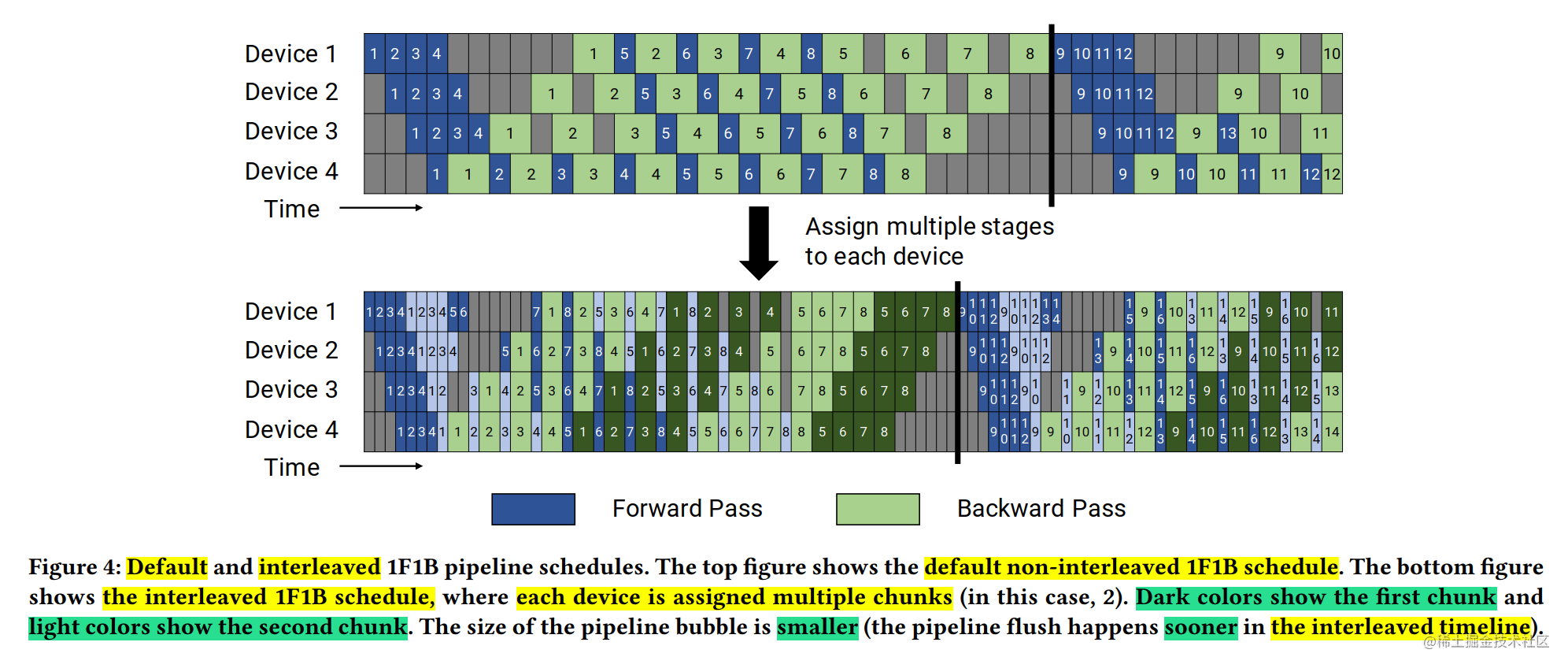
所谓交错式调度,就是在第一个batch(上图中包含4个mini-batch)的F和B还没有完成的情况下,就开始计算第二个batch的mini-batch了。

上图是DeepSeek-V3提出的DualPipe的示意图。两组batch同时进入流水线调度,用双倍的存储,换取利用率的提高。
参考:
https://zhuanlan.zhihu.com/p/618590870
大模型训练Pipeline Parallel流水并行性能分析
https://zhuanlan.zhihu.com/p/653860567
流水线并行
https://www.cnblogs.com/rossiXYZ/p/15318574.html
PyTorch流水线并行实现
TF-Replicator, GPipe, Mesh-Tensorflow
TF-Replicator主要侧重于Data parallelism的库。
GPipe是一个纯model-parallelism的库。
Mesh-TensorFlow是一个DSL语言,既支持Data parallelism,又支持Model parallelism,但是侵入性很强。
参考:
https://zhuanlan.zhihu.com/p/113233933
谷歌GPipe训练超大规模神经网络
https://zhuanlan.zhihu.com/p/342223356
Mesh-Tensorflow: 广义分布式
https://zhuanlan.zhihu.com/p/63211072
TF-Replicator, GPipe, Mesh-Tensorflow三个库对比
https://mp.weixin.qq.com/s/9k6PDusoDHjmz58HAZxZcw
GPipe: 小批量流水线带来的大模型训练
https://mp.weixin.qq.com/s/HY2yPZ–Zm5_m3B70baWjQ
谷歌开源效率怪兽GPipe,速度提升25倍,CIFAR-10精度达到99%
pytorch
因为GPipe是基于TensorFlow的库,所以kakaobrain的一些工程师就用PyTorch来实现了GPipe,并且开源出来,这就是torchgpipe。
代码:
https://github.com/kakaobrain/torchgpipe
fairscale.nn.pipefork自torchgpipe,并最终进入torch.distributed.pipeline。
代码:
benchmarks/distributed/pipeline/pipe.py
另一个Pipeline Parallelism的库。
https://github.com/pytorch/PiPPy
参考:
https://www.cnblogs.com/rossiXYZ/p/15318574.html
PyTorch流水线并行实现 (1)–基础知识
https://pytorch.org/docs/stable/pipeline.html
Pipeline Parallelism
https://pytorch.org/tutorials/intermediate/pipeline_tutorial.html
Training Transformer models using Pipeline Parallelism
https://pytorch.org/tutorials/advanced/ddp_pipeline.html
Training Transformer models using Distributed Data Parallel and Pipeline Parallelism
torch.distributed.pipeline关键代码:
torch/distributed/pipeline/sync/pipeline.py: _clock_cycles
torch/distributed/pipeline/sync/pipe.py: _split_module
其他概念
分布式数据集
大模型不光模型的训练是分布式的,数据集也是分布式的。
https://www.alanshawn.com/tech/2022/02/27/tensorflow-big-dataset.html
Using Huge, Heterogenous Datasets in TensorFlow
https://tensorflow.google.cn/datasets/beam_datasets?hl=zh-cn
使用Apache Beam生成大型数据集
https://www.tensorflow.org/tutorials/distribute/input?hl=zh-cn
分布式输入
Pathways
https://blog.csdn.net/OneFlow_Official/article/details/124054450
解读谷歌Pathways架构(一):Single-controller与Multi-controller
https://blog.csdn.net/OneFlow_Official/article/details/124113864
解读谷歌Pathways架构(二):向前一步是OneFlow
框架设计
https://zhuanlan.zhihu.com/p/547878945
五谈AI软件栈–无责乱弹AI软件栈研发方法论
数据下沉
数据下沉是将数据一次性传输到端侧,减少频繁的Host-Device数据传输来加速的技术。因为数据在Device上通过通道传输,Host侧和Device侧之间每个epoch进行一次数据交互,所以每个epoch只返回一次结果。
https://zhuanlan.zhihu.com/p/397481167
MindSpore的桎梏和破局
https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/63RC2alpha002/tfmoddevg/tfmigr1/atlasmprtg_13_9048.html
训练迭代循环下沉
大模型训练
目前部分深度学习框架,例如Pytorch和Tensorflow,没有办法满足超大规模模型训练的需求,于是微软基于Pytroch开发了DeepSpeed,腾讯基于Pytroch开发了派大星PatricStar,达摩院基于Tensoflow开发的分布式框架Whale。像是华为昇腾的MindSpore、百度的PaddlePaddle,还有国内的一流科技OneFlow等厂商,对超大模型训练进行了深度的跟进与探索,基于原生的AI框架支持超大模型训练。
https://zhuanlan.zhihu.com/p/432813821
大模型的发展与解决的问题
https://zhuanlan.zhihu.com/p/432289008
从分布式训练到大模型训练
https://www.zhihu.com/question/498271491
为什么说大模型训练很难?
https://zhuanlan.zhihu.com/p/611325149
大型语言模型(LLM)训练指南
https://zhuanlan.zhihu.com/p/629589593
LLM应用开发全栈指南
内存墙
从GPT-1到GPT-3,两年时间内模型参数0.1B增加到175B,而同期,NVIDIA交出的成绩单是从V100的32GB显存增加A100的80GB,显然,显存的提升速度远远赶不上模型模型增长的速度,这就是内存墙问题。
https://mp.weixin.qq.com/s/kuIsyX0QEIeFHn8tvFE8vw
AI训练的最大障碍不是算力,而是“内存墙”
activation checkpointing
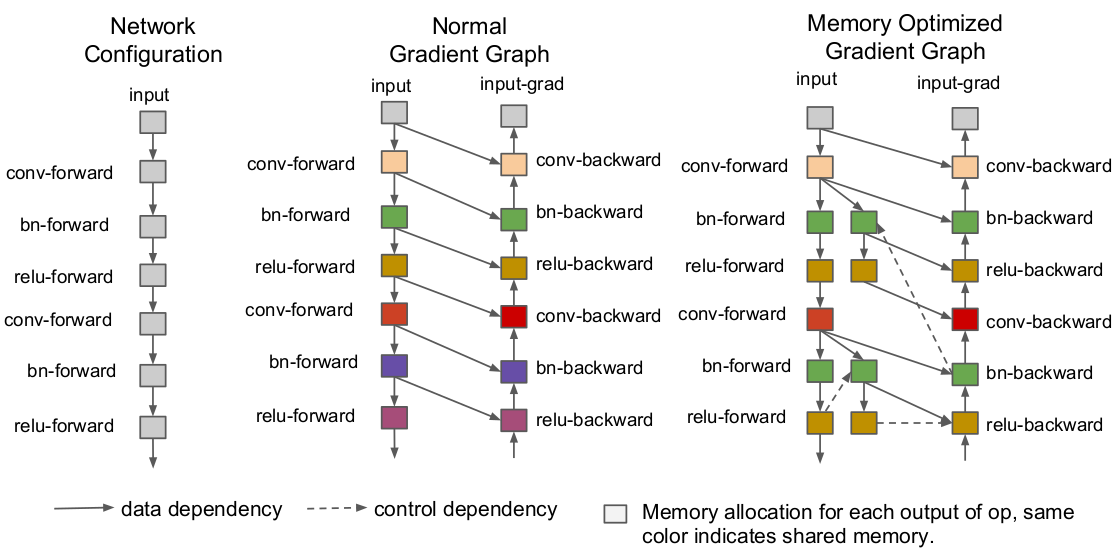
在每个mini-batch的前向过程中删除一些暂时用不到的中间激活特征以降低内存占用,并在后向过程中需要时借助额外的前向计算恢复它们。
在PyTorch中,save_for_backward函数用于在自定义的autograd.Function实现中保存中间变量,以便在后续的反向传播过程中使用。
https://zhuanlan.zhihu.com/p/373662730
亚线性内存优化—activation checkpointing在oneflow中的实现
bucket
Bucketing是一种训练多个不同但又相似的结构的网络的方法,这些网络共享相同的参数集。
一个典型的应用是循环神经网络(RNNs)。实现RNNs通常会沿时间轴将网络显式地展开。为了处理序列中的所有元素,我们需要将网络展开成最大可能的序列长度。然而这很浪费资源,因为对于较短的序列,大部分计算都浪费在填充的数据的执行上了。
Bucketing不再将网络展开成最大可能长度,而是展开成多个不同长度的实例(比如,长度为5, 10, 20, 30)。在训练过程中,对于不同长度的最小批数据,使用最恰当的展开模型。
https://blog.csdn.net/xuezhisdc/article/details/54927869
how_to——bucketing
在训练各个部分耗时中,backward(BWD)反向传播部分,通常占比比较大,相比之下,参数更新的部分(OPT)则通常是耗时比重小的部分。
所以为了能够overlap通讯的耗时,Pytorch DDP选择在backward的时候进行梯度更新,并且为此引入bucket的概念。一个bucket里通常有不超过一定大小的几个layer的参数组成(默认是25MB),当一个bucket内部的梯度准备好了之后,则这个bucket就可以开始进行ring-all-reduce取平均操作,而不需要等到计算完整个模型的反向传播过后才进行一次统一的ring-all-reduce操作,相当与把多卡通讯的时间隐藏在了backward计算的耗时中,大大提升了资源利用效率。
Horovod
Horovod是Uber开源的一套分布式深度学习框架。Horovod支持TensorFlow、Keras、PyTorch和Apache MXNet等后端框架。
官网:
https://eng.uber.com/horovod/
代码:
https://github.com/horovod/horovod
Horovod主打Data Parallel。这在前LLM时代用的比较多,但对于LLM而言,单卡根本放不下所有的参数,Data Parallel也就用不起来了。
参考:
https://www.cnblogs.com/rossiXYZ/p/14856464.html
深度学习分布式训练框架Horovod
https://zhuanlan.zhihu.com/p/40578792
Horovod-基于TensorFlow分布式深度学习框架
https://zhuanlan.zhihu.com/p/158375055
PyTorch单机多卡操作(分布式DataParallel,混合精度,Horovod)
https://mp.weixin.qq.com/s/iQIRj7ifsOEnupYZuQsVwQ
是时候放弃TensorFlow集群,拥抱Horovod了
https://mp.weixin.qq.com/s/qOjGrR59Mf0Mzgh4bpDhrA
详解Horovod:Uber开源的TensorFlow分布式深度学习框架
https://mp.weixin.qq.com/s/yNxjJHpGns6utpBpI-0XDA
分布式训练框架Horovod初步学习
https://zhuanlan.zhihu.com/p/374575049
一文看懂Horovod源码
https://mp.weixin.qq.com/s/7c7Q0P3g3IEL_r4BU2ZxRg
Horovod架构剖析——解密最成功的第三方DL分布式训练框架
https://horovod.readthedocs.io/en/stable/xla.html
Horovod with XLA in Tensorflow

您的打赏,是对我的鼓励
