DL acceleration » 深度加速(五)——硬件加速技巧, 模型优化工具
2020-12-02 :: 6100 Words知识蒸馏(续)
https://mp.weixin.qq.com/s/xcd9CHgE2_vEXrQ4MK019Q
知识蒸馏方法的演进历史综述
https://zhuanlan.zhihu.com/p/265906295
知识蒸馏:如何用一个神经网络训练另一个神经网络
https://mp.weixin.qq.com/s/qE1makMUIaFNrWk4nqOxDw
最新《知识蒸馏》2020综述论文,30页pdf,悉尼大学
https://zhuanlan.zhihu.com/p/51563760
知识蒸馏(Knowledge Distillation)最新进展(一)
https://zhuanlan.zhihu.com/p/53864403
知识蒸馏(Knowledge Distillation)最新进展(二)
https://zhuanlan.zhihu.com/p/81467832
知识蒸馏(Knowledge Distillation)简述(一)
https://mp.weixin.qq.com/s/pXoENwz4Z-eok9y3P9rQvg
知识蒸馏(Knowledge Distillation)简述(二)
https://zhuanlan.zhihu.com/p/102038521
知识蒸馏(Knowledge Distillation) 经典之作
https://zhuanlan.zhihu.com/p/92166184
知识蒸馏简述(一)
https://zhuanlan.zhihu.com/p/92269636
知识蒸馏简述(二)
http://coderskychen.cn/2019/02/23/distilling/
知识蒸馏三部曲:从模型蒸馏、数据蒸馏到任务蒸馏
https://mp.weixin.qq.com/s/5_qgj33tyVTHivpXkU4LDw
一个知识蒸馏的简单介绍
https://zhuanlan.zhihu.com/p/93287223
从入门到放弃:深度学习中的模型蒸馏技术
https://zhuanlan.zhihu.com/p/113549023
浅谈知识蒸馏方法研究综述
https://mp.weixin.qq.com/s/mFuxCl0Mzv5hmDFewWZkrw
FAIR&MIT提出知识蒸馏新方法:数据集蒸馏
https://mp.weixin.qq.com/s/MDgqSwVEClNqNpaWuGTEpg
微软亚研院提出用于语义分割的结构化知识蒸馏
https://blog.csdn.net/xbinworld/article/details/83063726
知识蒸馏(Distilling the Knowledge in a Neural Network),在线蒸馏
https://mp.weixin.qq.com/s/ekKg46bQlWrlg9Hon01M5g
Hinton胶囊网络后最新研究:用“在线蒸馏”训练大规模分布式神经网络
https://mp.weixin.qq.com/s/SqxooZqSeD3wA4EFK5D3Kg
再生神经网络:利用知识蒸馏收敛到更优的模型
https://mp.weixin.qq.com/s/Nkxy0SUdbwIjp5swU6tS9g
深度互学习-Deep Mutual Learning:三人行必有我师
https://mp.weixin.qq.com/s/I08kMmUohWWbYVpPDgTJsw
Startdt AI提出:使用生成对抗网络用于One-Stage目标检测的知识蒸馏方法
https://mp.weixin.qq.com/s/yFyM5OVp1YLKQBlgXeAzhw
华为诺亚方舟实验室提出无需数据网络压缩技术
https://mp.weixin.qq.com/s/0f0aToVaAsU7yWK4xz-HzQ
剪枝量化初完结,蒸馏学习又上线
https://github.com/patrickwaters1000/DistillingNeuralNets
Implements the technique of distillation
https://mp.weixin.qq.com/s/ckn4RERri-mfqLVPDRHGog
让学生网络相互学习,为什么深度相互学习优于传统蒸馏模型?
https://mp.weixin.qq.com/s/wwtsqjjUGt7MTEWDc5bSvQ
一种无需原始训练数据的Teacher-Student模型压缩方法
https://mp.weixin.qq.com/s/9dHRO80mMTGdRHaa0AdihQ
无需数据集的Student Networks
https://mp.weixin.qq.com/s/fQAkNdNhwkFichSZCwnNqA
北大、华为联合提出无需数据集的Student Networks
https://mp.weixin.qq.com/s/fA5NWLvLQN6kbB563pJnKg
从16.6%到74.2%,谷歌新模型刷新ImageNet纪录(Noisy Student)
https://mp.weixin.qq.com/s/UPm02RtTwhQhP_YhtmheBg
面向视觉智能的知识蒸馏和Student-Teacher方法,附37页pdf下载
https://zhuanlan.zhihu.com/p/143155437
知识蒸馏在推荐系统的应用
https://mp.weixin.qq.com/s/OFCzl8stFU5b1MWrkDU7NA
阿里电商推荐中如何进行特征蒸馏提升模型效果
https://mp.weixin.qq.com/s/ZNjC30F28uX2lBkHBAAU3g
双DNN排序模型:在线知识蒸馏在爱奇艺推荐的实践
https://mp.weixin.qq.com/s/_Wq7qawac1nTfZnV_AKG6w
模型压缩中知识蒸馏技术原理及其发展现状和展望
https://mp.weixin.qq.com/s/W8mLxU48dgWBB4eEFnU2rQ
知识蒸馏经典解读
https://zhuanlan.zhihu.com/p/144982430
强化学习如何用于模型蒸馏?
https://zhuanlan.zhihu.com/p/144987182
模型蒸馏的核心技术点有哪些,如何对其进行长期深入学习
https://mp.weixin.qq.com/s/3zpri6pfVtp-3-5_004B1Q
优势特征蒸馏在淘宝推荐中的应用
https://zhuanlan.zhihu.com/p/163477538
知识蒸馏与推荐系统
https://mp.weixin.qq.com/s/QpOx58M7lUfkONt-3SP8yg
知识蒸馏与推荐系统
https://mp.weixin.qq.com/s/TJVMuaDVZIjwqzuw6gd8uA
无数据知识蒸馏
https://zhuanlan.zhihu.com/p/90049906
知识蒸馏是什么?一份入门随笔
https://mp.weixin.qq.com/s/rxwHFjl0FEPWEcfMcwXL8w
BERT蒸馏完全指南
https://mp.weixin.qq.com/s/xgCtgEMRZ1VgzRZWjYIjTQ
知乎搜索文本相关性与知识蒸馏
https://mp.weixin.qq.com/s/6K5FvjMIVer-_fXJazU20Q
深度学习中的3个秘密:集成,知识蒸馏和蒸馏
https://mp.weixin.qq.com/s/-Rzvx9RMg9uZK5NFDs6cNg
语义分割的结构知识蒸馏
https://zhuanlan.zhihu.com/p/160206075
Knowledge Distillation(知识蒸馏)Review–20篇paper回顾
https://mp.weixin.qq.com/s/E7-MF18Y-UeKx694kGFHzA
深度学习中的知识蒸馏技术(上)
https://mp.weixin.qq.com/s/Noac4YLIimr1HM2fln2bjg
深度学习中的知识蒸馏技术(下)
https://mp.weixin.qq.com/s/IkKig7I5_97y_siixEj72w
协同训练
https://mp.weixin.qq.com/s/SUcz-Ba37CzUoAG52zW7YA
强化学习推荐模型的知识蒸馏探索之路
硬件加速技巧
https://mp.weixin.qq.com/s/KPT4P5SQ4E4ofPdjhhjRvA
如何加速深度神经网络计算效率?看NVIDIA-ISSCC2021教程,附93页Slides与视频
GEMM
多通道卷积操作最终可以转化为矩阵运算,如下图所示:
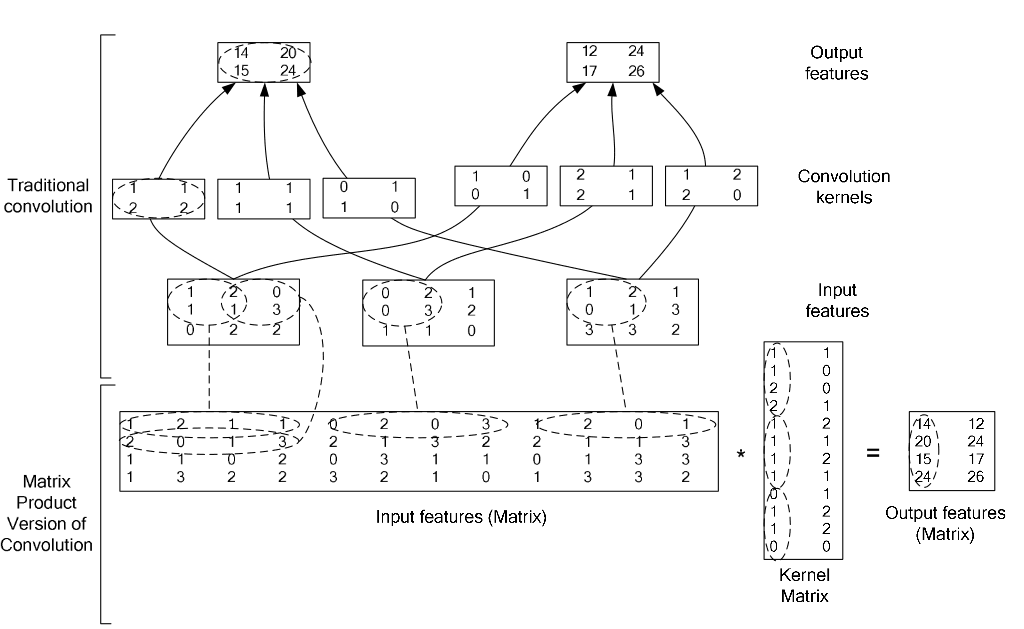

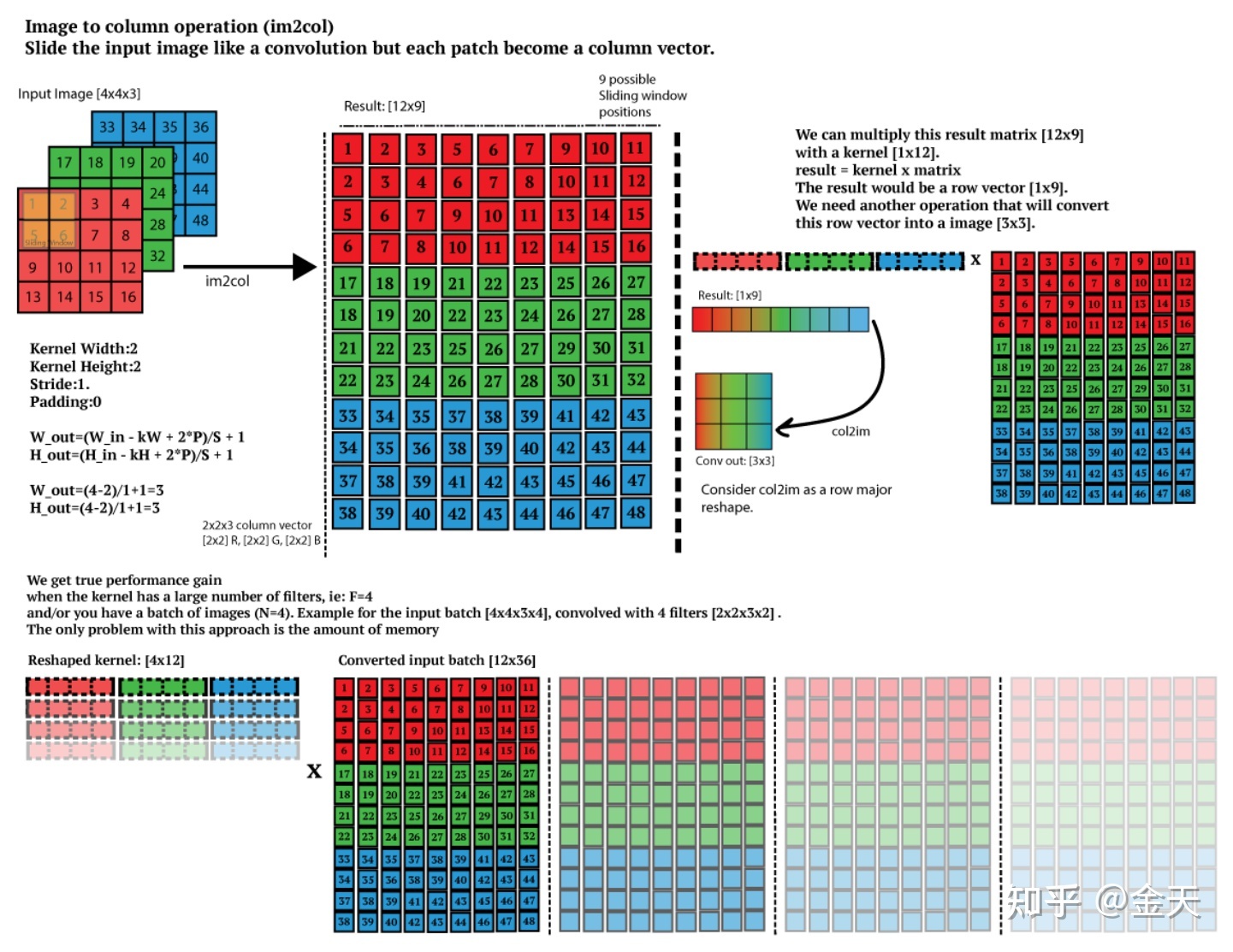
这种将卷积运算变为矩阵乘法运算的方法,一般被称为GEMM(General Matrix Matrix multiplication)。因为卷积变为矩阵这一步运算在Caffe中是用im2col函数实现的,因此,也有使用im2col来指代这类方法的。
要点:
-
forward的时候,只有input需要im2col。
-
backward的时候,先算好input_grad,再col2im将之变换到input的形状即可。
im2col的缺点在于input的数据按照conv的规则复制了若干份,对于计算的带宽要求较大。而在NV的实现中,input只需要保存一份,使用mask来选择需要被conv的数据,从而节省了带宽。
和GEMM类似的还有GEMV(General Matrix Vector multiplication)。
GEMM的公式是:
\[D= \alpha \times A \times B + \beta \times C\]其中的A、B、C为矩阵,\(\alpha, \beta\)为系数。但一般我们只关心其中的矩阵乘法。
Multiply Accumulate, MAC
Matrix Multiply Accumulate, MMA
Fused Multiply-Add, FMA
参见:
http://blog.csdn.net/u014114990/article/details/51125776
多通道(比如RGB三通道)卷积过程
https://www.zhihu.com/question/28385679
在Caffe中如何计算卷积?
https://buptldy.github.io/2016/10/01/2016-10-01-im2col/
Implementing convolution as a matrix multiplication(中文blog)
https://zhuanlan.zhihu.com/p/63974249
im2col方法实现卷积算法
https://zhuanlan.zhihu.com/p/66958390
通用矩阵乘(GEMM)优化与卷积计算
https://mp.weixin.qq.com/s/Q1Ovl1LrT5Y6amVqlYpdbA
基于GEMM实现的CNN底层算法被改?Google提出全新间接卷积算法
https://jackwish.net/2019/gemm-optimization.html
通用矩阵乘(GEMM)优化算法
https://mp.weixin.qq.com/s/lqVsMDutBwsjiiM_NkGsAg
详解Im2Col+Pack+Sgemm策略更好的优化卷积运算
https://mp.weixin.qq.com/s/EgC2puTsIfEk1uvgWlHXZA
基于how-to-optimize-gemm初探矩阵乘法优化
https://mp.weixin.qq.com/s/w0YCm8TEPxFg0CR6g4A28w
再探矩阵乘法优化
https://mp.weixin.qq.com/s/moQnarr1U-8v834bNJ10Zw
GPU上的高效softmax近似
https://petewarden.com/2015/04/20/why-gemm-is-at-the-heart-of-deep-learning/
Why GEMM is at the heart of deep learning
https://www.zhihu.com/question/1937383550547658365
npu底层设计,推荐卷积还是矩阵乘?
Tile
矩阵乘法的实现(matmul)是一个简易的三层for循环。这样的循环其实对于缓存是不友好的。
为解决缓存使用的问题,可以改变matmul的计算顺序,使得data矩阵的一部分数据可以长久地驻扎在缓存中,避免重复从内存读取这部分数据,这种技术被称为Blocking(或tiling)。它将矩阵划分几块,然后在小块中进行矩阵乘法,最后将数据汇集到输出矩阵中。
内积乘法 vs 外积乘法
做matrix矩阵计算(GEMM)有三种范式,外积、内积、脉动(systolic)。
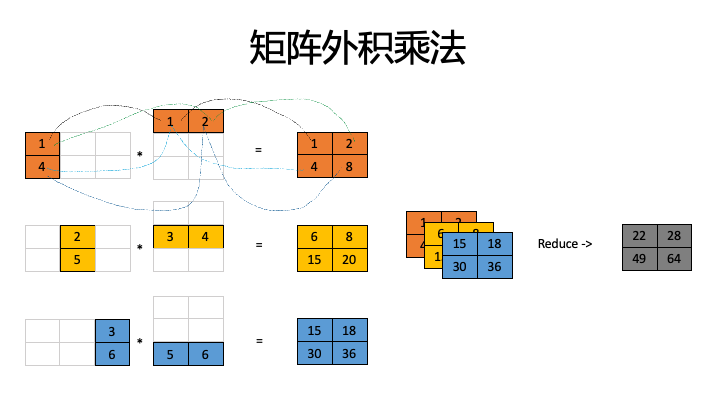
内积:优点是每次每个计算单元缓存的并不需要太多,gather时通讯带宽需求也低。缺点是每个计算单元会重复缓存相同行和列,整体上看缓存了很多遍AB矩阵,潜在问题是缓存冲突,访存延迟增加。
外积:优点是计算单元需要的数据少,整体上看只缓存一份A和B矩阵;缺点是每个计算节点计算结果无法及时reduce,导致输出访存量大,同时reduce操作数据较多,内部带宽要求高。
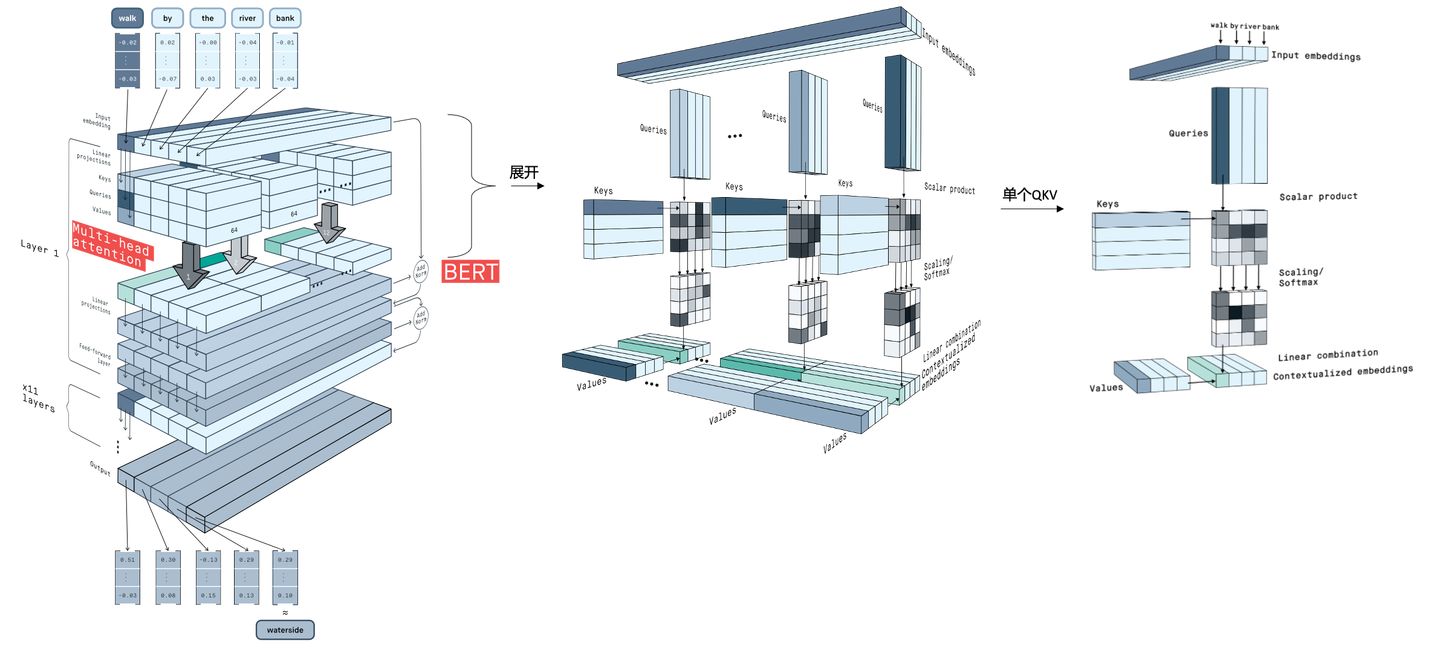
对于传统CNN网络,卷积核一般较小,适合于将核放入scratchpad memory(暂时存储器),内积的缓存劣势不明显,计算效率高。
但是对于transformer/bert等基于注意力机制的模型不但统治了NLP,在CV领域也大行其道的眼下,势必要优化下硬件结构,见前文分析,注意力机制使用QKV三个大矩阵两两相乘的结构,似乎更适合外积+片上SRAM。
内积和外积真正的分野,不是公式写法,而是你这一刀究竟切在了哪里:
- 若切在累加状态上,让一大片部分和长期悬在场上,等着输入一轮轮去拍它,这一路便更近外积;
- 若切在局部归并上,先把若干乘积在近处熬成一团,再去碰高精度总账,这一路便更近内积。
低精度时代真正贵的,往往不是“乘”,而是“加”。它不只是尾数相加,还牵着指数对齐、规格化、舍入,需要的位宽远大于乘法。外积递归求和的误差,并不是均匀地撒在每一步上,而是会被各步partial sum的大小加权;越往后加,旧部分和越大,新乘积便越容易受它支配。
训练里即便权重、激活、梯度都敢往低精度压,部分和累加却往往仍要保留更宽位宽,否则训练质量会明显下滑。

您的打赏,是对我的鼓励
