DL acceleration » NN Quantization(二)——Flexpoint, TF32, FP8, W4A16, FP4, OCP MX Formats, Posit
2019-07-26 :: 5614 Words- Flexpoint
- TF32
- x86 Extended Precision Format
- FP8
- BF8 and Tesla CFloat
- W4A16
- q4f16 & q3f16
- FP4
- OCP MX Formats
- Posit
Flexpoint
Flexpoint是Nervana的作品。
论文:
《Flexpoint: An Adaptive Numerical Format for Efficient Training of Deep Neural Networks》
讲了Google的成功案例,这里来讲一个反面教材。
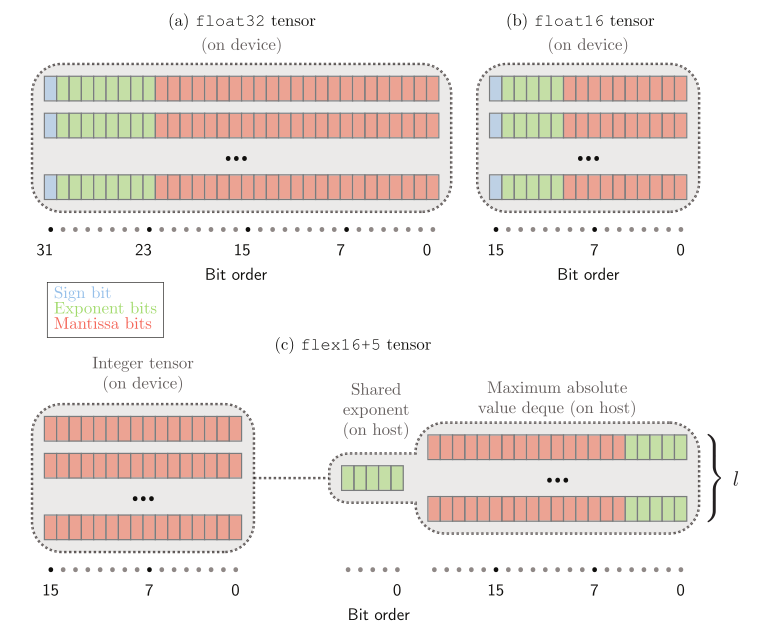
这实际上就是INT16的量化,用在inference上应该还是可以的,然而Nervana的目标还有training。
和bfloat16相比,它至少有如下问题:
-
格式转换比bfloat16复杂。
-
Dynamic Range小,容易梯度消失,从而造成模型很难收敛。
从指数位宽来看,Flexpoint和float16相同,都是5位。然而由于Flexpoint是共享指数,因此它真正的Dynamic Range是不如float16的。
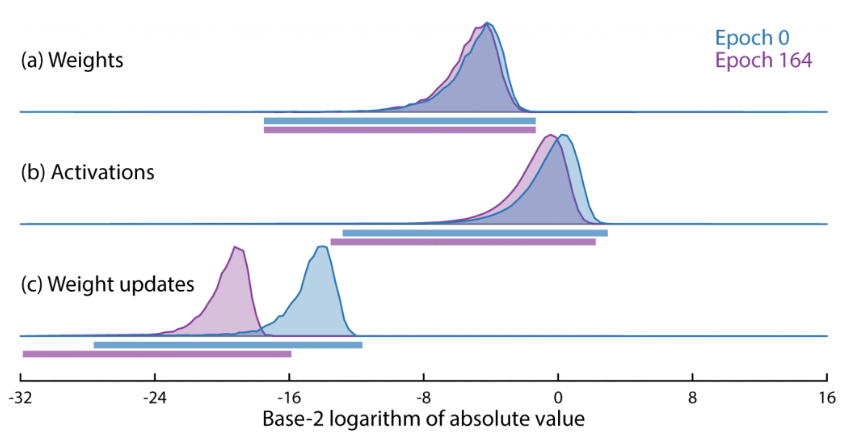
上图是模型训练过程中,相关值的典型范围。
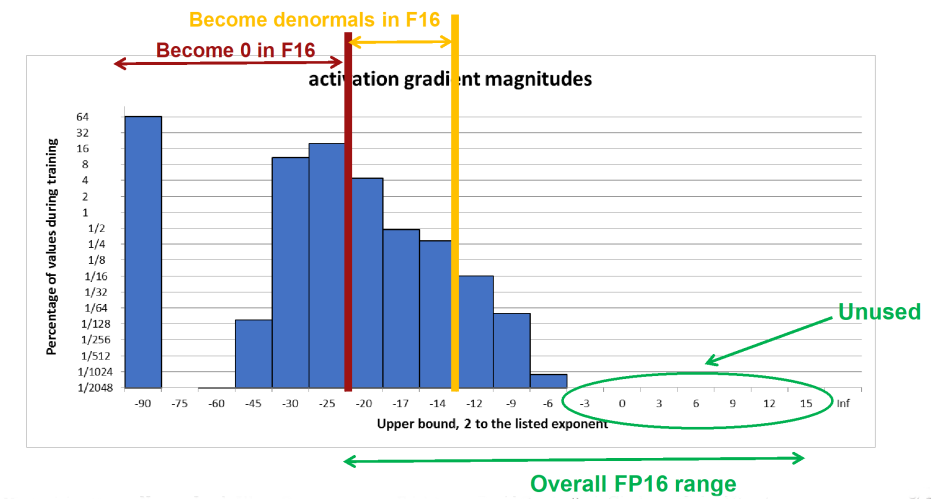
float16已经被证明是不适合training的,更遑论Flexpoint了。
事实上,Intel内部已有人评价道:
Flexpoint16三个月converge不了一个网络,而BF16一天就可以converge三个。
- 指数保存在Host上,会造成反复通信的带宽问题。
总的来说,这个方案虽然精巧,但是由于没有对数据特点做充分分析,没有意识到Dynamic Range比底数精度更重要,从而导致了最终的失败。
目前,整个芯片行业,已经由过去芯片专家根据以往经验(比如摩尔定律),定义下一代产品的规格,逐渐过渡到根据实际应用定义芯片的阶段,即所谓的“软件定义硬件”。
BF16的成功经验表明,算法专家在AI芯片中的重要程度,甚至超过了IC专家。
需要注意的是Flexpoint的失败,主要在于Dynamic Range和底数的位宽取舍上。他的设计思路本身还是有可取之处的。采用同样思路的MSFP就获得了成功。
MSFP由微软提出,在微软Project Brainwave产品上得到了广泛的应用。
参考:
https://www.intel.ai/flexpoint-numerical-innovation-underlying-intel-nervana-neural-network-processor/
Flexpoint: Numerical Innovation Underlying the Intel Nervana Neural Network Processor
https://zhuanlan.zhihu.com/p/33580205
Flexpoint——利用一种自适应的数据类型加速神经网络训练
https://mp.weixin.qq.com/s/z4OEPrAAtaNmBQoyvEd7Nw
从春秋到战国—论Nervana的倒掉
TF32
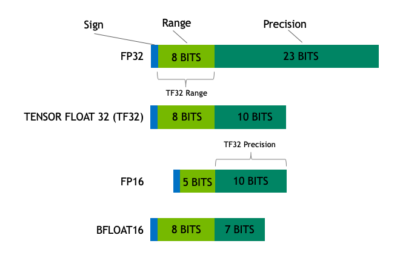
这是Nvidia推出的格式,相当于把FP32的指数和FP16的底数拼到了一起。有BF16珠玉在前,这个的设计只能说中规中矩了。
优点:底数精度虽然不如Dynamic Range重要,但对于运算结果还是有一定的影响的。这点在CNN中不太显著,但在RNN/Transformer中还是有所体现的。
缺点:毕竟不是16位,运算速度只有FP16/BF16的一半,但比FP32快一些。
BF16和TF32的先例一开,各种格式如火山爆发一般涌现。例如AMD的fp24,Pixar的pxr24,Enflame的ef32。
壁仞原创定义了TF32+,相较于TF32,在满足同样动态表示范围的前提下,增加了5位尾数。实际上就是pxr24。。。
参考:
https://zhuanlan.zhihu.com/p/143499632
NVIDIA A100 GPU中的TF32将AI训练与HPC速度提升20倍
https://www.cnblogs.com/zhouronghua/p/15170247.html
AI中各种浮点精度概念集合:fp16,fp32,bf16,tf32,fp24,pxr24,ef32
https://zhuanlan.zhihu.com/p/449857213
那些年,AI芯片里的浮点(FloatPoint)格式
x86 Extended Precision Format
Intel在早期的8087芯片上引入了一种80bit的浮点格式:1 Sign + 15 Exponent + 80 Significand
这个格式设计不知道是否启发了BF16,因为它采用了和IEEE 754中128bit相同的Exponent,正如BF16使用FP32的Exponent一样,都是高一个档次的Exponent搭配低档次的Significand。
FP8
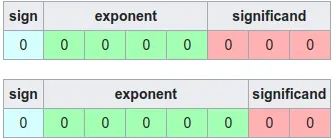
FP8包括两种常见的变种:E4M3(4位指数和3位尾数)和E5M2(5位指数和2位尾数)。
类似的还有FP6:E2M3和E3M2。
NVIDIA在H100中,添加了FP8的支持,但是去掉了对INT1/INT4的支持。。。看起来后两者还是实用价值偏低了。
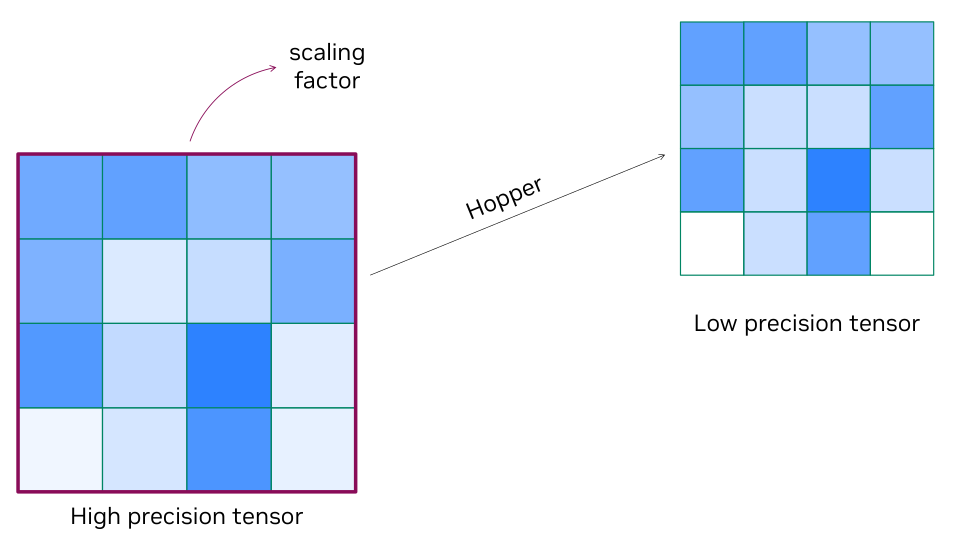
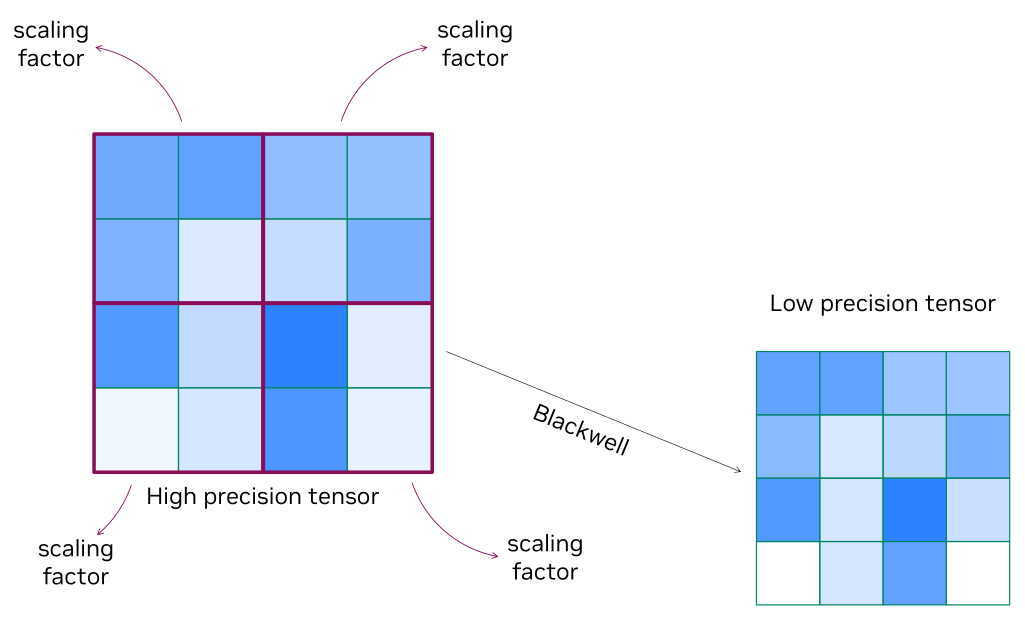
Blackwell使用了比Hopper更精细的scaling factor,用以降低量化误差。
参考:
https://zhuanlan.zhihu.com/p/521631165
Nvidia H100中的FP8
https://zhuanlan.zhihu.com/p/714933476
大模型量化技术原理:FP8
https://arxiv.org/pdf/2209.05433
FP8 Formats for Deep Learning
BF8 and Tesla CFloat
当我们将浮点的继续降低到8-bit的时候,BF8遇到的挑战越来越大。
在论文HFP8中,模型inference的时候,FP8(1-4-3)在mobilenet和transformer任务上明显的精度降低。
对于training来说,遇到的挑战进一步增大,weight/gradients/activation的范围相差更大,没有办法选择一个合适的格式来满足所有数值的要求。
HFP8就提出了一种Hybrid的方式:forward的时候用FP-1-4-3,backward的时候用FP-1-5-2。forward的时候,更关注精度,backward的时候更注重范围。这样的话,HFP8就能够在训练的过程中获得接近FP32的表现。
在工业界Tesla DoJo提出了一种可配置的CFloat,exponent和mantissa的位数可以动态的调整,只要满足总共的bit数就可以了。这样,由软件来选择合适的浮点类型CFormat,来最大化的利用硬件的性能。
《8-BIT NUMERICAL FORMATS FOR DEEP NEURAL NETWORKS》
CFormat这种动态调整exponent和mantissa位数的量化方式,又被称为Dynamic Fixed Point Quantization。
NV推出了一个叫做TransformerEngine的库,专门用于Hopper GPU上的FP8加速。
https://github.com/NVIDIA/TransformerEngine
W4A16
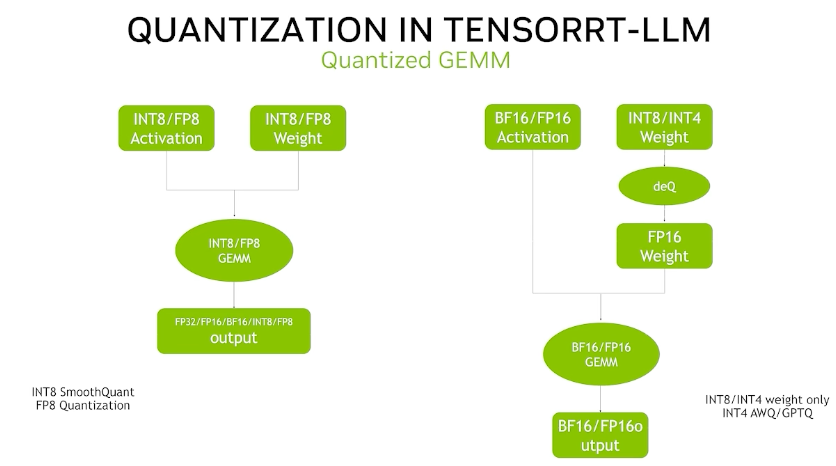
这种量化方式只对Weight使用4bit量化,而其他Tensor仍然使用16bit的浮点数。A是Activation的意思。
W4A16主要有GPTQ和AWQ等实现。

上图是QuaRot提出的一种W4A16在LLM领域的实践方法,其中还包含了KV Cache的4bit量化。
这是韩松团队的另一篇类似的论文:
《QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving》

参考:
https://zhuanlan.zhihu.com/p/681578090
大模型量化技术原理-AWQ、AutoAWQ
https://zhuanlan.zhihu.com/p/680212402
大模型量化技术原理-LLM.int8()、GPTQ
https://www.cnblogs.com/rossiXYZ/p/18903277
大模型量化基础
https://www.cnblogs.com/rossiXYZ/p/18916637
大模型量化方案
Marlin Quantization是Neural Magic推出的一套针对4-bit(INT4)权重量化的高性能GPU推理方案,但在Hopper GPU上表现不佳。因此Neural Magic又针对Hopper GPU推出了Machete Quantization。
AQLM(Additive Quantization for Language Models)是一种极端低位权重量化技术,由ISTA-DASLab等机构在2024年提出,可把LLM压缩到2-bit每权重,同时保持接近原始模型的性能。
q4f16 & q3f16
q3f16(q3指使用Quantize 3 bit来量化,f16是指核心计算使用fp 16来计算)。
FP4

IEEE版本的FP4(E2M1)如上图所示,但由于过于粗糙,一般使用更多的是所谓的NormalFloat的NF4。
NF4只能表示[-1, 1]之间的浮点数。由于在神经网络中,预训练的权重通常具有零中心的正态分布。所以根据正态分布的累积分布函数来量化,比均匀量化,效果要好一些。
所有可能的NF4值为:
[-1.0, -0.6961928009986877, -0.5250730514526367, -0.39491748809814453,
-0.28444138169288635, -0.18477343022823334, -0.09105003625154495, 0.0,
0.07958029955625534, 0.16093020141124725, 0.24611230194568634, 0.33791524171829224,
0.44070982933044434, 0.5626170039176941, 0.7229568362236023, 1.0]
注意:0左侧和右侧的量化是非对称的,因为[-1, 0]之间有8个值,而[0, 1]之间有9个值。
NF4是QLoRA引入的,而FP4目前只有NV的GPU支持。
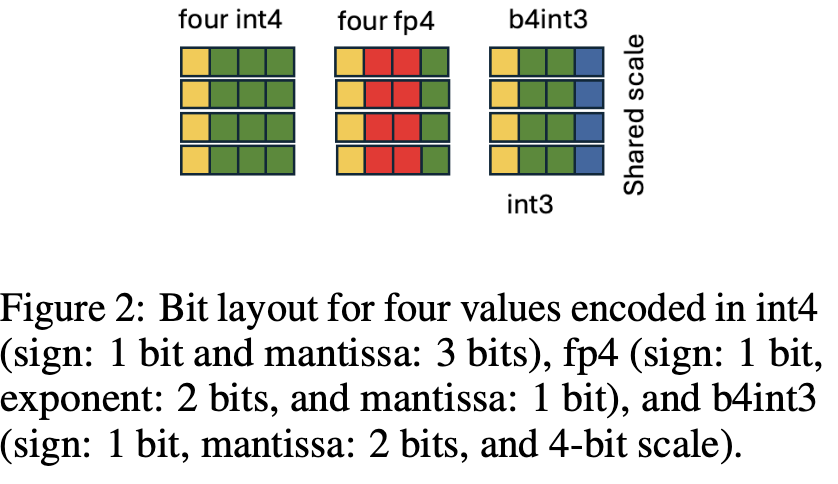
b4int3的scale复用前3位的数据,再加上自己的1位。但不管怎么变,还是只有16个取值,只是动态范围比前面几种FP4,要大的多。
OCP MX Formats
官方文档:
https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf
OCP Microscaling Formats (MX) Specification
Open Compute Project提出了一种有别于IEEE标准的浮点数格式。
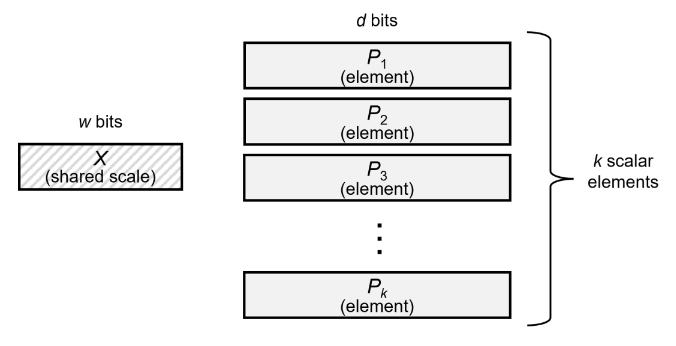
一个block包含w+kd bits的数据。
MX格式用block-wise共享指数X当input scale,用指数域直接相加的方式即时产生output scale,既能在训练端做反向传播,也能在推理端零开销还原,比传统per-channel/per-tensor scale更省带宽、更省寄存器。
这种方法也被称为Block Scaling。
DeepSeek-V3.1引入的UE8M0-FP8格式,这里的UE8M0实际上并不是FP8的格式,而是Block Scaling的格式。
f6E3M2FNU:
- f6:6bit浮点数。
- E3:3bit指数。
- M2:2bit底数。
- FN:没有infinity/NaN。
- U:没有0/负数。
参考:
https://zhuanlan.zhihu.com/p/705420505
OCP Microscaling Formats(MX)介绍
Posit
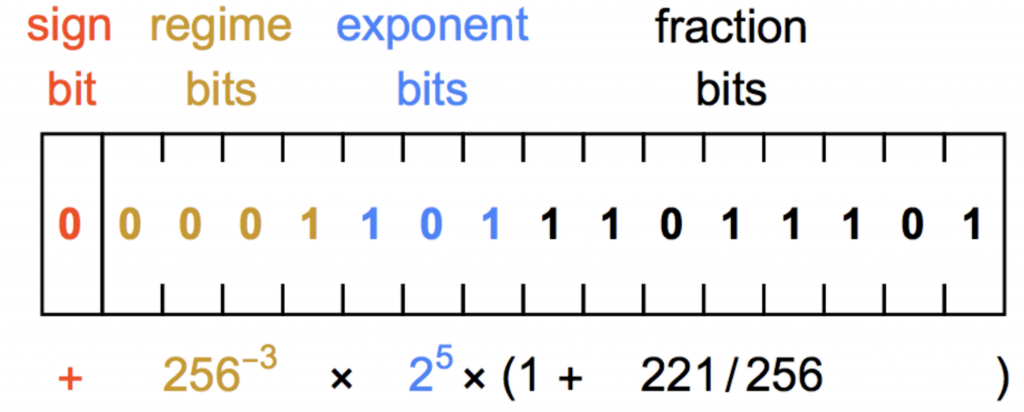
上图是Posit格式的示意图,除了符号位、指数和底数之外,它还包括了regime bits。
regime bits不知道怎么翻译,这里不妨意译为超指数。它的公式是:
\[useed^k\]其中,
\[useed=2^{2^{es}}\]es表示指数位的宽度,这里是3,所以\(useed=2^{2^{3}}=2^8=256\)
k的表示没有采用补码,而是一种特殊的方法:

k=从左面开始数0或者1的个数。
需要注意的是,同样总位宽的Posit格式,其每个部分(符号位除外,固定占1位)的宽度是不定的。除了regime bits是必须有的(但宽度不定)之外,指数和底数都是可选项。
Posit的设计思路其实是很自然的:
-
底数增加1位,Dynamic Range增加2倍。
-
指数增加1位,Dynamic Range增加\(2^2\)倍。
-
如果还想增加Dynamic Range,自然就需要引入超指数了。
https://www.sigarch.org/posit-a-potential-replacement-for-ieee-754
Posit: A Potential Replacement for IEEE 754
常见的软件实现:
https://github.com/cjdelisle/libposit
https://github.com/stillwater-sc/universal

您的打赏,是对我的鼓励
