DL acceleration » 并行 & 框架 & 优化(六)——Megatron-LM, KV Cache
2024-04-09 :: 6538 WordsFSDP(续)
FSDP本身并不能减少数据的通信量,更不可能减少计算量(所有的分布式算法都无法减少理论计算量),甚至还会增加数据的通信量。但是可以通过重叠IO和计算的时间,来提升系统的利用效率。显然与其等待全部计算完成,再All-Reduce,还不如算一部分,通信一部分来的快。
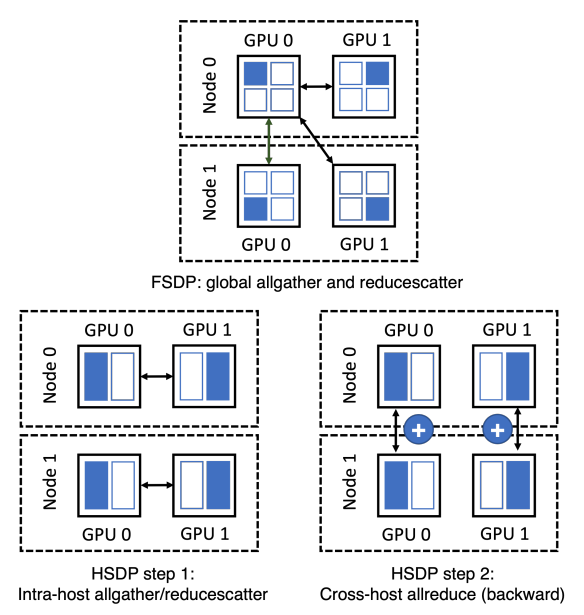
受到FSDP的启发,Facebook又发明了HSDP(hybrid sharding data parallel),进一步用小步快跑的IO策略,提升系统的利用效率。
pytorch roadmap:
- 3D Parallel = FSDP2 + ASync SP + PP
- 4D Parallel = FSDP2 + ASync SP + CP + PP
- 5D Parallel = HSDP2 + Async SP + CP + PP
代码:
https://github.com/facebookresearch/fairscale/blob/main/fairscale/nn/data_parallel/fully_sharded_data_parallel.py
pytorch里已经集成了该代码:
torch/distributed/fsdp/fully_sharded_data_parallel.py
FSDP的backward_prefetch策略是用于优化反向传播过程中通信和计算重叠的一种配置。
BACKWARD_PRE:这种模式在当前参数集的梯度计算之前就开始预取下一组参数。这可以实现最大程度的通信和计算重叠,但会增加最多的内存使用。它会在内存中同时持有当前参数集、下一组参数和当前梯度。
BACKWARD_POST:这种模式在当前参数集的梯度计算之后开始预取下一组参数。它允许较少的重叠,但内存使用也较少。在内存使用峰值时,它只持有下一组参数和当前梯度。
同样的还有forward_prefetch策略,FSDP会在当前前向计算之前显式地预取下一个前向传递所需的全收集(all-gather)操作。
需要注意的是,forward_prefetch只适用于静态图模型,因为预取操作是按照第一次迭代的执行顺序进行的。这意味着在动态图模型中,由于执行顺序可能在每次迭代中发生变化,因此不建议使用此策略。
参考:
https://www.cnblogs.com/rossiXYZ/p/15815013.html
Facebook如何训练超大模型—(1)
https://www.cnblogs.com/rossiXYZ/p/15819817.html
Facebook如何训练超大模型—(2)
https://zhuanlan.zhihu.com/p/485208899
数据并行Deep-dive: 从DP到Fully Sharded Data Parallel(FSDP)完全分片数据并行
https://pytorch.org/tutorials/intermediate/FSDP_tutorial.html
GETTING STARTED WITH FULLY SHARDED DATA PARALLEL(FSDP)
Megatron-LM
Megatron是NVIDIA的研究小组。目前已经推出了三篇论文:
《Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism》
《Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM》
《Reducing Activation Recomputation in Large Transformer Models》
目前训练超大规模语言模型主要有两条技术路线:TPU + XLA + TensorFlow/JAX和GPU + PyTorch + Megatron-LM + DeepSpeed。前者由Google主导,后者背后则有NVIDIA、Meta、MS大厂加持。
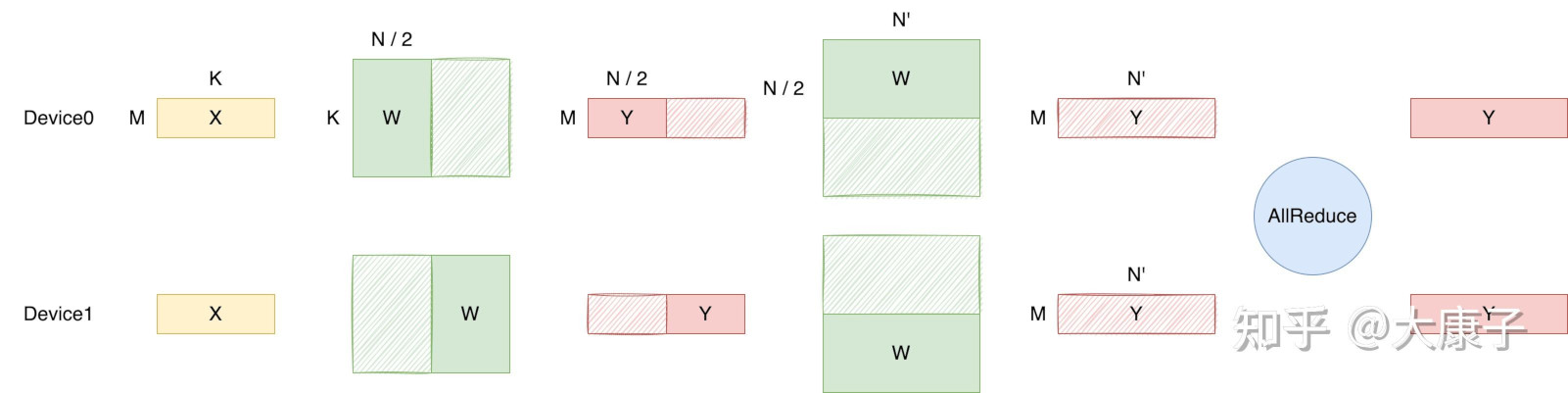
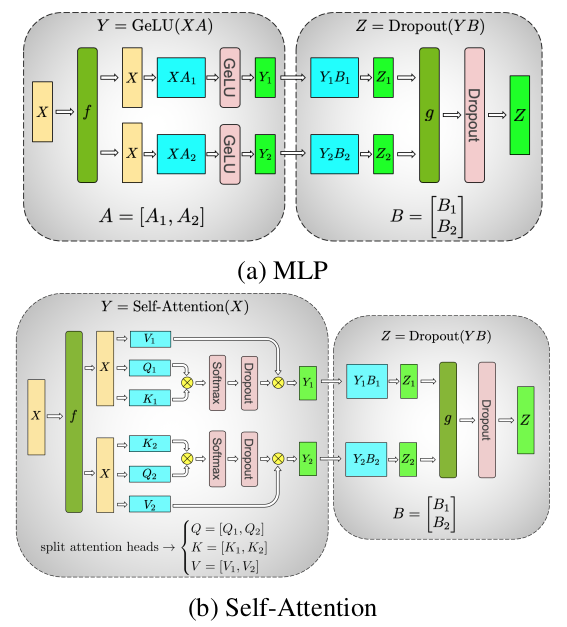
代码:
https://github.com/NVIDIA/Megatron-LM
微软还有一个项目将DeepSpeed和Megatron-LM结合了起来:
https://github.com/microsoft/Megatron-DeepSpeed
参考:
https://zhuanlan.zhihu.com/p/522198082
Megatron-LM 第三篇Paper总结——Sequence Parallelism & Selective Checkpointing
https://zhuanlan.zhihu.com/p/366906920
Megatron论文和代码详细分析(1)
https://zhuanlan.zhihu.com/p/388830967
Megatron论文和代码详细分析(2)
https://blog.csdn.net/v_JULY_v/article/details/132462452
通俗理解Megatron-DeepSpeed之模型并行与数据并行
https://mp.weixin.qq.com/s/bvF50XRaA9cO2O4oB31kbg
大语言模型分布式训练的量化分析与最佳实践,以GPT-175B为例
KV Cache

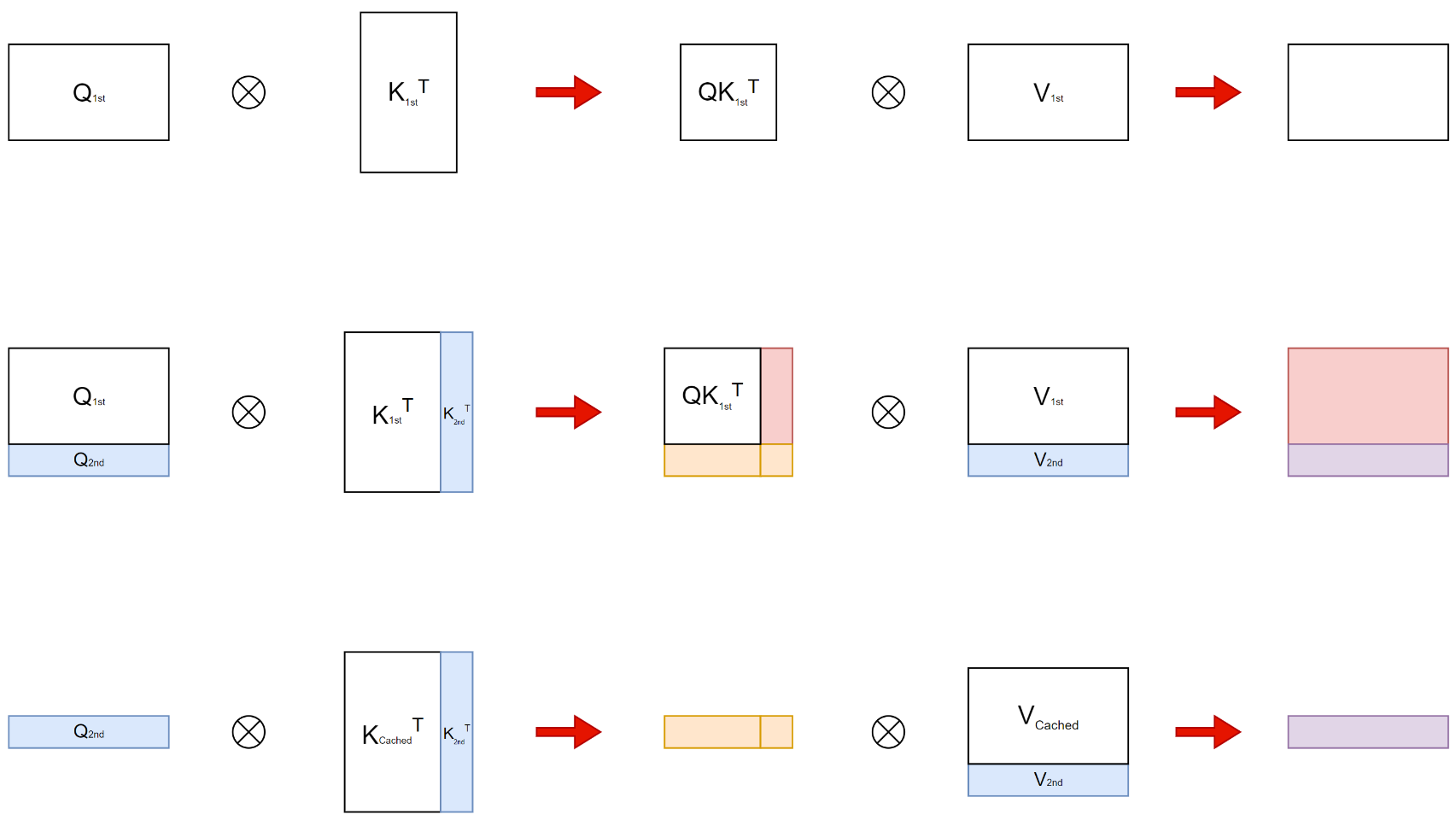
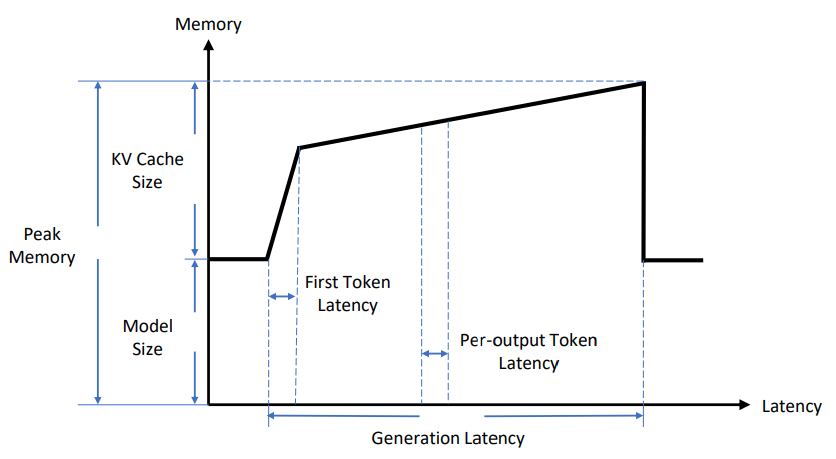
对于每个输入的prompt,在计算第一个token输出的时候,每个token的attention肯定是都要从头计算。但是在后续token的生成中,都需要计算self-attention,也就是输入prompt以及前面输出的token的attention。这是就需要用到前面每一个token的K和V,由于每一层的参数矩阵是不变的,此时只有刚生成的那个token的K和V需要从头计算,输入prompt和之前生成的token的K和V其实是跟上一轮一样的。
我们可以把每一层的K、V矩阵缓存起来,这就是所谓的KV Cache。
上图中,由于每次只有一个Q进行计算,所以并没有Q cache.
https://www.zhihu.com/question/653658936
为什么加速LLM推断有KV Cache而没有Q Cache?
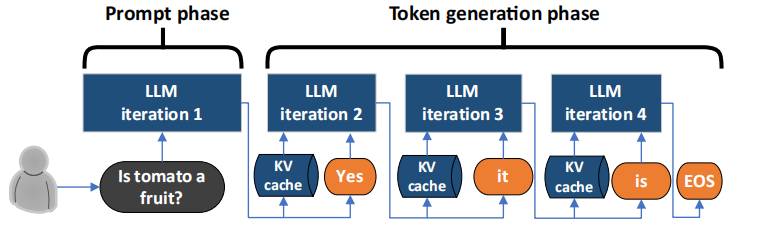
上图中的Prompt Phase又称为Prefill Phase,Token generation Phase又称为Decoding Phase。
KV Cache的使用方式一般如上图所示。其中蓝色表示输入里可以share的部分(即KV Cache),绿色表示输入里不可以share的部分,黄色表示输出。
某些非Dense Attention的KV cache的例子。
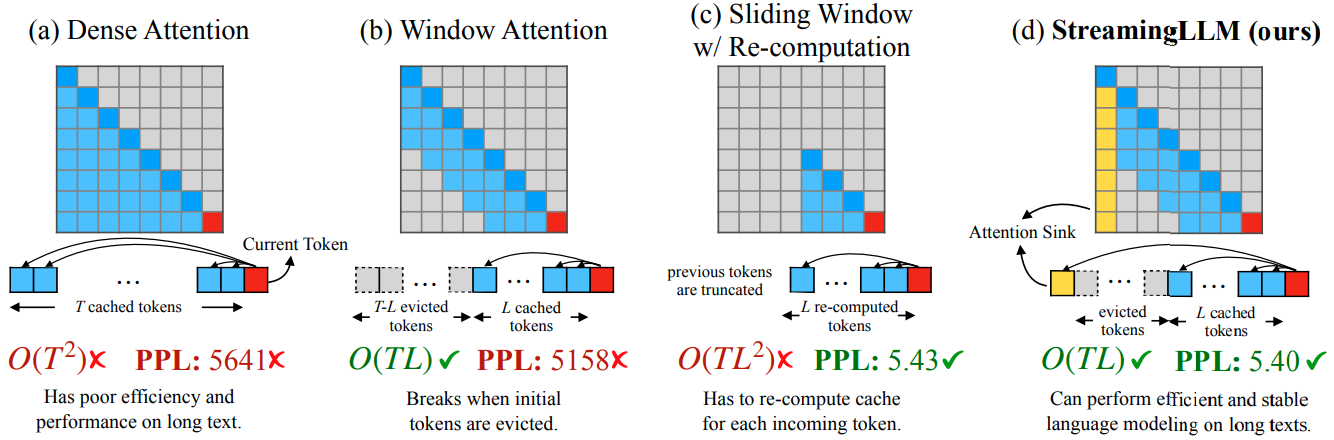
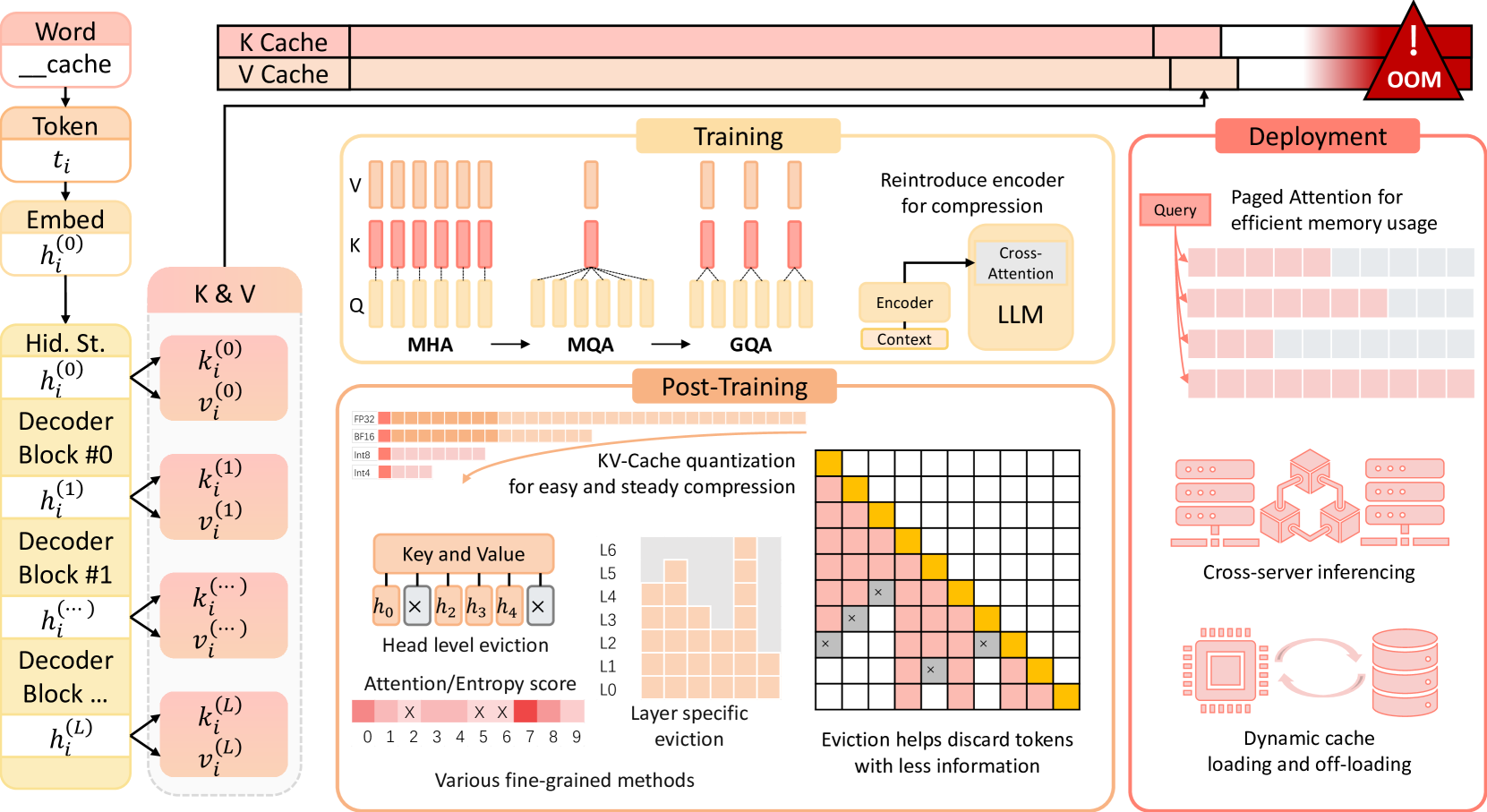
key cache对于量化更加敏感,一般采用FP16,而value cache可以看做都是同分布的,所以可以很容易找到相应的量化参数,一般使用INT8,甚至INT4量化。
key cache通常采用per channel量化,而value cache则主要采用per token量化。
https://zhuanlan.zhihu.com/p/691537237
量化那些事之KVCache的量化
https://zhuanlan.zhihu.com/p/630832593
大模型推理性能优化之KV Cache解读
https://zhuanlan.zhihu.com/p/662498827
大模型推理加速:看图学KV Cache
https://zhuanlan.zhihu.com/p/700197845
大模型推理优化技术-KV Cache
https://www.cnblogs.com/rossiXYZ/p/18799503
KV Cache
MQA & GQA
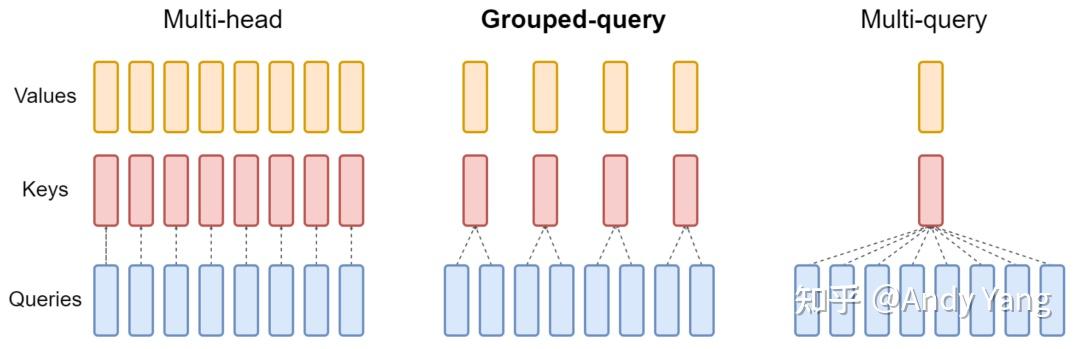
首先是原始的MHA(Multi-Head Attention),QKV三部分有相同数量的头,且一一对应。每次做Attention,head1的QKV就做好自己运算就可以,输出时各个头加起来就行。
而MQA则是,让Q仍然保持原来的头数,但K和V只有一个头,相当于所有的Q头共享一组K和V头,所以叫做Multi-Query了。
实现改变了会不会影响效果呢?确实会影响,但相对它30%-40%的吞吐收益,性能的些微降低是可以接受的。
而GQA呢,是MHA和MQA的折衷方案,既不想损失性能太多,又想获得MQA带来的推理加速好处。
https://zhuanlan.zhihu.com/p/647130255
为什么现在大家都在用MQA和GQA?
MLA
MLA是幻方量化投资的DeepSeek公司的DeepSeek-V2模型发明的。该模型1元/百万输入Tokens的价格,只有GPT4价格的1/100。
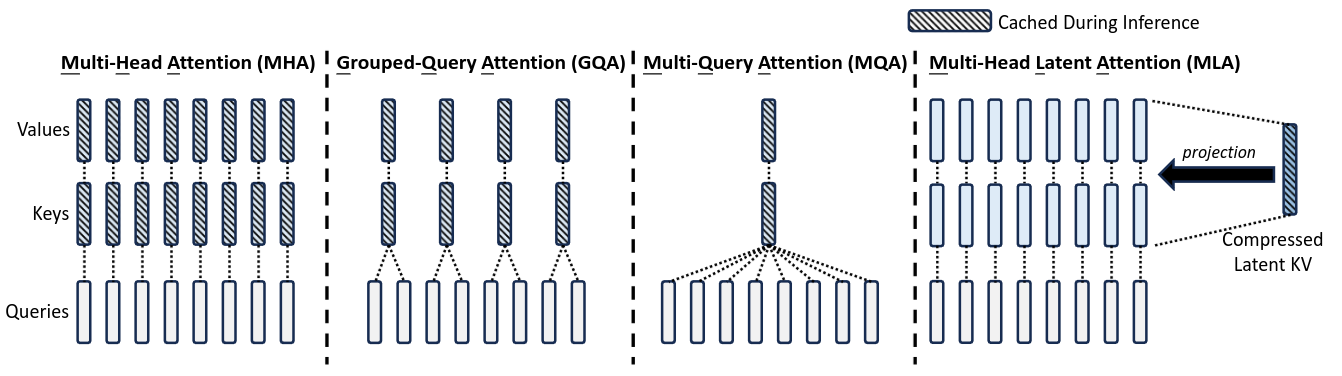
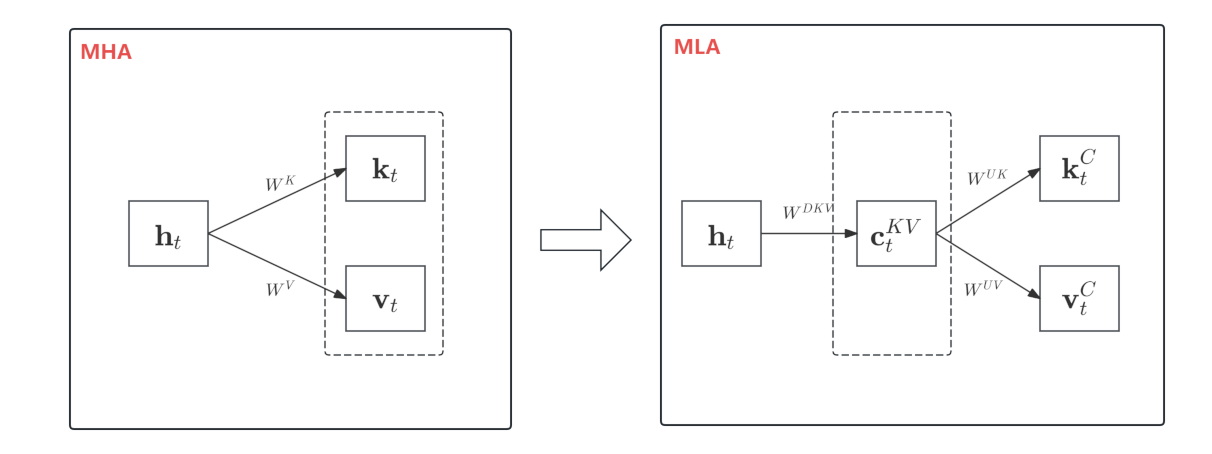
MLA的创新点,其实不是低秩分解,因为如果你想的话,GQA也可以重写成低秩分解的形式。
MLA的关键是低秩分解后面的事情,GQA是split and repeat,MLA则一般化为dense projection,从而实现了同样的低秩分解下更好的效果,或者同样效果下更低的秩,后者就是它能比GQA更进一步压缩KV Cache的根本原因。
推理时,MLA需要利用恒等变换才能实现低秩的KV Cache,但代价是每个头的Q/K的head_size变大了不少,所以理论上MLA推理的计算量是增加的。它最后之所以还能提高效率,是充分结合了LLM推理主要瓶颈是访存而不是计算这一特性。
MLA推理时,使用了矩阵吸收(matrix absorb)的技巧。
标准Attention权重的计算:
\[A=(x * W_q) * (x * W_k)^T\]通过矩阵的恒等变化,得到吸收后的权重计算方式为:
\[A=(x * (W_q * W_k^T)) * x\]而\(W_q * W_k^T\)可以作为Q的投影矩阵出现。
\[\require{cancel}\begin{array}{c|c} \text{训练/Prefill} & \text{Decoding} \\ \\ \begin{gathered} \boldsymbol{o}_t = \left[\boldsymbol{o}_t^{(1)}, \boldsymbol{o}_t^{(2)}, \cdots, \boldsymbol{o}_t^{(h)}\right] \\[10pt] \boldsymbol{o}_t^{(s)} = \frac{\sum_{i\leq t}\exp\left(\boldsymbol{q}_t^{(s)} \boldsymbol{k}_i^{(s)}{}^{\top}\right)\boldsymbol{v}_i^{(s)}}{\sum_{i\leq t}\exp\left(\boldsymbol{q}_t^{(s)} \boldsymbol{k}_i^{(s)}{}^{\top}\right)} \\[15pt] \boldsymbol{q}_i^{(s)} = \left[\boldsymbol{x}_i\boldsymbol{W}_{qc}^{(s)},\boldsymbol{x}_i\boldsymbol{W}_{qr}^{(s)}\color{#3ce2f7}{\boldsymbol{\mathcal{R}}_i}\right]\in\mathbb{R}^{d_k + d_r}\\ \boldsymbol{k}_i^{(s)} = \left[\boldsymbol{c}_i\boldsymbol{W}_{kc}^{(s)},\boldsymbol{x}_i\boldsymbol{W}_{kr}^{\color{#ccc}{\smash{\bcancel{(s)}}}}\color{#3ce2f7}{\boldsymbol{\mathcal{R}}_i}\right]\in\mathbb{R}^{d_k + d_r} \\ \boldsymbol{v}_i^{(s)} = \boldsymbol{c}_i\boldsymbol{W}_v^{(s)}\in\mathbb{R}^{d_v},\quad\boldsymbol{c}_i = \boldsymbol{x}_i \boldsymbol{W}_c\in\mathbb{R}^{d_c} \end{gathered} & \begin{gathered} \boldsymbol{o}_t = \left[\boldsymbol{o}_t^{(1)}\boldsymbol{W}_v^{(1)}, \boldsymbol{o}_t^{(2)}\boldsymbol{W}_v^{(2)}, \cdots, \boldsymbol{o}_t^{(h)}\boldsymbol{W}_v^{(h)}\right] \\[10pt] \boldsymbol{o}_t^{(s)} = \frac{\sum_{i\leq t}\exp\left(\boldsymbol{q}_t^{(s)} \boldsymbol{k}_i^{\color{#ccc}{\smash{\bcancel{(s)}}}}{}^{\top}\right)\boldsymbol{v}_i^{\color{#ccc}{\smash{\bcancel{(s)}}}} }{\sum_{i\leq t}\exp\left(\boldsymbol{q}_t^{(s)} \boldsymbol{k}_i^{\color{#ccc}{\smash{\bcancel{(s)}}}}{}^{\top}\right)} \\[15pt] \boldsymbol{q}_i^{(s)} = \left[\boldsymbol{x}_i\boldsymbol{W}_{qc}^{(s)}\boldsymbol{W}_{kc}^{(s)}{}^{\top}, \boldsymbol{x}_i\boldsymbol{W}_{qr}^{(s)}\color{#3ce2f7}{\boldsymbol{\mathcal{R}}_i}\right]\in\mathbb{R}^{d_c + d_r}\\ \boldsymbol{k}_i^{\color{#ccc}{\smash{\bcancel{(s)}}}} = \left[\boldsymbol{c}_i, \boldsymbol{x}_i\boldsymbol{W}_{kr}^{\color{#ccc}{\smash{\bcancel{(s)}}}}\color{#3ce2f7}{\boldsymbol{\mathcal{R}}_i}\right]\in\mathbb{R}^{d_c + d_r}\\ \boldsymbol{v}_i^{\color{#ccc}{\smash{\bcancel{(s)}}}} = \boldsymbol{c}_i= \boldsymbol{x}_i \boldsymbol{W}_c\in\mathbb{R}^{d_c} \end{gathered} \\ \end{array}\]上面的公式实际上就是下图中的MHA模式和MQA模式。
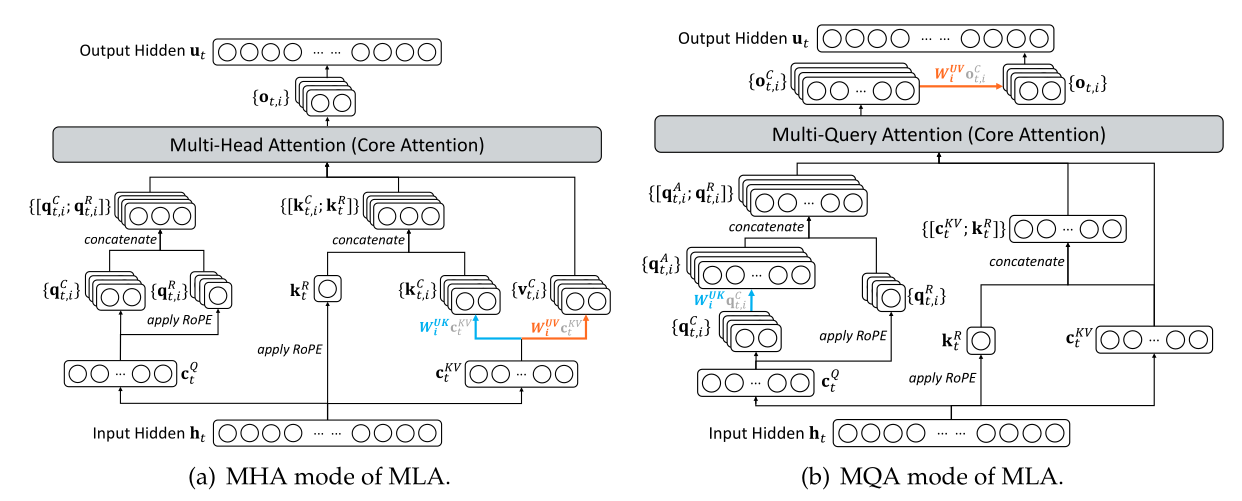
不难发现,矩阵吸收不是MLA独有的,MHA也可以做这样的操作。它本质上是用计算量换空间的策略。
Prefill阶段的瓶颈是计算量,MLA的矩阵吸收并没有优势,甚至更慢;但在Decode阶段,由于推理是逐token进行的,计算量少但需要线性积累KV Cache,总的KV Cache的大小就成为了显存瓶颈,MLA此时起到显著的作用。
而MHA使用矩阵吸收,由于增加的计算量过于巨大,无论何种阶段都没有收益。

您的打赏,是对我的鼓励
