DL acceleration » 并行 & 框架 & 优化(二)——Parameter Server, MPI
2019-07-02 :: 4583 Words概述(续)
并行性的粒度
细粒度并行:
-
计算量不要过大,这样每个线程都有足够的工作可做。
-
尽可能减少在数据同步上的开销,这样每个线程能够独立的完成自己的任务。
-
负载的划分也很重要,因为有大量的独立任务需要并行执行,设计良好的任务调度器都能灵活控制负载,并保证在多任务运行的同时,让线程上的达到均衡。
粗粒度并行:
-
计算量肯定要高于细粒度并行时的计算量,因为不会像细粒度并行那样,有很多线程同时执行。
-
编程者使用粗粒度编程时,需要了解应用的整体结构,让粗粒度中的每个线程作为任务,服务于应用。
通常来说,上层App(当同步和通讯的开销大于计算)一般采用粗粒度并行,而底层算子(比如CUDA/OpenCL)采用细粒度并行。
并行的层级
指令并行、线程并行、单机多卡并行、集群并行。
https://zhuanlan.zhihu.com/p/381978470
一文读懂Pod(集群)
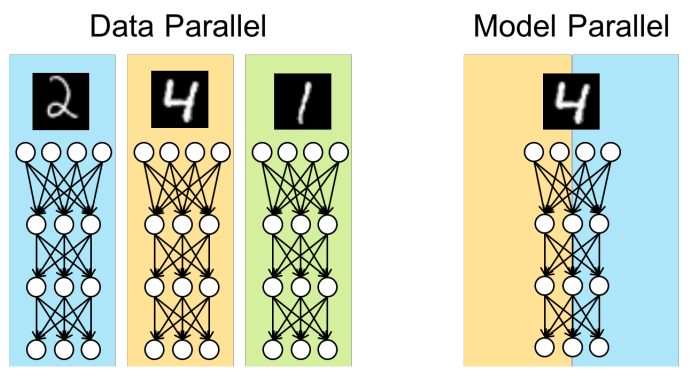
数据并行 & 模型并行
当数据量很大时,单个节点需要很长时间才能完成1轮训练,这对于动辄十几轮或几十轮的训练来说是不可忍受的,所以可以将数据进行划分并分配给多个节点,每个节点处理自己的一小部分数据,从而加快整体的训练速度。在TensorFlow中数据并行也被称为图间复制(Between-graph Replication)。
模型并行是指将模型切分为多个部分并将各个部分放置到不同的节点进行训练的分布式模式。因为当模型很复杂,参数很多时,由于内存的限制,单个节点无法将整个模型加载并进行训练,所以需要将模型切割为更小的部分,并将各个部分运行在不同的节点上以完成训练。在TensorFlow中模型并行也被称为图内复制 (In-graph Replication)。
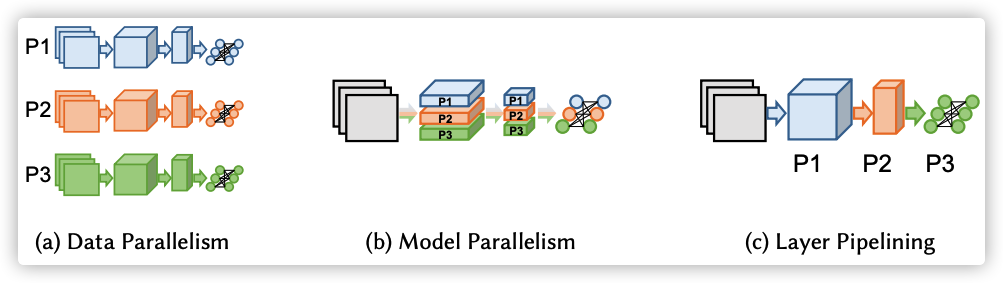
模型并行又可以按照是否对算子进行切分而分为两类,即上图中的b和c。其中c又被称为pipeline并行。
并行的精髓在于切分:
切分Batch:数据并行
切分Layer:pipeline并行
切分其他维度:模型并行
多GPU的数据并行和单GPU不完全等价,主要是batch norm不等价。每张卡单独计算均值和分差,和单卡算出来的不一样。必须进行相应的同步操作,才能得到等价的结果。
Distributed Data Parallel
https://mp.weixin.qq.com/s/52Wz4pUI8egKugMFuknWKw
Pytorch中的Distributed Data Parallel与混合精度训练(Apex)
https://mp.weixin.qq.com/s/x1Z4jkMvfo4mD-_rKqvjuw
在PyTorch中使用Distributed Data Parallel进行多GPU分布式模型训练
https://zhuanlan.zhihu.com/p/178402798
DDP系列第一篇:入门教程
https://zhuanlan.zhihu.com/p/187610959
DDP系列第二篇:实现原理与源代码解析
https://zhuanlan.zhihu.com/p/250471767
DDP系列第三篇:实战与技巧
Parameter Server
在深度学习概念提出之前,算法工程师手头能用的工具其实并不多,就LR、SVM、感知机等寥寥可数、相对固定的若干个模型和算法;那时候要解决一个实际的问题,算法工程师更多的工作主要是在特征工程方面。而特征工程本身并没有很系统化的指导理论(至少目前没有看到系统介绍特征工程的书籍),所以很多时候特征的构造技法显得光怪陆离,是否有用也取决于问题本身、数据样本、模型以及运气。如果给这种方式起一个名字的话,大概是简单模型+复杂特征;
深度学习代表的简单特征+复杂模型是解决实际问题的另一种方式。
两种模式孰优孰劣还难有定论,以点击率预测为例,在计算广告领域往往以海量特征+LR为主流,根据VC维理论,LR的表达能力和特征个数成正比,因此海量的feature也完全可以使LR拥有足够的描述能力。
Parameter Server就是处理海量特征计算的一种方法。
我最初也被某系统号称上亿的特征给吓到了,毕竟自己设计的推荐系统搜肠刮肚也不过500左右的特征。后来才了解到,国内几家大公司在特征构造方面的成功率在后期一般不会超过20%。也就是80%的新构造特征往往并没什么正向提升效果。一个特征随便弄一下(窗口滑动、离散化、归一化、开方、平方、笛卡尔积、多重笛卡尔积)就弄出一堆特征。。。
一些所谓从事数据挖掘工作多年的专家,其实从方法论上也没有多高明。特征工程严重依赖领域知识,理论知识嘛,LR又不是多高深的东西。。。
2017.5,我曾去某电商面试推荐系统职位。言谈之中发现他们对于DL几乎一无所知,当时就觉得有些古怪。直到接触Parameter Server才明白了他们的玩法。。。非常庆幸他们鄙视了我。后来到了2017.12的时候,他们主动找我,想再次面试,被我婉拒。
这类问题的另一个特征是:特征虽多,但单独的一个样本具有的有效特征相对有限,一般不过数百个。使用样本更新参数时,只考虑这几百个特征即可,这也为相关的分布式运算提供了有利条件。
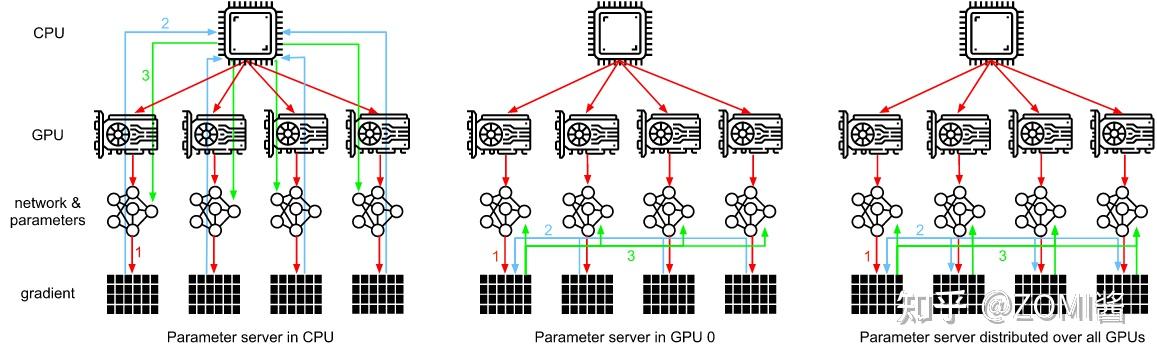
如图所示,PS架构将计算节点分为server与worker,其中,worker用于执行网络模型的前向与反向计算。而server则对各个worker发回的梯度进行合并并更新模型参数,对深度学习模型参数中心化管理的方式,非常易于存储超大规模模型参数。
但是随着模型网络越来越复杂,对算力要求越来越高,在数据量不变的情况下,单个GPU的计算时间是有差异的,并且网络带宽之间并不平衡,会存在部分GPU计算得比较快,部分GPU计算得比较慢。这个时候如果使用异步更新网络模型的参数,会导致优化器相关的参数更新出现错乱。而使用同步更新则会出现阻塞等待网络参数同步的问题。
参考:
https://www.zhihu.com/question/26998075
最近比较火的parameter server是什么?
http://blog.csdn.net/cyh_24/article/details/50545780
Parameter Server详解
https://mp.weixin.qq.com/s/yuHavuGTYMH5JDC_1fnjcg
阿里妈妈基于TensorFlow做了哪些深度优化?TensorFlowRS架构解析
https://zhuanlan.zhihu.com/p/29968773
大规模机器学习框架的四重境界
https://mp.weixin.qq.com/s/2RCH2Or_ITUTGrlfYLB8mg
腾讯千亿级参数分布式ML系统无量背后的秘密
https://zhuanlan.zhihu.com/p/82116922
一文读懂“Parameter Server”的分布式机器学习训练原理
https://mp.weixin.qq.com/s/5Ae1NyLM-jZnO6TCOPMYkQ
PS Worker分布式性能优化
https://www.cnblogs.com/rossiXYZ/p/15897877.html
NVIDIA HugeCTR,GPU版本参数服务器
MPI
Parameter Server这种参数中心化的分布式计算方案,主要适用于稀疏矩阵的参数更新。对于多数的DL算法而言,采用参数去中心化的集合通讯模式是一种更有效率的做法。
集群可以很好解决单节点计算力不足的问题,但在集群中大规模的数据交换是很耗费时间的,因此需要一种在多节点的情况下能快速进行数据交流的标准,这就是Message passing interface(MPI)。
MPI的主流实现主要是:mpich,openmpi,Intel MPI,Microsoft MPI,其中Intel MPI和Microsoft MPI都是基于开源的mpich。
和MPI类似的技术,还有NVIDIA的NCCL,FaceBook的gloo等。
NVIDIA SHARP:Scalable Hierarchical Aggregation and Reduction Protocol
MPI官网:
http://www.mpi-forum.org/docs/
1994:MPI-1
1998:MPI-2
2012:MPI-3
2021:MPI-4
因为MPI的历史比较久远,深刻影响了后来的分布式并行程序,比如TF等。所以这里简单介绍一下几个关键的术语。
gloo官网:
https://github.com/facebookincubator/gloo
基础术语
Incast:多个发送者向一个接收者发送数据。
Multicast:一个发送者向多个接收者发送数据。
Broadcast:一个发送者向所有可能的接收者发送数据。
Barrier
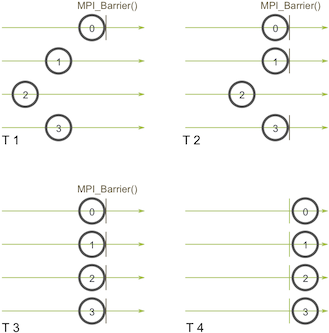
这个方法会构建一个屏障,任何进程都没法跨越屏障,直到所有的进程都到达屏障。
实现屏障的方式有很多,最简单的是令牌环(token ring)。
第一个进程到达的屏障生成一个token,然后传递给下一个到达屏障的进程。所有的进程都到达屏障之后,token被传递回第一个进程。
MPI_Barrier在TF中被称为AfterAll。
Bcast & Scatter
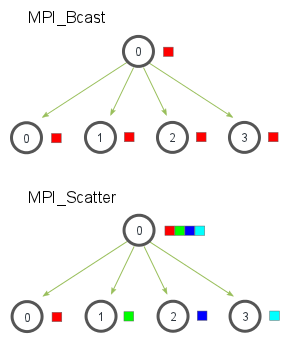
MPI_Bcast给每个进程发送的是同样的数据,然而MPI_Scatter给每个进程发送的是一个数组的一部分数据。
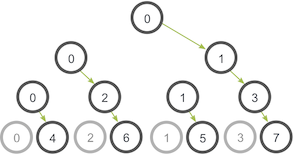
在上图的树形算法里,能够利用的网络连接每个阶段都会比前一阶段翻番,直到所有的进程接收到数据为止。
Gather & Allgather
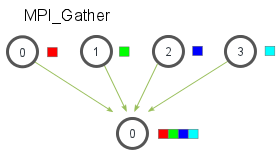
MPI_Gather跟MPI_Scatter是相反的。
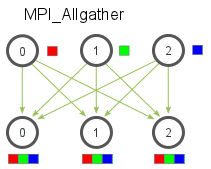
MPI_Allgather相当于一个MPI_Gather操作之后跟着一个MPI_Bcast操作。
allgather操作常见的有两种实现方式:Recursive Doubling和Bruck算法。
Reduce & Allreduce
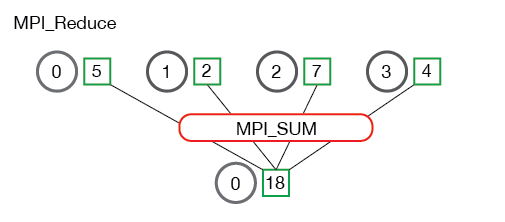
数据归约包括通过函数将一组数字归约为较小的一组数字。例如,假设我们有一个数字列表[1,2,3,4,5]。用sum函数归约此数字列表将产生sum([1、2、3、4、5]) = 15。
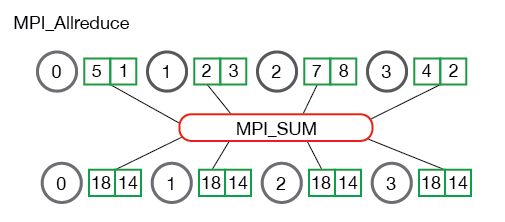
MPI_Allreduce等效于先执行MPI_Reduce,然后执行MPI_Bcast。
ReduceScatter

它的作用相当于分布式AllReduce+Shard操作。它的对偶操作是:Allgather。
ReduceScatter操作有两种实现方式:Recursive Halving和Pairwise Exchange。

您的打赏,是对我的鼓励
