DL acceleration » 浮点运算和代码优化, 并行 & 框架 & 优化(一)——概述
2015-10-12 :: 5561 Words浮点运算和代码优化
浮点运算问题
浮点运算在工业中应用非常广泛,但嵌入式CPU通常没有对浮点运算提供直接的硬件支持。而采用标准库提供的软件计算方案,性能又很差。这时就需要使用浮点运算协处理器加速浮点运算。(486之前的PC,CPU和浮点运算协处理器FPU也是分开的,例如i486DX是有FPU的型号,而i486SX则是没有FPU的型号。)
硬件的支持离不开软件的使用。如果在添加了FPU的硬件上,使用浮点计算的软件方案的话,FPU也是不起作用的。因此必须用FPU驱动库函数替换标准库提供的软件方案的相应函数。
最直观的做法是将所有用到浮点计算的地方都替换成FPU函数。例如如下代码:
float a,b,c;
a = b + c;
假设FPU加法函数的原型为:
float Add(float a, float b);
如果我们要使用FPU硬件加速的话,只需要将上述代码改为:
float a,b,c;
a = Add(b,c);
就可以了。
上面的这种方法显然是直观而正确的,但是却不方便。需要将源代码中,所有涉及到浮点运算的地方都做相应的修改,而且以函数的方式取代C语言中的运算符,本身书写起来也很麻烦。
我们可以这样思考一下,C语言是如何将运算符转换成机器指令的呢?首先编译阶段肯定要做类型判断,整数加法和浮点数加法的指令显然不会相同。而链接阶段,只有符号表的概念,类型也好、运算符也好,都灰飞烟灭了。
因此,我们只要看一看浮点加法的汇编指令,就可以找到相关的符号表了。经查浮点加法对应的符号是__adddf3(gcc下)。因此它的原型就是:
float64 __adddf3(float64 x, float64 y)
将FPU函数写成这个样子,然后在链接阶段替换标准库函数就可以了。具体操作如下:
1.使用nm命令查看libgcc.a中的符号表,可以查到__adddf3在_addsub_df.o中。
2.使用ar -d从libgcc.a中去掉_addsub_df.o。
3.在链接时使用FPU函数库
立即数计算量的问题
请看以下代码:
float64 a, b,c;
a = 2 * PI * (b - c) / 365.25;
机器执行这段代码会进行几次运算呢?
答案是3次。虽然有4个运算符,但2*PI是在编译阶段运算的。(这可以通过查看生成的汇编代码来验证。)基于同样的理由,我们还可以改进这段代码:
a = 2*PI / 365.25 * (b - c);
这样只需要2次运算了。
需要说明的是括号如果不改变运算的顺序的话,是不会改变计算次数的。因此
a = (2*PI / 365.25) * (b - c);
和
a = 2*PI / 365.25 * (b - c);
是等效的,都只需要2次运算。
3.冗余代码的问题
假设我们定义了a函数,但是在其他地方并未使用该函数,我们是否可以认为a函数的代码不会出现在最终的可执行文件中呢?
这个问题至少在gcc没有设置任何参数时,是否定的。不管a函数使用与否,它的代码都会包含在最终的可执行文件中。
对于PC来说,这不是个太大的问题,但对于嵌入式设备来说,任何空间的浪费都是不可接受的。
写到这里,有人会说,使用gcc的-o2选项优化代码,不就可以了吗?遗憾的是,这是不行的。
-o2有什么作用呢?还是上面的例子:
void main()
{
float64 a, b,c;
a = 2 * PI * (b - c) / 365.25;
}
如果是-o2选项的话,机器会进行几次运算呢?
答案是0次。这种不涉及到输出结果的计算,直接被忽略掉了。
回到第一个问题。如何做才能在最终的可执行文件中不包含未使用的函数呢?步骤如下:
1.gcc添加-ffunction-sections选项。我们通常的做法是一个.c文件编译生成一个.o文件。而这个.c文件中的函数代码都会包含在.o文件的.text段(section)中。而-ffunction-sections选项会将每个函数放在单独的段中,例如a函数,会被放到.text.a段中。
2.ld添加–gc-sections选项。这个选项的作用是不链接未使用的段。
从上面的步骤可以看出,链接的最小单位既不是.o文件,也不是单个函数,而是段。
使用以上方法生成的程序,理论上没什么问题,但实际中,还是有不方便之处:为每一个函数生成一个段,可以想象可执行文件中会有多少段,而在某些平台上,代码在段之间的跳转是要比段内跳转消耗资源的。
我们可以在链接脚本中合并这些段,以下是一个简单的实例:
.text :
{
. = ALIGN(4);
text_start = .;
*(.text.*)
. = ALIGN(4);
text_end = .;
}
参考
https://zhuanlan.zhihu.com/p/482979228
看完微软大神写的求平均值代码,我意识到自己还是too young了
概述
George S. Almasi和Allan Gottlieb于1989年将并行计算机定义为:“并行计算机是一些处理单元的集合,它们通过通信和协作快速解决一个大的问题”。
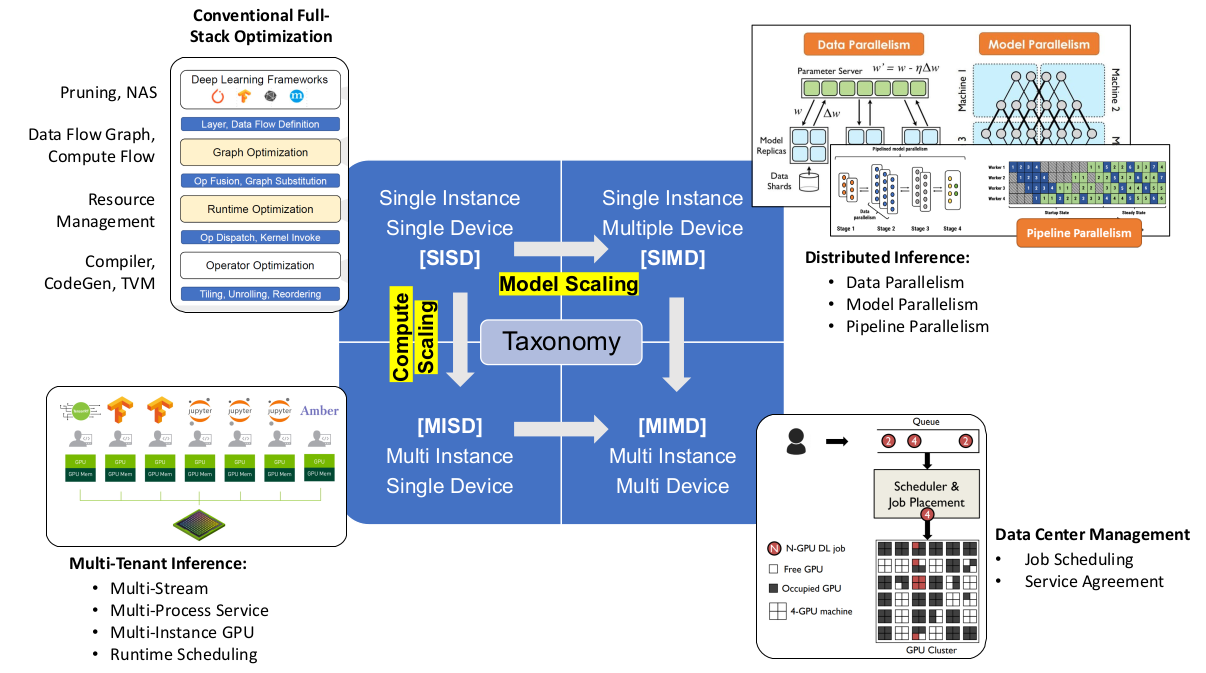
并行计算的必要性:
美国Sandia国家实验室一项模拟测试证明:由于存储机制和内存带宽的限制,16核、32核甚至64核处理器对于超级计算机来说,不仅不能带来性能提升,甚至可能导致效率的大幅度下降。必须研究并行计算的算法,才能有效克服这些缺陷。
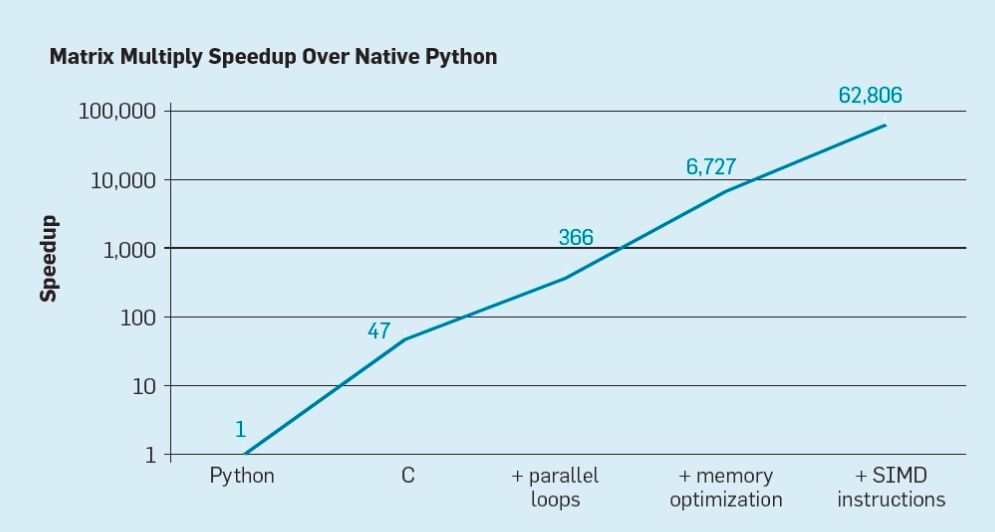
2001年,斯坦福大学Bill Dally教授团队在处理器微结构旗舰期刊《IEEE Micro》上发表了一篇题为“Imagine: Media Processing with Streams”的论文,介绍了一个可加速多媒体应用的流处理器(Stream Processor)结构。
这项工作很快引起了英伟达的关注,并向Dally教授伸出橄榄枝。2003年,Dally教授担任英伟达的顾问,参与公司新一代GeForce 8800系列GPU的微架构设计,指导如何在GPU中加入流处理器(Stream Processor),让GPU具备浮点运算能力。
与此同时,斯坦福大学一位年轻的博士生Ian Buck在导师Pat Hanrahan教授(2019年图灵奖得主)的指导下开展如何方便且高效发挥GPU能力的研究。2004年,Ian Buck发表了一篇题为“Brook for GPUs: Stream Computing on Graphics Hardware”的论文,为GPU设计了一套支持流编程(Stream Programming)语言的编译器和运行时系统Brook,从而能让开发者像在通用CPU上那样进行编程。
这项工作旋即得到英伟达的青睐,于是2004年Buck博士毕业后便立刻加入英伟达,带领两位工程师创立了CUDA项目。
为了让GPU可编程、支撑CUDA,英伟达必须大幅增加晶体管,导致显卡生产成本暴涨约50%;但售价无法同步提升,毛利率从近60%暴跌至30%–35%,利润被严重挤压。
黄仁勋在公司年营收仅30亿美元时,坚持每年投入5亿美元迭代CUDA,持续近十年。巨额投入叠加金融危机与产品召回,英伟达在2009–2010财年连续亏损,股价暴跌超80%,市值最低仅约15亿美元,一度濒临破产。
最早的并行计算项目是斯坦福大学的BrookGPU:
http://graphics.stanford.edu/projects/brookgpu/
科学家们很早就意识到GPU进行通用数值计算的可行性。然而GPU从创建之初,就主要针对图形渲染,早期的通用计算需要通过很复杂的处理,才能安排到GPU的pipeline中进行运算。BrookGPU的作用就是给通用数值计算提供一个相对简单的接口。
随着GPU厂商逐渐意识到通用数值计算的重要性,并陆续提出了一些新框架。BrookGPU项目也就过时了。
NV的路线是:Brook -> CUDA
AMD的路线是:Brook -> Brook+(后更名Stream/APP) -> OpenCL/DirectML -> ROCm(同时有OpenCL和DirectML支持)。
常见并行计算框架
| 名称 | 优点 | 缺点 |
|---|---|---|
| CUDA | 生态系统良好,发展成熟。 | 只能NV的卡。 |
| OpenCL | 跨平台,很容易异构计算。 | 大家都把它当作干儿子,没人认真写它的驱动。 |
| C++ AMP | 基于Direct compute,易于使用。 | Windows Only。 |
| OpenMP | 移植改动少 | CPU多线程而已,和GPU无关。 |
| Metal | for iOS | - |
其他的并行计算框架还有:OpenACC、AMD stream、PGI。
OpenMP
Hello World示例:
#include <omp.h>
#include <stdio.h>
#define NT 4
#define thrd_no omp_get_thread_num
int main(){
#pragma omp parallel num_threads(NT)
{
int no = thrd_no();
if (no%2) { printf("thrd no %d is Odd \n",no);}
else { printf("thrd no %d is Even\n",no);}
#pragma omp for
for(int i=0; i<NT; i++) printf("thrd no %d\n",thrd_no());
}
}
OpenMP使用directive的方式表示并行,后来又推出的属性表示法。
很多编译器都原生支持OpenMP,比如gcc使用-fopenmp编译。
https://github.com/lapesd/libgomp
一个OpenMp的扩展库
https://www.cnblogs.com/lfri/p/10111315.html
OpenMP入门教程
教程
https://hpc.llnl.gov/documentation/tutorials/introduction-parallel-computing-tutorial
Introduction to Parallel Computing Tutorial
https://www.cnblogs.com/Carrawayang/p/14691607.html
上文的中文版
http://15418.courses.cs.cmu.edu/spring2013/
15-418/15-618: Parallel Computer Architecture and Programming
论文
《Demystifying Parallel and Distributed Deep Learning: An In-Depth Concurrency Analysis》
《A Survey of Large-Scale Deep Learning Serving System Optimization: Challenges and Opportunities》
《Efficient Training of Large Language Models on Distributed Infrastructures: A Survey》
blog
https://zhuanlan.zhihu.com/c_1174996853811335168
一个多核&并行的专栏
https://deeplearningsystems.ai
Deep Learning Systems: Algorithms, Compilers, and Processors for Large-Scale Production
https://chenzomi12.github.io/
AI系统 & 深度学习系统
https://openmlsys.github.io
机器学习系统:设计和实现
并发和并行
并发(concurrency)是指能处理多个同时性活动的能力,并发事件之间不一定要同一时刻发生。
并行(parallelism)是指同时发生的两个并发事件。并行编程必须是并发的,而并发编程不一定并行,也可以串行。
来个比喻:并发和并行的区别就是一个人同时吃三个馒头和三个人同时吃三个馒头。
Erlang之父Joe Armstrong曾经以人们使用咖啡机的场景为例描述了这两个术语。
并发:如果多个队列可以交替使用某台咖啡机,则这一行为就是并发的。
并行:如果存在多台咖啡机可以被多个队列交替使用,则就是并行。
参考:
https://mp.weixin.qq.com/s/23QCWf0NOoXlwRGAHfx4oQ
还在疑惑并发和并行?
https://mp.weixin.qq.com/s/-kizIk3ZXqu7UNqAb3QlQw
C++并发编程(C++11到C++17)

您的打赏,是对我的鼓励
