Chip » DPU, AMD, 芯片杂烩, 超算
2022-10-26 :: 4633 WordsDPU
如同GPU是针对图像显示领域的加速,DPU(Data Processing Unit)则是对于数据传输方面的加速。
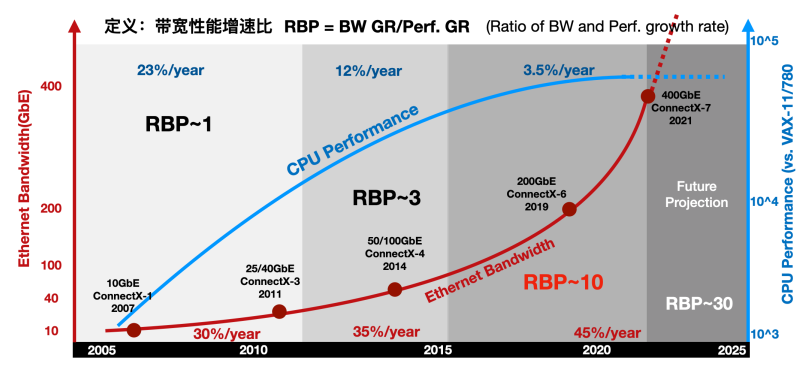
https://zhuanlan.zhihu.com/p/145142691
什么是DPU?
https://mp.weixin.qq.com/s/bL1PoUjZ_sH2VKcBxI6N5A
Wave公司发布数据流处理架构DPU
https://zhuanlan.zhihu.com/p/409507738
写一下DPU
https://www.zhihu.com/question/471238373
dpu芯片发展前景如何?
https://mp.weixin.qq.com/s/xRvXCpHpDnMqSNjJyIf3XQ
大话DPU
https://mp.weixin.qq.com/s/hN8tZ7xCRttIc-3pXdqElQ
中科院计算所牵头发布《专⽤数据处理器DPU技术白皮书》,94页pdf
https://zhuanlan.zhihu.com/p/430203049
在IPU/DPU/SmartNIC中P4能成为主流吗?
AMD
CPU
Bulldozer (推土机) -> Piledriver (打桩机) -> Streamroller (压路机) -> Excavator (挖土机) -> Zen -> Zen+ -> Zen 2 -> Zen 3
这些架构均采用农用设备命名,所以自然AMD被称为“农企”(Agriculture Machine Devices)。
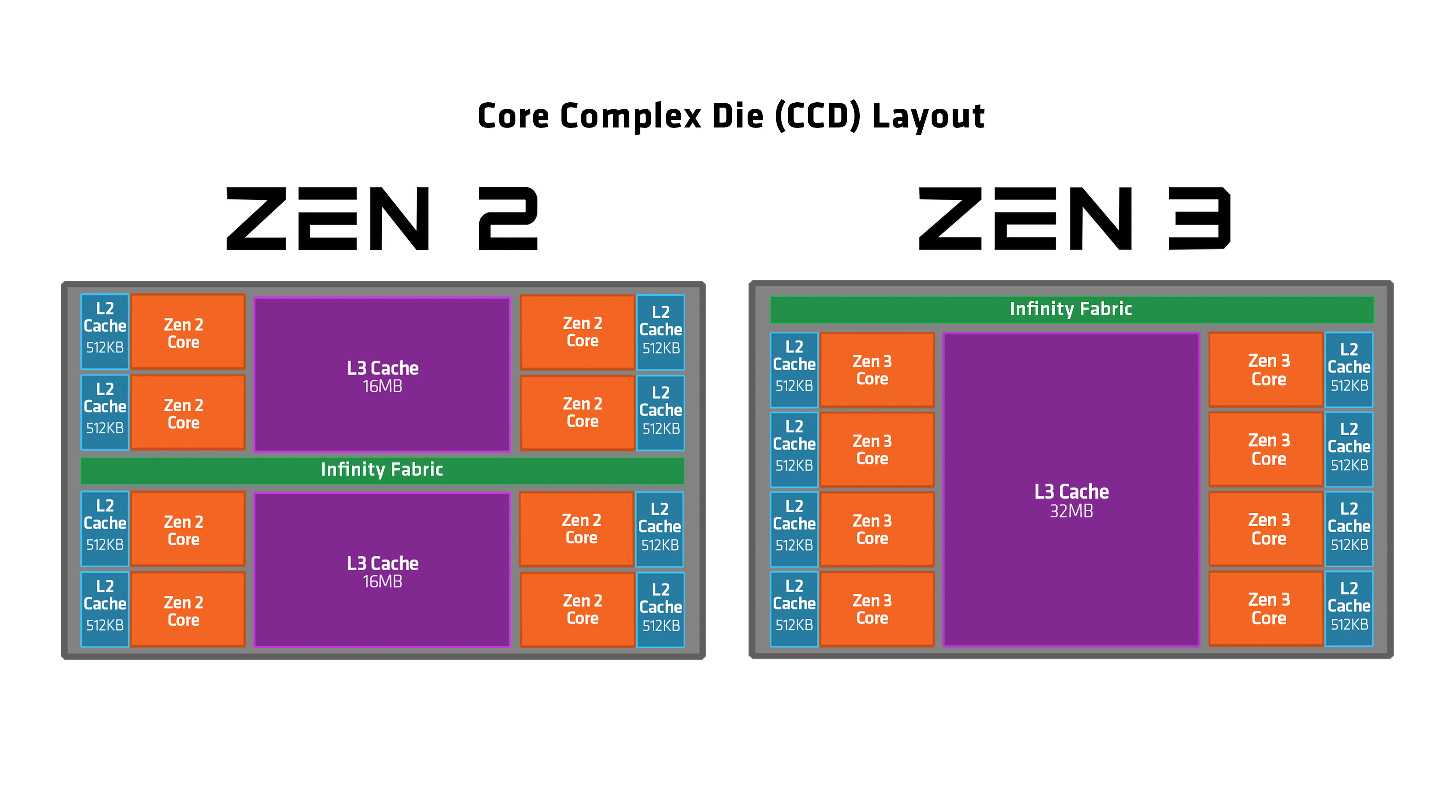
在Zen 2架构中,处理器不再是一个单一的大核心,而是被分为了CCD核心和I/O核心两个部分。
CCD核心和I/O核心之间通过Infinity Fabric总线连接。
3D V-Cache技术,通过在CCD上堆叠额外的缓存,显著提升了处理器的性能。
Matrix Core
对标英伟达Tensor Core,AMD推出Matrix Core。
高速互联
对标NVLink,AMD推出了:
GMI:Global Memory Interconnect
AMD Infinity Fabric Link
其实Intel也有一个叫做Xelink的东西。
IBM BlueLink
HIP
HIP:Heterogeneous Interface for Portability。
HIP是AMD提出的C++接口,号称能兼容CUDA和自家的ROCm。
https://zhuanlan.zhihu.com/p/545296023
写给CUDA开发者AMD ROCm & Intel oneAPI开发贴士
Linux KFD(Kernel Fusion Driver)是AMD为其GPU计算平台开发的一个内核驱动程序,主要用于支持ROCm(Radeon Open Compute)生态系统。
https://zhuanlan.zhihu.com/p/2018493367651148453
600行Rust击败AMD官方GEMM库 — 裸金属GPU编程实战
Composable Kernel
Composable Kernel(CK)库旨在提供一套在AMD GPU上算子融合的后端方案。
https://www.sohu.com/a/603796560_129720
AMD Composable Kernel: 定制化算子融合,大幅提升AI端到端性能
AITemplate
AITemplate首先在Python层寻找最优的kernel配置,生成Jinja2 template,再生成C++ template:
-
NVIDIA GPU:基于CUTLASS的GPU Tensor Core C++ template;
-
AMD GPU:基于CK(Composable Kernel)的Matrix Core C++ Template。
官网:
https://github.com/facebookincubator/AITemplate
参考:
https://www.zhihu.com/question/557608132
如何看待Meta发布的全新推理引擎AITemplate?
AI服务器
AMD Instinct系列,大致对标NVIDIA DGX。
官网:
https://www.amd.com/zh-hans/graphics/instinct-server-accelerators
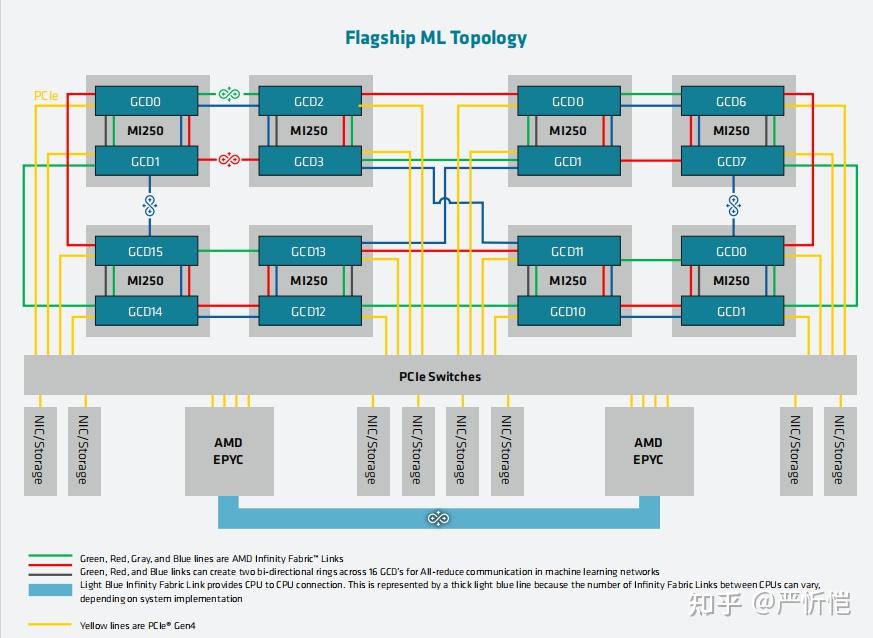
https://zhuanlan.zhihu.com/p/434686566
AMD CDNA2架构(MI200)
https://www.zhihu.com/question/606505567
如何看待AMD发布Instinct MI300X GPU芯片?是否在大模型时代威胁Nvidia地位?
参考
以前的算法比较简单,数据吞吐量小,AMD的短流水线渲染单元数量多所以效率高。到了Ethash这类重IO算法主流的年代,其实A卡效率还略有优势,但是没以前那么夸张,所以N卡也被拉出来挖。
A卡的新驱动对于老游戏的支持有些差,解决办法:删除游戏目录下的dbghelp.dll文件。
https://www.zhihu.com/question/593343983
截至2023年4月,用AMD显卡做机器学习怎么样?
https://zhuanlan.zhihu.com/p/651797296
通过“最差实践”实验探索AMD GPU调度细节
Intel
Performance Core
Efficient Core
AMD的思路与Intel有所不同,Zen4和Zen4c使用同一微架构,仅L3 Cache的大小有差异。前者追求单核极限性能,后者追求多核密度与能效。
https://zhuanlan.zhihu.com/p/1941097136155494318
Intel Core核心发展简史-1:疯魔Pentium 4带来的灾难与Pentium 3的传承
https://zhuanlan.zhihu.com/p/1943346856122901845
Intel Core核心发展简史-2:酷睿问世,谁与匹敌?
https://zhuanlan.zhihu.com/p/1944345283581411627
Intel Core核心发展简史-3:AMD 农企时期,Intel真的在挤牙膏吗?
芯片杂烩
我接触到的芯片分门别类罗列如下:
| 类别 | 名称 | 厂家 |
|---|---|---|
| Low MCU(追求低价) | LPC4088 | NXP |
| Hi MCU(追求性能) | ASAP1826T | alphascale |
| MDM9215M | Qualcomm | |
| Wifi Low Power SOC | QCA4002 | Qualcomm Atheros |
| RTL8711AF | Realtek | |
| ESP8266 | Espressif(乐鑫) | |
| BLE SOC | QN9021 | NXP |
| Wifi SOC | RTL8881AB | Realtek |
| MT7620A | MTK | |
| Nand Flash | MT29F4G08ABBEAH4 | Micron Technology |
| HY27UF081G2A | Hynix | |
| Wifi Audio | RTL8871AM | Realtek |
| RT5350F | Ralink | |
| AR9331 | Qualcomm Atheros | |
| ATV3603 | 炬力 | |
| Audio Codec | WM8728 | Wolfson |
| TAS5731M | Texas Instruments | |
| MAX5556 | MAXIM |
超算
Seymour Cray,1925~1996。1957年,克雷和其它几位ERA的同事辞职后,创办了CDC(Control Data Corporation)。1972年,克雷自立门户,创立了克雷研究公司。
https://blog.csdn.net/programmer_editor/article/details/1305826
西摩•克雷(Seymour Cray)――隐居丛林的超级计算机之父
Massively Parallel Processor
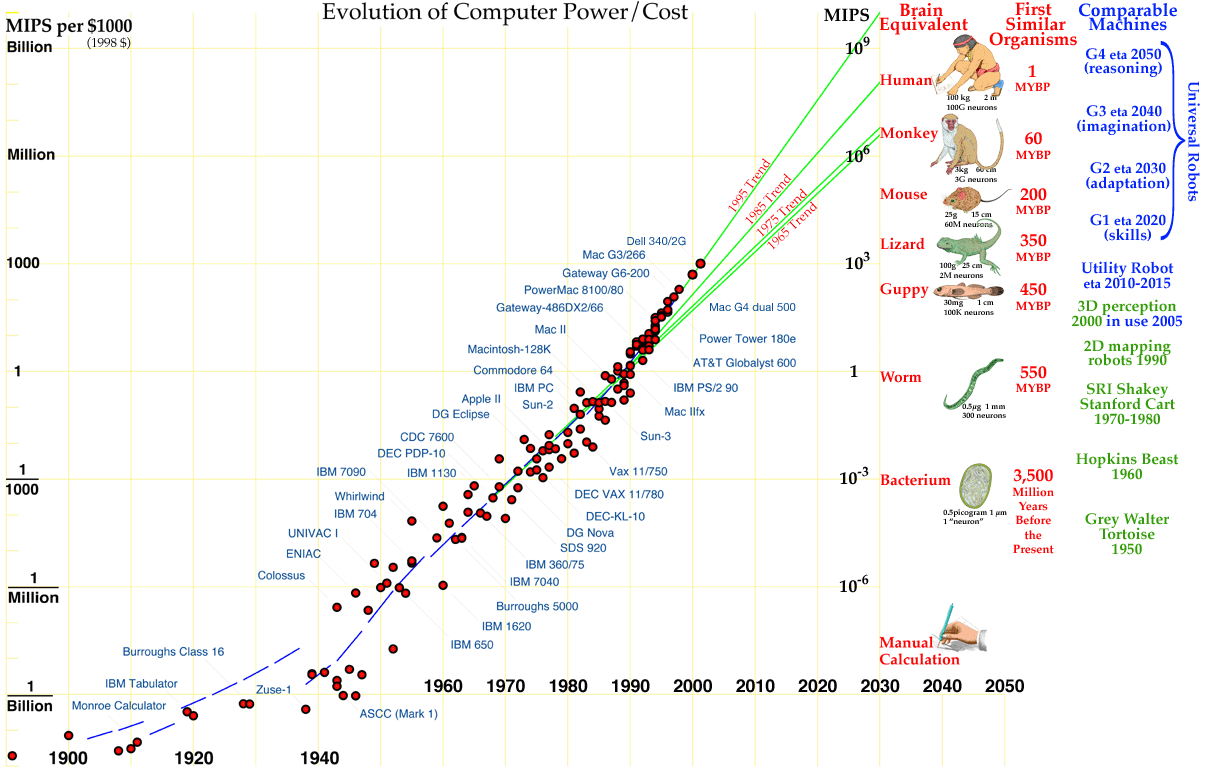
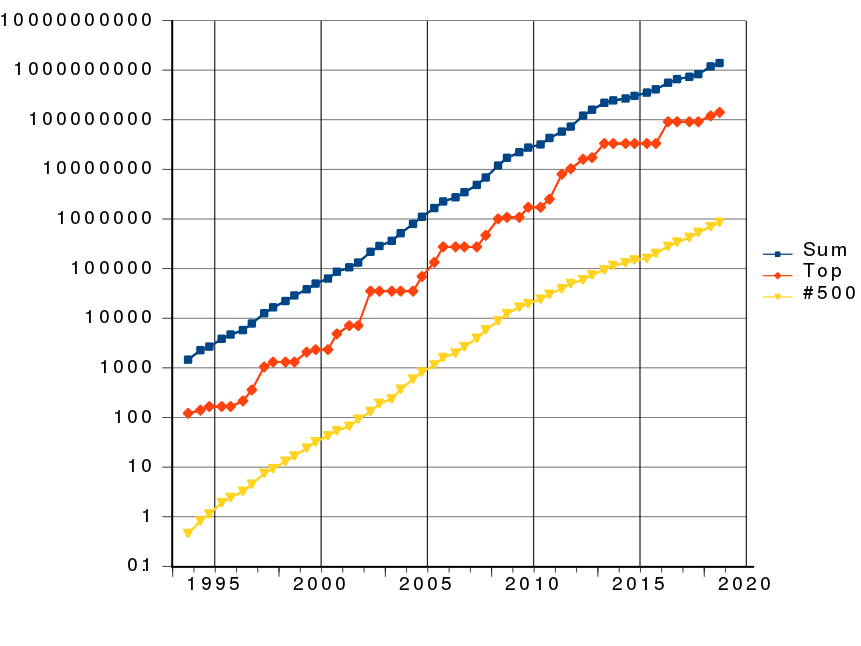
Top 500超算之间的差距竟有3个数量级,从榜首到落榜差不多要10年时间。OS从2015年开始全都是Linux了。Windows在超算领域从来没有风光过,之前没钱,自然斗不过UNIX,后来又被Linux打趴下了。
Sunway TaihuLight和Sierra的算力相当,但core的数量竟是后者的6.7倍,功耗是后者的2.06倍。差距明显啊!
- 相对浮点计算能力,内存带宽太低,严重的访存受限。
- 网络带宽也不够,特别是考虑的通信和计算重叠的情况,这时候由于1,问题更严重。
- 节点数实在太多了。(4万节点也太多了)可扩展性由于1,2,不好做。
https://www.top500.org/
超算排名网站
https://zhuanlan.zhihu.com/p/33956771
超算排名之中的地区和架构之争
https://www.zhihu.com/question/47843945
神威太湖之光的缺点有哪些?

https://mp.weixin.qq.com/s/gJWTiMCovGMQ8ye_TovdOw
富士通的这颗芯片凭啥让日本走向了世界之巅?
https://www.zhihu.com/question/404217836
如何看待全球超级计算机TOP 500榜单日本登顶,中国跌出前三?近年中国超算发展现状如何?
传统的排名是基于涉及64位浮点计算的基准,除此之外还有其他基准。
2021年7月,由国防科技大学研制,部署在国家超级计算天津中心的“天河”E级计算机关键技术验证系统在国际Graph500排名中,获得SSSP Graph500(单源最短路径)榜单世界第一和BIG Data Green Graph500(大数据图计算能效)榜单世界第一的成绩。
https://www.zhihu.com/question/280357538
如何看待美国造出超过神威太湖之光的“顶点”的超级计算机?
https://www.zhihu.com/answer/2512513124
如何看待美国新的超级计算机Frontier成为超算榜全球第一,超过2–8名计算能力之和?
https://www.zhihu.com/question/2032659692376343993
如何评价中国超算”灵晟”登顶Top500,中国超算重回世界第一?

您的打赏,是对我的鼓励
