Chip » 内存, NAND
2024-07-17 :: 6158 Words内存
2008年,金融危机爆发,DRAM价格再次雪崩,从2.25美元狂跌至0.31美元。
众厂商哀鸿遍野时,已经羽翼丰满的三星,又一次祭出了逆周期投资的看家法宝,将三星电子上一年的总利润的118%,全部用于扩大产能,故意扩大行业的亏损!
2009年,行业排名第三的德国巨头奇梦达资金链断裂,欧洲仅存的内存厂商就此成为历史。
2012年,在日本人苦苦挣扎数年后,尔必达支撑不住,宣布破产。
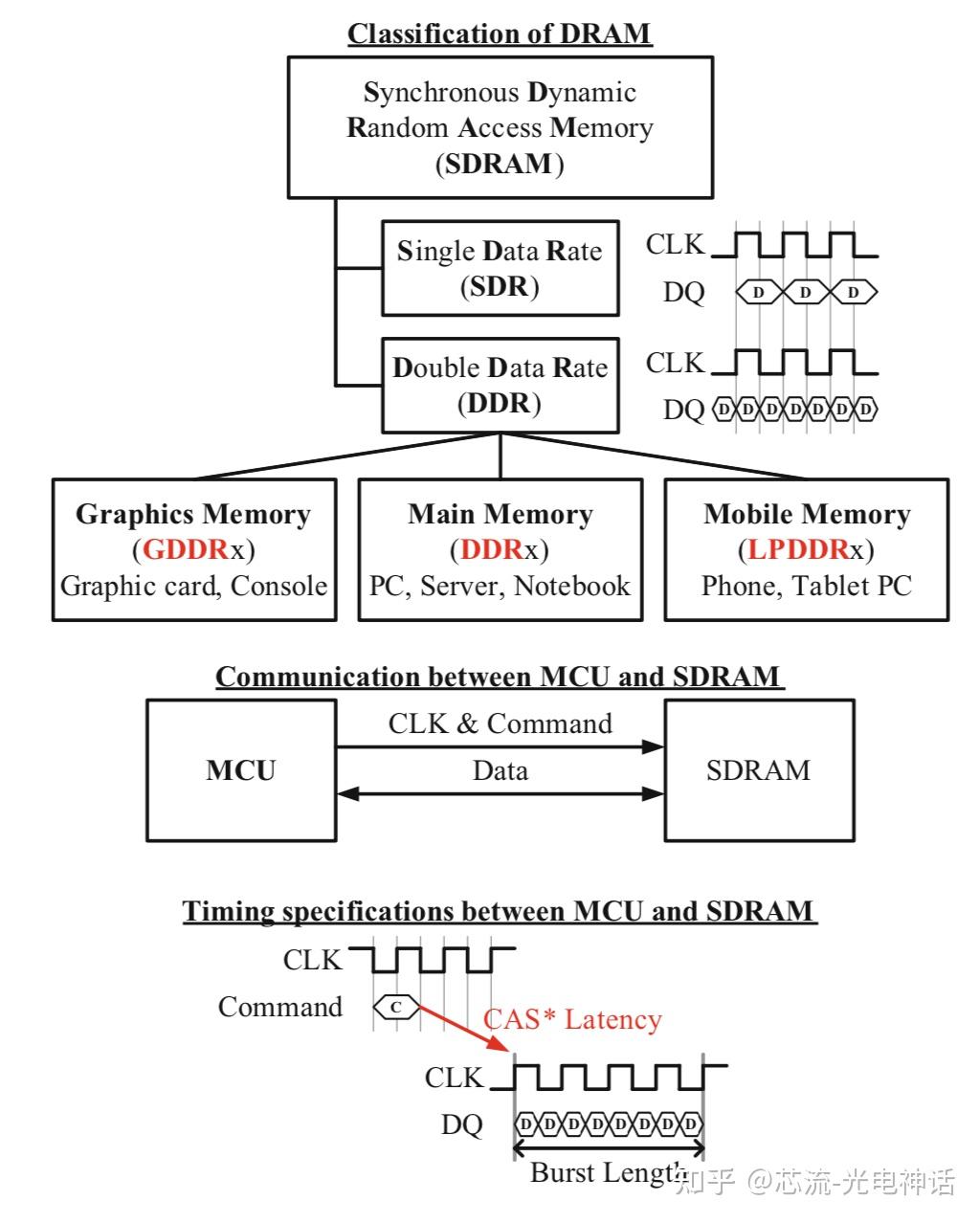
带宽翻倍原理很简单,DDR内部一次操作预测n倍数据,连续读写是完全能命中的,而随机读写的n-1部分是完全命中不了的。
DRAM颗粒核心频率不变,仅仅提升I/O口频率,这也导致了从DDR1到DDR6内存随机访问延迟没什么变化。
https://www.zhihu.com/question/649546709
内存的起源是哪里?DDR1到DDR6的区别分别是什么?
https://www.zhihu.com/question/9218009141
DDR5内存是如何做到速度相比DDR4实现“质的飞跃”的?
“4F2”在DRAM Cell Structure中指的是一种存储单元的面积,其中”F”代表晶体管的特征尺寸(Feature size)。在DRAM技术发展中,4F2意味着存储单元的尺寸是特征尺寸的四倍平方。
与传统的8F2和6F2单元相比,4F2 DRAM cell可以分别提高约60%和30%的产量。
DIMM:Dual In-Line Memory Module
RDIMM:Register DIMM
LRDIMM:Load Reduced DIMM
https://zhuanlan.zhihu.com/p/91835185
什么是RDIMM和LRDIMM?
CAS Latency描述了内存控制器发出读取命令(CAS 命令)到内存开始发送数据之间的延迟。在内存规格中,CAS延迟通常与内存的频率一起列出,如”2666MHz CL17”中的”CL17”表示CAS延迟为 17个时钟周期。
https://mp.weixin.qq.com/s/HOhBNZfOf5xQIFLYQ5ntCw
内存的故事
https://mp.weixin.qq.com/s/qhR0St3CLWEYqV_kl_oXAw
Rambus之战
https://mp.weixin.qq.com/s/gh9cL0BPzCQ2JFOoXdtqyg
内存的技术发展
https://mp.weixin.qq.com/s/kHPTZlDtjqtr0Vi-5OWycQ
金士顿的传说
https://zhuanlan.zhihu.com/p/57780996
内存延迟:因与果
https://mp.weixin.qq.com/s/XcC18tulYdnwqlusg2QrxA
嵌入式内存STT-MRAM趋势分析
https://zhuanlan.zhihu.com/p/62234511
DDR3 vs DDR4?为什么说内存是个很傻的设备?DDR5在哪里?
https://zhuanlan.zhihu.com/p/40601422
双通道、四通道内存对游戏重要吗?
https://mp.weixin.qq.com/s/9skWM6yirEupLj2wdpgqkA
带你深入理解内存对齐最底层原理
https://mp.weixin.qq.com/s/Mb7iSXfrOtettVn-Sz8QUA
主板上这家伙,要当CPU和内存的中间商!
https://blog.csdn.net/shiwq1127/article/details/127975179
memory interleaving(内存交织)
https://zhuanlan.zhihu.com/p/675766394
DDR5内存的“组织架构”
https://zhuanlan.zhihu.com/p/675768122
DDR5内存全家照
NAND
NOR Flash & NAND Flash
Flash按照内部存储结构不同,分为两种:NOR Flash和NAND Flash。
NOR Flash使用方便,易于连接,可以在芯片上直接运行代码(eXecute In Place),稳定性出色,传输速率高,在小容量时有很高的性价比,这使其很适合应于嵌入式系统中作为FLASH ROM。
在通信方式上NOR Flash分为两种类型:CFI Flash和SPI Flash。
NAND Flash强调更高的性能,更低的成本,更小的体积,更长的使用寿命。这使NAND Flash很擅于存储纯资料或数据等,在嵌入式系统中用来支持文件系统。NAND Flash存在坏块问题。
桀冈富士雄(Fujio Masuoka)1980年发明了NOR Flash,1986年又发明了NAND Flash。
三星最早提出Norless的概念,在它的CPU on die ROM中固话了NAND Flash的驱动,会把NAND flash的开始一小段拷贝到内存低端作为bootloader,这样昂贵的NOR Flash就被节省下来了,降低了手机主板成本和复杂度。渐渐NOR Flash在手机中慢慢消失了。
参考:
https://mp.weixin.qq.com/s/Coz81Zidz_LaSYkcErJsOQ
NAND Flash与NOR Flash究竟有何不同
https://zhuanlan.zhihu.com/p/26745577
NOR和NAND Flash
SSD
SLC(1Bits/cell) < MLC(2Bits/cell) < TLC(3Bits/cell) < QLC(4Bits/cell) < PLC(5Bits/cell) < HLC(7Bits/cell)
https://zhuanlan.zhihu.com/p/53547723
一篇文章告诉你SLC、MLC、TLC和QLC究竟有啥区别?
https://zhuanlan.zhihu.com/p/92712620
SLC、MLC、TLC、QLC究竟有什么不同
随着硬件设备存储介质的改变和性能不断的提升,存储设备处理IO的能力越来越快,传统的旋转设备HDD单个IO需要几毫秒到十几毫秒不等,而如今的高性能的NVMe SSD已经降低到了微秒级别。
因此也有了一些专门针对SSD硬盘的存储软件框架。
https://mp.weixin.qq.com/s/d8aoAFi_lpFoZZCZsPij_g
SPDK概览
黑片(Black Die/Wafer)是指在生产过程中发现了某些缺陷的NAND闪存芯片,这些缺陷可能影响其性能、耐用性或可靠性。

内存芯片 → Bankgroups → Banks
- 同一Bankgroup内的Bank共享某些资源。
- 不同Bankgroup之间的操作可以更高程度地并行。
- 访问不同Bankgroup的延迟小于访问同一Bankgroup内不同Bank的延迟。
https://zhuanlan.zhihu.com/p/34858149
128G的固态硬盘为什么有的标120G,有的标100G?固态硬盘容量背后的秘密
https://zhuanlan.zhihu.com/p/71267390
固态硬盘和u盘的区别
https://www.zhihu.com/question/401733153
长江存储的Xtacking技术与英特尔的3D Xpoint技术、SK的4DNAND技术有什么异同点?
当年跳水价时候一群人说是因为国产颗粒研发成功所以白菜价了,现在两年过去了,是因为国产颗粒研发技术跨时空倒退了吗?
降价时感恩长鑫长存,涨价时责任全在美光。
C/C++参考资源=
std::tuple
auto tuple = std::make_tuple(1, 'A', "test");
std::cout << std::get<0>(tuple) << std::endl;
std::cout << std::get<1>(tuple) << std::endl;
std::cout << std::get<2>(tuple) << std::endl;
std::tie
可用tuple或pair返回多个返回值,然后用tie进行解包。这里的语法非常类似python。
std::pair<int, std::string> fun_tie(int a, std::string str)
{
return std::make_pair(a, str);
}
int a;
std::string str;
std::tie(a , str) = fun_tie(12, std::string("Pony Ma"));
std::cout << a << "," << str << std::endl;
inl文件
inl文件是内联函数的源文件。内联函数通常在C++头文件中实现,但是当C++头文件中内联函数过多的情况下,我们想使头文件看起来简洁点,能不能像普通函数那样将内联函数声明和函数定义放在头文件和实现文件中呢?
当然答案是肯定的,具体做法将是:将内联函数的具体实现放在inl文件中,然后在该头文件末尾使用#include引入该inl文件。
参考:
https://www.cnblogs.com/findumars/p/4340936.html
C++中的INL
常用libc实现
libc是C语言标准库的简称,它有多种实现。除了最常用的gcc自带的glibc之外,还有musl、uClibc、dietlibc等。
http://www.etalabs.net/compare_libcs.html
这个网址是以上4种libc实现的比较结果。从结果来看,musl比较有投资价值。实际上,最近(2015.5)的OpenWrt项目就已经将libc由uClibc改为musl。我也是因为这个原因,才知道musl的。
当然这个表并不完整,其他的libc可以参见:
https://en.wikipedia.org/wiki/C_standard_library
有价值的C/C++库
https://github.com/fffaraz/awesome-cpp
一个专门收集各种C/C++库的网页
https://github.com/gabime/spdlog
一个C++的log库
https://zhuanlan.zhihu.com/p/674073158
超详细!spdlog源码解析
模板元编程
这段代码用来在编译期根据“一堆长度”生成一个N维静态数组类型。
template<typename A, size_t... dims>
struct variadic_array;
// 告诉编译器:后面会有一个模板variadic_array,它接收一个类型A和任意数量的size_t类型的参数。此时没有定义,只做了声明。
template<typename A, size_t first_dim, size_t... rest_dims>
struct variadic_array<A, first_dim, rest_dims...> {
using type = typename variadic_array<A, rest_dims...>::type[first_dim];
};
// 当模板实参列表里至少有一个size_t时,这个版本被选中。它把第一个维度first_dim拿出来,然后递归到剩下的维度rest_dims...。
template<typename A>
struct variadic_array<A> {
using type = A;
};
// 当把所有维度都剥光后,只剩下类型A,递归停止。
template<typename A, size_t... dims>
using variadic_array_t = typename variadic_array<A, dims...>::type;
// 给整个元函数起一个别名,variadic_array_t<float, 3, 4, 5>等价于float[3][4][5]。
...只能出现在模板参数列表或函数参数列表里,声明一般为typename... Ts的形式,而使用则是Ts...。前者也被称为pack,后者则是unpack。
使用sizeof...(Ts)运算符可以得到pack的数量。
C/C++参考资源
vector<bool>并不是一个通常意义上的vector容器,这个源自于历史遗留问题。 早在C++98的时候,就有vector< bool>这个类型了,但是因为当时为了考虑到节省空间的想法,所以vector<bool>里面不是一个Byte一个Byte储存的,它是一个bit一个bit储存的!
https://www.zhihu.com/question/23367698
c++中为什么不提倡使用vector<bool>?
struct Test {
int a;
int b;
char c[0];
};
Zero-length array不占用结构体的空间,但可以由编译器计算offset,例如上例中指向c的指针,实际上指向了整个结构体的尾部(不含结构体本身)。
C++已经有不少解释器:clang-repl,cling等。
https://zhuanlan.zhihu.com/p/23016264
这么多款STL,总有一款适合你
https://mp.weixin.qq.com/s/Hpn7KqYlBKz0JdryiozqyQ
每个开发者都应该了解的一些C++特性
https://www.cnblogs.com/wuchanming/p/3913492.html
emplace_back与push_back的区别
https://zhuanlan.zhihu.com/p/82895086
当我们谈论C++时,我们在谈论什么?
https://mp.weixin.qq.com/s/pxyTlQn4wx-N_MaWZc0oAQ
漫谈C++的各种检查
https://mp.weixin.qq.com/s/LchYGGcSbIMVGxO0Uea0RA
深入C++回调

您的打赏,是对我的鼓励
