Chip » AI Chip(三)——群雄(1)
2022-09-25 :: 5179 WordsAI Chip
DEEPHi(续)
目前的AI Chip战争,入局的玩家基本都解决了芯片有无的问题。体系结构的红利也吃的差不多了,在未来几年不大可能再保持目前的算力增速。因此,未来争夺的焦点将转向软件方面。实际上,今年以来,已经有客户拿友商产品性能来压我们。然而也就是压一下而已,让他弃用他肯定不干。原因无他,我司80%的功能都已经自动化,没人会和好用过不去。
2021.11
最近国内比较火的AI芯片初创公司已经换成了:
- 壁仞科技
- 摩尔线程
- 沐曦集成
- 燧原科技
- 瀚博半导体
- 登临科技
- 天数智芯
某牛点评:
做一个ASIC其实目前真没有什么大的门槛,不然你以为上海那么多家的ASIC公司是怎么来的,随便拉几个人都敢成立ASIC公司,还不是门槛不高,你让他就那几个人搞个CPU和GPU试试。但是要做一个好的ASIC,适配模型和场景丰富的ASIC,是非常不容易的。而且一旦模型场景丰富,你就不仅仅是在硬件领域所谓的PPA各种挣扎,你还需要在指令级别,或者说通用和性能做妥协,甚至架构上的一些妥协改变。
在回马枪看,npu厂商换三代,能玩出代代不兼容。。。
国内海量的npu,随便能跑矩阵的屎,都能跑llm推理,但是一个个都做不明白,也不能和别人形成共识,业界前沿也难跟上,但不妨碍这一票npu厂商,ppt上随手灭老黄。
npu的当年的愿景很简单,就是算法和模型会固化会成熟,老黄的愿景是算法和ai会继续狂奔,所以当年npu从愿景上就输了。
https://zhuanlan.zhihu.com/p/1933155604605698054
国产芯片的三年
2024.9
象帝先由于资金链断裂,停止运营。
格灵深瞳2013年立项时直接切入3D:用PrimeSense深度摄像头发射红外结构光,采集点云→重建三维坐标→做行为轨迹分析,希望一次解决“人是谁+人在干什么”。
旷视、商汤同期把全部资源压在2D CNN:靠大规模人脸标注数据训练深度网络,先把“人是谁”这一步做到工业可用,再横向扩展。
FuriosaAI
FuriosaAI是韩国的一家AI芯片公司。

地平线

地平线主要做智能驾驶领域的AI芯片,和它类似生态位的还有黑芝麻智能。前者于2024.10上市,而后者是2024.8。
Cerebras
现在,计算芯片是越做越大,在早先的PC中,最大的芯片无疑是CPU了。但现在高端显卡芯片的面积已经超越CPU了。
Cerebras在这方面更为极端,它的芯片采用了一整张300mm晶圆,将40万个内核,1.2万亿个晶体管,46,225平方毫米的硅和18GB的片上存储器,全部集成在一个与整个晶圆一样大的芯片中,大到令人难以置信。
其实Nvidia的芯片也有越来越大的趋势:
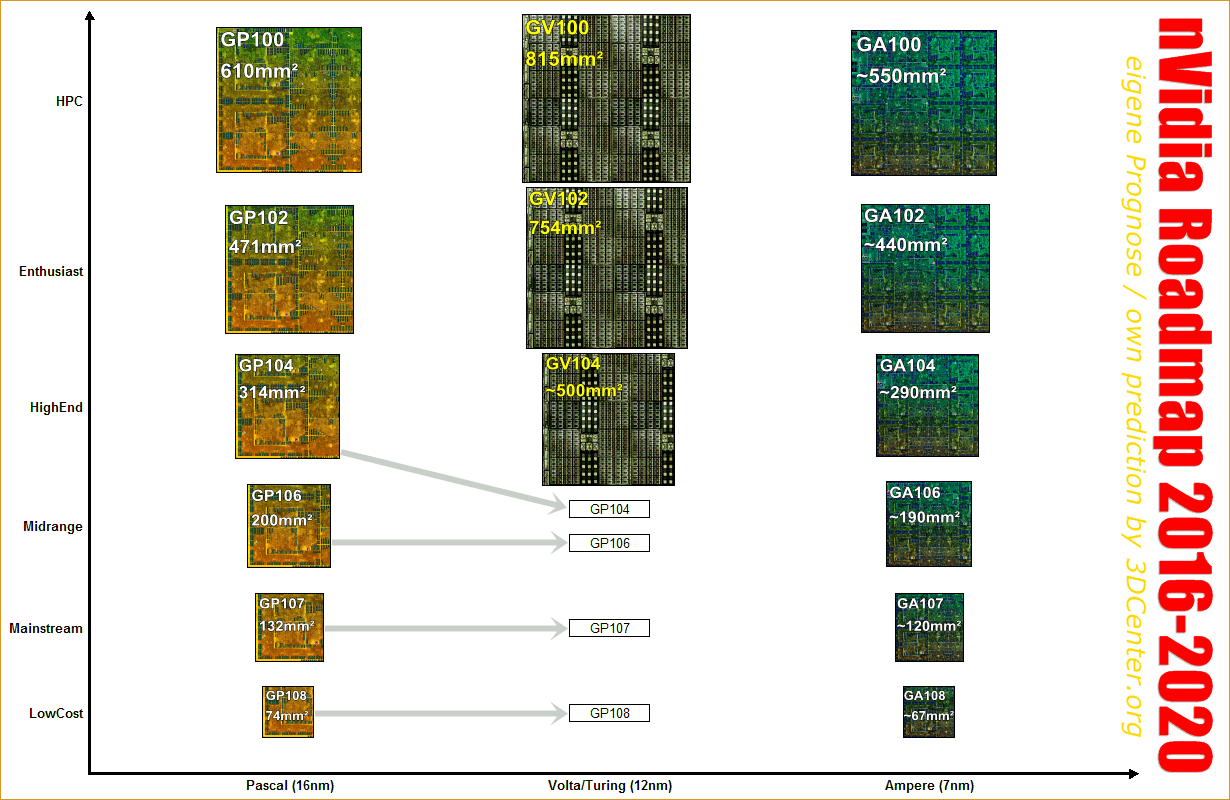
超大芯片主要有两个问题:
-
良品率问题。这个问题可以通过冗余设计来解决。比如Intel的i5、i7实际上都是同一批生产出来的。如果所有核都OK,那就是i7;否则的话,屏蔽不好的核,这就是i5,因此i5常有6核这样的奇怪数字出现。
-
散热问题。
参考:
https://mp.weixin.qq.com/s/Zsmvsy8I_qKZWrONj9Juuw
史上最大芯片正式推出世界最快AI计算机:1/30体积、1/5功耗、3倍性能!谷歌TPU V3在它面前就是“渣”
https://mp.weixin.qq.com/s/nGzDVR9dlF-jL4ZIkss0Ow
这家用一整块硅片做AI芯片的公司成功了?
Habana
Habana Labs是一家位于以色列特拉维夫和加州圣何塞的无晶圆厂半导体公司,创立于2016年。
Habana的产品线主要有:
-
用于Train的Gaudi系列芯片。
-
用于Inference的Goya系列芯片。这是一个基于PCI接口的板卡,所以还是数据中心的范畴,暂不能用于终端设备。
据说国内的数据中心相关的企业,对它的产品很感兴趣。
官网:
https://habana.ai
2019.12 Habana被Intel收购。稍后,就传出Intel解散Nervana团队的事情。后者是2016年被Intel收购的一家AI芯片公司。
国外类似的企业还有:
- HAILO
- blaize
参考:
https://mp.weixin.qq.com/s/cnHQSmM89Sp92gke_F9T2Q
一窥Habana的推理和训练神经处理器
https://zhuanlan.zhihu.com/p/84562992
Goya from Habana Labs芯片与软件栈分析
沐曦
沐曦专注在研发全兼容CUDA及ROCm生态的国产GPU计算卡(面向AIDC和HPC的计算需求),创始团队也是AMD背景。
Expedera
官网:
https://www.expedera.com
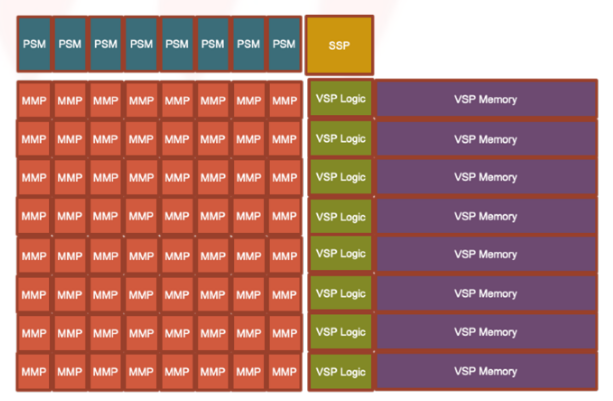
其中的partial summation (PSUM)也是近年来针对大模型的一种常见的优化方法。原理有点类似MapReduce,PSUM相当于Reducer,对数据进行初步的收集,再最终汇总到一起。这样效率上要比全局只有一个单元进行summation要高的多。
参考:
https://www.expedera.com/wp-content/uploads/2023/02/Architectural-Considerations-for-Compute-in-Memory-in-AI-Inference-final.pdf
https://www.expedera.com/wp-content/uploads/2021/04/Expedera-Linley-White-Paper.pdf
Huawei
Huawei的AI芯片项目大约启动于2016年底,算是布局比较晚的了,所以初期它们和寒武纪有不少合作。
官网:
https://ascend.huawei.com/home
Model Zoo:
https://github.com/Ascend/models
重要的开源项目:
https://gitee.com/ascend/tensorflow
https://gitee.com/mindspore/graphengine
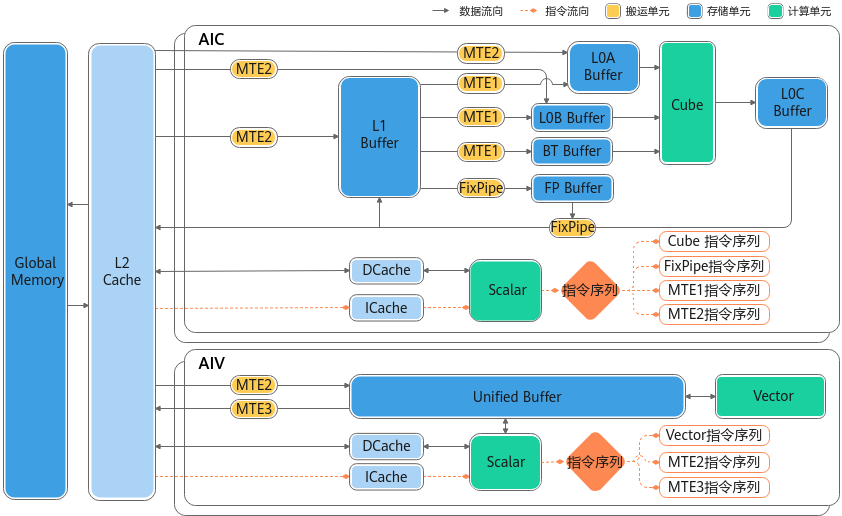
Ascend(昇腾)芯片主要包括端侧的310系列和用于数据中心的910系列。
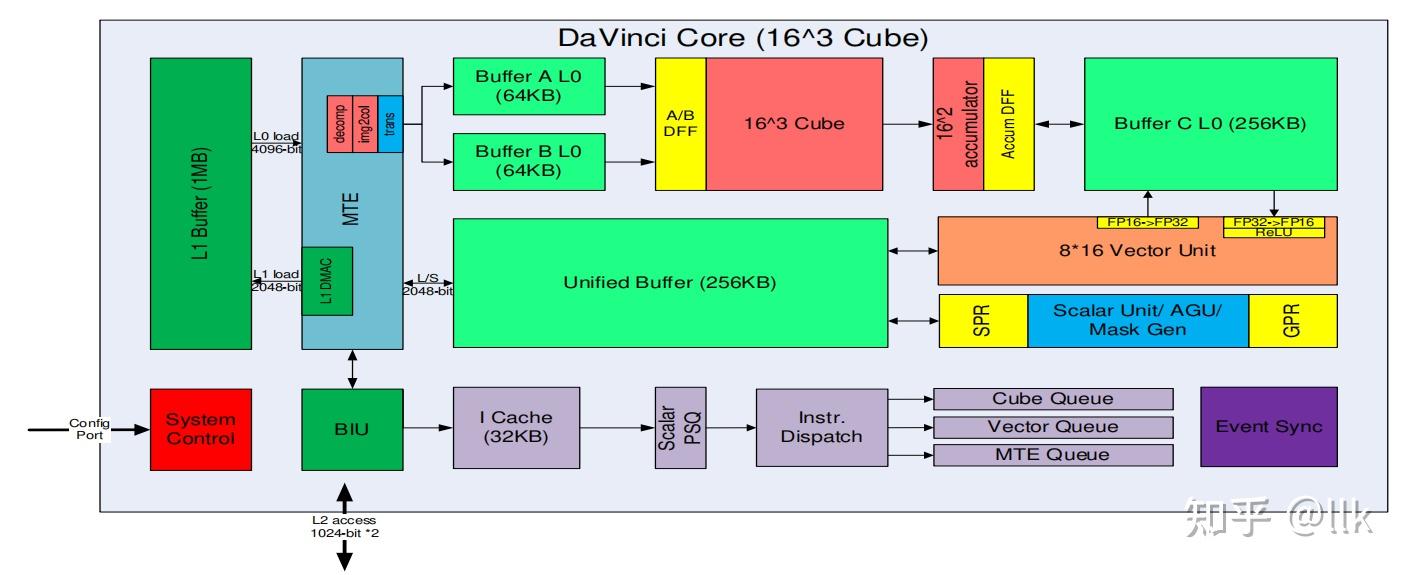
MTE(Memory Transfer Engine)
三种计算单元支持的典型操作:

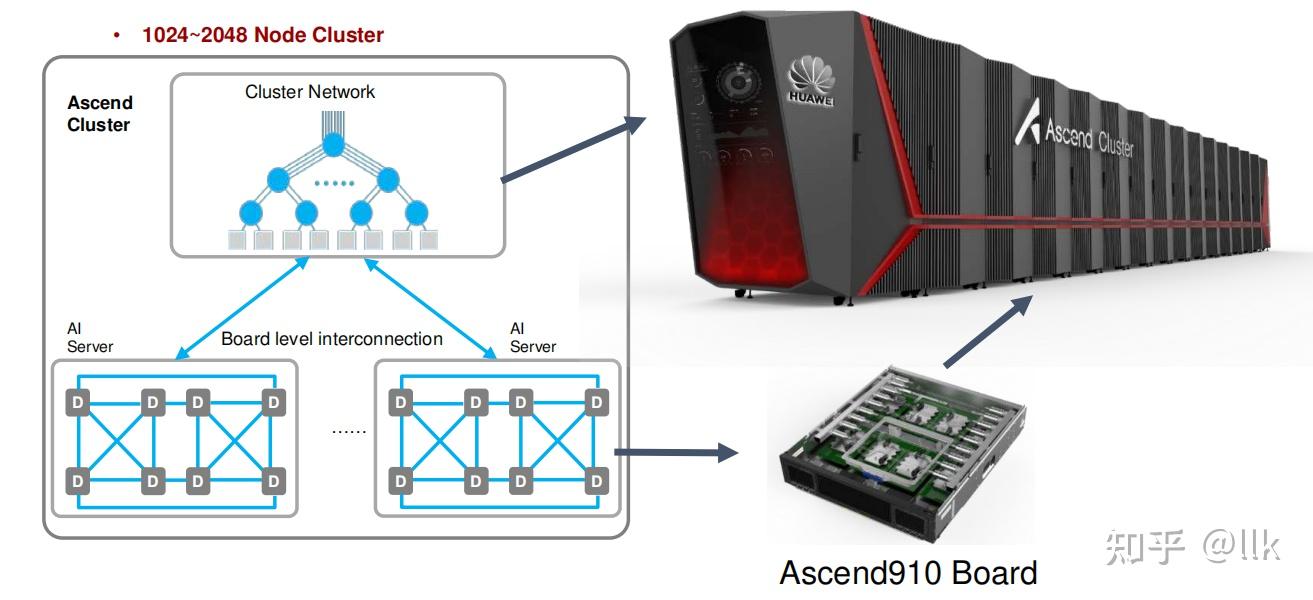
HCCS,即Huawei Cache Coherence System(华为Cache一致性总线)。
英伟达的NVLink可以实现8颗芯片互联,而HCCS目前仅支持4路互联,提供30GB/S带宽。两个组使用PCI-E总线相互通信,提供32GB/S带宽。
这实际上就是NV在DGX1+P100时代,采用过的hybrid cube-mesh结构。
910C架构图:
参考:
https://www.zhihu.com/answer/3459186418
华为昇腾芯片跟英伟达的芯片相比,差在哪里?
参考:
https://www.jiqizhixin.com/articles/2019-08-20-4
华为在hotchips详细介绍了达芬奇架构
https://www.hiascend.com/zh/software/cann
CANN(Compute Architecture for Neural Networks)是华为针对AI场景推出的异构计算架构
https://www.zhihu.com/question/1925252282942988983
华为NPU昇腾芯片是否属于重大战略方向性失误,应该选择GPGPU
https://zhuanlan.zhihu.com/p/2022779284499039419
辩经系列之一:NPU or GPGPU
Imagination
Imagination Technologies公司前身是一家名为Video Logic的公司,VideoLogic成立于1985年,主营业务是图形与音频加速等方面。后来选择了与ARM的类似盈利模式——授权IP核,并在1999年更名为Imagination Technologies。
在移动GPU市场上,Imagination的PowerVR GPU一度占有非常高的市场份额。苹果公司设计的各种供苹果手机使用的AP,比如A8、A9、A10等处理器都搭载了Imagination Technologies公司的PowerVR图像处理技术。
但在2017年4月,苹果宣布将不再使用其技术后,Imagination股价当天暴跌60%。后于2017年9月,被有中资背景的Canyon Bridge收购。
其AI Chip主要是:PowerVR Series2NX NNA和PowerVR Series3NX NNA。
Imagination目前主要的客户是:
-
汽车电子:Renesas
-
手机:MTK、紫光展锐
除此之外,由于Imagination已经全国资化了,因此很多研究所也对它的产品感兴趣。
从方案来看,Imagination采用的是GPU+NPU的模式。
这种模式的特点主要有:
-
NPU专注NN计算,其实主要是CNN/GEMM计算。
-
GPU作为通用计算的兜底,以应付一些不常见的op。GPU支持各种数学计算,单纯从计算的角度是完全可以替代CPU的。GPU的局限主要在于它没有CPU那样的逻辑控制的能力。
-
GPU的主频一般低于CPU,因此如果算法的并行性很差的话,效果并没有CPU好。但这种情况并不多见。
-
最近高通和华为CPU的超大核设计,应该对于提升串行运算性能很有帮助。毕竟CPU核再多,还能有GPU/NPU的核多吗?如果碰到就需要单挑能力的场合该怎么办呢?
综上,GPU+NPU的模式可以将NN运算基本承接过来,这样CPU的负载相对就比较小了。
从商业的角度讲,Imagination的核心产品还是GPU,NPU只是一个添头而已。它的目的应该还是利用NPU,来多卖一些GPU。
摩尔线程的GPU是基于Imagination的IMG BXT-32-1024 MC4。
官网:
https://www.imgtec.com/vision-ai/
参考:
https://mp.weixin.qq.com/s/W7GNhEq-em18V0YjCZ7MBw
被苹果抛弃的芯片供应商,现状如何?
https://zhuanlan.zhihu.com/p/436515863
PowerVR系列GPU架构的演进(一)
https://zhuanlan.zhihu.com/p/491131559
PowerVR系列GPU架构的演进(二)
https://zhuanlan.zhihu.com/p/492651331
PowerVR系列GPU架构的演进(三)
https://zhuanlan.zhihu.com/p/493240867
PowerVR系列GPU架构的演进(四)
2020.1
苹果自己研发受阻,重新延续imagination授权。
https://zhuanlan.zhihu.com/p/103597189
挣扎两年苹果重新向Imagination低头:自研GPU究竟难在何处?
Qualcomm
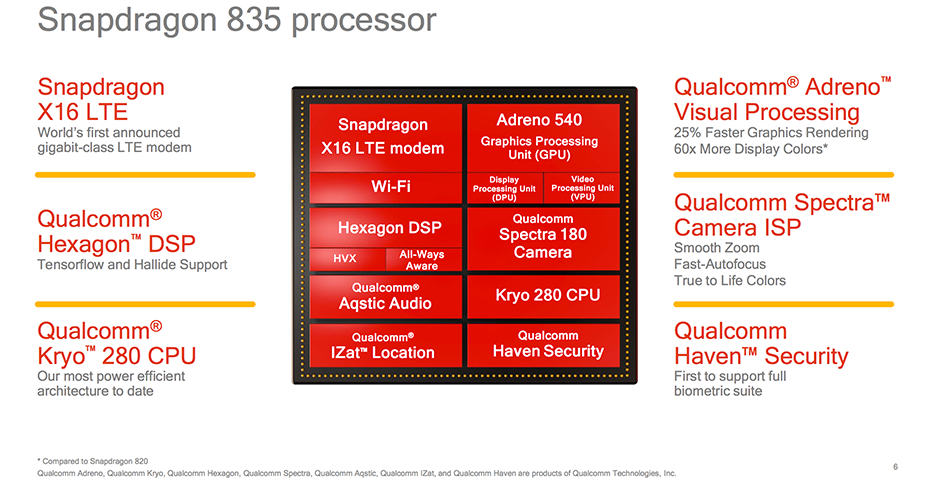
SnapDragon = Kryo CPU + Adreno GPU + Hexagon DSP(include Hexagon Tensor Accelerator, HTA & Hexagon Vector eXtensions, HVX)
参考:
https://zhuanlan.zhihu.com/p/51727365
骁龙855细节曝光:引入张量加速器最亮眼
https://zhuanlan.zhihu.com/p/341328310
聊聊芯片技术趋势
壁仞
https://www.zhihu.com/question/547728200
如何评价壁仞科技发布的最大算力GPGPU BR100?
https://zhuanlan.zhihu.com/p/642431341
壁仞的BR100:来自中国的机器学习GPU
https://zhuanlan.zhihu.com/p/2017278722395366997
重剑无锋:BR100微架构分析

您的打赏,是对我的鼓励
