Chip » 计算机体系结构(二)
2024-05-28 :: 4440 Words计算机体系结构
NUMA
在SMP架构中,又可以分为NUMA架构和UMA架构。
NUMA(non-Uniform Memory Access)非均匀内存访问架构是指多处理器系统中,内存的访问时间是依赖处理器和内存之间相对位置的。在这种设计里面存在和处理器相近的内存,通常称作本地内存;还有和处理器相对远的内存,通常称之为远端内存。
UMA(Uniform Memory Access)均匀内存访问架构则是与NUMA架构相反,所以处理器对共享内存的访问距离和时间是相同的。
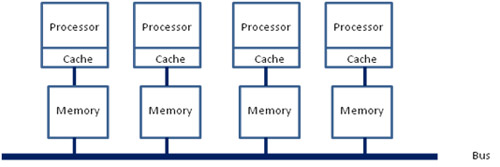
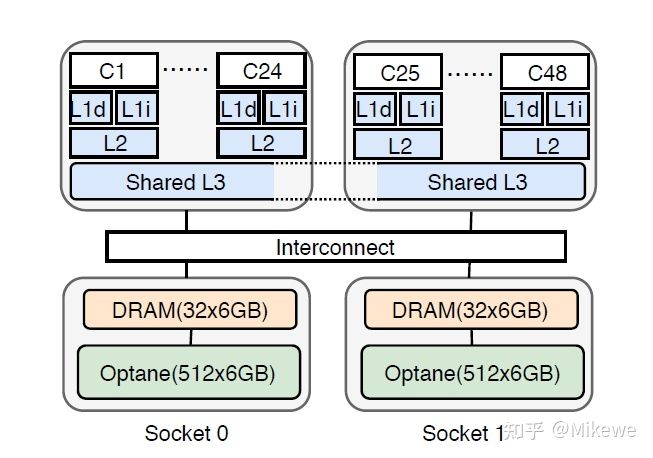
上图是NUMA(Non-Uniform Memory Access)的结构图。可以看到CPU和一部分内存直接相连,而和其他内存通过总线相连。接近NUMA结点的内存称为本地内存,其他NUMA节点的内存称之为远端内存。
如果我们把局部数据放到直连内存上,CPU显然就能够更快速的访问数据。
与NUMA相关的还有一个著名的BUG:
https://zhuanlan.zhihu.com/p/387117470
十年后数据库还是不敢拥抱NUMA?
参考:
https://software.intel.com/en-us/articles/optimizing-applications-for-numa
Optimizing Applications for NUMA
https://mp.weixin.qq.com/s/uH0XRjDNfVQe5r1aes0zDw
性能之殇:从冯·诺依曼瓶颈谈起
https://zhuanlan.zhihu.com/p/476411477
NUMA架构详解
DSM
Distributed Shared Memory是分布式系统的所有节点(处理器)共享的虚拟地址空间。程序访问DSM中的数据的方式与访问传统计算机虚拟内存中的数据的方式非常相似。
分布式共享内存(DSM)在10几年前是OS领域的研究热点,不过因为网络传输的性能太差了,所以凉了。而基于消息传递模型的分布式计算发展了起来。其中数据以消息的形式从处理器传递到处理器。RPC实际上也是相同的模型。
https://blog.csdn.net/JiangTao2333/article/details/124530699
分布式共享内存(DSM - Distributed Shared Memory)
VLIW & superscalar
超长指令字(VLIW:Very long instruction word)和超标量(superscalar)都在同一个CPU中,集成了数套运算单元。
超标量用硬件来决定哪些指令可以并行执行,而VLIW采用软件来决定哪些指令并行,通过把指令调度的复杂度交给编译器来降低硬件复杂度。超标量CPU,有时也称为宽架构CPU。
VLIW的代表是Intel的Itanium处理器。当处理器的执行宽度(execution width),指令执行延迟时间,执行单元个数(function unit)改变时,VLIW需要重新编译程序来适应。但是Superscalar却不需要。
因此,VLIW在GPU中用的比较多。GPU程序并不直接生成GPU指令,而是通过厂商提供的DX/OpenGL库操作GPU。因此这些重新编译程序的任务已经由厂商完成,对于使用者透明。
https://mp.weixin.qq.com/s/OQ3KUAi6HMyOS8k3J_1e6g
关于超长指令集VLIW的一些讨论
https://www.zhihu.com/question/430177243
CPU长指令(VLIW)失败的主要原因是什么,VLIW真的无药可救吗?
VLIW和superscalar的设计差异,实际上是Brainiac和Speed-Demon两种路线之争,前者需要额外使用硬件来处理指令并行,而后者主张用编译器来节省硬件。
然而编译器由于只有编译期的信息,而没有执行期的信息辅助指令生成,设计难度和优化程度远远不如硬件处理,所以VLIW在CPU领域很快就败下阵来,现在流行的CPU,几乎都是superscalar的。
Out-of-Order Execution
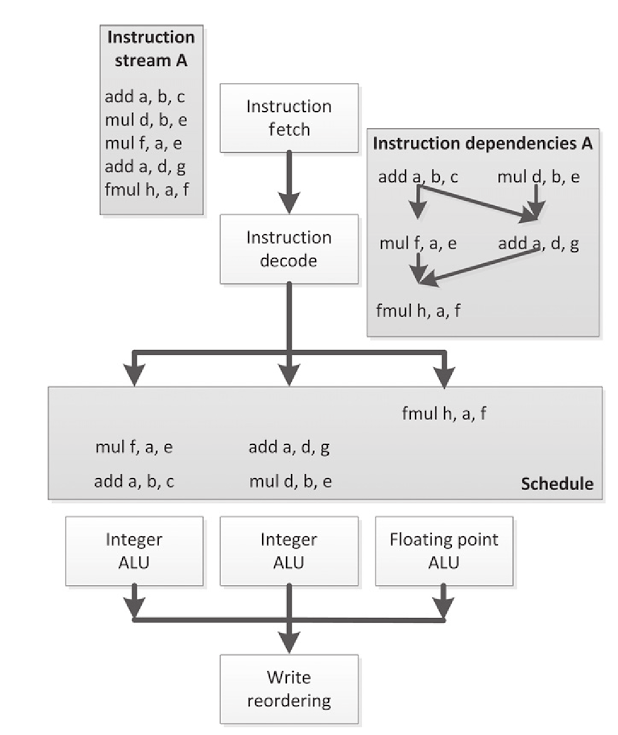
superscalar采用了如上图所示乱序执行的方案来并行执行。而且这个能力是硬件提供的,串行的代码不需要做任何修改,就能比原来执行的速度快很多。
分支预测
BTB:Branch Target Buffer,分支目标缓冲。
https://mp.weixin.qq.com/s/tyZXc_hz89SxERjb_c34_w
现代处理器分支预测技术
https://www.zhihu.com/question/645121724
现代中央处理器(CPU)的分支目标缓冲(BTB)是怎么设计的?
硬件多线程
在处理器中多开辟几份线程状态,当线程发生切换时,处理器切换到对应的线程状态执行,这种方式叫做硬件多线程(Hardware Multithreading)。
这里的线程不是软件概念,而是指的指令流水线,也就是下图中Instruction stream。
有两种方式实现硬件多线程:
-
并发多线程(SMT,Simultaneously multithreading)
-
时域多线程
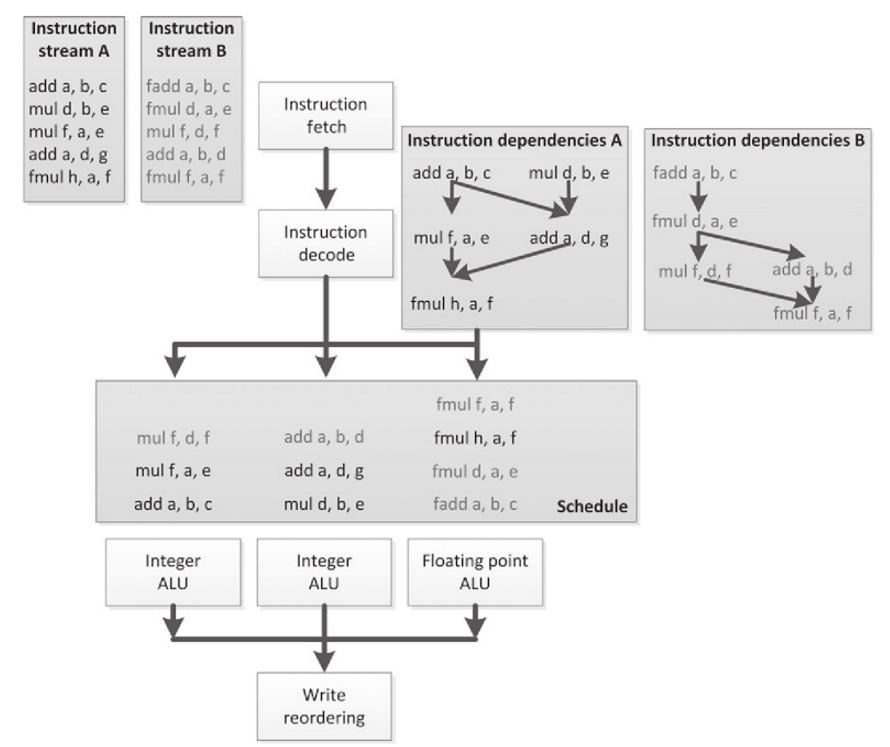
SMT相当于是多线程版本的Out-of-Order Execution。

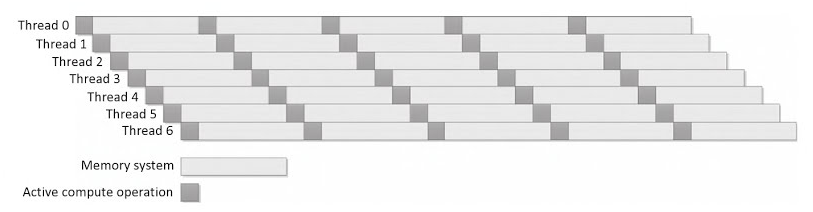
时域多线程,又称Hyper-Threading,实际上就是多级流水线。
硬件多线程和Cache一样,都是隐藏指令延迟的常用手段。
超线程其实就是两个线程共享一个计算单元和内存控制单元,但有自身独立的一些硬件,目的是两个都不是全负荷工作的线程可以轮流使用计算单元来实现比较好的throughput。但只要有一个很忙,那就可能饿死另一个。
进行乱序执行的处理器必须记住这些指令之间的依赖性,使用可重命名的寄存器可以容易地实现这个目的:例如将寄存器中的值存储到内存中,接着加载内存中的其他值到同名寄存器中,这里的”同名寄存器“并不一定是物理上的同一个寄存器。更进一步说,如果把这两条指令映射到不同的物理寄存器中,则他们可以并行执行,这就是实现乱序执行的重点。
历史上,MIPS非常喜欢做SMT4,同步4线程,Xeon Phi也尝试过;IBM的Power系列做过SMT8,同步8线程。
但这里存在一个边际效用递减的问题,因为同步多线程的强大之处,就是在重访存查找、IO传输等阻塞场景下去尽可能的复用CPU中的ALU,以便于够实现2倍、3倍乃至7倍、8倍的性能提升。可这种场景哪怕在数据中心也不是每分每秒能见到的,家用就更不必多说了。
哪怕单核双线程这种反复被intel和amd这种主流验证过的,最大多核性能提升也只是30%左右一点。
ILP,Instruction Level Parallelism
MLP,Memory Level Parallelism
TLP,Thread Level Parallelism
SMT本质上是:convert TLP into ILP/MLP。在乱序核上将这一点做到极致的,就是IBM的超多路SMT的POWER CPU,它上面跑的数据库,代表了一类应用:ILP低,MLP低。在这类应用上,SMT带来的性能/SMT的硅片面积开销 > 1,非常划算。
但现在双低型应用越来越少了。
https://www.zhihu.com/question/641481229
怎么理解英特尔15代大核取消超线程?
https://www.zhihu.com/question/695613109
为什么英特尔的下一代处理器取消了超线程?
加长流水线 vs 加宽流水线
奔腾四(P4)处理器所使用的核心有三个发展阶段:威廉核心(Willamette)、北木核心(northwoog)、波塞冬核心(Prescott)
第一代P4威廉核心(Willamette)只有13级流水线,频率基本没有上2G,性能中规中矩;
第二代P4北木核心(Northwoog)使用了20级流水线,这个级数比较符合当时的处理能力,没有浪费执行效率,所以北木被认为是P4系列里最成功的一个架构。当时P4非常成功地把AMD速龙XP系列CPU成功压制住了,于是英特尔在加长流水线的路上越走越远;
第三代P4波塞冬核心(Prescott)把流水线长度增加到了31级,缓存也加大了,相应也把频率频率拉的很高,但是大家很快就发现虽然频率高但是实际运行效率却没有北木那么高,3.2G以下波塞冬竟然打不过北木,发热和功耗也成为了劣势,高频低能说的就是波塞冬。
加长流水线既然不行,加宽流水线就成为了必然,超标量、GPU都是这方面的尝试。
苹果过去强,主要是工艺领先一步,设计上敢加宽架构,现在都用宽架构了,都用台积电新工艺了,差距就不大了。
https://www.zhihu.com/question/26289306
处理器(CPU)流水线长度是否存在理论极限?
https://www.starduster.me/2020/11/05/modern-microprocessors-a-90-minute-guide
现代微处理器架构90分钟指南
参考
结构冒险(Structural Hazard):CPU在同一个时钟周期,同时在运行两条计算机指令的不同阶段。但是这两个不同的阶段,可能会用到同样的硬件电路。
类似的,还有Data Hazard和Control Hazard。
https://blog.csdn.net/do2jiang/article/details/4545889
流水线、超流水线、超标量技术对比
https://blog.csdn.net/edonlii/article/details/8755205
单发射与多发射
https://mp.weixin.qq.com/s/FJX9eeRkxS5nJ4XIhRVwkg
从ServerSwitch到SONiC Chassis:数据中心交换机技术的十年探索历程
https://mp.weixin.qq.com/s/MCYocOY2pHHqiLhcE4SXyg
为什么苹果M1芯片这么快?
https://zhuanlan.zhihu.com/p/358167791
Vector的前世今生(1):从辉煌到低谷
https://zhuanlan.zhihu.com/p/368640768
Vector的前世今生(2):ARM SVE简述
https://zhuanlan.zhihu.com/p/594532014
一文搞懂Cortex-A77(ARMv8架构)工作原理

您的打赏,是对我的鼓励
