Chip » 计算机体系结构(一)
2021-07-21 :: 5175 Words计算机体系结构
按照Michael J. Flynn的分类方法,计算机的体系结构可分为如下四类:
Single instruction stream single data stream (SISD)
Single instruction stream, multiple data streams (SIMD)
Multiple instruction streams, single data stream (MISD)
Multiple instruction streams, multiple data streams (MIMD)
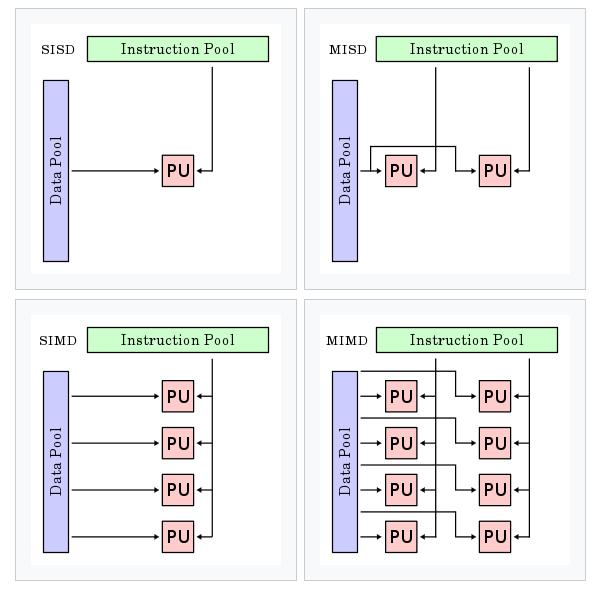
原图地址:
https://en.wikipedia.org/wiki/Flynn%27s_taxonomy
论文:
《Very High-Speed Computing Systems》
Michael J. Flynn,1934年生,美国计算机科学家。Manhattan College本科(1955)+Syracuse University硕士(1960)+Purdue University博士(1961)。Stanford教授,IEEE Fellow,ACM Fellow。
CPU通常是SISD和SIMD的,而GPU则是SIMD的,超级计算机则是MIMD的。
Intel的SSE/AVX,ARM的Neon/SVE,都属于SIMD指令。
参考:
https://mp.weixin.qq.com/s/n_V_-TOvu5hLZ0BwKpgy9A
计算机体系结构发展史
https://zhuanlan.zhihu.com/p/31271788
SIMD指令集
https://mp.weixin.qq.com/s/UExKPAMbA9EfRW35P3WnFA
RISC-V其实是反潮流,但是……
https://zhuanlan.zhihu.com/p/717140323
利用SIMD技术实现高性能的纯CPU渲染器
SPMD和MPMD
Single Program Multiple Data (SPMD):
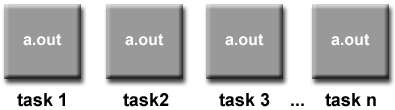
单个程序:所有任务同时执行同一程序的副本。该程序可以是线程,消息传递,并行数据或混合数据。
多个数据:所有任务可能使用不同的数据。
Multiple Program Multiple Data (MPMD):

多个程序:任务可以同时执行不同的程序。程序可以是线程,消息传递,并行数据或混合数据。
多个数据:所有任务可能使用不同的数据。
SPMD和MPMD都是编程模型的概念。
编程模型就是对编程共性的抽象。而体系结构是对于硬件的抽象。
SIMT
SIMT: Single Instruction Multiple Threads,多个thread运行同一指令,但各自处理的数据可以不同(一般每个线程的数据,尤其是寄存器是独立的)。
SIMT最早是Nvidia发明的概念,它也是一种编程模型。
SIMD的编程模型除了SIMT之外,还有subword SIMD、vector SIMD、vector-thread (VT)等。
详见论文:
《Simplified Vector-Thread Architectures for Flexible and Efficient Data-Parallel Accelerators》
https://zhuanlan.zhihu.com/p/113360369
从现代GPU编程角度看SIMD与SIMT
https://zhuanlan.zhihu.com/p/5711426839
SIMD & SIMT 与芯片架构
SIMT相比SIMD在可编程性上最根本性的优势在于硬件解决了大部分流水编排的问题。
程序执行最大的瓶颈是访存和控制流,针对这种问题能做的优化其实主要就两种:
-
一种是充分利用cache或软件可见的片上sram,减少这种大延迟的ddr访问。把一部分数据捞进来放到片上存储中,然后尽可能复用,或者把一些临时数据放到片上,避免和ddr的交互。这类思路可以统称为切块(tiling)。
-
另一种是让访存和计算并行起来,因为硬件上访存和计算单元肯定是两个模块,同时跑起来利用率肯定更高。这种并行其实也有两个纬度,一个是计算的不同阶段如果没有依赖关系,可以在做前一个阶段的计算同时做下一个阶段的数据读取,也可以是对同一个阶段的向量进行切分,计算上一部分的时候读取下一步的数据,也就是通常所讲的double buffer,这一类思路可以统称为流水编排。
在cuda编程模型中,每一个thread block内部需要有很多并行线程,隐式分成了若干个组(warp),每一组都会包含大量串行交错的访存和计算。GPU通过warp scheduler动态交错执行,一组线程的流水阻塞了就切下一组,隐式通过并行度掩盖各种流水阻塞。
当然,这也是有代价的,GPU上要放置大量sram来保存线程上下文,避免为了掩盖ddr延迟进行上下文切换又引入新的ddr访问。因此在GPU上register file的规模往往和L2差不多量级。
CPU的线程大部分都是不相关线程,GPU最适合的还是处理大连相关线程,如果线程不相关,那SIMT还是无法很好的工作。
https://zhuanlan.zhihu.com/p/562135333
SIMT、SIMD和DSA(1)
https://zhuanlan.zhihu.com/p/564623647
SIMT、SIMD和DSA(2)
https://zhuanlan.zhihu.com/p/78925147312
SIMD < SIMT < SMT
RISC vs. CISC
一直以来大部分课本上的观点是这样的:RISC由于速度快,必将取代CISC,而之所以没取代,主要是由于现在的大部分软件只能运行在X86体系上,也就是说是由于非技术的市场原因导致的。
市场原因当然不在我这篇文章的考量范畴,但“RISC比CISC快”这个结论却值得打个问号。
课本中给出的解释是:CISC由于指令复杂,所以需要将每条指令分解成微指令,才能执行,因此指令的CPI(Cycles Per Instruction)要比RISC高,所以就慢。RISC尽管完成同样的功能需要更多的指令,但根据80/20的原则,总的来说还是要比CISC快。
应该说这个结论,在上个世纪90年代中期以前,的确是颇有道理的。但主板倍频技术的出现,让这个问题有了新的变化。在早期的X86计算机中,CPU和内存工作在同样的频率下,也就是说CPU和内存一样快。而使用倍频技术后,CPU频率和内存频率之间就产生了差距。这种差距到后期,竟然几乎相差了一个数量级,这个时候CPI就不再是决定CISC和RISC快慢的决定因素了。CISC由于指令密度高,在某些场合甚至比RISC快也就不足为奇了。
事实上,现在商用的CPU已经无法再用老的定义来分类了,因为他们都借鉴了对方的某些优点。
1.提高指令密度。ARM按照传统来说是RISC,但它引入了Thumb指令来提高指令密度,因此它的指令集不再是传统RISC的定长指令集。
2.减少CPI。Intel的X86 CPU最初只有一个指令解码器,而现在为了处理最常用的20%的简单指令,它引入了简单指令解码器的概念,再加上指令流水线的引入,它在CPI上的表现与传统的RISC已经没有什么太大的差别了。
顺便说一句,Linux在多核机器上引入了“自旋锁”的概念。自旋锁的实现,说白了就是一种有条件的死循环,从表面看,死循环空占CPU,似乎是种很低效的方案,但由于CPU和其他设备之间速度的巨大差异,有时候这种方案反而是最快的方案。道理和上面的RISC vs. CISC是类似的。
总之,每个时代限制系统速度的瓶颈不同,因而完全有可能昨天的结论和今天的结论完全相反。
英特尔并不是首个将x86前端解码器与所谓的RISC风格后端结合起来的x86 CPU制造商,被AMD收购的NexGen同样如此。NexGen 5×86 CPU于1994年3月首次亮相,而奔腾Pro直到1995年11月才推出。
译码前端的复杂性才是X86真正的弱点,不规整,不等长的指令,导致硬件开销增大,但是,在工艺允许集成数亿晶体管的今天,这种硬件开销就是蚊子腿,而且随着X86加入微指令缓冲,前端的弱点也逐渐消失。同时享受着比L1更快的微指令缓冲带来的红利。微指令缓冲命中很高的程序里,程序执行速度肯定比传统的L1取指的RISC快。
https://mp.weixin.qq.com/s/HlOqQUCPljvnxNxqathWcA
都2021年了,还把x86和ARM归为CISC和RISC?
https://blog.csdn.net/windeal3203/article/details/51985832
RISC诞生与发展的缩影
https://mp.weixin.qq.com/s/8w3V-ndKBD2fReM9QZokwA
ARM架构要逆天?
https://www.zhihu.com/question/267873770
请问X86与ARM的功耗控制有什么区别?
No instruction set computing:上面提到指令需要分解成微指令才能执行,如果编译器能直接生成微指令的话,那么指令集也就不需要了,这就是NISC。
One-instruction set computer:使用Bit-manipulating之类的技术,可以用1条指令搭建一个图灵完备的机器。
定律
Strong Scaling(强扩展)和Weak Scaling(弱扩展)是衡量并行计算性能扩展性的两种常用方法。
Strong Scaling关注“同一任务用更多核能快多少”(Amdahl’s rule),Weak Scaling 关注“任务和核一起变多时还能不能保持效率”(Gustafson’s law)。
Amdahl’s rule(阿姆达尔定律):整个计算系统的性能提升取决于速度最慢的这一部分。
如果f是被并行化代码的比率,并且如果并行化版本在一个有p个处理器的机器上运行,且没有任何通信或者并行化开销,那么此时的加速比是:
\[\frac{1}{(1 - \mathcal{f}) + (\mathcal{f} / \mathcal{p})}\]Gustafson’s law(古斯塔夫森定律):问题规模足够大(必须串行执行的时间相对小)时,增加核心数目是好的。
两个定律,一个悲观,一个乐观,但是并不矛盾。
https://www.jianshu.com/p/2a756f9c379f
阿姆达尔定律和古斯塔夫森定律
术语
Shared Virtual Memory, SVM
Memory consistency model
Multisample anti-aliasing, MSAA
模拟器
计算机系统架构模拟器gem5。
https://zhuanlan.zhihu.com/p/487737252
gem5模拟器入门
https://zhuanlan.zhihu.com/p/678502885
从零开始实现GameBoy模拟器
内存模拟器Ramulator:
https://github.com/CMU-SAFARI/ramulator2
多核
从架构上区分:
-
同构(homogeneous)多核架构:系统中的处理器在架构上是相同的。
-
异构(heterogeneous)多核架构:系统中的处理器在架构上是不同的。
从运行模式上区分:
SMP(Symmetric Multiprocessing):多个核心运行一个操作系统,该操作系统同等的管理多个内核,这种运行模式就是简单提高运行性能。
AMP(Asymmetric Multiprocessing):多个核相对独立的运行不同的任务,每个核之间相互隔离,可以运行不同的操作系统或裸机程序。
BMP(Bound Multiprocessing):与SMP类似,同样也是一个OS管理所有的核心,但开发者可以指定将某个任务仅在某个指定内核上执行。
https://zhuanlan.zhihu.com/p/53596593
所有CPU内核一定生来平等吗?Intel非对称异构多处理器:Lakefield
https://en.wikipedia.org/wiki/ARM_big.LITTLE
ARM的big.LITTLE架构

您的打赏,是对我的鼓励
