Chip » NVIDIA
2021-02-08 :: 5328 WordsNVIDIA
NVIDIA作为行业龙头,其影响力甚至在Khronos Group之上,它提出的标准很多成为了行业的事实标准。
最近(2018.2),公司副总M给我们讲座的时候,回顾他早年在NVIDIA的经历,当时他作为公司骨干,曾拥有数万股NV的股票,可惜早都卖了。这十几年来,NV股票经过5次分拆(每次1股拆2股),当初的一股现在要值6500美元。他要不卖,现在可能已经是亿万富翁了。。。
The more you buy,The more you save.
https://www.zhihu.com/question/22407373
英伟达(NVIDIA)创始人黄仁勋是一个什么样的人?
第一代NVIDIA显卡甚至都不是PC游戏用的显卡,它是世嘉土星的兼容卡,可以在PC上玩SS游戏。因为要和Sega的3D技术兼容,N卡一度偏离了行业主流,差点破产。
一款叫《孤岛危机》,别称“显卡危机”的游戏于2007年诞生了,带来绝佳画面的同时,也“羞辱”了包括卡皇8800 Ultra在内的全部游戏GPU。当年主流分辨率尚且只是720P,但孤岛危机也需要3张8800 Ultra(总价在当年的北京可以买下2.5㎡房)SLI到一起,才能满足最高画质+4AA下,60帧流畅玩的需求。
黄仁勋父亲黄兴泰原籍浙江青田大安村,1945年迁往中国台湾谋生。
母亲罗彩秀出自台南的名门望族。罗家是明末清初,随郑成功迁台的福建泉州府晋江县人士,罗家定居台南水仙宫一带,逐渐发展成世家望族。如今罗家更是发展成全球性家族。
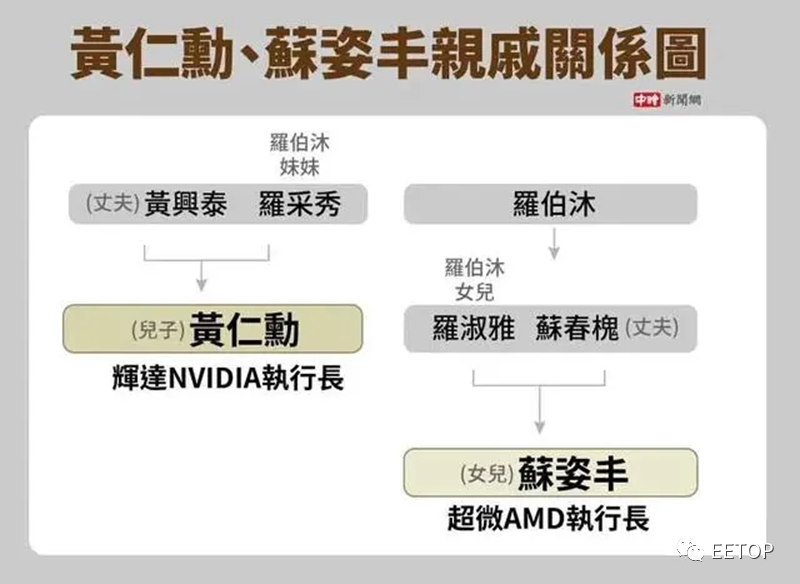
苏姿丰的外公与黄仁勋的妈妈是兄妹,苏姿丰依照辈份要喊黄仁勋一声“表舅”。
1960年广东江门有个孩子叫何国源,吃的太饱偷渡去了香港,中学毕业后又辗转去了台湾,毕业于成功大学电子工程系。
1985年,他和三个香港朋友,刘理凯、刘百行、班尼·刘,凑钱在加拿大成立了一家公司,名字叫ATI。
https://zhuanlan.zhihu.com/p/571633096
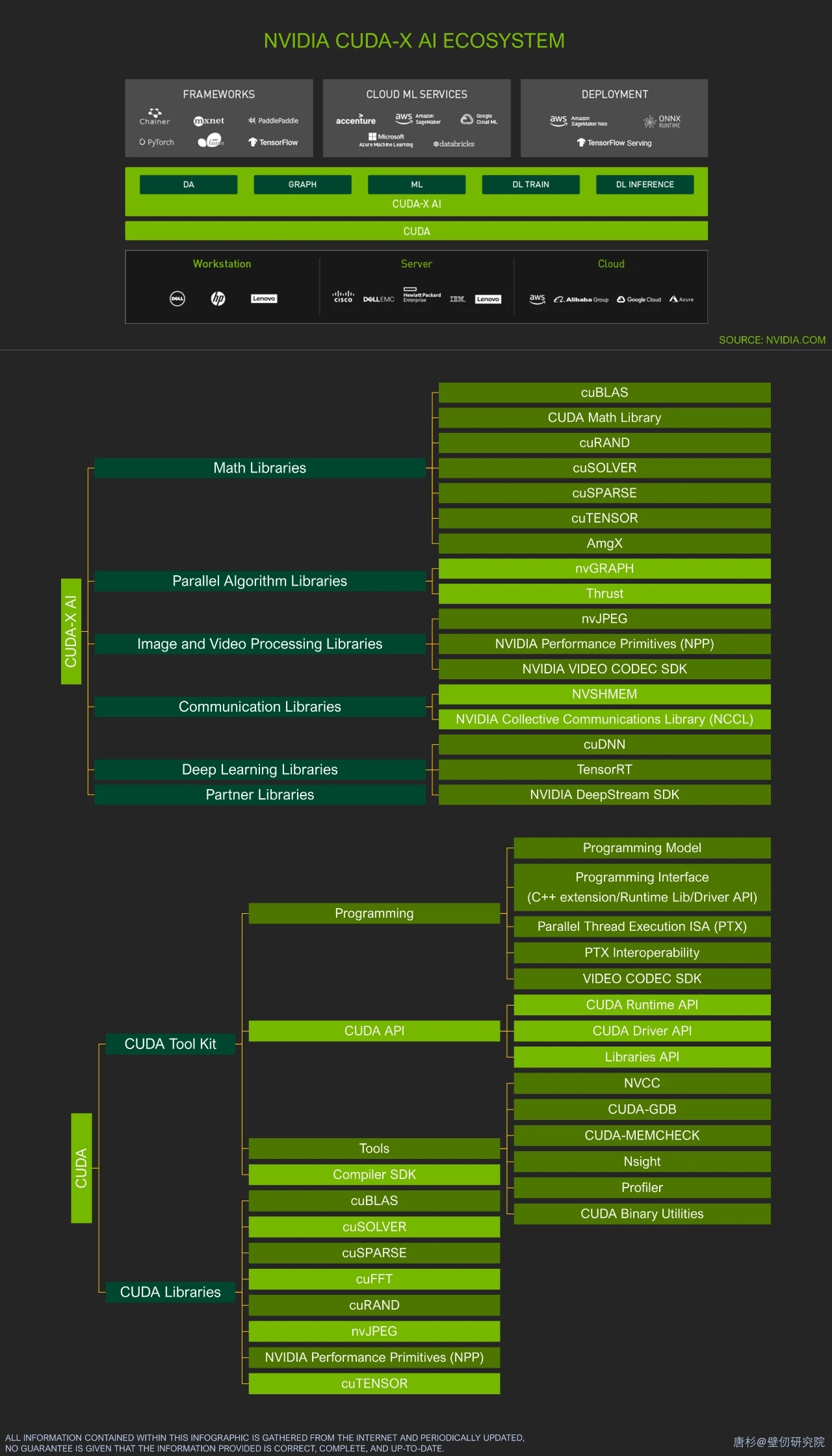
NVIDIA软硬件全栈浅析
术语
iGPU:Integrated Graphics Processing Unit。
dGPU:Discrete Graphics Processing Unit。
Copy Engine:复制引擎可以在流处理簇做计算时执行主机与设备之间的内存传输。在早期的CUDA硬件并没有任何复制引擎,后来版本的硬件包括了一个复制引擎,可以传输线性设备内存(CUDA数组除外),而最新的CUDA硬件则包括了两个复制引擎,这样可以使PCIe总线饱和并可以在CUDA数组和线性内存之间转换。
Stream Processor:传统的顶点和像素分离渲染架构,存在着资源分配不均匀的问题——两种单元的渲染在不同场景的任务量不同。如果一个单元既能做顶点渲染,又能做像素渲染的话,这个问题就迎刃而解了。这样的统一渲染单元被称为Stream Processor。
一个GPU含有若干个GPC(Graphics Processing Clusters),每个GPC含有7~8个TPC(Texture Processing Clusters),每个TPC有2个SM(Streaming Multi-processor)。
EU:Execution Units
产品线
Tesla产品专为数据中心与工作站计算应用而设计。
Quadro产品专为专业图形与工程应用而设计。
GeForce产品专为互动游戏与消费类应用而设计。
| NVIDIA Tesla V100 | NVIDIA RTX 3090 | |
|---|---|---|
| FP32 (float) performance | 14.13 TFLOPS | 35.58 TFLOPS |
| FP64 (double) performance | 7066 GFLOPS | 1112 GFLOPS |
RTX系列属于对于机器学习来说性价比较高的显卡,但是双精度浮点数性能很弱。
NVIDIA HGX:主板级的产品。比如数据中心机架上的板卡。
NVIDIA DGX:服务器级的产品。
NVIDIA EGX:主打边缘计算的主板级产品。
NVIDIA AGX:主打自动驾驶等AI功能的产品。目前已经有Parker、Xavier、Orin、Atlan、Thor等代产品。

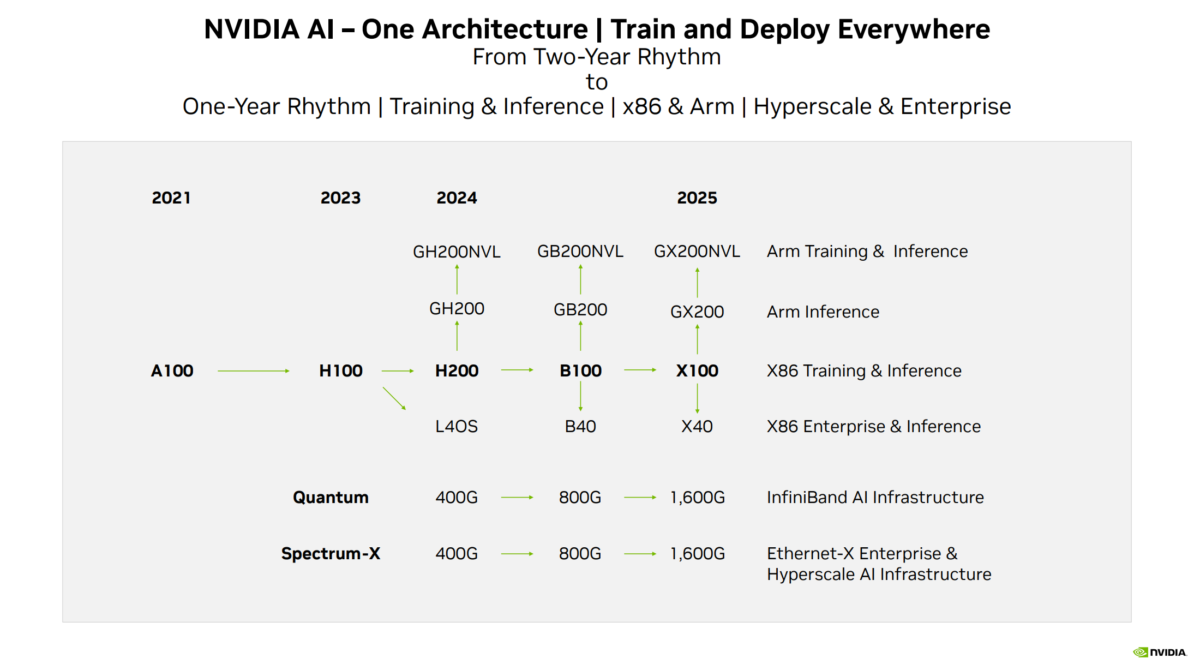
历代GPU架构代号:Currie -> Tesla -> Fermi -> Kepler -> Maxwell -> Pascal -> Volta -> Turing -> Ampere -> Grace (CPU) Hopper (GPU)-> Ada Lovelace -> Blackwell -> Vera (CPU) Rubin (GPU) -> Rosa (CPU) Feynman (GPU)
- Pascal:HBM2内存 + NVLink 1.0
- Volta:Tensor Cores + 独立线程调度(warp内的线程有独立的程序计数器,可以独立地挂起和恢复。)
- Turing:RT Core + 并发的INT32和FP32执行路径 + 统一的缓存架构
- Ampere:爆炸性增长的L2缓存(6MB -> 40MB) + Multi-Instance GPU + TF32 + 异步拷贝 (Asynchronous Copy) 与新屏障机制
- Hopper:FP8 + Thread Block Cluster + DPX指令集
- Blackwell:双Die MCM (Multi-Chip Module) + FP4/FP6 + RAS(可靠性、可用性、服务性)引擎
https://zhuanlan.zhihu.com/p/2011109512568932071
英伟达GPU架构世代差异与演进
https://arnon.dk/matching-sm-architectures-arch-and-gencode-for-various-nvidia-cards/
Matching CUDA arch and CUDA gencode for various NVIDIA architectures
这篇文章虽然讲的是NVCC的sm选项的含义,但同样可以看作是NV GPU架构的历代记。
V100表示是Volta架构的GPU,A100和H100同理。
A40是A100的简配版,用于数据中心的AI推理。
H100搭配的是X86的CPU,如果搭配NV自研的基于ARM架构的Grace CPU的话,就是GH200了。
GB202, GB203, GB205, GB206, GB207这些是芯片代号,分别对应RTX 5090/5080/5070/5060/5050显卡。
Grace Hopper,1906~1992,女,美国计算机科学家。耶鲁大学博士(1934)。Cobol语言之母。
David Harold Blackwell,1919~2010,美国统计学家,伊利诺伊大学博士(1941年)。拉奥-布莱克韦尔定理的提出者之一。他是美国国家科学院的首位黑人院士,和加州大学伯克利分校的首位黑人终身教员。当然他是黑人混血,不是传统意义的黑人。
当Blackwell的名字被列入普林斯顿大学的访问学者名单时,该校校长大发雷霆。他声称该学院滥用了大学的好客,录取了一名黑人。
https://zhuanlan.zhihu.com/p/476820418
最伟大的黑人数学家——布莱克威尔,统计学领域的天才
Vera Florence Cooper Rubin,1928~2016,女,美国天文学家,美国国家科学院院士。她是研究星系自转速率的先驱,她通过研究星系旋转曲线,发现了预测的星系角运动与观测到的星系角运动之间的差异。通过确定星系自转问题,她的工作为暗物质的存在提供了证据。这些结果在随后的几十年里得到了证实。
2019年,Large Synoptic Survey Telescope被命名为Rubin天文台。
Rosa:Rosalyn Sussman Yalow 或者 Rosalind Franklin。NV的CPU以女性科学家命名。
Rosalyn Sussman Yalow,1921~2011,美国核物理学家。1959年开发出放射免疫分析法。1977年诺贝尔生理学或医学奖得主。
Rosalind Franklin,1920~1958,英国化学家。拍摄著名的”Photo 51”X射线衍射照片,清晰显示DNA的螺旋结构。发现DNA存在两种形式(湿润型和干燥型),确定湿润型DNA为螺旋结构,磷酸基团位于外侧。1953年初已得出DNA为双螺旋结构的结论。她的数据被同事Maurice Wilkins在未经她同意的情况下展示给Watson和Crick,成为他们提出DNA双螺旋模型的关键依据。后三者获得1962年诺贝尔生理学或医学奖,而她因已于1958年去世而未能获奖。她的学生Aaron Klug继续她的病毒研究工作,1982年获诺贝尔化学奖。
H100/A100和RTX 4090最大的区别就在通信和内存上,算力差距不大。至于A40之类的芯片虽然内存大,但是带宽甚至不如RTX同档的产品,导致实际效果也是远远不如后者。
https://zhuanlan.zhihu.com/p/655402388
A100/H100太贵,何不用4090?
https://zhuanlan.zhihu.com/p/669880751
谈谈RTX4090 GPU改装为AIDC加速卡的可行性--PCB板级改造的工艺缺陷和风险
GPU
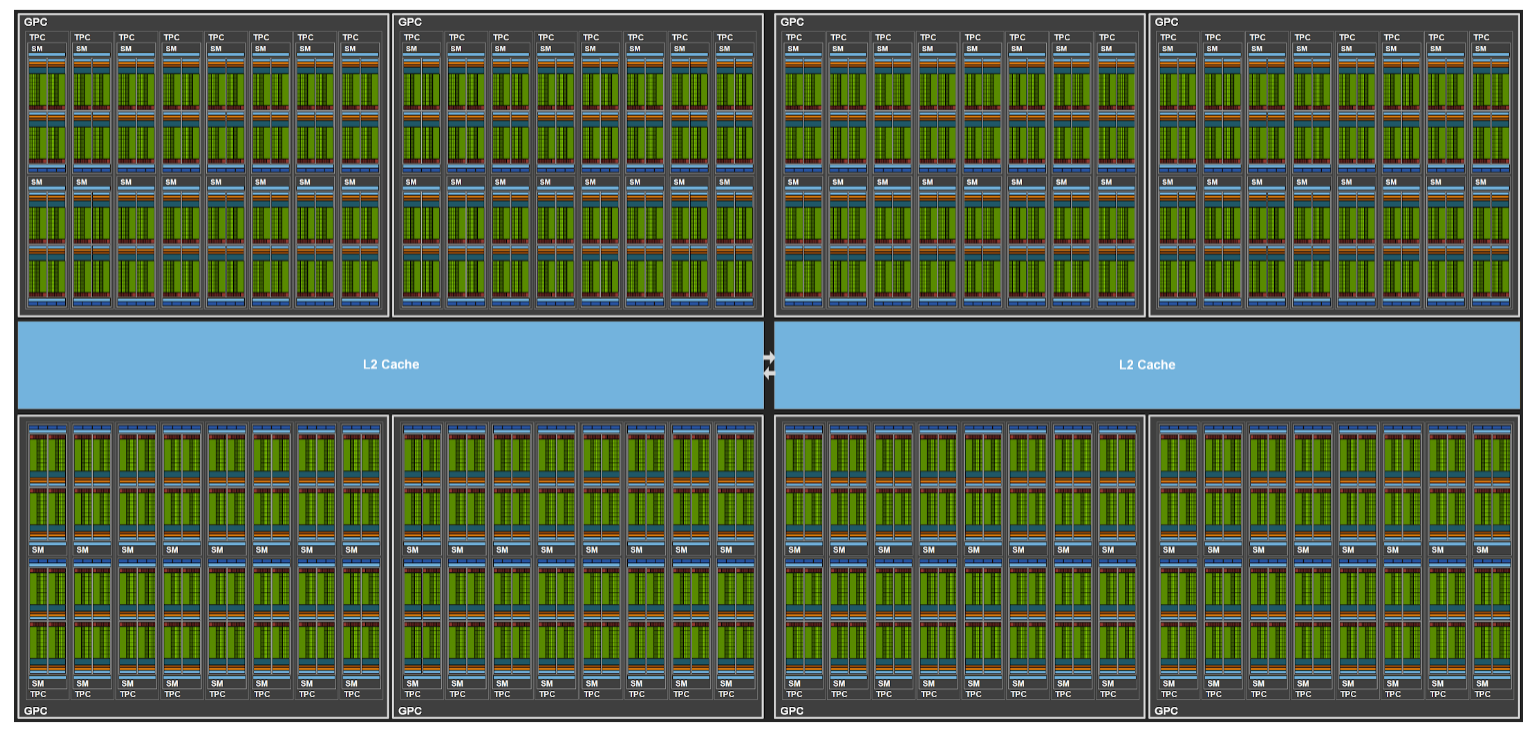
GPU → GPC → TPC → SM → CUDA/Tensor/RT Core
Hopper架构里, 一个SM有四个SM quadrants,每个SM quadrant对应一个warp dispatcher、一组SIMD ALU、一个TensorCore、一组RegisterFiles和一个L0 cache。
一个GPU方面的专栏:
https://modal.com/gpu-glossary
H100
有幸在客户那里见识了H100 Server的配置。
GPU:H100x8,每卡显存80GB。
CPU:Intel(R) Xeon(R) Platinum 8462Y+ 128核。
内存:2TB。
硬盘:14TB的MD RAID阵列。
驱动安装
查看显卡硬件型号:
ubuntu-drivers devices
安装驱动:
sudo ubuntu-drivers autoinstall
N卡型号:
nvidia-smi -L
参考:
https://zhuanlan.zhihu.com/p/59618999
Ubuntu 18.04安装NVIDIA显卡驱动
NVDLA
NVIDIA Deep Learning Accelerator是一个开源的用于inference的芯片方案。官网:
http://nvdla.org/
NVDLA由于其强大的背景,被很多芯片公司拿来套壳开发。
参考:
https://mp.weixin.qq.com/s/aFmr6WKhZ3E-PsF6-uJvJg
一图理清Nvidia AI软件栈
https://zhuanlan.zhihu.com/p/561018305
NVDLA硬件架构之卷积核心
RAPIDS
RAPIDS,全称Real-time Acceleration Platform for Integrated Data Science,是NVIDIA针对数据科学和机器学习推出的一套开源GPU加速库,基于CUDA-X AI打造。
官网:
https://rapids.ai/
代码:
https://github.com/rapidsai
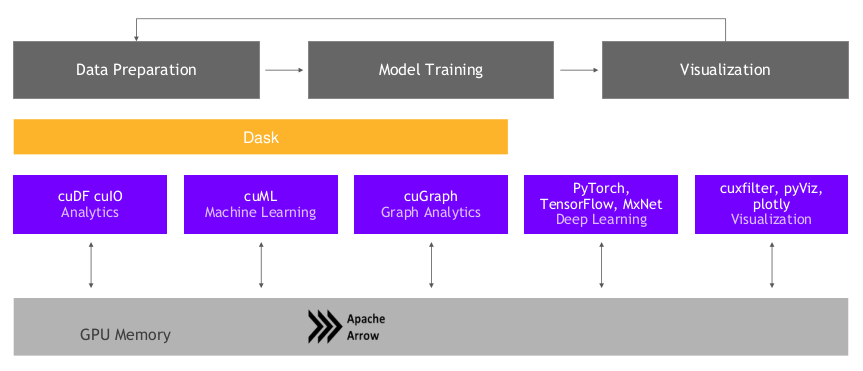
参考:
https://blog.csdn.net/sinat_26917383/article/details/104503795
NVIDIA的python-GPU算法生态
cuLitho
光刻是芯片制造过程中最复杂、最昂贵、最关键的环节,其成本约占整个硅片加工成本的1/3甚至更多。计算光刻模拟了光通过光学元件并与光刻胶相互作用时的行为,应用逆物理算法来预测掩膜板上的图案,以便在晶圆上生成最终图案。
“计算光刻是芯片设计和制造领域中最大的计算工作负载,每年消耗数百亿CPU小时。”黄仁勋讲解道,“大型数据中心24x7全天候运行,以便创建用于光刻系统的掩膜板。这些数据中心是芯片制造商每年投资近2000亿美元的资本支出的一部分。”而cuLitho能够将计算光刻的速度提高到原来的40倍。

NV的EDA辅助设计

您的打赏,是对我的鼓励
