Chip » AI Chip(二)——存算一体, FPGA
2019-06-25 :: 4900 WordsAI Chip
HBM(续)
https://www.zhihu.com/question/565166250
AMD的chiplets芯片出了这么多年了,为什么Intel和NVIDIA还不跟进?
https://www.zhihu.com/question/318057718
hbm2显存和gddr6显存,如果单从相同显存比较性能哪个好?
https://www.zhihu.com/question/422438453
NVIDIA为什么在游戏卡上死活不用HBM2显存?
https://zhuanlan.zhihu.com/p/681519240
HBM发展概述
存算一体
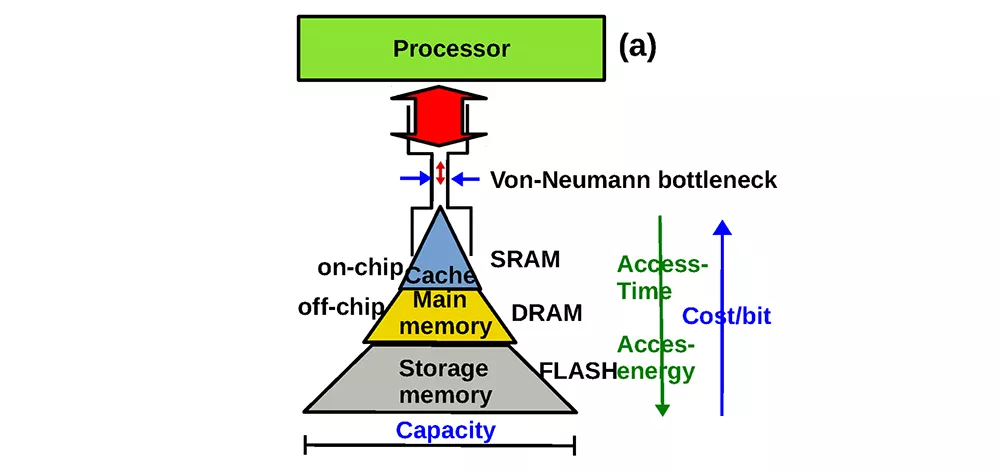
传统架构存在上图所示的“存储墙”问题。
目前存算技术主要有几个方向:
查存计算(Processing With Memory):GPU中对于复杂函数就采用了这种计算方法,是早已落地多年的技术。存储芯片内部的存储单元完成查表计算操作,存储单元和计算单元完全融合,没有一个独立的计算单元。
近存计算(Computing Near Memory):典型代表包括AMD的Zen系列CPU。计算操作由位于存储区域外部的独立计算芯片/模块完成。这种架构设计的代际设计成本较低,适合传统架构芯片转入。
存内计算(Computing In Memory):典型代表是Mythic、闪忆、知存、九天睿芯。计算操作由位于存储芯片/区域内部的独立计算单元完成,存储和计算可以是模拟的也可以是数字的。这种路线适合算法固定的场景算法计算,目前主要用于语音等轻算力场景。
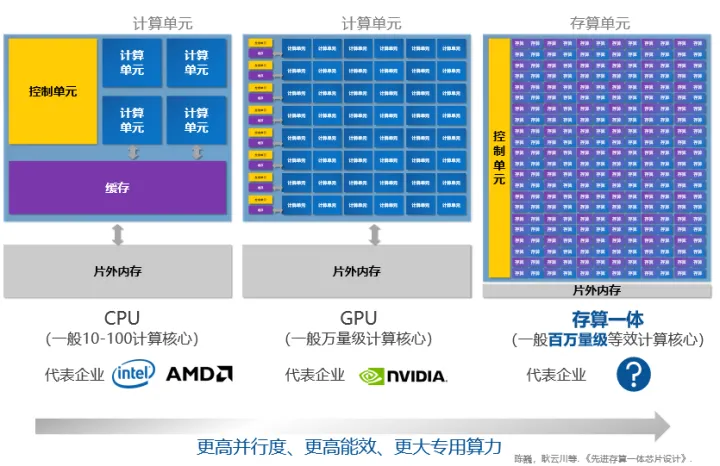
https://mp.weixin.qq.com/s/kq5F47N3LS43ZKdwe9-CUQ
端侧智能存算一体芯片的需求、现状与挑战
https://zhuanlan.zhihu.com/p/480612865
存算一体技术是什么?发展史、优势、应用方向、主要介质
https://zhuanlan.zhihu.com/p/522755103
存算一体芯片设计与编译器开发
https://zhuanlan.zhihu.com/p/444859995
阿里达摩院最新存算芯片技术解读
https://www.zhihu.com/question/623317319
存算一体芯片的技术壁垒是什么?
https://www.cnblogs.com/sasasatori/p/17136498.html
基于存算一体技术的新型计算机体系结构
https://www.cnblogs.com/sasasatori/p/18455155
聊聊LLMs与CIM
llm对内存的极致需求并不是只因为权重更大了,所以你不能简单理解成芯片也scaling到一个很夸张的规格,就又能体现架构的优势了。
传统NN主要就是权重,剩下的内存需求基本都是计算产生的中间结果,通过存算一体搞个weight station,再用数据流极致减少相邻层之间中间结果的暂态尺寸,最后再靠DSA疯狂叠算力把吞吐拉爆,这当然是个美好的故事。
今天infra层面是反过来的,我的机器有多大内存,权重占用是固定的先刨掉,7B模型就7GB,70B模型就70GB,稍微留微乎其微的一点点给inference的层间中间数据消耗(这部分才是数据流狂吹的优化空间,可惜根本不重要),剩下的几十到几百GB的内存几乎就全放kv-cache了,根据剩下的容量倒推能做多大的上下文长度,以及并发度做多高,很多情况下要把并发度降低到1来保证长上下文指标,如果还是满足不了,只能诉诸于各种压缩了。
LLM的访存特征并不复杂,权重是所有请求所有Token都共享的,也是固定大小的内存占用量,一般是1GB~100GB量级,取决于模型规模,KV的内存占用量则是和模型相关,也和上下文长度成正比,并且每个请求独立的,并发的请求越多,KV需要占用的存储越大。今天在100GB~1TB区间上极限也就是做到100K量级的上下文长度,此时并发度往往是个位数甚至1。这个是很恐怖的,因为并发度提升一个数量级,或者上下文长度提升一个数量级,需要的KV存储也直接提升一个数量级,奔着1TB~10TB去了。
SRAM6T物理结构实在是shrink不下去的;相较1T1C(1晶体管+1电容)DRAM的单位面积/成本是相当昂贵的,相校垂直堆叠走线的HBM也要至少昂贵2X-3X;虽然SRAM的速度相较HBM3更快数倍。
常规AI芯片最大的带宽压力(HBM带宽问题),在Groq这种架构上都转换到了内部的SRAM上,但是因为集群内的芯片级联以及计算效率提升,groq就无需再访问HBM。
Groq这颗芯片相当于放弃了传统的主显存,而是用更大的L3/L4 cache作为替代,容量/带宽比极高,指令发射密度可以拉得很高,且可能通过2D Systolic Array补偿大吞吐流水线,弥补容量局限。但是与片外主存交互的load/offload cycle仍会慢下来,同时搬运效率也受限于这一段的bandwidth。
这种选择一个很尴尬的地方在于,内存带宽选择的sram是芯片内的尺度,而互联又不可避免走向更低速的芯片间、甚至板卡间、服务器间的尺度,互联自然远远跟不上内存带宽,从而把内存的优势打回原形。
大家一致认为目前的HBM看起来不是一个最好的solution,应该会被hybird bonding stacking dram或CXL memory取代,一个替换HBM近程,一个替换远程。
MOE算是稀疏化了权重,每个Token只访问了可能和这个请求更相关的权重,这样用更少的访存量就可以获得接近的权重质量,因为Token感受野里的世界理解以及上下文相关度更高。
KV的稀疏化未来大概率也会爆发,当上下文长度飙升到M甚至G量级的时候,只访问其中相关度更高的子集来减少访问量,其实一定程度类似于我最前面写的几年前对于神经图灵机这种精细化管理的理念。
https://www.zhihu.com/question/645010090
Groq公司推出的全球最快的大模型推理服务达到每秒输出500个token,如何看待这一技术?
https://zhuanlan.zhihu.com/p/683873553
TSP: LPU(Language Processor Unit) 成名绝技
https://zhuanlan.zhihu.com/p/683359705
LLM推理到底需要什么样的芯片?(1)
https://zhuanlan.zhihu.com/p/683908169
LLM推理到底需要什么样的芯片?(2)
https://zhuanlan.zhihu.com/p/557933130
从2022新公开的特斯拉机器人Dojo芯片架构信息到存算一体
FPGA
CGRA:Coarse Grained Reconfigurable Array
FPGA:Field Programmable Gate Array
FPGA主要是由以LUT和MUX为基础构成的门级可编程逻辑块构成的。
CGRA是coarse-grained的粗粒度,它是编程重构ALU阵列而非逻辑门阵列,因此很多的运算由硬核实现,不是LUT搭真值表。
https://www.zhihu.com/question/407417134
CGRA和FPGA有什么不同?
https://mp.weixin.qq.com/s/Cy_vb0PpcvGTDmlMt1VkSw
从GPU、TPU到FPGA及其它:一文读懂神经网络硬件平台战局
https://mp.weixin.qq.com/s/DnurlGgd5q4Fwjxy3YnIrQ
当数据库遇见FPGA:X-DB异构计算如何实现百万级TPS?
https://mp.weixin.qq.com/s/H_KnHQ6AzCNFqmW8uDj1rA
基于FPGA的深度学习加速器综述:挑战与机遇
https://mp.weixin.qq.com/s/acAbNP_ERnKlL3_9v_mwow
FPGA:AI ASIC的必经之路?
https://mp.weixin.qq.com/s/K_dohaZbCISZlxe1Utu50w
如何用FPGA加速卷积神经网络(CNN)?
https://zhuanlan.zhihu.com/p/152167194
两大FPGA公司的“AI技术路线”
CNN加速器
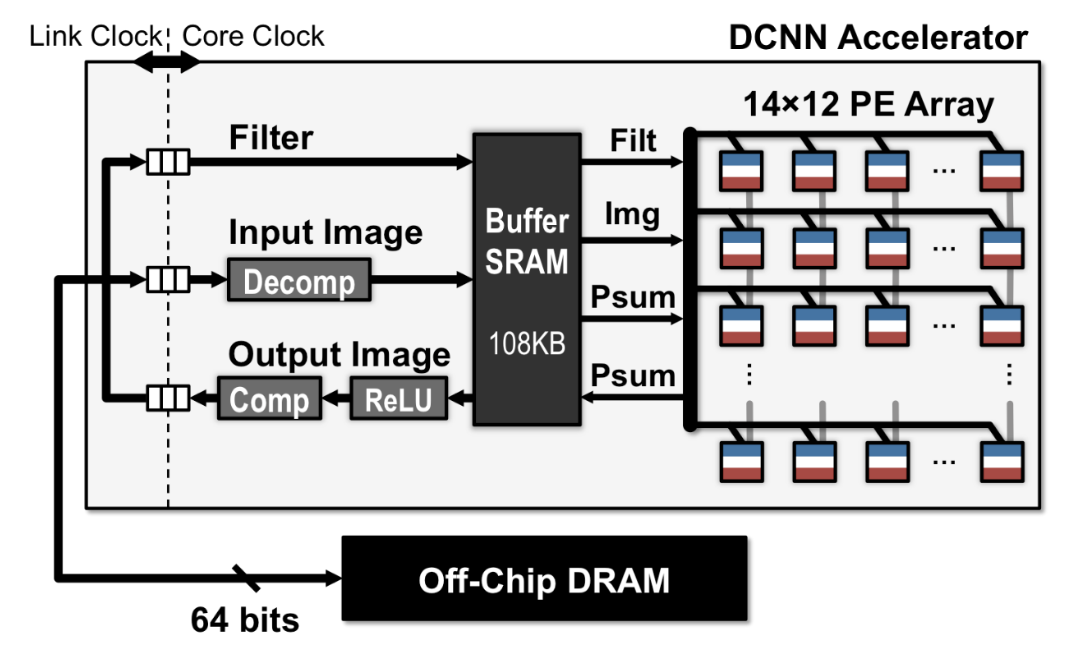
https://zhuanlan.zhihu.com/p/108167850
Eyeriss:适用于深度卷积神经网络的节能型可重构加速器
Softmax加速器
A3, SpAtten, Sanger等。
CGRA
CGRA(Coarse-Grained Reconfigurable Array,粗粒度可重构阵列)是一类介于通用CPU/GPU和专用ASIC之间的可重构计算架构,近年来在AI加速、边缘计算和能效敏感场景里备受关注。
CGRA是由大量“可编程处理单元(PE)+可重配置片上网络”组成的二维阵列,能在纳秒-微秒级重新配置成不同数据通路,以接近ASIC的能效执行特定算法,又保留软件可编程的灵活性。
https://zhuanlan.zhihu.com/p/586253188
CGRA在AI领域的最新进展综述
https://zhuanlan.zhihu.com/p/586253188
CGRA编译技术研究:Ultra-Fast CGRA Scheduling to Enable Run Time, Programmable CGRAs论文研读
DEEPHi
2018.8
深鉴科技是一家AI Chip公司。成立于2016年3月,2018年7月被Xilinx收购。
深鉴科技与云天励飞、寒武纪和地平线共同被称为“天寒地鉴”的中国AI芯片四小龙。
官网:
http://www.deephi.com/
姚颂,1992年出生,2015年毕业于清华大学电子工程系。曾任深鉴科技创始人&CEO,现担任东方空间联合创始人&联席CEO。
如果说2017年以前的AI Chip领域,主要解决的是芯片有无的问题的话,那么2018年的重点就聚焦在如何更好的使用上了。
性能方面各家各有千秋,即使不考虑功耗、面积等约束,也没有哪家在所有运算上,都比别人快,因此产品只要不是全面落伍,就还有的混。但易用性方面差距就比较大了。
1.CPU+NN混合编程。深鉴这方面做的还不错,似乎一套工具链就可以搞定,就是不知道自动化程度如何。有的友商连这一步都没做好,两套工具链+手动链接,把应用工程师折腾惨了。
2.模型压缩。Pruning方面由于有韩神的加持,确然做的很好,比我司强。Quantization方面,INT8量化算是最基本的量化了,不知道UINT8/INT16,他们做的如何。
3.Tensor Processor。深鉴这方面似乎是空白,这导致的一个结果就是AI Chip支持的运算非常有限,CPU负载过高,而AI Chip的负载相对就不行了。
4.模型导入。这方面深鉴只能说还不入流。虽然表面看来,它支持了Caffe和Tensorflow。然而它的支持方案是修改源代码。。。众所周知,pb文件的易用性是建立在通信双方使用同一套协议的基础之上。但目前AI领域魔改成风,跑个开源模型,还必须要下载作者魔改版的Caffe。。。可以想见深鉴这方面的自动化程度一定不咋样,肯定有很多手工活要做。
那么正确的做法是什么呢?参见ONNX。我司的方案比ONNX略早,但思路基本一致。
5.Model Zoo。这个比较寒碜了,只有三个模型,而且还都是最简单的分类模型。不过从支持Inception v1来看,应该是掌握了加速分支网络的技巧。其他的Face Detection等只有视频,没有模型,似乎还处于实验室阶段,可能易用性还有待提升。

您的打赏,是对我的鼓励
