Chip » AI Chip(一)——TPU, HBM
2018-08-04 :: 5859 WordsAI Chip

https://basicmi.github.io/AI-Chip/
A list of ICs and IPs for AI, Machine Learning and Deep Learning.
https://www.zhihu.com/answer/1902838887392458347
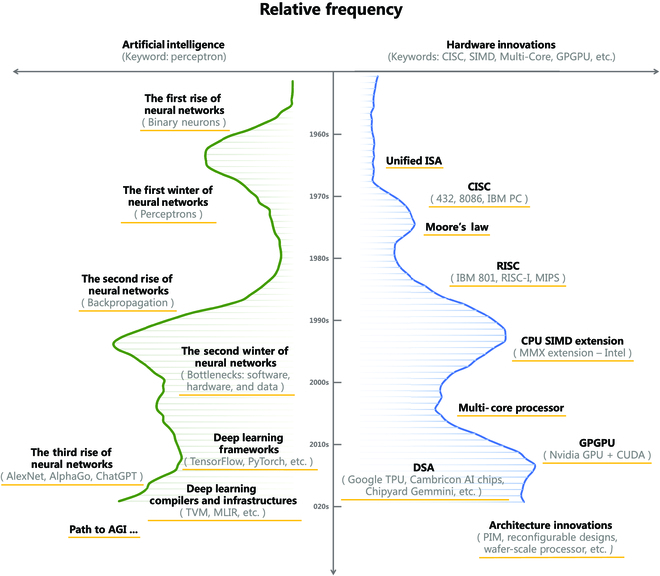
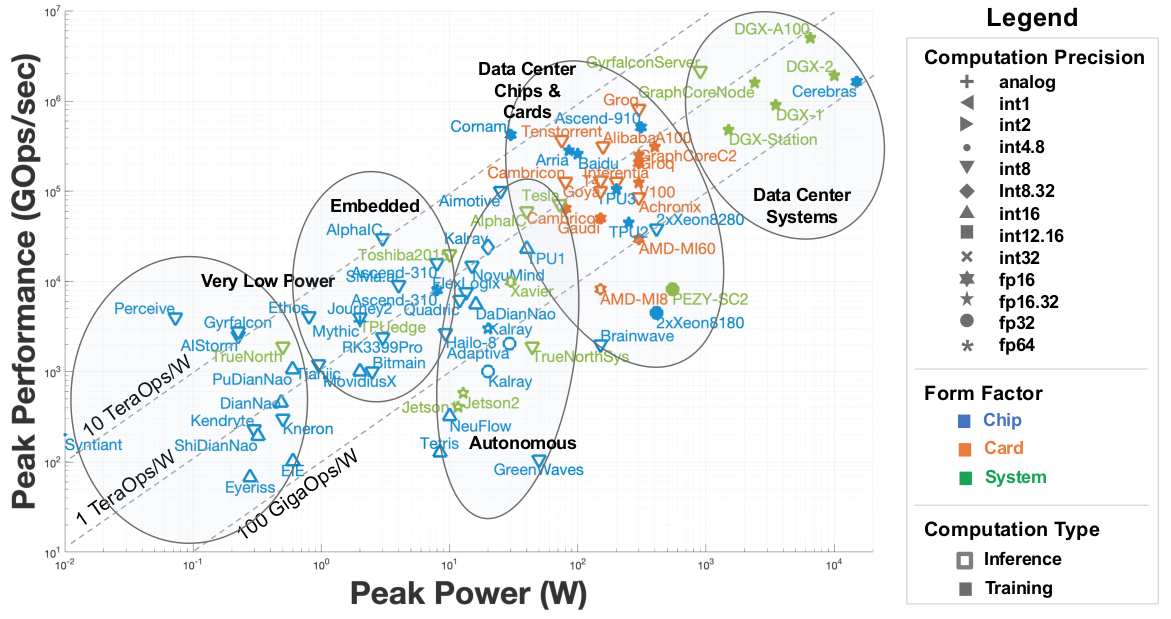
各类AI加速芯片架构比较
NN计算的硬件设计
NN计算问题的瓶颈主要包括两类:
1.数学运算的速度。NN运算主要以乘加为主,实现这类加速功能的硬件单元一般被称为NN Processor。这也是第一代AI芯片主要解决的问题。
再细分的话,又有矩阵派和卷积派两种。
矩阵派的通用性好,且FC运算速度快于卷积派。
而卷积派由于针对Conv的Kernel数据不变这一特点进行优化,Conv速度极快。
2.IO问题,也称带宽问题。早期的NN由于算子有限,基本只有FC、Conv、Pooling、Activation等少数几种算子。但现在的NN模型算子可就多了,且有相当部分算子属于非计算类的搬运数据算子,比如permute等。针对这类运算,一般采用被称作Tensor Processor的硬件单元进行加速。
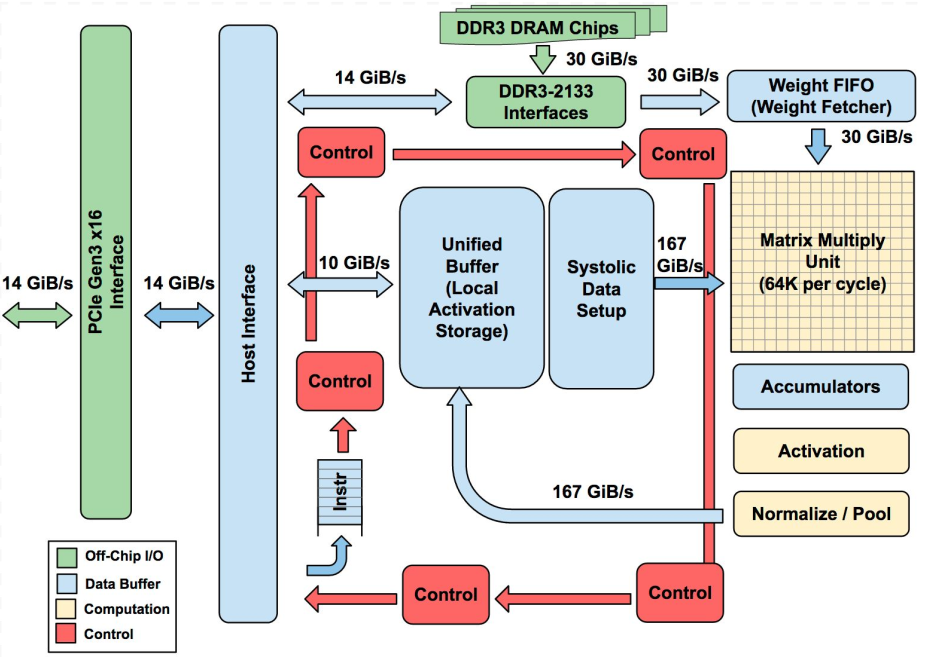
TPU
Tensor Processing Unit(TPU)是Google推出的AI芯片系列。目前已经有3个版本:
TPU v1, deployed 2015, 92 teraops, inference only.
TPU v2, cloud TPU 2017, pod 2018, 180 teraflops, 64 GB HBM, training and inference, generally available. 11.5 petaflops in a pod.
TPU v3, cloud beta 2018, 420 teraflops, 128 GB HBM, training and inference, beta. >100 petaflops in a pod.
论文:
《In-Datacenter Performance Analysis of a Tensor Processing Unit》
《TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings》
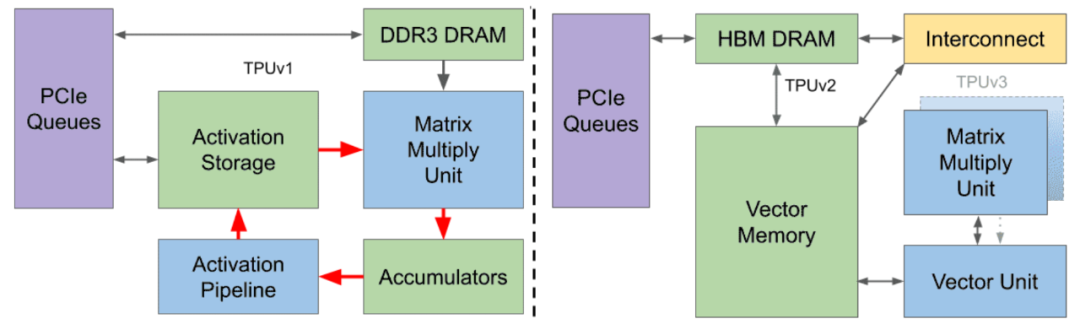
TPUv2的改进:
-
TPU v2将上述两个互相独立的缓冲区调整位置后合并为向量存储区(Vector Memory),从而提高可编程性。
-
改进针对的是激活函数管道(Activation Pipeline),TPU v1的管道内包含一组负责非线性激活函数运算的固定功能单元。TPU v2则将其改为可编程性更高的向量单元(Vector Unit),使其对编译器和编程人员而言更易用。
-
将矩阵乘法单元直接与向量存储区连接,如此一来,矩阵乘法单元就成为向量单元的协处理器。这种结构对编译器和编程人员而言更友好。
-
TPU v1使用DDR3内存,因为它针对的是推理,只需使用已有的权重,不需要生成权重。针对训练的TPU v2则不一样,训练时既要读取权重,也要写入权重,所以在v2中,原本的DDR3改为与向量存储区相连,这样就既能向其读取数据,又能向其写入数据。
-
将DDR3改为HBM。因为从DDR3读取参数速度太慢,影响性能,而HBM的读写速度快20倍。
-
在HBM和向量存储区之间增加互连(Interconnect),用于TPU之间的连接,组成Pod超级计算机。
TPUv3在体系结构方面改进不大,主要是堆料:加计算单元,加内存,加主频等等。
TPUv4是TPU系列时隔4年(2021)之后的大升级。它的改进主要是:
-
TPU核心间的网络拓扑由2D Tours改为3D Tours。
-
加入Sparse Core专门处理Transformer模型中的Embedding操作。
-
引入Optical Circuit Switching,OCS。
TPU v5e是2023年发布的。
从TPU v5开始,e系列负责训推一体,Pod规模不会很大,部署更加灵活,而p系列则负责更大规模的Foundation Model训练任务。
https://zhuanlan.zhihu.com/p/653993836
面向大模型的最强DSA——TPU v5e架构分析
https://zhuanlan.zhihu.com/p/626412573
谈谈Google TPUv4处理器的硬件结构、计算范式与SuperPod互连拓扑--部分细节对比Nvidia
https://zhuanlan.zhihu.com/p/3326989452
简单谈谈Google TPUv6
https://zhuanlan.zhihu.com/p/1933648489704818615
TPUv4深度解析
https://www.zhihu.com/answer/2716117809
David Patterson在UCB的演讲,分享了Google TPU近十年的发展历程以及心得体会
Coral Dev Board
Coral Dev Board是Google于2019年3月推出的一款搭载TPU的嵌入式开发板。
参考:
http://linuxgizmos.com/google-launches-i-mx8m-dev-board-with-edge-tpu-ai-chip/
Google launches i.MX8M dev board with Edge TPU AI chip
脉动阵列
AI=矩阵乘+非线性
由于非线性只有可怜的O(N)的计算量,矩阵乘的O(N^3)的计算量才是AI中的绝对计算瓶颈。
Systolic array是孔祥重和他的博士生Charles Leiserson于1978年发明的。
论文:
《Why systolic architectures?》

孔祥重(H. T. Kung/Kung, Hsiang-Tsung),1945年生。台湾国立清华大学本科(1968)+CMU博士(1974)。CMU、Harvard教授。台湾中央研究院院士、美国工程院院士。除了Systolic array之外,数据库领域的Optimistic concurrency control(乐观并发控制)也是他的贡献。
除了Charles Eric Leiserson之外,他的博士生还有Robert Tappan Morris,也就是著名的Morris Worm的作者。
上图中,矩阵A和B都是脉动式的进入计算单元,这种情况,一般被称为全脉动阵列。
如果A和B,其中之一保持不变,只有另一个脉动式的进入计算单元,则为半脉动阵列。
参考:
http://web.cecs.pdx.edu/~mperkows/temp/May22/0020.Matrix-multiplication-systolic.pdf
矩阵乘法器原理
http://www.eecs.harvard.edu/~htk/publication/1980-introduction-to-vlsi-systems-kung-leiserson.pdf
Algorithms for VLSI Processor Arrays
https://zhuanlan.zhihu.com/p/26522315
脉动阵列-因Google TPU获得新生
http://www.sohu.com/a/142237570_505803
我们应该拥抱“脉动阵列”吗?
https://zhuanlan.zhihu.com/p/26882794
Google深度揭秘TPU
TPU是单颗超大128×128全局脉动阵列;NVIDIA是大量分布式4×4小脉动阵列嵌入在各个SM中,配合CUDA通用核灵活调度。
参考:
https://mp.weixin.qq.com/s/1X9xiZkmVPI-j-aipr-ocg
AlphaGo Master最新架构和算法,谷歌云与TPU拆解
https://mp.weixin.qq.com/s/Yo0uKd1Mzy4mmS4r0mxfVw
有图有真相:深度拆解谷歌TPU3.0,新一代AI协同处理器
https://mp.weixin.qq.com/s/kPrZ0PuevXEJjVB7RXs70g
谷歌TPU率队,颠覆3350亿美元的半导体行业
https://mp.weixin.qq.com/s/wunqEHC6c-yUVXTl4yTG4w
仅需1/5成本:TPU是如何超越GPU,成为深度学习首选处理器的
https://mp.weixin.qq.com/s/vncPcczTyqglndeZAgjWfw
一文读懂:谷歌千元级Edge TPU为何如此之快?
https://www.nextplatform.com/2018/05/10/tearing-apart-googles-tpu-3-0-ai-coprocessor/
Tearing Apart Google’s TPU 3.0 AI Coprocessor
https://mp.weixin.qq.com/s/3DubSQ1D59Z-PCovjHiidQ
TPU(灵魂三问 WHAT? WHY? HOW?)
https://mp.weixin.qq.com/s/j053qtpdz21IdgS22uGwAw
深入剖析卷积乘累加的硬件加速技术
https://mp.weixin.qq.com/s/XXO4hkjJkcZ5sTVVKWghEw
TPU的起源,Jeff Dean综述后摩尔定律时代的ML硬件与算法
https://mp.weixin.qq.com/s/e8zOrmiIidy8IoV1yMfdKg
谷歌长文总结四代TPU打造经验:里程碑式的TPUv4是怎样炼成的?
https://mp.weixin.qq.com/s/uEAlKdpzutOpnPGmg5dOjw
谷歌TPU超算,大模型性能超英伟达,已部署数十台:图灵奖得主新作
https://zhuanlan.zhihu.com/p/656363598
谷歌TPU2机器学习集群的幕后
https://zhuanlan.zhihu.com/p/1933648489704818615
TPUv4深度解析
HBM
HBM:High Bandwidth Memory是一款新型的CPU/GPU内存芯片(即“RAM”),其实就是将很多个DDR芯片堆叠在一起后和GPU封装在一起,实现大容量,高位宽的DDR组合阵列。
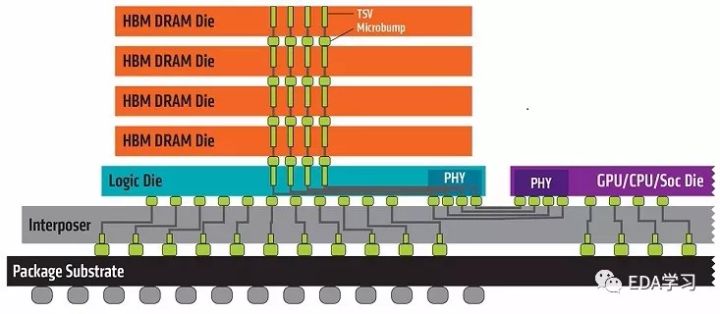
这是HBM的结构图。
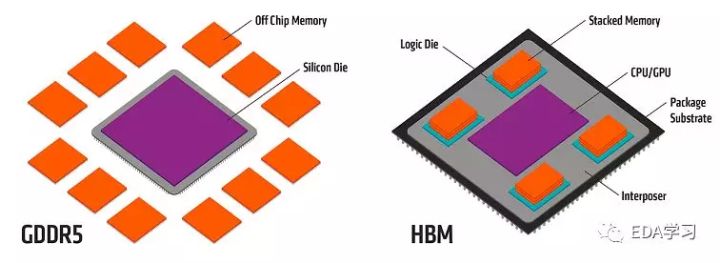
这是HBM和GDDR5的对比图。
从上面两图可以看出,HBM的集成程度在chip一级,介于PCB和die之间,这也就是近来比较火的Chiplet技术。
HBM带宽是传统内存(DRAM)的4.5倍,因此更适合处理AI应用程序所需的大量数据。这种性能的提升是如此之大,以至于许多客户更愿意支付专用内存所需的更高价格(每GB大约25美元,标准内存大约8美元)。
LPDDR和HBM卷成本,如果考虑的是$/GB,那LPDDR确实有优势,但如果考虑的是$/GBps,HBM还是最具性价比的选择。而LLM虽然对内存容量有比较大的需求,但对于内存带宽同样有巨大的需求。
NVIDIA是GDDR协议几乎实际的掌控者,每一代GDDR出来,Nvidia都会来个GDDR-X,这个-X,实际上是下一代GDDR的beta特性,即其他人用GDDR6的时候,Nvidia有GDDR6-X定制(并且独享供货),而这玩意儿实际上是GDDR7-beta。
HBM是将DRAM透过先进封装技术堆栈而成,利用硅穿孔(TSV)技术,再填充导电物质连接金属球以达通电效果。
HBM堆栈层数愈多,DRAM就必须做得更薄,因此必须导入更先进的DRAM制程。
普通DRAM颗粒,透过TSV垂直方向钻孔、TCB热压键合的封装技术,可以堆栈出规格不算高的HBM装置救急。
HBM的生产卡点主要在前段Dram,目前由于国内无法取得西方先进设备,工艺被限制在18nm也就是1y水平的Dram,但同样是利用DUVi + MP以及结构的优化去推进到接近1a的水平,进而生产HBM所需要的DDR5以上颗粒。
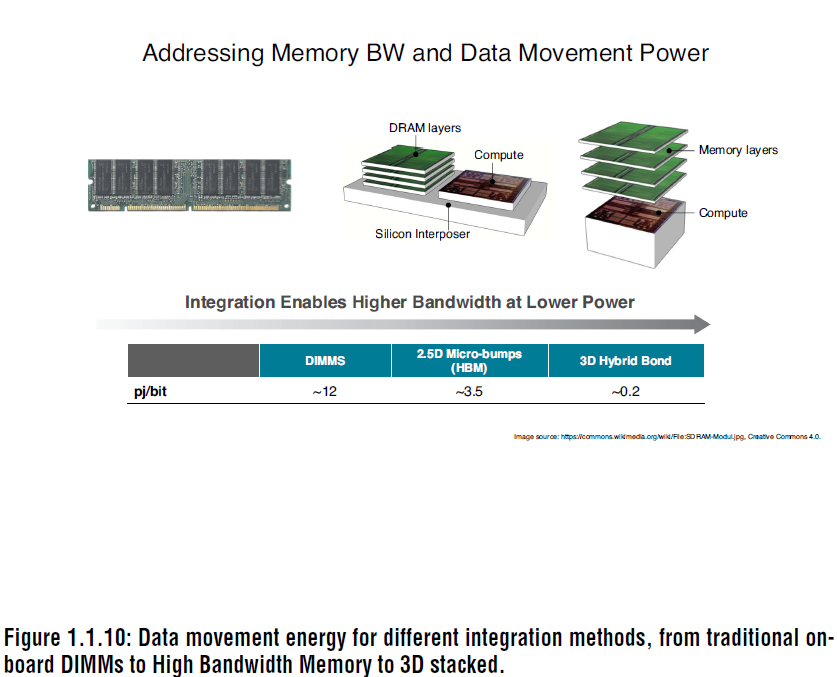
HMC(Hybrid Memory Cube)
能否达成HBM3E的带宽,基本上就是需要12mmx12mm Size下放入确定频率、Bank/Rank规格的Array的数量,而要放入这么多Array,需要工艺密度接近1β。
但你或多或少地放弃掉HBM的这些约束的话,你会发现,什么HBM很难做啥的,都消失不见了,没有EUV就没有呗,大不了尺寸做大点。
NV的Feynman架构也将使用定制化的HBM。
https://zhuanlan.zhihu.com/p/1942523887578494185
你缺HBM吗?
- TPU上的片上内存单元(CMEM、VMEM、SMEM)比GPU上的L1、L2缓存大得多。
- TPU上的HBM比GPU上的HBM小得多。
- 负责计算的Core少了很多。
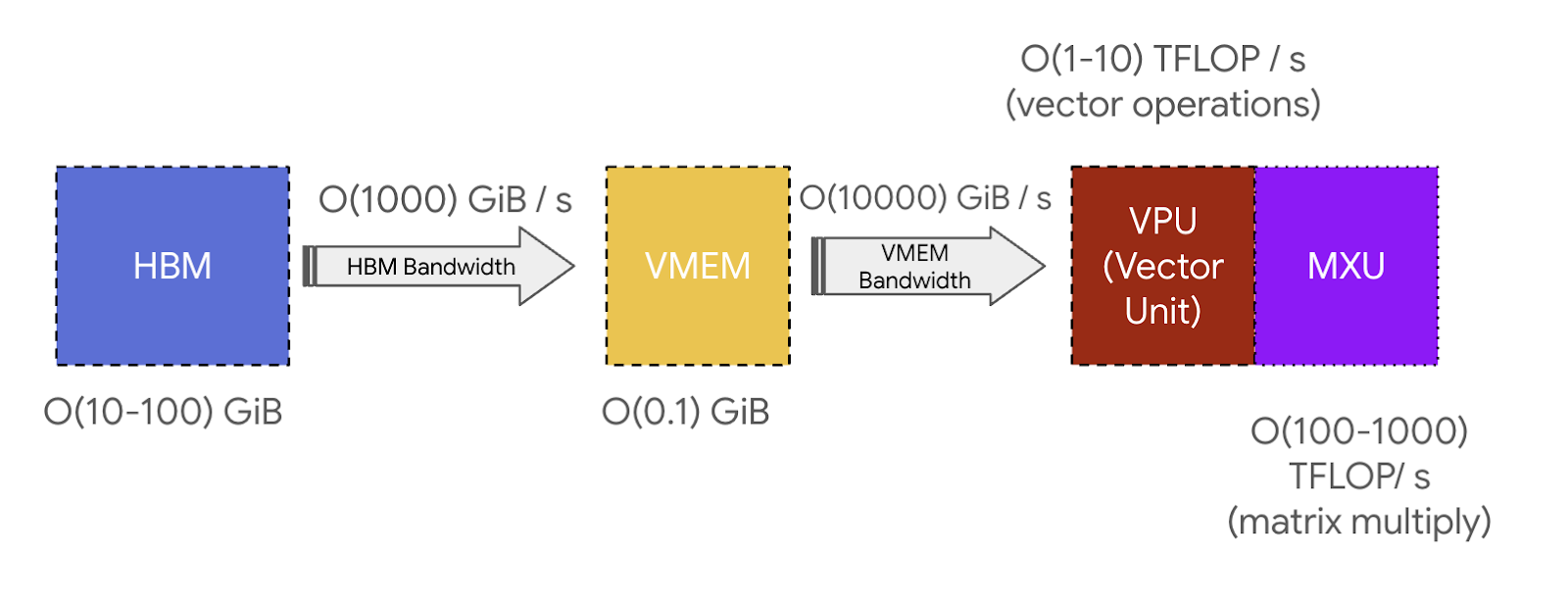
参考:
https://zhuanlan.zhihu.com/p/33990592
HBM火了,它到底是什么?
https://zhuanlan.zhihu.com/p/34164501
HBM技术之显卡应用
https://mp.weixin.qq.com/s/5JrsQnwL6u1fZNIpKq_hQA
DRAM的架构历史和未来
https://mp.weixin.qq.com/s/PzD1lCe5h3VkMrhFb7CfQg
后SoC时代或将迎来Chiplet拐点
https://mp.weixin.qq.com/s/oMA9RSaq0nuSNgKDRwHavQ
Chiplet最强科普
https://zhuanlan.zhihu.com/p/356505099
Chiplet与异构集成技术研究

您的打赏,是对我的鼓励
