toolchain » TVM
2021-05-27 :: 6894 WordsTVM
TVM是陈天奇领导的一个DL加速框架项目。它处于DL框架(如tensorflow、pytorch)和硬件后端(如CUDA、OpenCL)之间,兼顾了前者的易用性和后者的执行效率。
官网:
https://tvm.apache.org/
代码:
https://github.com/apache/tvm
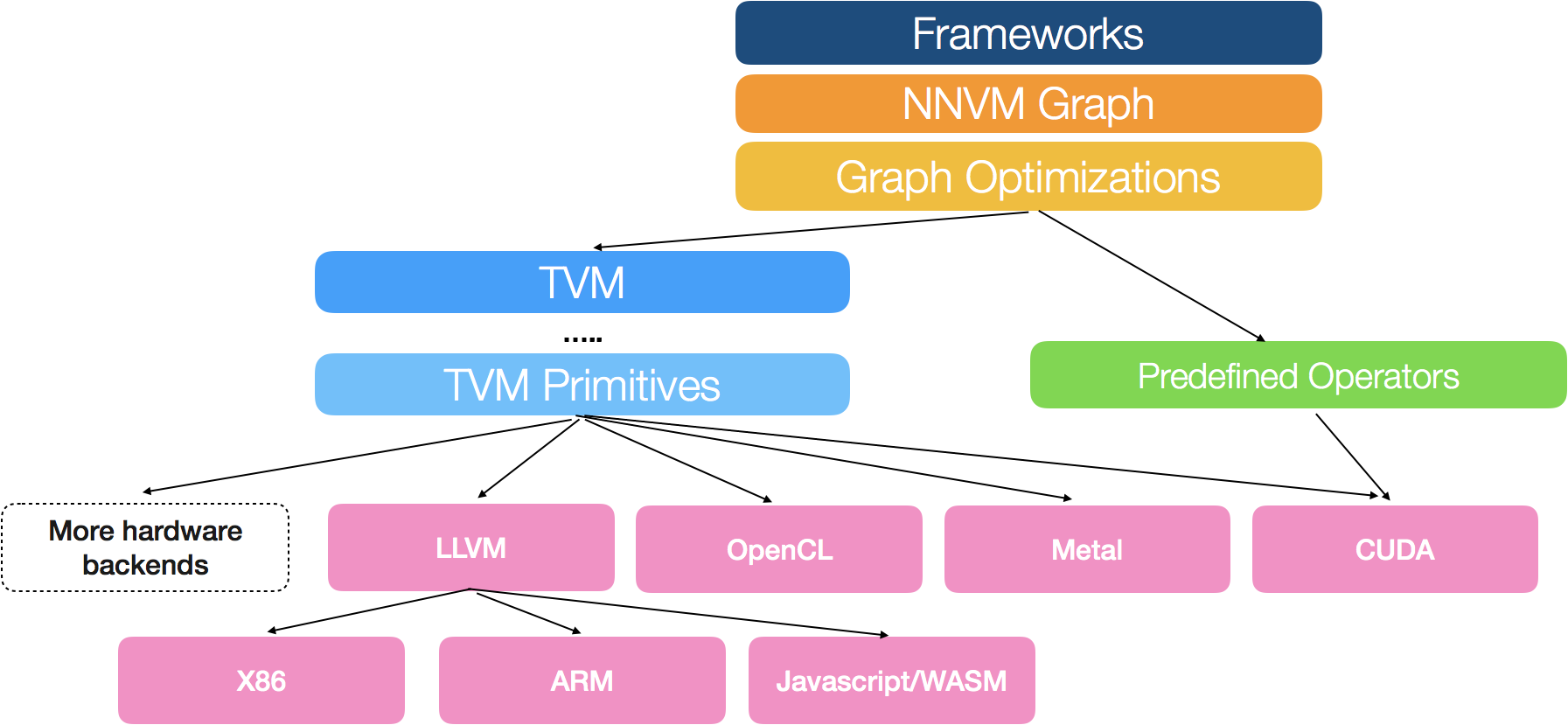
论文:
《TVM: End-to-End Optimization Stack for Deep Learning》
和同类项目的差异:
-
TFLite和ONNXRuntime只能接收特定格式的模型。而TVM这些都能接收。
-
NCNN、MACE之类的项目,一般只考虑了ARM CPU的优化,对于异构计算做的比较少。
-
TVM强化了图优化的部分,使之更类似于编译器的架构。
架构
官网:
https://tvm.apache.org/docs/arch/index.html


安装
TVM暂时不支持pip安装,pip install tvm安装的是另一个同名软件。。。
TVM Runtime
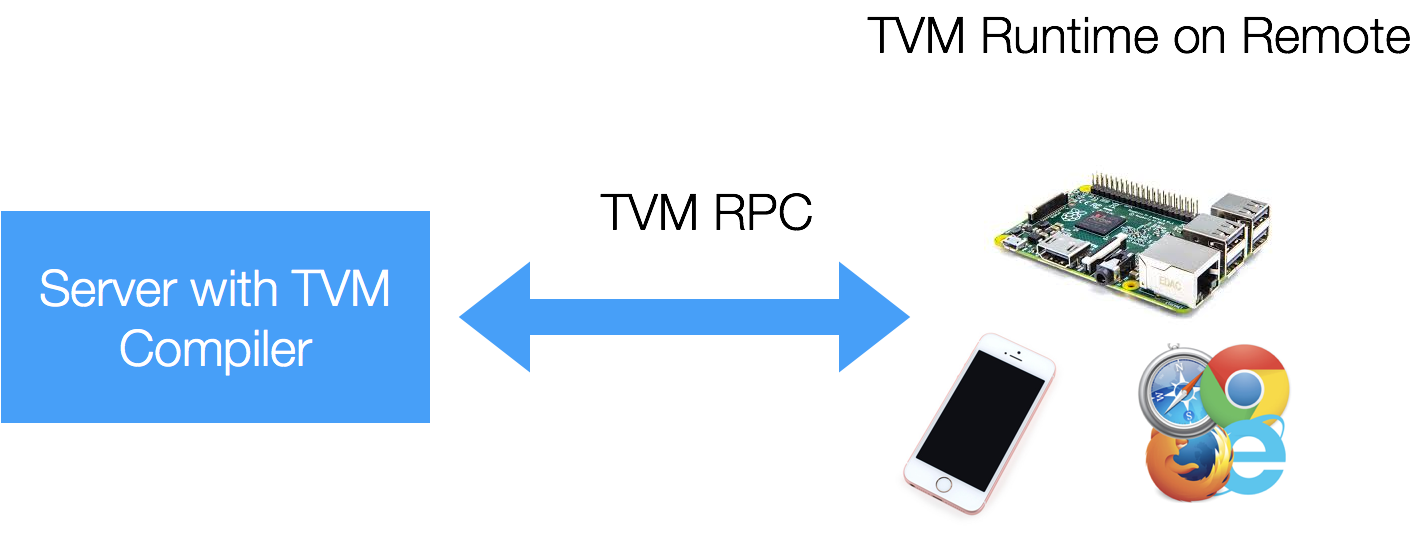
TVM采用C/S模式进行部署,其中在target机器上的部分,被称为TVM Runtime。
TVM Runtime的代码通常比较薄,只需要把host发过来的优化结果执行即可。
官方文档:
http://tvm.apache.org/docs/dev/runtime.html
TVM Runtime也是BYOC的重要组成部分。
BYOC:Bring Your Own Codegen
https://tvm.apache.org/2020/07/15/how-to-bring-your-own-codegen-to-tvm
How to Bring Your Own Codegen to TVM
这是中文翻译版:
https://zhuanlan.zhihu.com/p/337033822
如何在TVM上集成Codegen(上)
https://zhuanlan.zhihu.com/p/337037547
如何在TVM上集成Codegen(下)
示例:
https://github.com/antkillerfarm/antkillerfarm_crazy/blob/master/python/ml/tvm/pytorch2tvm.py
该示例包含以下内容:
1.如何导入pytorch和tflite的模型。
2.local执行和remote执行。
3.使用print(mod.astext(show_meta_data=False))可以打印相关IR的内容。meta data有的时候包含了权重,打印出来意义不大,反而导致其他有意义的部分,淹没在大量的log中,没法看了。
TVM最近还推出了TVM Web runtime。
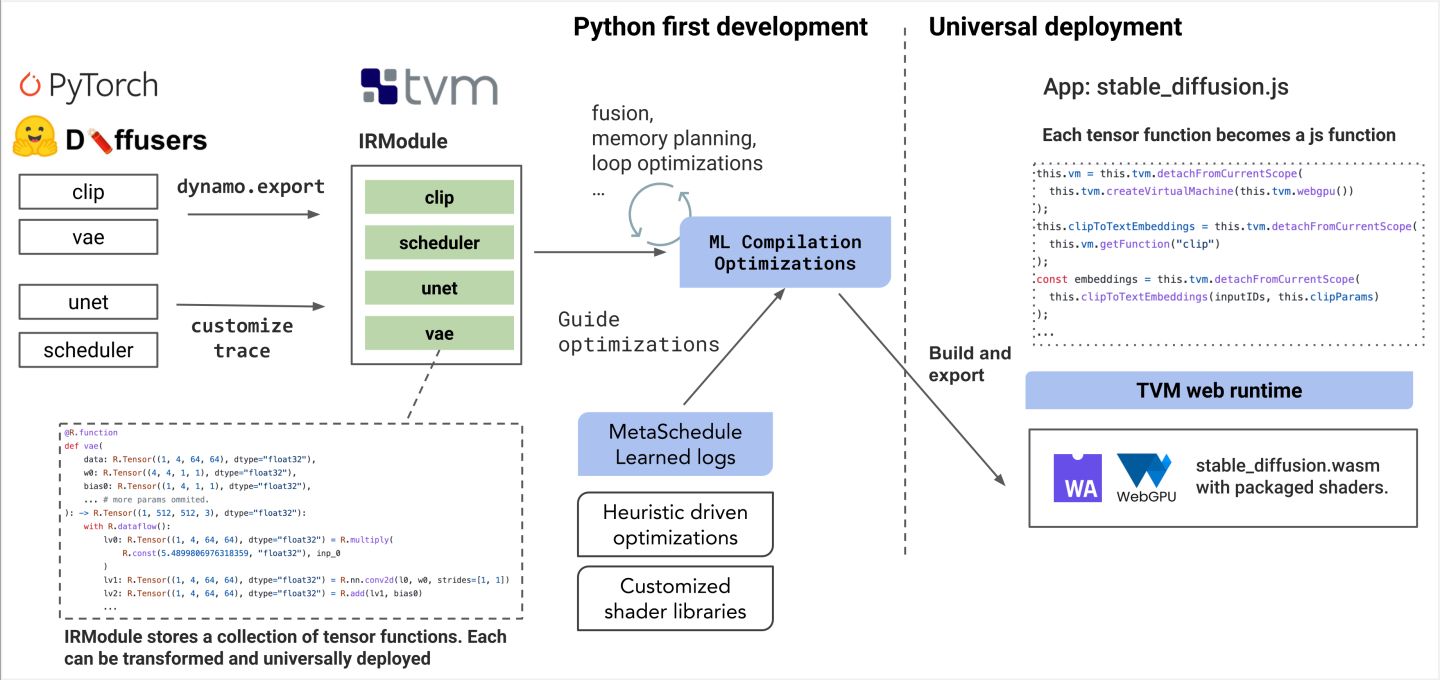
参考:
https://zhuanlan.zhihu.com/p/369981405
部署TVM Runtime
https://zhuanlan.zhihu.com/p/352988283
TVM学习记录——pytorch
https://zhuanlan.zhihu.com/p/612517660
面向Web的机器学习编译突破:纯浏览器运行Stable Diffusion
NNVM
NNVM是一个类似于ONNX、NNEF的中间表示。
官网:
https://github.com/dmlc/nnvm
参考:
https://mp.weixin.qq.com/s/qkvX0rmEe0yQ-BhCmWAXSQ
李沐:AWS开源端到端AI框架编译器NNVM
http://zhengsz.tech/2019/11/05/NNVM-graph-compiler/
TVM/NNVM graph compiler
Relay
Relay是TVM中用来替代NNVM的模块,其本身被认为是NNVM第二代。
官网:
https://tvm.apache.org/docs/arch/relay_intro.html
NNVM本质上只能描述传统的计算图,这属于Data Flow的范畴。但是现在的DL框架越来越灵活,不仅能对数据进行计算,还能对数据进行一定的控制处理,也就是所谓的Control Flow(if-else/ADT matching/递归调用)。
论文:
《The Deep Learning Compiler: A Comprehensive Survey》
参考:
https://zhuanlan.zhihu.com/p/91283238
TVM图编译器Relay简单探究
https://zhuanlan.zhihu.com/p/390087648
Relay IR与Relay Pass
https://mp.weixin.qq.com/s/Kt4xDLo-NRui8Whl0DqcSA
Data Flow和Control Flow
https://zhuanlan.zhihu.com/p/523395133
Relax: TVM的下一代图层级IR
http://zhengsz.tech/2019/11/10/TVM-Relay-graph-compiler/
TVM/Relay graph compiler
Pass
https://tvm.apache.org/docs/how_to/extend_tvm/use_pass_infra.html
和LLVM类似,TVM的Pass也可分为两类:
ModulePass:将整个程序视作一个单元处理的pass。
FunctionPass:以单个函数为作用域的pass, 每个函数间是相互独立的。
FunctionPass包括了Relay层的tvm.relay.transform.FunctionPass和TIR层的tvm.tir.transform.PrimFuncPass。
部分pass:
-
FoldConstant: src/relay/transforms/fold_constant.cc
-
AlterOpLayout: src/relay/transforms/alter_op_layout.cc
-
Legalize: src/relay/transforms/legalize.cc
-
MergeComposite: src/relay/transforms/merge_composite.cc
参考:
https://zhuanlan.zhihu.com/p/378739411
万字长文入门TVM Pass
https://www.cnblogs.com/wujianming-110117/p/14580172.html
TVM Pass IR如何使用
https://zhuanlan.zhihu.com/p/112813859
Relay Pass in TVM
https://zhuanlan.zhihu.com/p/358437531
pass总结
Schedule Primitives
https://tvm.apache.org/docs/how_to/work_with_schedules/schedule_primitives.html
Layout
TVM默认的input layout: NCHW,kernel layout: OIHW。
Backend
python层面:
python/tvm/relay/op/contrib/ethosn.py
@register_pattern_table("ethos-n")
def pattern_table():
@tvm.ir.register_op_attr("nn.max_pool2d", "target.ethos-n")
def max_pool2d(attrs, args):
relay层面:
src/relay/backend/contrib/ethosn
TVM_REGISTER_GLOBAL("relay.ext.ethos-n").set_body_typed(CompileEthosn);
runtime层面:
src/runtime/contrib/ethosn
test:
tests/python/contrib/test_ethosn
代码分析
TVM建立了一套类型系统:
class BaseExprNode : public Object;
class BaseExpr : public ObjectRef;
根据基类,查看实际类型:
XX->checked_type()
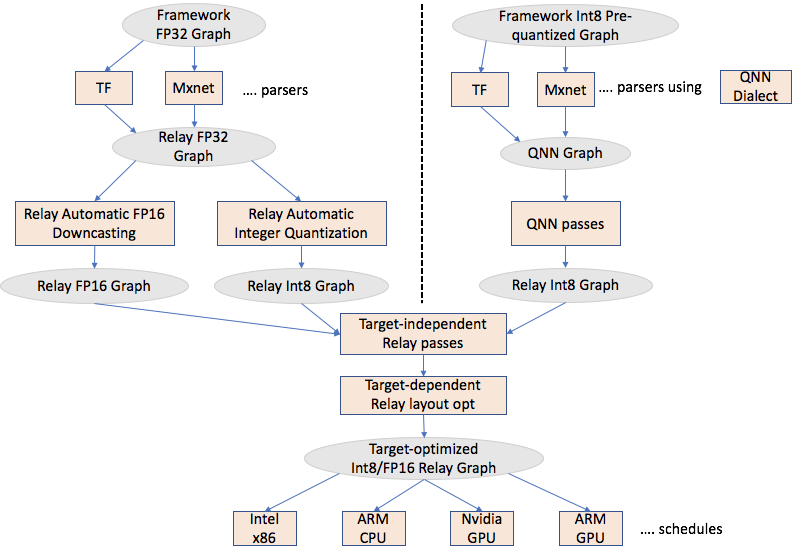
Quantize
microTVM
microTVM可用于那些没有OS的单片机。
官网:
https://tvm.apache.org/docs/arch/microtvm_design.html
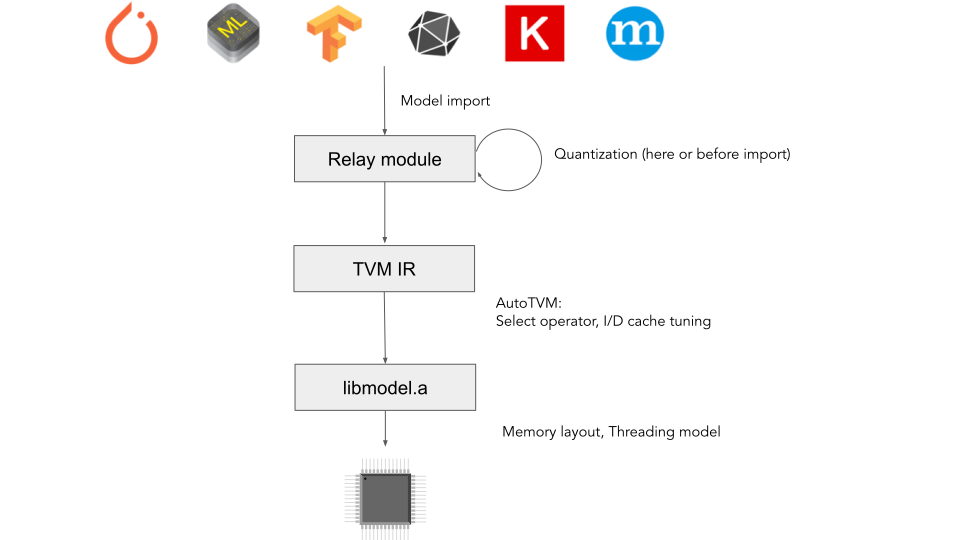
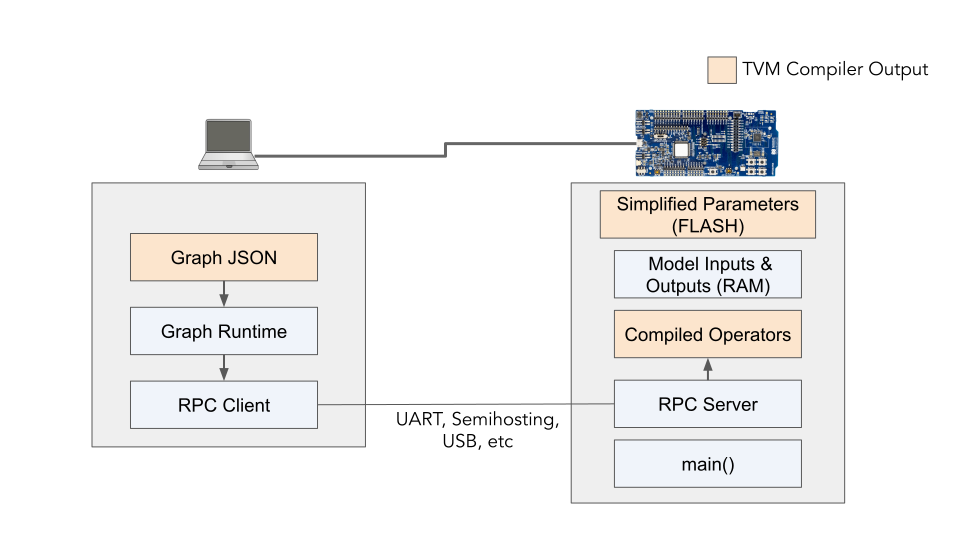
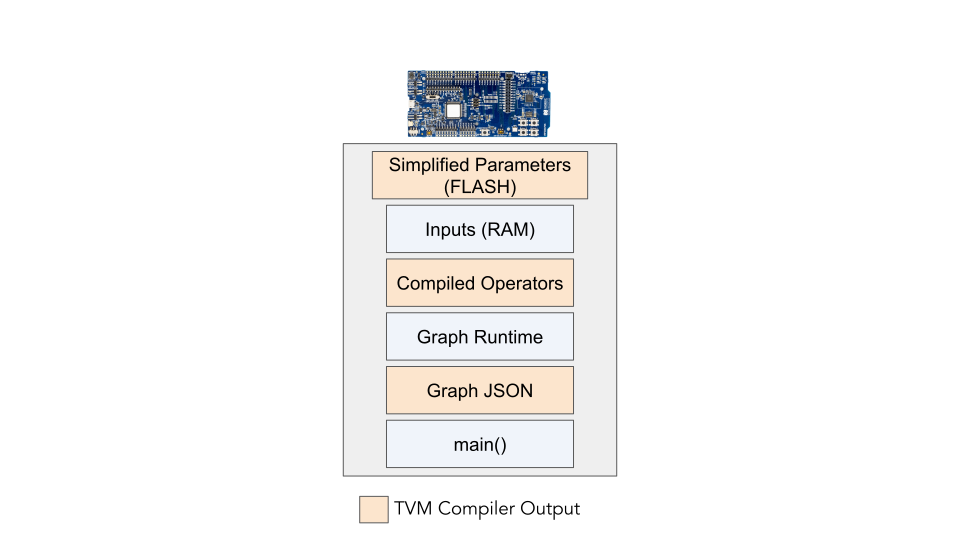
从上面的图来看,microTVM只要在单片机的main函数中启动即可,同时参数也可以放到FLASH上。
PS:这种能直接寻址的FLASH,多半是NOR FLASH。
参考:
https://zhuanlan.zhihu.com/p/337085225
TinyML-TVM是如何驯服Tiny的(上)
https://zhuanlan.zhihu.com/p/337087273
TinyML-TVM是如何驯服Tiny的(下)
VTA
VTA:Versatile Tensor Accelerator
https://mp.weixin.qq.com/s/1oDVo7eGMGYODRd00OxpIw
陈天奇团队推出开源AI芯片栈VTA,降低芯片设计门槛
https://zhuanlan.zhihu.com/p/39635145
VTA: 开源AI芯片栈
auto-scheduler
TVM中的auto-scheduler,包括第一代的AutoTVM、第二代的Ansor、第三代的MetaSchedule。
《Tensor Program Optimization with Probabilistic Programs》
https://mp.weixin.qq.com/s/YVIvdMznb3oatIXqD5a5_A
陈天奇等人提出AutoTVM:让AI来编译优化AI系统底层算子
https://zhuanlan.zhihu.com/p/401120318
谈谈tvm ansor
https://zhuanlan.zhihu.com/p/394765523
AutoScheduler:Ansor
https://blog.csdn.net/jinzhuojun/article/details/121296836
TVM中的auto-scheduling机制(Ansor)学习笔记
技术变革和展望
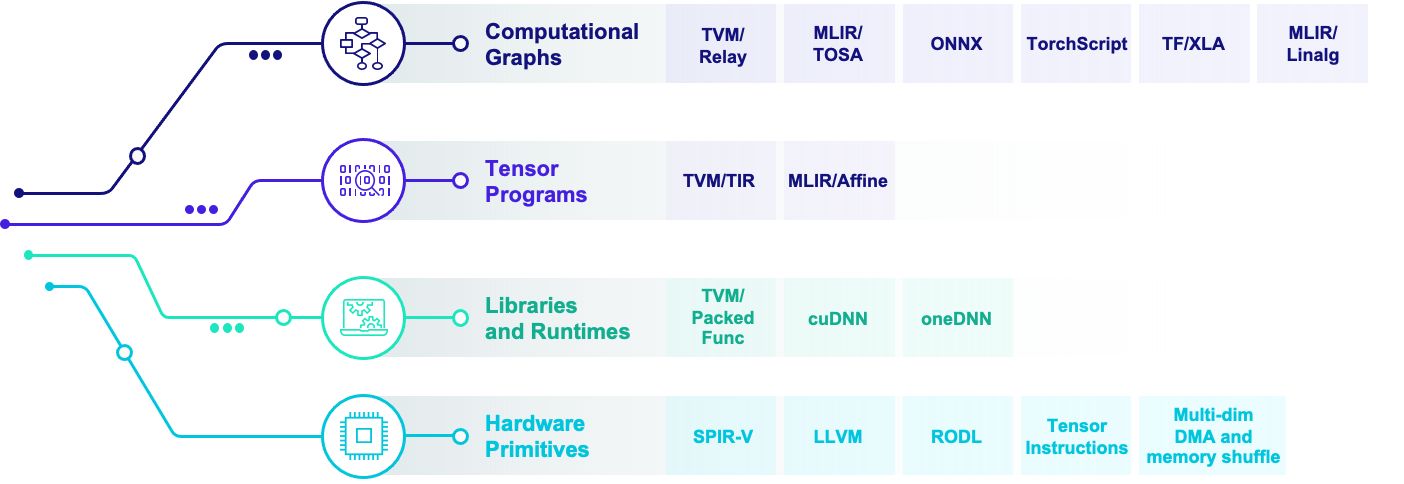
深度学习编译生态围绕着四类抽象展开:
计算图表示(computational graph):计算图可以把深度学习程序表示成DAG(Directed Acyclic Graph),然后进行类似于算子融合,改写,并行等高级优化。Relay, XLA, Torch-MLIR,ONXX 等基本都在这一级别。
张量程序表示(tensor program): 在这个级别我们需要对子图进行循环优化,对于DSA支持还要包含张量化和内存搬移的优化。
算子库和运行环境(library and runtime): 算子库本身依然是我们快速引入专家输入优化性能的方式。同时运行环境快速支持数据结构运行库。
硬件专用指令 (hardware primitive) :专用硬件和可编程深度学习加速器也引入了我们专用硬件张量指令的需求。
目前的整个生态,包括深度学习框架,编译框架(包括基于MLIR,ONNX或者是TVM的解决方案)。大家都遵循一种叫做多层渐进优化(Multi-stage lowering)的方式。这种构建方式的大致思路是我们在每一层抽象中采用一个(有时多个)中间表示。我们会在每一个层级(dialect, abstraction)做一些内部优化,然后把问题丢给下一个层级继续进行优化。
深度学习运行框架和编译框架的两种流派:
一类是以手工算子优化为主的算子库驱动方案。这一类方案一般可以比较容易地让更多的优化专家加入,但是本身也会带来比较多的工程开销。
另一类方案是以自动优化为主的编译方案。编译核心方案往往可以带来更多的自动的效果,但是有时候也比较难以引入领域知识。
https://zhuanlan.zhihu.com/p/446935289
新一代深度学习编译技术变革和展望
https://github.com/mlc-ai/mlc-llm
一个基于TVM的LLM推理引擎
参考
https://zhuanlan.zhihu.com/p/139552817
一篇关于深度学习编译器架构的综述论文
https://www.zhihu.com/question/396105855
针对神经网络的编译器和传统编译器的区别和联系是什么?
https://mp.weixin.qq.com/s/8bXwxYyNjdThlGQQ70cgWQ
TVM:端到端自动深度学习编译器,244页ppt
https://zhuanlan.zhihu.com/p/333706468
TVM学习系列blog
https://zhuanlan.zhihu.com/p/163717035
AI编译优化
https://www.zhihu.com/question/267167829
如何看待Tensor Comprehensions?与TVM有何异同?(这个问题下的答案不多,但基本都是陈天奇、贾扬清之类的大佬)
https://mp.weixin.qq.com/s/irvBbPKENiZX9G_6wh5c-Q
陈天奇等人提出TVM:深度学习自动优化代码生成器
https://mp.weixin.qq.com/s/28n8g_epHsYB0I9GVc_lww
陈天奇团队TVM重磅更新:直接在浏览器使用GPU
https://mp.weixin.qq.com/s/7JGLm-hkCZBNDLA98qvWNA
自动生成硬件优化内核:陈天奇等人发布深度学习编译器TVM
https://mp.weixin.qq.com/s/HquT_mKm7x_rbDGz4Voqpw
阿里巴巴最新实践:TVM+TensorFlow提高神经机器翻译性能
https://zhuanlan.zhihu.com/p/50529704
手把手带你遨游TVM
https://mp.weixin.qq.com/s/z5rsU_uAAaRxgD9YAxDkZA
陈天奇:深度学习编译技术的现状和未来
https://zhuanlan.zhihu.com/p/75203171
如何利用TVM快速实现超越Numpy(MKL)的GEMM
https://zhuanlan.zhihu.com/p/58918363
TVM: Deep Learning模型的优化编译器
https://zhuanlan.zhihu.com/p/87664838
也谈TVM和深度学习编译器
https://mp.weixin.qq.com/s/VE3CySjjS2rTpUDPnKcLTg
陈天奇最新研究:递归模型编译器CORTEX
https://zhuanlan.zhihu.com/p/358585143
深度学习编译器及TVM介绍
https://zhuanlan.zhihu.com/p/360385060
TVM中的scheduler
https://zhuanlan.zhihu.com/p/388452164
tvm or mlir?
https://zhuanlan.zhihu.com/p/428713676
如何在MLIR里面写Pass?
https://zhuanlan.zhihu.com/p/500041871
TVM及深度学习编译器相关论文
http://zhengsz.tech/2019/03/13/TVM%E4%B8%AD%E5%A6%82%E4%BD%95tune%E5%8D%B7%E7%A7%AF/
TVM中如何tune卷积
http://zhengsz.tech/2019/03/16/%E5%9C%A8TVM%E4%B8%AD%E5%86%99in-place%E8%AE%A1%E7%AE%97/
在TVM中写in-place计算

您的打赏,是对我的鼓励
