toolchain » AI Compiler(二)——Triton
2024-04-07 :: 5513 WordsAI Compiler
概述(续)
ML编译器核心问题主要有三部分:auto-tensorize、auto-tiling和auto-schedule。
auto-schedule的问题被polyhedral model部分解决,而auto-tiling的问题形式化后往往会变得极其非线性,所以一直以来都是老大难问题。
过去编译器关注的都是通用处理器上的代码优化问题,合法调度在解空间里非常稠密,只要解决依赖性分析的问题,搜索空间里基本都是合法调度,关键在于调度后程序的性能。而DSA指令的引入,其实将搜索空间中的合法解变得稀疏化了。此时找到合法解本身就是一件很难的事情,合法解集合随着DSA指令的粒度变大而变小。算是在新的历史阶段引入的新问题,即auto-tensorize的问题。
寻找可行解的开放问题,实际上就是标准的SAT问题。
优化问题实际上是软硬件协同完成的,DSA指令优化一部分(manual-tiling和manual-schedule),编译器优化一部分(auto-tiling和auto-schedule)。
auto-tensorize解决的终极问题其实就是判断任意两段标量代码,完成的是不是同一件事。这样我只要把后端指令或者库函数也用代码描述一下功能,就可以在前端代码里寻找可以和这段指令功能描述一致的代码片段,从而完成替换,自动利用起后端指令或者库函数。
这里实际有两个问题:求可行解和求最优解。
目标:即使一个算子没写,编译器也能直接用起硬件的新指令提升效率,而算子解决的是关键应用的性能问题。
现在的AI软件栈体系里面通常包含了算子编译器和图编译器两层。
两者主要的区别是数据依赖的处理方式不同。算子编译器和传统编译器非常接近,是通过load/store的方式进行编程的,图编译器一个很显著的特点是类似数据流的执行方式,显式定义了数据依赖关系,从而把数据依赖建模成通信。
算子编译器针对的是share memory的体系,而图编译器针对的是distributed memory体系。
而我们现阶段的硬件形态,通常是局部share memory,全局distributed memory,从而产生了目前图编译器在上,算子编译器在下的局面。
share memory对软件是非常友好的,但最大的困难在于硬件scale-out时的memory wall非常严重。像nv gpu就需要比较大的代价来通过一个crossbar,来实现各个流处理器到gddr的数据通路。
而distribute memory要scale-out就非常容易了,基本就是复制粘贴了。但复杂性只能被转移,可以因为设计做得不好而创造出来,但没法被消灭。靠distribute memory进行scale-out其实把复杂性都转移到图编译问题上了。
当我们把越来越多的算子从一个share memory的大核上重构到一堆2d-mesh distribute memory的小核上来利用这种新众核的性能。原来的auto-schedule和auto-tiling问题的复杂性则迁移到了auto-placement和auto-routing上。
placement和routing在EDA领域已经有非常充分的探索,但到今天也没脱离启发式和图划分算法这一类没有办法的办法。相比之下,基于share memory体系的编译优化,至少发展出了polyhedral model等相对更形式化和高效的求解方法。
分布式框架考虑的是跨核跨节点的分布式问题,不过对于众核这种核内分布式也有一定参考意义。
scale问题,在分布式训练的情况下,64、256、1024个分布式节点已经属于很大规模的情况了,新众核很容易就scale成上百万个核(比如dojo的集群就有上百万个核)。
这些策略背后拓扑的假设,大多数分布式并行训练的策略其实对节点通信的不对称性考虑是比较粗放的,对应的最优硬件拓扑要么是全相连要么是ring。而2d-mesh上不同距离的节点通信延迟差距会非常明显,粗放的管理会导致很严重的性能问题。同时,还有途经流量负载的问题耦合在里面。
硬件视角下很容易把软件这边当做一个只要有优化机会就都能抓住的万金油。软件视角下又很容易把硬件理解为不管怎样都能每年自动提性能。
https://zhuanlan.zhihu.com/p/409418796
专用架构与AI软件栈(3)
https://zhuanlan.zhihu.com/p/439455295
专用架构与AI软件栈(4)
https://zhuanlan.zhihu.com/p/458544969
专用架构与AI软件栈(5)
https://zhuanlan.zhihu.com/p/474668889
专用架构与AI软件栈(6)
https://zhuanlan.zhihu.com/p/432853785
SAT问题简介
https://tvm.hyper.ai/docs/how_to/te_schedules/tensorize
使用Tensorize来利用硬件内联函数
CDFG(Control-Data Flow Graph)把传统CFG(控制流图和DFG(数据流图)合并成一张图。
An MLIR-based Compilation Framework for Control Flow Management on CGRAs
https://mp.weixin.qq.com/s/jjT0x99ht8xtfWmzL-0R1A
深度学习的IR“之争”
https://mp.weixin.qq.com/s/G36IllLOTXXbc4LagbNH9Q
编译器与IR的思考: LLVM IR,SPIR-V到MLIR
https://www.zhihu.com/question/391811802
如何评价TensorFlow开源的新运行时TFRT?
https://zhuanlan.zhihu.com/p/347599203
TFRT的开源代码分析
https://zhuanlan.zhihu.com/p/600622073
AI编译器之后端优化
https://github.com/JYRoy/MLC-Learning
一个Machine Learning Compilation方面的专栏
Triton
OpenAI Triton是一个类似于TVMscript的可以通过python语法去写高性能GPU程序的库。注意不要和NVIDIA Triton搞混了。后者是一个AI推理框架。
NVIDIA Triton Inference Server(此前称为TensorRT Inference Server)能够帮助开发人员和IT/DevOps轻松地在云端、本地数据中心或边缘部署高性能推理服务器。
官网:
https://triton-lang.org/main/index.html
代码:
https://github.com/openai/triton
Triton Dialect:
https://triton-lang.org/main/dialects/TritonDialect.html

CUDA在线程的细粒度上进行编程,Triton是在分块的细粒度上进行编程。
Google有个pallas项目,也就是jax版的triton。
类似的DSL还有Tilelang, CuTeDSL, Mojo, helion, cuTile等。
Triton的目标是只考虑在CUDA生态下的优化,直接考虑要解决的问题就是Pre Fetching,访存合并,Shared Memory的分配与同步,完全放弃了硬件中立。
然而大家发现,Triton的编程模型,反而好像是各种硬件的公约数,如何划分数据块,load到片上,再store回去,在各种硬件架构下都是难搞的问题。
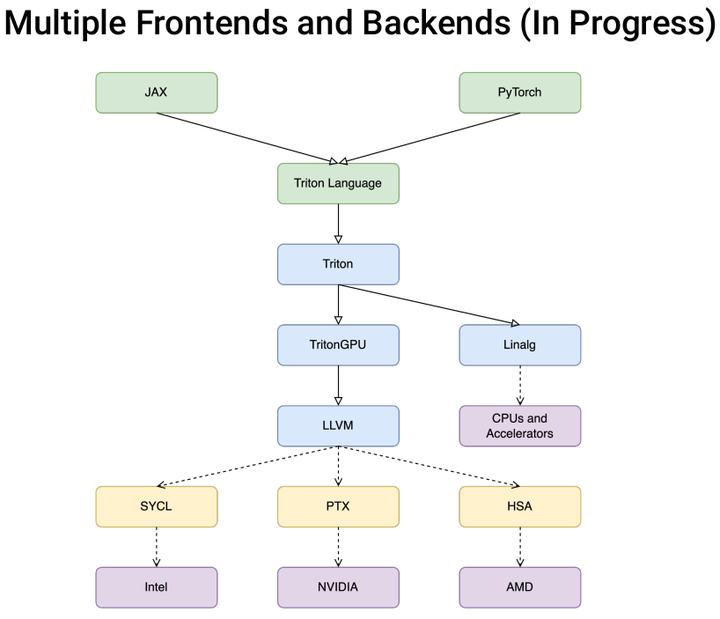
triton-shared是微软开源的一个项目,它为Triton编译器提供了一个共享的中间层(middle-layer)。这个中间层的主要目的是将Triton IR降低到MLIR方言。
代码:
https://github.com/microsoft/triton-shared
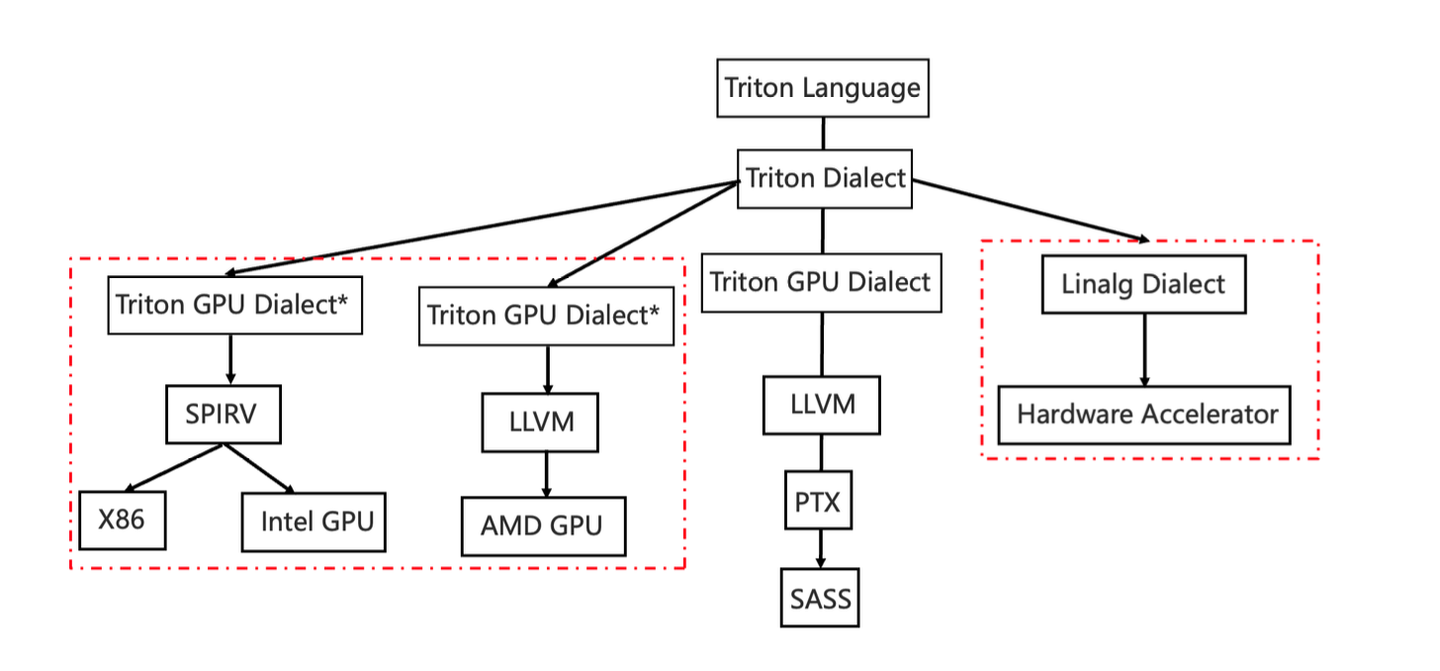
triton-shared其实主要是用来cover最右边的分支,因为Linalg dialect是一个非常重要的dialect,它可以去承接很多不同的backend,在主流一些backend的编译优化环节,都会将Linalg作为主要的dialect,来进行上下游不同dialect之间的转换与对接。
https://github.com/FlagOpen/FlagGems
一个Triton写的算子库
https://github.com/FlagOpen/FlagAttention
一个Triton写的Attention方面的算子库
参考:
https://zhuanlan.zhihu.com/p/394377526
OpenAI开源GPU编程语言Triton,将同时支持N卡和A卡
https://zhuanlan.zhihu.com/p/613244988
谈谈对OpenAI Triton的一些理解
https://blog.csdn.net/kebijuelun/article/details/136343258
OpenAI Triton 入门教程
https://superjomn.github.io/posts/triton-mlir-publish/
OpenAI/Triton MLIR 迁移工作简介
https://pytorch.org/blog/cuda-free-inference-for-llms/
CUDA-Free Inference for LLMs
https://zhuanlan.zhihu.com/p/709844371
一起实现一个Baby Triton
https://www.zhihu.com/column/c_186688444
一个OpenAI/Triton MLIR的专栏
https://tfruan2000.github.io/posts/triton-linalg/
Triton Linalg
https://zhuanlan.zhihu.com/p/666763592
lightllm代码解读番外篇——triton kernel撰写
https://mp.weixin.qq.com/s/FN6EpobpSmWnYeI5G53xUw
深入Triton后端适配:天数GPU的Triton适配及共享内存管理机制
https://zhuanlan.zhihu.com/p/1925309765489230184
Triton SPIR-V后端开发:矩阵乘实现验证
https://zhuanlan.zhihu.com/p/1953522198804398390
国产NPU为啥都使用triton这种方式而不是Cuda的方式来自定义算子?
https://www.zhihu.com/question/1984630179713279606
DSL大战中,谁活了下来?
https://zhuanlan.zhihu.com/p/1993279478114309062
简单triton例子的全部编译过程【trion->ttir->ttgir->llir->ptx->cubin(sass)】
https://www.zhihu.com/question/2008960281838110129
如何看待AMD开源的FlyDSL及当前Python eDSL的现状?
NVFuser
NVFuser是NV专门为Pytorch设计的自动化的GPU代码生成器。
AKG
AKG是面向华为昇腾AI处理器的张量编译器。
官网:
https://gitee.com/mindspore/akg/
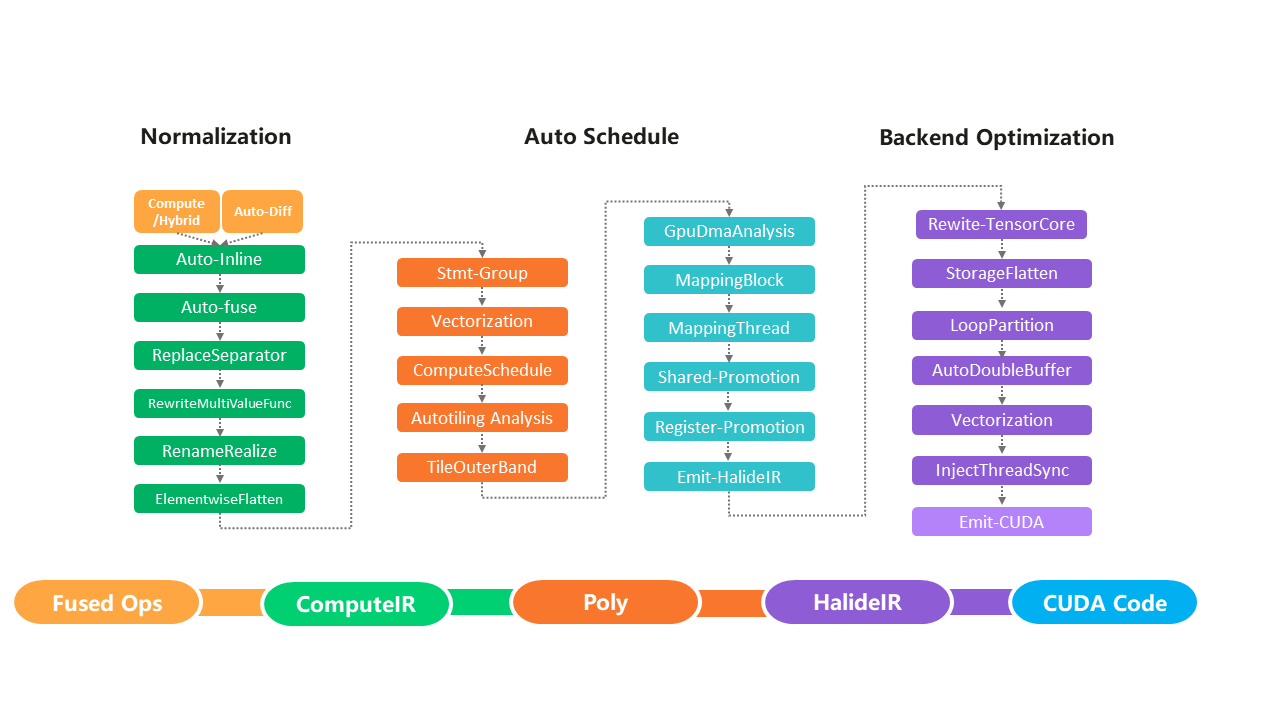
Halide
Halide也是一个高性能的图形DSL+编译器的项目。它影响了后来的TVM、Taichi等计算引擎项目。
如果你想用普通的CPU做加速,又不想去优化算法,那么halide将是非常优秀的选择。唯一要做的,就是把算法用halide重写一遍即可。
Halide采用的计算和调度分离的方案,为后来的Taichi和TVM所采用。
官网:
https://halide-lang.org/
参考:
https://www.zhihu.com/question/294625837
如何评价Halide?
https://zhuanlan.zhihu.com/p/122217135
halide编程技术指南
https://www.zhihu.com/question/479548933
如何学习halide?
Tiramisu
官网:
http://tiramisu-compiler.org/
参考:
https://zhuanlan.zhihu.com/p/363516429
Tiramisu:一种基于Polyheral的深度学习模型编译器
Lift
Lift也是一种并行编程及优化的语言。
官网:
http://www.lift-project.org/
参考:
https://www.zhihu.com/question/313697268
如何评价lift编程语言?

您的打赏,是对我的鼓励
