toolchain » NN中间语言, AI Compiler(一)——概述
2022-08-06 :: 5006 WordsNN中间语言
概述
随着目前DL框架越来越多,如何在框架之间对模型进行相互转换,就成为了工业界的一个大问题。
https://github.com/ysh329/deep-learning-model-convertor
这个网页包含了各种深度框架之间的模型相互转换的工具的列表。从中可以看出ONNX和MMdnn算是目前比较有用的转换工具了。
这类many-to-many工具从实现原理上,主要是将各种模型转换成中间语言(IR,intermediate representation),然后再变换成目标语言。
NNEF
Neural Network Exchange Format是Khronos制定的用于交换NN模型数据的数据格式标准。
官网:
https://www.khronos.org/nnef
ONNX
和NNEF竞争的标准还有微软和Facebook联合推出的Open Neural Network Exchange。
官网:
https://onnx.ai/
代码:
https://github.com/onnx

截止2020.5,ONNX已经获得压倒性的胜利,成为了事实上的标准。
中文指南:
https://zhuanlan.zhihu.com/p/41255090
ONNX–跨框架的模型中间表达框架
修改ONNX模型:
https://github.com/saurabh-shandilya/onnx-utils
ONNX模型除了可以由其他框架生成之外,也可借助ONNX官方的helper API构建。
https://onnx.ai/onnx/api/helper.html
由于这种方法比较繁琐,MS又发明了ONNX Script:
https://github.com/microsoft/onnxscript
参考:
https://cloudblogs.microsoft.com/opensource/2023/08/01/introducing-onnx-script-authoring-onnx-with-the-ease-of-python/
Introducing ONNX Script: Authoring ONNX with the ease of Python
Onnx Optimizer、ONNX Simplifier被誉为onnx的优化利器,其中ONNX Simplifier可以优化常量,Onnx Optimizer可以对节点进行fuse。
ONNX Simplifier:
https://github.com/daquexian/onnx-simplifier
Onnx Optimizer:
https://github.com/onnx/optimizer
参考:
https://zhuanlan.zhihu.com/p/350702340
onnx simplifier和optimizer
参考:
https://mp.weixin.qq.com/s/etSrI8Z3-NWbrqNWIbfzjw
微软Facebook联手发布AI生态系统
https://mp.weixin.qq.com/s/D5rQ6r3s54PR_esAAu5rhQ
开源一年多的模型交换格式ONNX,已经一统框架江湖了?
https://blog.csdn.net/xxradon/article/details/104715524
onnx模型如何增加或者去除里面node,即修改图方法
https://mp.weixin.qq.com/s/H1tDcmrg0vTcSw9PgpgIIQ
ONNX初探
https://mp.weixin.qq.com/s/_iNhfZNR5-swXLhHKjYRkQ
ONNX再探
https://mp.weixin.qq.com/s/naJwpmXm7Yl3pxEFYiGf-g
深度探索ONNX模型部署
https://zhuanlan.zhihu.com/p/32711259
从NNVM和ONNX看AI芯片的基础运算算子
MMdnn
MMdnn是微软推出的工具集,也是目前功能最强的工具集。
官网:
https://github.com/Microsoft/MMdnn
AI Compiler
教程
https://dlsyscourse.org/lectures/
10-414/714: Deep Learning Systems
https://mlc.ai/
Machine Learning Compilation
这两个课程都是陈天奇主讲的。
概述
我们在《NN中间语言》一文中已经展示了各种中间语言/接口。
从目前来看,DL方面的中间语言/接口/编译器架构实在太多了。下图是Google(2019.4)推出的MLIR对自家各种优化技术的总结,这里还不包括其他家的相关技术。
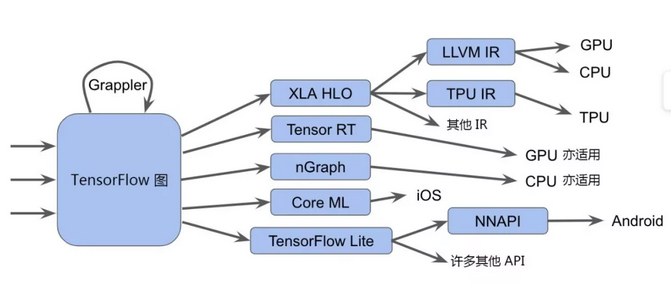
从趋势来看,仅仅纠结于各种模型的导入/导出已经不再是最佳的做法,AI compiler才是王道。
某网友的评价:
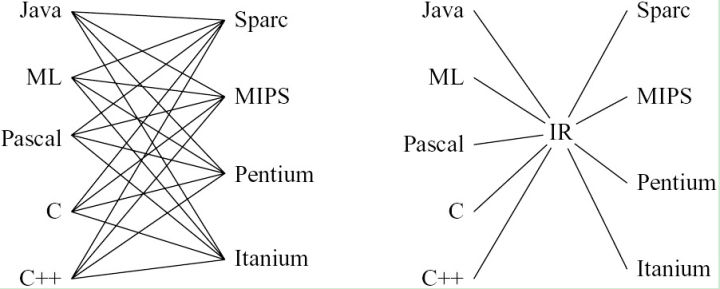
Tensorflow Model / ONNX / Caffe Model / … —> DL IR (nGraph IR / *.IR) —> LLVM IR —> CPU JIT / GPU / …
如果把前面的Model看成一种语言或者DSL,就是DSL —> DL IR —> LLVM IR —> Target,然后你就在中间层疯狂的做优化,编译器优化开发也是这样做的。
在LLVM IR出现以前,很多编译器都有几层的IR表示,比如 C++ —> 1st IR —> OPT —> 2nd IR —> …. -> Target,只是LLVM出来以后,LLVM IR做了统一,编译器变为了 C++ —> LLVM IR —> OPT —> LLVM IR —> Target
Google(2020.9)又推出了IREE项目,定位和TVM类似。
官网:
https://github.com/openxla/iree

同期,还有一个叫做TFRT的项目:
https://github.com/tensorflow/runtime
High-level IR(图层IR),如XLA的HLO,TVM的Relay IR以及MindSpore的MindIR等,重点关注非循环相关的优化。除了传统编译器中常见的常量折叠、代数化简、公共子表达式等优化外,还会完成Layout转换,算子融合等优化,通过分析和优化现有网络计算图逻辑,对原有计算逻辑进行拆分、重组、融合等操作,以减少算子执行间隙的开销并且提升设备计算资源利用率,从而实现网络整体执行时间的优化。
Low-level IR,如TVM的TIR,HalideIR,以及isl schedule tree等。针对Low-level IR主要有循环变换、循环切分等调度相关的优化,与硬件intrinsic映射、内存分配等后端pass优化。其中,当前的自动调度优化主要包含了基于搜索的自动调度优化(如ansor)和基于polyhedral编译技术的自动调度优化(如TC和MindAKG)。
https://zhuanlan.zhihu.com/p/305546437
AI编译优化–Dynamic Shape Compiler
图算融合:大算子怎样打开、小算子如何重新融合。
https://zhuanlan.zhihu.com/p/629048218
AI编译器和推理引擎的区别
编译器不是万能的。一定程度上很多架构师都喜欢画大饼,用一个编译器衔接上下各种碎片化的前端和后端,似乎这样整个架构图就一切都舒爽了,啥都能自由支持,而且自动优化。但实际上编译器的能力是非常有限的。且不说AI编译器这种才几年探索的新兴事物,HPC领域卷了几十年了,要是编译器优化能力可以依赖,那还有blas库啥事呢?
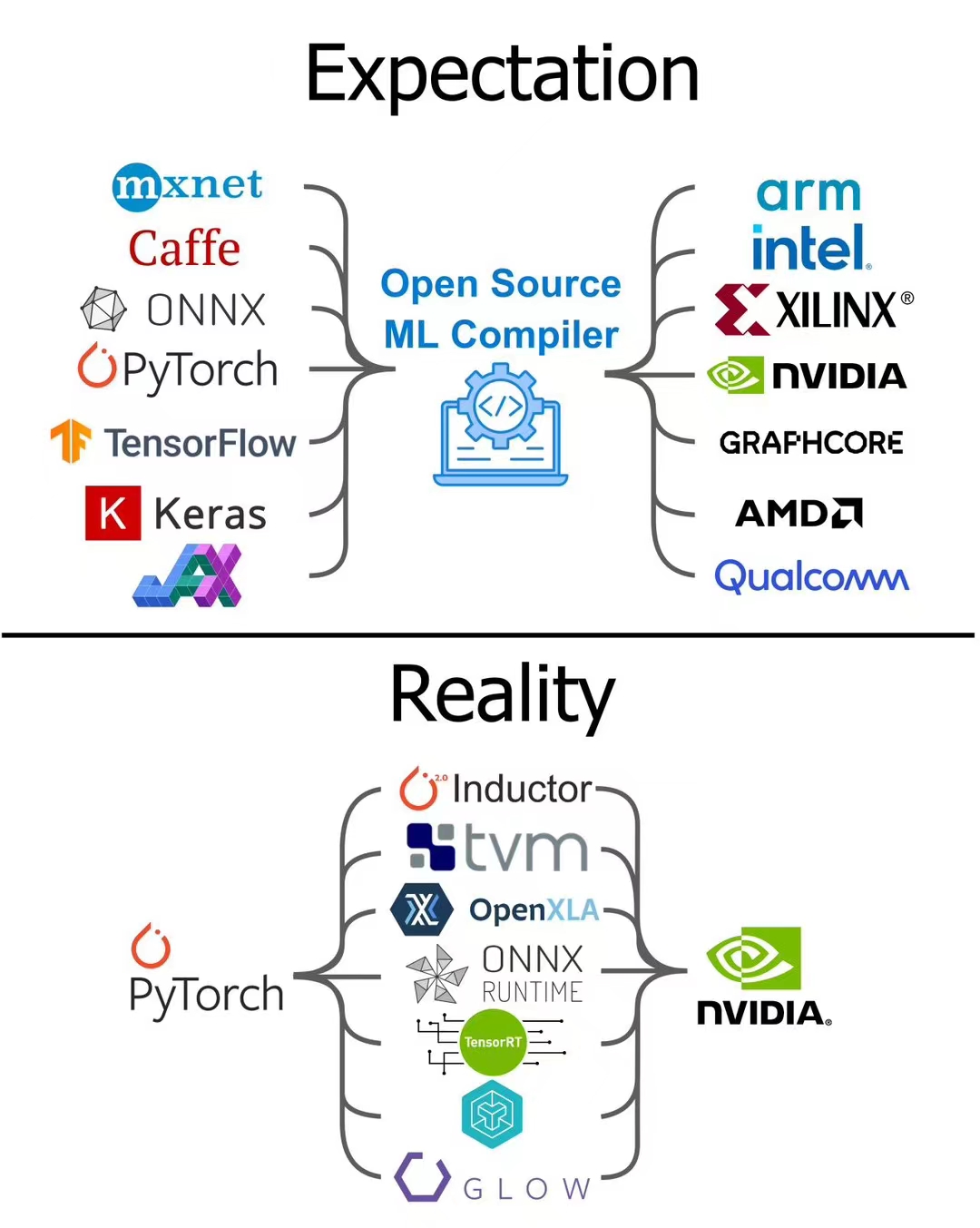
AI的软件栈基本可以简单分类为两类。
一类是希望找一个稳定的中间层IR,这个IR可以是硬件层面的virtual ISA,可以是library层面的一层稳定的API,也可以是一个算子库,甚至是深度学习框架。希望在剧烈变化的前端和后端之间找到一个稳定不变的层来解耦合。
ONNX坚持到今天,算子集合短短几年已经更新了十几代了,而且至今没能做到两个主流框架pytorch和tensorflow的全覆盖,可以说是一个标准的“试图用一个大一统的框架统一现在的n个框架,最后导致出现了n+1个框架”的典范了。
虽然chris在编译器黄金时代的演讲中讲了很多解决碎片化的问题,尤其提到了要从O(前端x后端)变成O(前端+后端)的工程量,但MLIR实际解决的是编译器基础设施的模块化和复用,而不是IR的复用,没有改变O(前端x后端),只是让这个大O的常数变小了一些。碎片化还是存在,只是换了个形式,变成MLIR dialect的碎片化。
MLIR一定程度上放弃了这种完备性的追求,转而躺平让大家随意在不同层之间打洞写conversion。
MLIR本身更接近一个库的定位而非生态。大多数参与者贡献的dialect和conversion都是在自己的闭环内,甚至tf团队自己的iree也是如此,大多算子基本bypass了所有core dialect。那么此时新的使用者其实很难复用其他人的闭环dialect,你的大多数dialect往往也只有你自己用,无法带来用的人越多大家都爽的优点。而大家建立自己闭环不是不配合建生态,毕竟high-level的dialect没有完备性,大家的需求也不一样,导致了大家都有对自己更有利的dialect设计和取舍。
另一类是尝试做算子编译器,负责自动算子生成。
Halide这一类核心在于解耦计算和调度,然后定义了一系列调度原语把调度优化的空间给手工建模出来,然后计算写一遍,调度可以手工tune或者通过一些算法来搜索。然而调度不仅和硬件强相关,也和计算的形式强相关,因此写调度的时候还是要针对特定计算和特定后端硬件来写调度,仍然是一个O(前端*后端)的碎片化状况。
现在大大小小的AI编译器团队非常多,其实真正搞编译器算法的人非常少也非常难招,而写算子的门槛则相对低很多,招人相对容易得多,很多团队围绕TVM进行工具链开发建设,可以招大量写算子的人来覆盖碎片化的工程量,从产业实践上来讲也算是一条不错的路径。MLIR其实也是类似的路径,不过是从写调度换成写lower通路的各种pass,都比较容易堆人力,本质上还是尝试用人力战胜复杂性。
https://zhuanlan.zhihu.com/p/394102530
专用架构与AI软件栈(2)
做深度学习编译器的人,可能是主要写算子库的,可能是主要做循环优化算法的,可能是主要做计算图优化的,也可能是主要做分布式调度的。
term rewrite,匹配程序IR中的某种特征,并按照预设的模板进行替换,从而达到对程序进行变形的目的。有了这种机制我们就可以通过增加term rewrite rule来不断覆盖各种手工变换代码的经验。这种方法扩展性很好,遇到各种corner case很容易添加rule来workaround。当然这种方式在变换空间较大的时候会变得很低效,可能需要无穷无尽的rule才能覆盖。
从完备性的角度来看,越底层的表示越完备,越上层的完备性越差,因为上层表示的基本要素一定是底层表示的某种粗粒度的结构,比如for循环和if-else分支,到底层都是jump指令,jump按照某种结构去组织就形成了for循环和if-else分支,但在底层要重建上层这种结构的语义就会比较困难,因为lower下来再进行一定的等价变换进行优化,上层的结构就很难重新发掘出来了。所以大家一直在讲lowering很容易,rising或者叫lifting很难。
这种粗粒度的表达通常是缺乏完备性的,两组不同的粗粒度算子集可能不一定能轻松实现相互转换。所以这个问题并不是软件在山顶,硬件指令在半山腰,而是硬件指令在另一座山的半山腰。

您的打赏,是对我的鼓励
