Segmentation » 语义分割(四)——SAM, 语义分割进阶
2020-07-28 :: 6852 Words花式U-NET
U-NET的另类用法(续)
这方面的数据集主要有:
- CCMixter:
https://members.loria.fr/ALiutkus/kam/
这个数据集的每个文件夹下有3个wav文件:
source-01.wav:纯音乐。
source-02.wav:人声。
mix.wav:混合后的声音。
- MUSDB18:
https://sigsep.github.io/datasets/musdb.html
类似这样用法的还有:
《Learning to See in the Dark》
代码:
https://github.com/cchen156/Learning-to-See-in-the-Dark
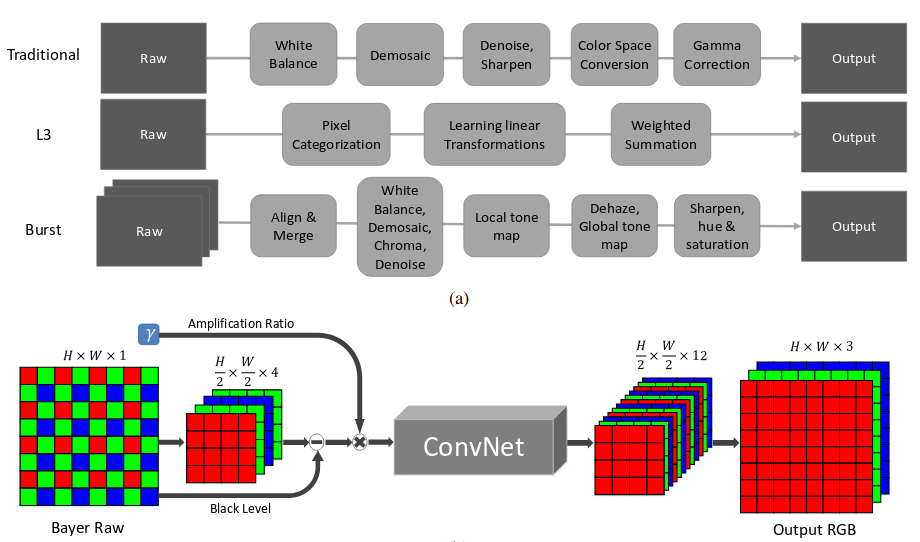
如上图所示,该文的目标是使用神经网络替换传统的相机ISP过程。由于输入和输出的尺寸等大,照例又到了U-NET出场的时间。
为了实现这一目标,作者收集了一个新的原始图像数据集,在弱光条件下快速曝光。同时,每个微光图像都有相应的长曝光、高质量的参考图像。
SID算是这类问题的里程碑作品,后续还有:
《YOLO in the Dark》
这是将YOLO用于黑暗图像的目标检测的论文。
参考:
https://mp.weixin.qq.com/s/cr0BJLkyN2kW35-w1pebGQ
学习在黑暗中看世界(Learning to See in the Dark)
https://mp.weixin.qq.com/s/iv4ixoXvyPMp60hp2XhK8A
港中文&腾讯优图等提出:暗光下的图像增强
https://mp.weixin.qq.com/s/p2Vr9Y9vl4BlHZB_DIzTbw
基于深度学习的低光照图像增强方法总结(2017-2019)
https://mp.weixin.qq.com/s/E20ucf5bfexKYH4R7zK-WA
最好用的音轨分离软件spleeter
https://mp.weixin.qq.com/s/ONoBoCNFzoPh-rsVuiD6Jg
YOLO in the Dark让黑夜里的目标检测成为可能
https://mp.weixin.qq.com/s/6qyl0m0HHCqGkdHzacLkfA
字节跳动这项研究火了:基于残差UNet架构,一键分离伴奏和人声
参考
U-Net其实还具有另一个层面的代表性:即结构简单有效的网络往往在不同任务中具有更好的鲁棒性。这种高度的可复用性相比几个点的提升而言是更被企业看重的。
https://www.zhihu.com/question/269914775
Unet神经网络为什么会在医学图像分割表现好?
https://mp.weixin.qq.com/s?__biz=MzIwMTE1NjQxMQ==&mid=2247488752&idx=3&sn=23f223fb82c64c14eb925ebd19d16fc5
图像分割中的深度学习:U-Net体系结构
https://zhuanlan.zhihu.com/p/55193930
Attention U-Net论文笔记
https://mp.weixin.qq.com/s/cumrVJPexV_BtCKoUprrLA
当UNet遇见ResNet会发生什么?
https://mp.weixin.qq.com/s/5rqCc_ozJNNFb1zYs8JOQQ
总结U-Net网络及他的变体
https://zhuanlan.zhihu.com/p/44958351
研习U-Net
https://mp.weixin.qq.com/s/_T-UP5aU88MfkSTUGBa-TQ
使用注意力机制来做医学图像分割的解释和Pytorch实现
https://zhuanlan.zhihu.com/p/159173338
FCN、Unet、Unet++医学图像分割那点事儿
https://mp.weixin.qq.com/s/TmR9TiB9cfvYGIhQTlctRQ
医学图像分割:UNet++
https://mp.weixin.qq.com/s/21h62T0Ig5gubVLwyLsdbg
U-Net Family方法汇总
https://mp.weixin.qq.com/s/d1mf-8c-mX5hRfH_FLlJIQ
医学图像语义分割最佳方法的全面比较:UNet和UNet++
https://mp.weixin.qq.com/s/w4EivVcZEA5JCdxYYAUOfA
Transformer-Unet:如何用Transformer一步一步改进Unet
SAM
SAM(Segment Anything Model)是Meta 2023年4月的作品。
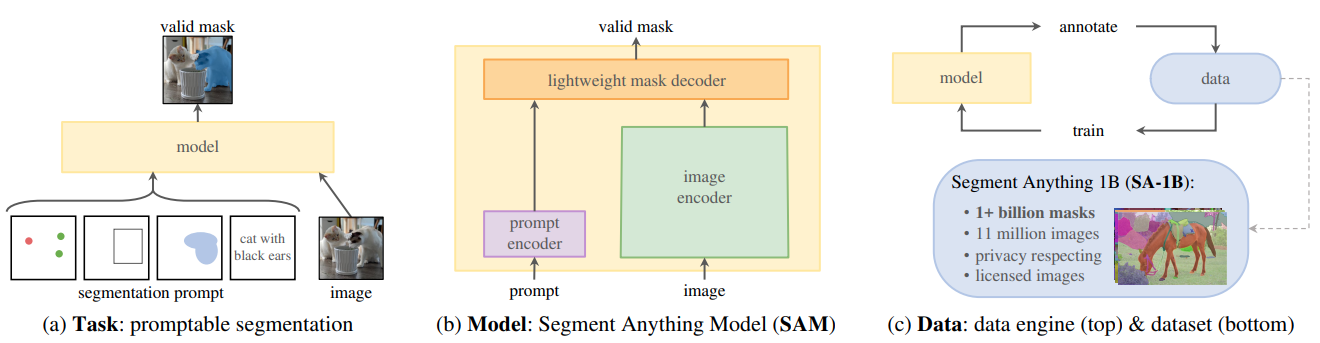
从网络结构来说,SAM除了引入了目前流行的LLM之外,其他部分只能算中规中矩。唯一厉害的地方是它的数据集。
Segment Anything 10 Billion Mask (SA-1B) 数据集是迄今为止最大的有标注分割数据集。它专为高级分割模型的开发和评估而设计。
2024年,Meta又推出了SAM2,用于视频的语义分割任务。
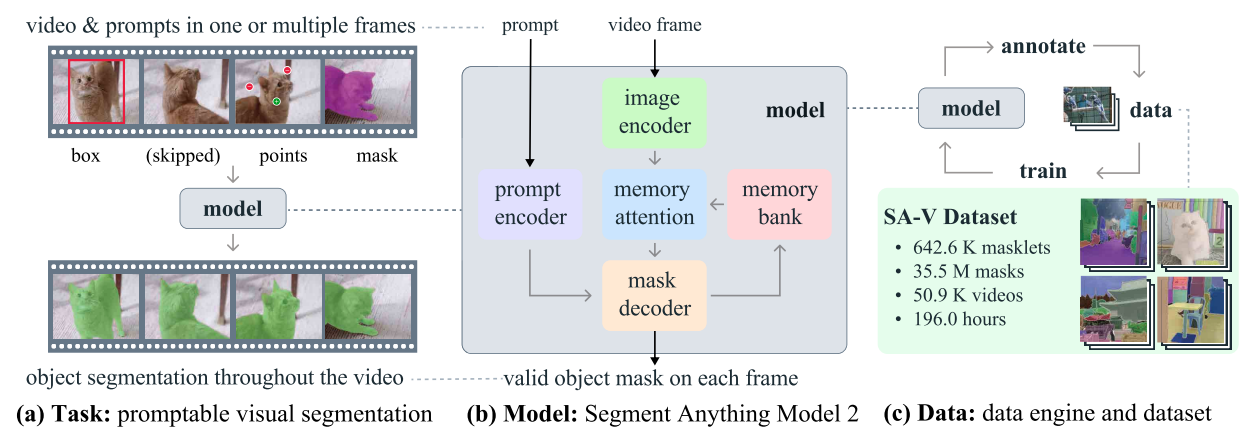
SAM2首先在SA-1B上进行预训练,然后在SA-V(SA-1B的一个子集,占SA-1B 10%的数据),以及DAVIS,YouTube,MOSE数据集上进行完全的训练。
还采用了视频数据(多帧)和静态图像(单帧)交替训练的策略。
参考:
https://blog.csdn.net/GarryWang1248/article/details/135122569
一文了解视觉分割新SOTA: SAM (Segment Anything Model)
https://blog.csdn.net/qq_36104364/article/details/133101952
Segment Anything Model(SAM)分割一切大模型相关论文和项目介绍
https://blog.csdn.net/qq_41234663/article/details/140796308
SAM 2:Segment Anything in Images and Videos
https://blog.csdn.net/v_JULY_v/article/details/131503971
图像分割的大变革:从SAM(分割一切)、FastSAM、MobileSAM到SAM2
语义分割进阶
https://mp.weixin.qq.com/s/_q8N8keNpcD-jXLrRd_8dw
深度学习时代下的语义分割综述
https://mp.weixin.qq.com/s/7EMDH-vuNCOHWmbpyWA3ow
基于深度学习的语义分割综述
https://zhuanlan.zhihu.com/p/412675982
实例分割综述总结综合整理版
https://mp.weixin.qq.com/s/IO4cUTgcFO9hCMT9hTCXiQ
图像分割2020总结:结构,损失函数,数据集和框架
https://mp.weixin.qq.com/s/YkFEXeVI7XAyvhGcO91m3w
2020年5篇图像分割算法最佳综述
https://blog.csdn.net/yorkhunter/article/details/104057159
arXiv综述论文“Image Segmentation Using Deep Learning: A Survey”
https://mp.weixin.qq.com/s/BSJ-F_Inp1-eHxSJDsQ3AQ
12篇文章带你逛遍主流分割网络
https://mp.weixin.qq.com/s/cANlqQAI-A2mC9vnd3imQA
Instance-Aware图像语义分割
https://mp.weixin.qq.com/s/v_TLYYq6cFWuwR9tXM8m-A
如何通过CRF-RNN模型实现图像语义分割任务
https://mp.weixin.qq.com/s/ceCC7Q6yr0QKESeZXi6lWQ
堆叠解卷积网络实现图像语义分割顶尖效果
https://mp.weixin.qq.com/s/V4_euZRcyyxeimXAA_waAg
贾佳亚:最有效的COCO物体分割算法
https://mp.weixin.qq.com/s/M1Oo4ST2aspgZF8UeSUDww
如何妙笔勾檀妆:像素级语义理解
https://www.zhihu.com/question/390783647
语义分割该如何走下去?
https://mp.weixin.qq.com/s/xalo2XtKtzR5tA_dPFzaJw
一文介绍3篇无需Proposal的实例分割论文
https://mp.weixin.qq.com/s/BL1xZ_YuuPe9frIc9E1fkA
南开大学提出新物体分割评价指标
https://mp.weixin.qq.com/s/3rfZUhio4Bk1RUGkEk5xoQ
ETH Zurich提出新型网络“ROAD-Net”,解决语义分割域适配问题
https://mp.weixin.qq.com/s/qMLCi-CghxvTcwyPnvFxnQ
ConvCRF:一种结合条件随机场与CNN的高效语义分割方法
https://mp.weixin.qq.com/s/deepxMWCpIEe3jk_kanfMg
金字塔注意力网络:一种利用底层像素与高级特征的语义分割网络
https://mp.weixin.qq.com/s/5n3jpvv_LxnHB0w4hsCEzQ
NVIDIA ECCV18论文:超像素采样网络助力语义分割与光流估计
https://mp.weixin.qq.com/s/MiChpWim5pGlRj88rcQtaA
谷歌等祭出图像语义理解分割神器,PS再也不用专业设计师!
https://mp.weixin.qq.com/s/J6UMzWSpcmSQVGwWKtm2Hw
UC伯克利提出基于自适应相似场的语义分割
https://zhuanlan.zhihu.com/p/43774180
提升密集预测的平滑的空洞卷积
https://mp.weixin.qq.com/s/sjD36kUDQ5iCmIKpR8_rlA
双重注意力网络:中科院自动化所提出新的自然场景图像分割框架
https://mp.weixin.qq.com/s/Sn3N8IxHtgp53Y0VLIPJCQ
17毫秒每帧!实时语义分割与深度估计
https://mp.weixin.qq.com/s/iNz82GUULxDndBIiGSArmQ
新开源!实时语义分割算法Light-Weight RefineNet
https://mp.weixin.qq.com/s/2QBifDubR5mMoJNKkdBNIw
多分辨率特征融合—RefineNet
https://mp.weixin.qq.com/s/1wqguIqDS4FNsS67Yj77Qw
牛津大学&Emotech首次严谨评估语义分割模型对对抗攻击的鲁棒性
https://mp.weixin.qq.com/s/EzfvKzs8Ue8i9x9TFgZ-CQ
爱奇艺蒙版AI:弹幕穿人过,爱豆心中坐
https://mp.weixin.qq.com/s/19uMhoNXEygLRTYT2PbsYQ
图像分割技术介绍
https://mp.weixin.qq.com/s/-wwDenAWRGCvJmprxsl15Q
基于多特征地图和深度学习的实时交通场景分割
https://mp.weixin.qq.com/s/ygWCfLnakHIwLVk7hRAKNg
全景分割任务介绍及其最新进展
https://mp.weixin.qq.com/s/ZN9ZYPTcgVP2c9mCx9Ox3g
全景分割这一年,端到端之路
https://mp.weixin.qq.com/s/x95XWQW2euTEcUW5vkIEoA
何恺明组又出神作!最新论文提出全景分割新方法(Panoptic FPN)
https://zhuanlan.zhihu.com/p/54510782
DANet论文笔记
https://www.zhihu.com/question/272988870
有关语义分割的奇技淫巧有哪些?
https://zhuanlan.zhihu.com/p/55263898
语义分割江湖的那些事儿——从旷视说起
https://mp.weixin.qq.com/s/x6MJqCz3Yvcbc9onEO8OMQ
语义分割:context relation
https://mp.weixin.qq.com/s/eLU-YNvV_QGc8HDK15P7Og
Fast-OCNet:更快更好的OCNet
https://zhuanlan.zhihu.com/p/56887843
MIT和Google等提出:新全景分割算法DeeperLab
https://mp.weixin.qq.com/s/1tohID6SM3weS476XU5okw
全景分割:Attention-guided Unified Network
https://mp.weixin.qq.com/s/ilQzQ-5RyiOYzS0RRMihLg
语义分割原理与CNN架构变迁
https://zhuanlan.zhihu.com/p/59141570
漫谈全景分割
https://mp.weixin.qq.com/s/fSaBskCxMkNwVXDtCI7ZZg
Decoders对于语义分割的重要性
https://mp.weixin.qq.com/s/eackv0HypWm3mTW9OAHv8g
旷视实时语义分割技术DFANet:高清虚化无需双摄
https://zhuanlan.zhihu.com/p/62652145
加州大学提出:实时实例分割算法YOLACT,可达33 FPS/30mAP!现已开源!
https://mp.weixin.qq.com/s/i6Qj5YyjLINxHSYuHckKzg
YOLACT++:更强的实时实例分割网络,可达33.5 FPS/34.1mAP!
https://mp.weixin.qq.com/s/27nzD9swpAcKfIv8CgvWJw
YOLACT: 首个实时one-stage实例分割模型,29.8mAP/33.5fps
https://mp.weixin.qq.com/s/Lz0Gk-1yDC4S9IQDcocxeA
YOLACT++: 实时实例分割,从29.8mAP/33.5fps到34.1mAP/33.5fps
https://mp.weixin.qq.com/s/8I7Lm5DMkVVlvw8v1L_HBA
多感受野的金字塔结构—PSPNet
https://mp.weixin.qq.com/s/TNHTvXmefRBlc6zfHW7C8A
全局特征与局部特征的交响曲—ParseNet
https://mp.weixin.qq.com/s/riS79dU5Zpzsl8vB64sPIg
BRNN下的RGB-D分割—LSTM-CF
https://zhuanlan.zhihu.com/p/67423280
无监督域适应语义分割
https://mp.weixin.qq.com/s/XTTzAkgVF-WMJT7IYWxJYg
病理图像的全景分割
https://mp.weixin.qq.com/s/HJzbMoCa7GenNm78sz7YAg
全景分割是什么?
https://mp.weixin.qq.com/s/PUHytS_nLKPjlrv8RYxo8A
一文看懂实时语义分割
https://zhuanlan.zhihu.com/p/77834369
语义分割中的Attention和低秩重建
https://mp.weixin.qq.com/s/wAWB2SLaqD2SmP9-j0Ut7g
速度提升一倍,无需实例掩码预测即可实现全景分割
https://mp.weixin.qq.com/s/LZNla-NKAu8wmi-OaJD8yA
旷视研究院推出可学习的树状滤波器,实现保留结构信息的特征变换
https://mp.weixin.qq.com/s/lTPm229gzV_9RU-aiY-xQg
2019年5篇图像分割算法最佳综述
https://mp.weixin.qq.com/s/n9Xdj5RKGR9cyXXNzxzvSw
基于深度学习的图像分割在高德的实践

您的打赏,是对我的鼓励
