Segmentation » 语义分割(三)——Mask R-CNN, 花式U-NET
2020-07-27 :: 6201 Words语义分割的展望(续)
另外,示例级别(Instance level)的图像语义分割问题也同样热门。该类问题不仅需要对不同语义物体进行图像分割,同时还要求对同一语义的不同个体进行分割(例如需要对图中出现的九把椅子的像素用不同颜色分别标示出来)。
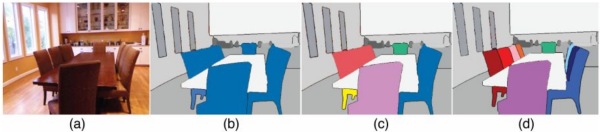
此外,基于视频的前景/物体分割(Video segmentation)也是今后计算机视觉语义分割领域的新热点之一,这一设定其实更加贴合自动驾驶系统的真实应用环境。
最后,目前使用的分割模型在对分割注释有限的大型概念词汇的识别方面表现欠佳。原因在于它们忽略了所有概念的固有分类和语义层次。例如,长颈鹿、斑马和马同属于有蹄类动物,这个大类描绘了它们的共同视觉特征,使得它们很容易与猫/狗区分开来。对人来说,即使你没见过斑马,但也不会把它错误的认成猫/狗。但目前的DL模型在这方面的能力还很薄弱。
参考:
https://mp.weixin.qq.com/s/palhFeMnWOZj-T2cqQN7tw
新型语义分割模型:动态结构化语义传播网络DSSPN
https://mp.weixin.qq.com/s/iNDzhcvwJd556T5btVwwRw
如何掌握好图像分割算法?值得你看的技术综述
Mask R-CNN
Mask R-CNN虽然挂着R-CNN的名头,但却是一个对象实例分割(不仅要分出对象的类别,连同一类对象的不同实例也要分出来)的网络。它是何恺明2017年的新作。
论文:
《Mask R-CNN》
代码:
官方Pytorch版本:
https://github.com/facebookresearch/maskrcnn-benchmark
TensorFlow版本:
https://github.com/hillox/TFMaskRCNN
MXNet版本:
https://github.com/TuSimple/mx-maskrcnn
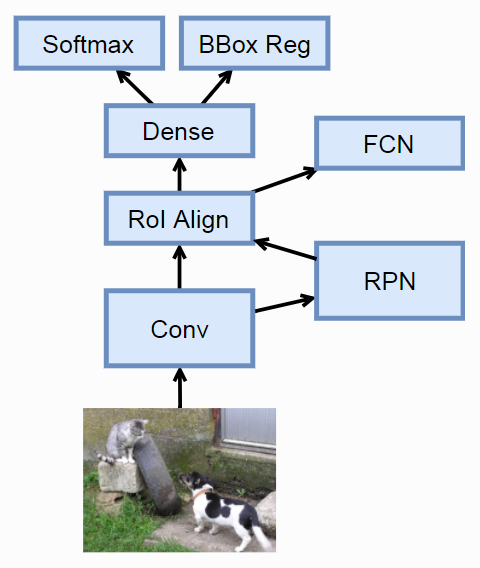
上图是Mask R-CNN的网络结构图。它实际上就是在Faster R-CNN的基础上添加了一个FCN。
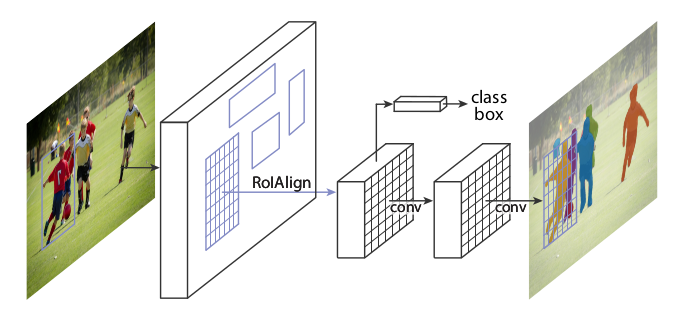
上图也是Mask R-CNN的网络结构图,但它对Faster R-CNN中与本主题无关的部分做了省略。
Mask R-CNN的要点主要有:
- RoI Align
RoI Align避免对RoI的边界或者块(bins)做任何量化,例如直接使用x/16代替[x/16]。
然而这就引来一个问题:如果x/16不是整数该怎么采样呢?
答案:对临近的整数采样点,使用双线性插值(bilinear interpolation)拟合,得到非整数采样点的值。

- 独立的类别预测
把loss由tf.nn.softmax_cross_entropy_with_logits换成tf.nn.sigmoid_cross_entropy_with_logits。参见《深度目标检测(五)》的YOLOv3一节。没错,YOLOv3借鉴了Mask R-CNN的这一设计思路。
- 对象实例分割
Mask R-CNN只对RoI Align后的区域进行分割,而不像U-NET等会对全景进行分割。因此,更适合抠图之类的应用。
Mask R-CNN除了可以用于实例分割以外,还可用于关键点检测。这点在原始论文和FB的代码中有体现,但是在通常的介绍中往往被忽略。
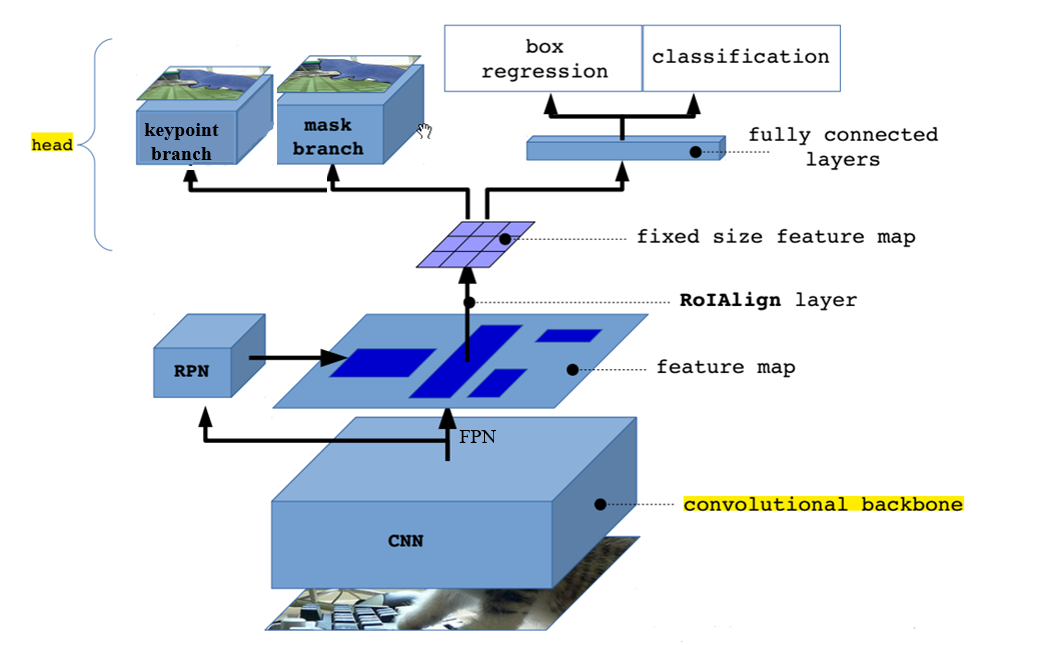
keypoint branch的输出结果是一个keypoint的heatmap(每个keypoint都有自己的heatmap),显然,heatmap中值最大的点就是keypoint的所在。
当然ROI区域和原图,无论是坐标,还是尺寸,都有差异,需要通过插值恢复回去。Mask R-CNN使用的是bicubic插值,该方法计算量较大,因此实际中,多采用下文所述的基于Taylor展开的方法进行插值。
《Invariant Features from Interest Point Groups》
参考:
https://zhuanlan.zhihu.com/p/25954683
Mask R-CNN个人理解
https://mp.weixin.qq.com/s/E0P2B798pukbtRarWooUkg
Mask R-CNN的Keras/TensorFlow/Pytorch代码实现
https://zhuanlan.zhihu.com/p/30967656
从R-CNN到Mask R-CNN
https://www.zhihu.com/question/57403701
如何评价Kaiming He最新的Mask R-CNN?
http://zh.gluon.ai/chapter_computer-vision/object-detection.html
使用卷积神经网络的物体检测
https://mp.weixin.qq.com/s/4BRwMEr6rFYvkmKXM7rYLg
效果惊艳!FAIR提出人体姿势估计新模型,升级版Mask-RCNN
https://mp.weixin.qq.com/s/UXzhMkGIwqek4zHVNPgRbA
Mask-RCNN论文解读
https://mp.weixin.qq.com/s/_ohsx7kzgU-szP-K9_Yv1w
优于Mask R-CNN,港中文&腾讯优图提出PANet实例分割框架
https://mp.weixin.qq.com/s/uJpVqRpWWaK2cY8fYGlRag
先理解Mask R-CNN的工作原理,然后构建颜色填充器应用
https://mp.weixin.qq.com/s/x_9klKK_hIiFV1fGhxZIVA
Mask R-CNN神应用:像英剧《黑镜》一样屏蔽人像
https://mp.weixin.qq.com/s/V6m1xBS2vZQ6VRlAg5zOSA
干掉照片中那些讨厌的家伙!Mask R-CNN助你一键“除”人!
https://mp.weixin.qq.com/s/48eIhnBdYzgEiV_wESHsJA
如何使用Mask RCNN模型进行图像实体分割?
https://mp.weixin.qq.com/s/G_2tuZlaxX5w-2c1DO8FwQ
利用边缘监督信息加速Mask R-CNN实例分割训练
https://mp.weixin.qq.com/s/Ug4ZEQWVF5UjhqWw4Kwb8A
Mask R-CNN抢车位,快人一步!
https://zhuanlan.zhihu.com/p/47579399
R-CNN、Fast/Faster/Mask R-CNN、FCN、RFCN、SSD原理简析
https://mp.weixin.qq.com/s/CsEHuGz_fAq8eWpHRq7d6g
性能超越何恺明Mask R-CNN!华科硕士生开源图像分割新方法
https://zhuanlan.zhihu.com/p/57629509
实例分割的进阶三级跳:从Mask R-CNN到Hybrid Task Cascade
https://mp.weixin.qq.com/s/7Z8unW7Gsu0cf1hAwvjAxw
何恺明等人提TensorMask框架:比肩Mask R-CNN,4D张量预测新突破
https://mp.weixin.qq.com/s/SUZcgq6wOqct_CrWB0j1gA
CVPR2019-实例分割Mask Scoring R-CNN
https://mp.weixin.qq.com/s/Uc0VFMmYoOFvH0c7IExKIg
何恺明团队计算机视觉最新进展:从特征金字塔网络、Mask R-CNN到学习分割一切
https://mp.weixin.qq.com/s/sRU9_M9LsP-j46kNdcI0QQ
Cascade R-CNN升级!目标检测制霸COCO,实例分割超越Mask R-CNN
https://www.cnblogs.com/fydeblog/p/10145805.html
MaskRCNN-Keypoints
https://zhuanlan.zhihu.com/p/65893018
玩转Facebook的maskrcnn-benchmark项目
https://mp.weixin.qq.com/s/A9WkTGHLsaUE11NiQKT2vw
1小时上手MaskRCNN·Keras开源实战
https://mp.weixin.qq.com/s/wwWk8pmQzEOx8rrtW4u39Q
何恺明团队新作:图像分割精细度空前,边缘自带抗锯齿,算力仅需Mask R-CNN的2.6%(PointRend)
https://zhuanlan.zhihu.com/p/98508347
论文速读:PointRend: Image Segmentation as Rendering
https://mp.weixin.qq.com/s/I1Ajguj6b7B1CZGKJoPbqw
SOTA实例分割算法BlendMask,超越mask-rcnn
https://mp.weixin.qq.com/s/8gMMglCkFH6iJgv1ajJGfQ
从零开始学Mask RCNN:一,原理回顾&&项目文档翻译
https://mp.weixin.qq.com/s/70YDNpmEYoKbVqsLiVPc_w
从零开始学Mask RCNN:二,Mask RCNN框架整体把握
https://mp.weixin.qq.com/s/2_TF11zy4aM0cZZTuRQhMg
从零开始学Mask RCNN:三,Mask RCNN网络架构解析及TensorFlow和Keras的交互
https://zhuanlan.zhihu.com/p/273587749
一文读懂RoIPooling、RoIAlign和RoIWarp
https://zhuanlan.zhihu.com/p/161540817
RoI Pooling与RoI Align的区别
https://mp.weixin.qq.com/s/SsKCrKiZU8d9L8CNQ6RUeQ
从R-CNN到Mask R-CNN的思维跃迁
花式U-NET
本节主要摘抄自:
https://zhuanlan.zhihu.com/p/57530767
图像分割的U-Net系列方法
3D U-Net
论文:
《3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation》
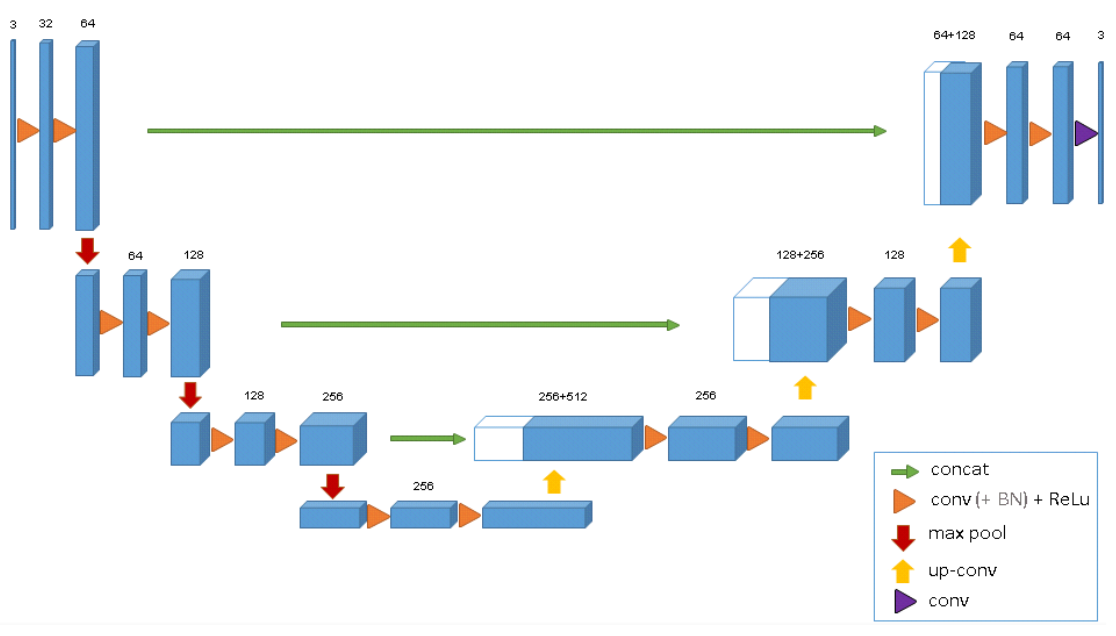
这个算是3D领域的base-line了,而且效果还不错。好多新网络还未必比得过它。
ResUnet
论文:
《Road Extraction by Deep Residual U-Net》
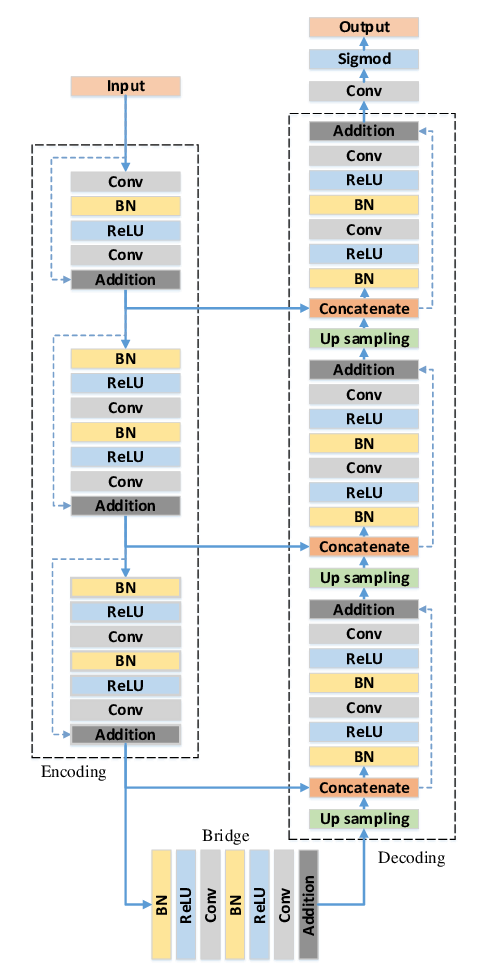
DenseUnet
论文:
《Fully Dense UNet for 2D Sparse Photoacoustic Tomography Artifact Removal》
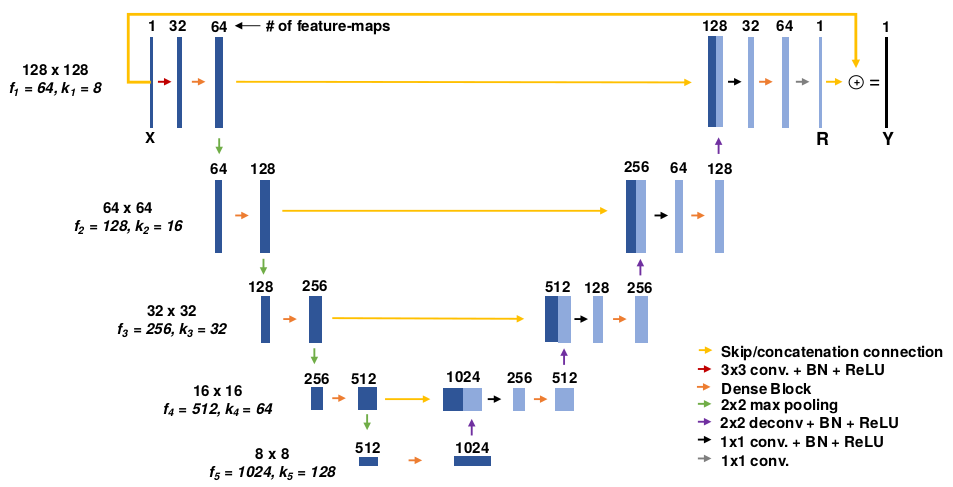

MultiResUNet
论文:
《MultiResUNet : Rethinking the U-Net Architecture for Multimodal Biomedical Image Segmentation》
ResUnet和DenseUnet基本属于排列组合式的灌水。下面的MultiResUNet还是有些干货的。
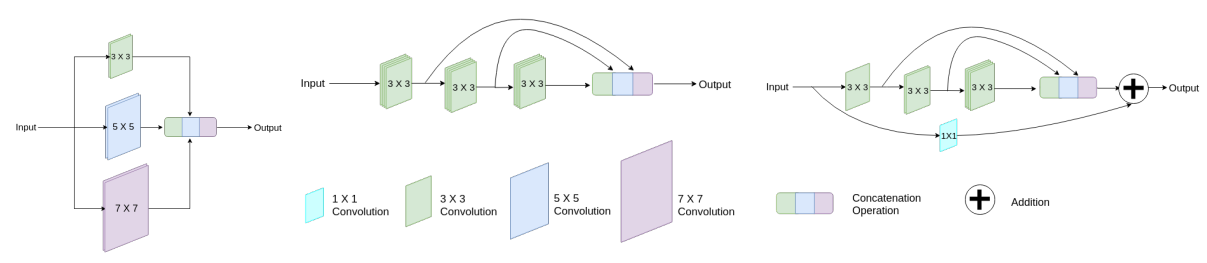
上图是该论文提出的MultiRes block结构。
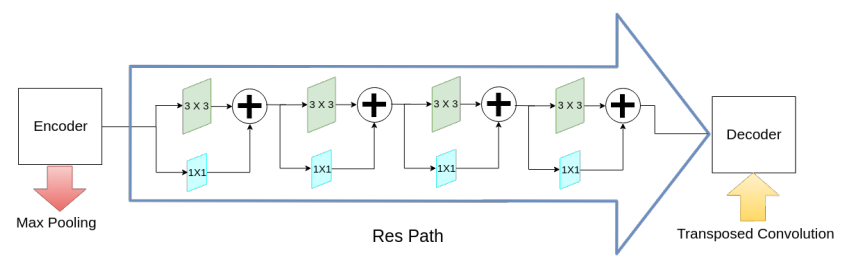
还有下采样和上采样之间的Res path结构。
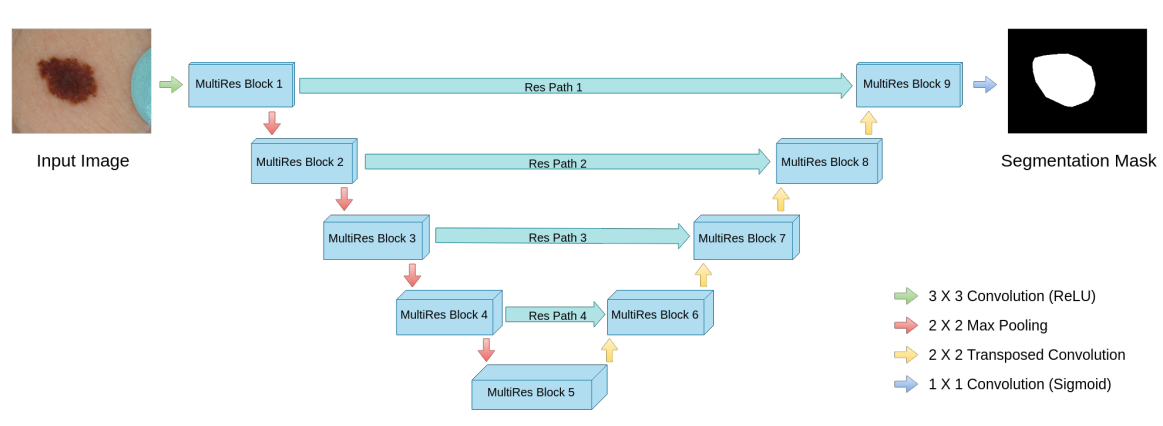
这是最终的网络结构图。基本上把concat和add的各种组合都撸了一遍。
R2U-Net
论文:
《Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation》
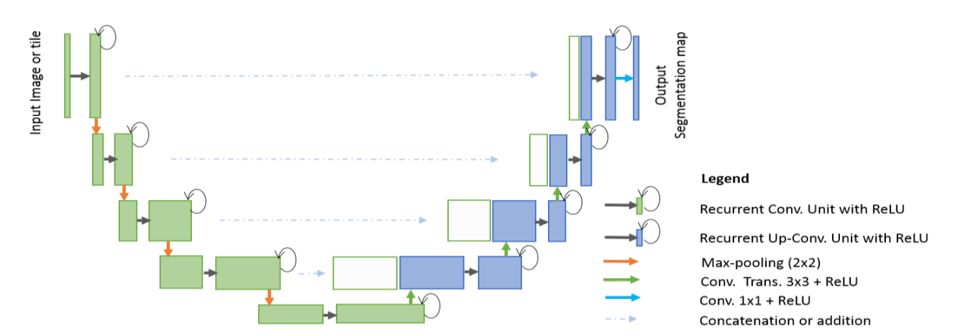
注意,这里的Recurrent Convolutional是Convolutional的一个变种,和RNN没有关系。
Attention U-Net
论文:
《Attention U-Net: Learning Where to Look for the Pancreas》
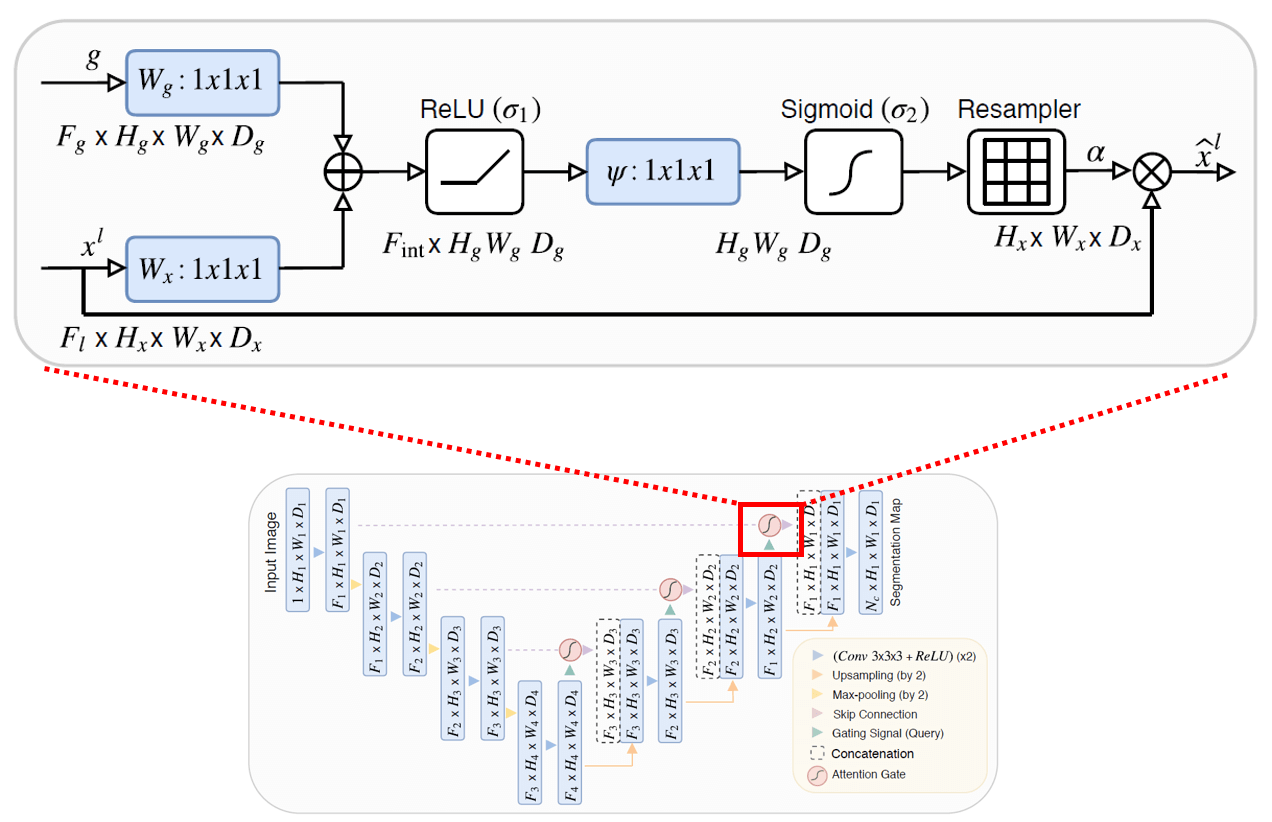
Attention也难逃毒手。
Attention R2U-Net
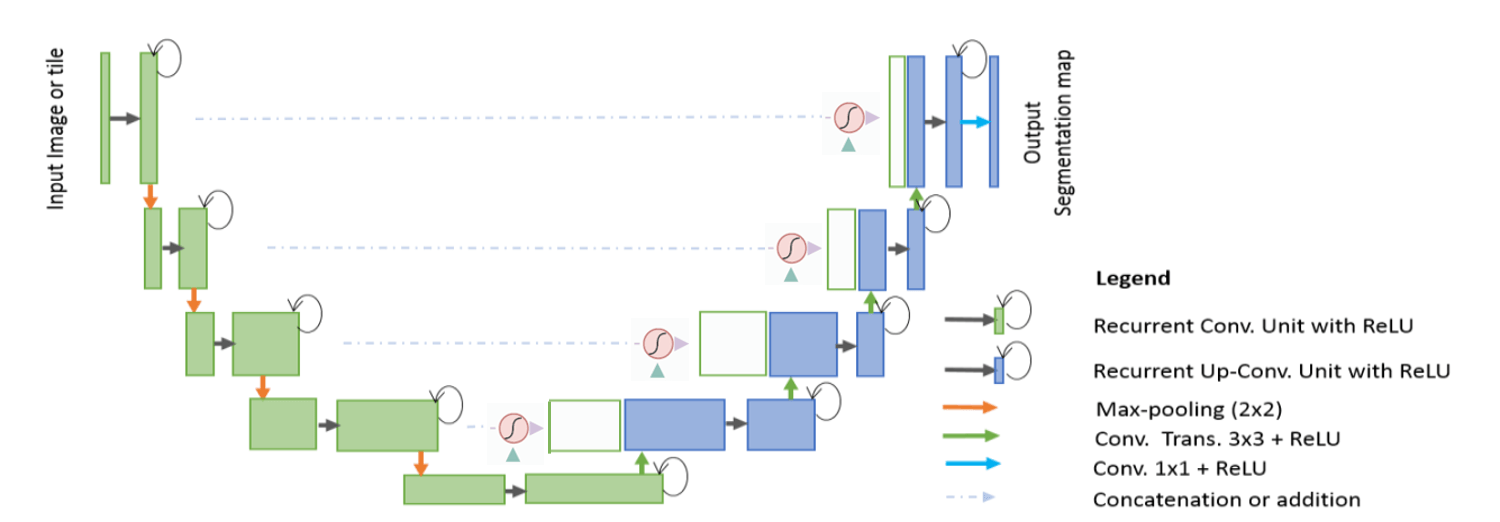
继续组合。不过作者还是有廉耻的,这个没有写论文灌水。
R2U-Net, Attention U-Net, Attention R2U-Net的代码都在这里:
https://github.com/LeeJunHyun/Image_Segmentation
U-NET的另类用法
U-NET除了用于语义分割之外,还可用于语音分离——将人声/音乐从原始混合声音数据中分离出来。比如卡拉OK中的常见的原声抑制功能。
论文:
《Singing Voice Separation With Deep U-net Convolutional Networks》
代码:
https://github.com/Xiao-Ming/UNet-VocalSeparation-Chainer
Chainer版本的实现
https://github.com/Jeongseungwoo/Singing-Voice-Separation
Tensorflow版本的实现
https://github.com/antkillerfarm/antkillerfarm_crazy/tree/master/python/ml/tensorflow/Singing-Voice-Separation
Jeongseungwoo的版本一次加载了全部的数据集到内存中,对PC的要求较高(估计起码要32GB内存才能跑),这是我修改后的版本。用户可以根据自己PC的性能,调整batch size。
https://github.com/f90/Wave-U-Net
另一个Tensorflow版本的实现。这哥们还有个使用Semi-supervised adversarial学习分离人声的项目(他也是该项目论文的一作):
https://github.com/f90/AdversarialAudioSeparation
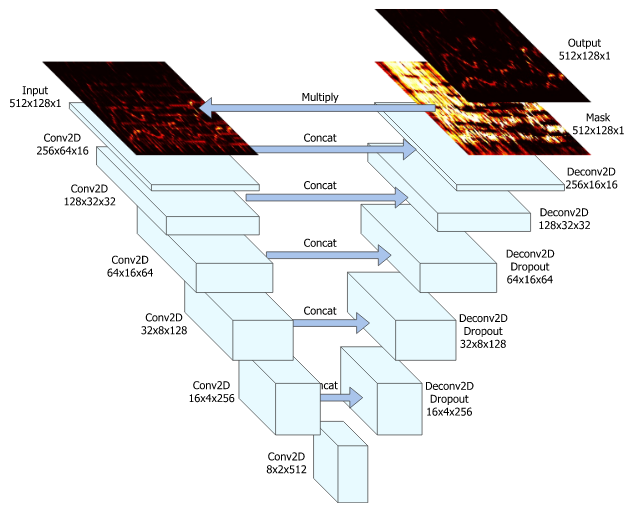
这种用途的U-NET和原始U-NET的区别在于:
1.输入和输出是音频数据的时序频谱图,从某种意义上来说,其实就是一张二维图片。
2.输入是包含混音的数据,而输出是纯净的人声/音乐的Mask。混音数据*Mask=纯净声音。由于标注数据比较难获得,因此通常的做法是使用纯音和若干噪声进行合成得到混音数据。
3.由于最终结果不再是像素级的分类问题,因此Loss采用了absolute difference。
从上面的论述可以看出,该论文主要是用到了语义分割网络中输入和输出的尺寸等大这个特点,算是一种很灵巧的构思了。

您的打赏,是对我的鼓励
