Segmentation » 语义分割(二)——FCN, SegNet, DeconvNet, DeepLab, ENet, GCN
2020-06-04 :: 5667 WordsFCN(续)
通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的一个数值描述(概率),比如AlexNet的ImageNet模型输出一个1000维的向量表示输入图像属于每一类的概率(softmax归一化)。
示例:下图中的猫, 输入AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类统计概率最高。
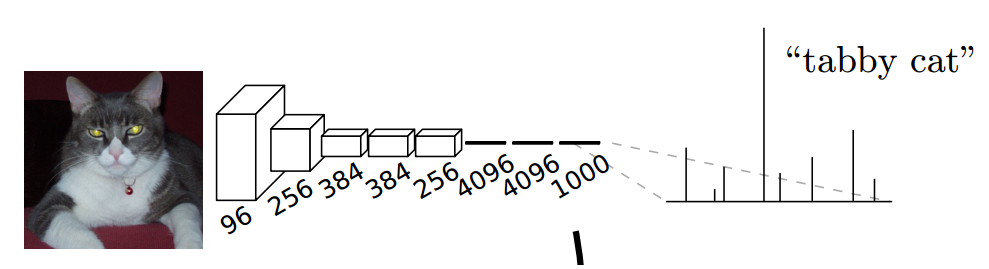
然而CNN网络的问题在于:全连接层会将原来二维的矩阵(图片)压扁成一维的,从而丢失了空间信息。这对于分类是没有问题的,但对于语义分割显然就不行了。
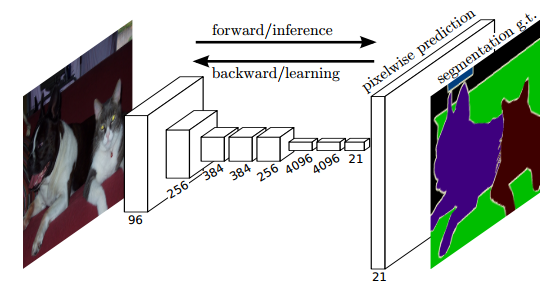
上图是FCN的网络结构图,它的主要思想包括:
1.采用end-to-end的结构。
2.取消FC层。当图片的feature map缩小(下采样)到一定程度之后,进行反向的上采样操作,以匹配图片的语义分割标注图。这里的上采样所采用的方法,就是《深度学习(九)》中提到的transpose convolution。
4.由于上采样会丢失信息。因此,为了更好的预测图像中的细节部分,FCN还将网络中浅层的响应也考虑进来。具体来说,就是将Pool4和Pool3的响应也拿来,分别作为模型FCN-16s和FCN-8s的输出,与原来FCN-32s的输出结合在一起做最终的语义分割预测(如下图所示)。
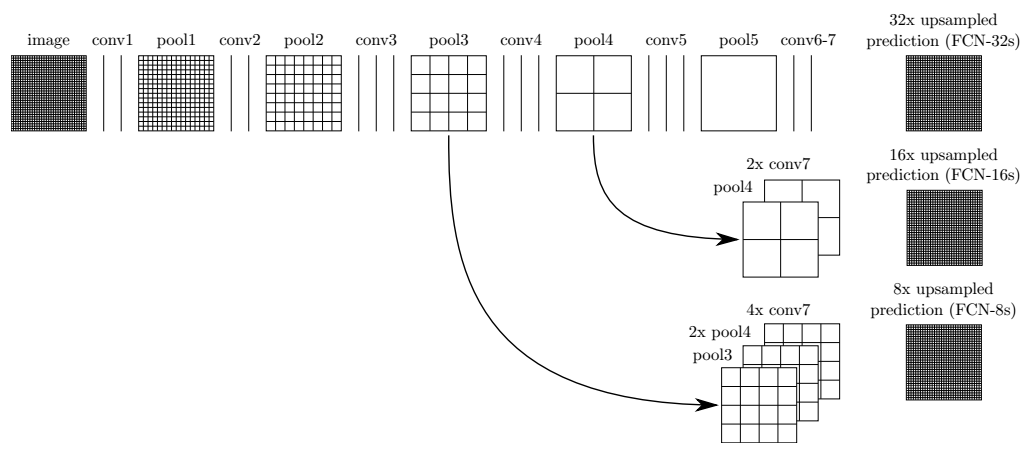
上图的结构在论文中被称为Skip Layer。
FCN的另一贡献是支持任意大小的图像。在CNN的常见操作中,Conv和Pooling都不在意图像大小。一组参数可以应用于任意大小的图像,但FC要求固定的输入维度,这决定了输入的图像的大小必须是固定的。因此,现代的CNN为了支持任意大小的图像,都有意减少或避免使用FC。
参考:
http://www.cnblogs.com/gujianhan/p/6030639.html
全卷积网络FCN详解
https://zhuanlan.zhihu.com/p/32506912
FCN的简单实现
https://mp.weixin.qq.com/s/kc0tTcTzRAT0p7q6ejXbqQ
重新发现语义分割,一文简述全卷积网络
https://www.zhihu.com/question/56688854
卷积神经网络里输入图像大小何时是固定,何时是任意?
https://mp.weixin.qq.com/s/AXfyMeFnCENIMc2qS8hNtA
10分钟看懂全卷积神经网络(FCN):语义分割深度模型先驱
https://mp.weixin.qq.com/s/d9ghEpsDgZE1cvW7TfNPQg
图像分割2020,架构,损失函数,数据集,框架的整理和总结
分类网络使用Conv替换FC
在语义分割网络中废弃FC是一个自然的操作,无须任何技巧,但是在分类网络中,由于FC起到了关键的分类作用,想要替换,办法就不那么显而易见了。
假设图像经过若干层CNN之后,变成了5x5的feature map。对feature map进行1x1的Conv,使其通道数等于分类的类别数。这样就得到了每个像素的类别概率。
对较高概率的像素进行聚类,即可得到分类信息。而且不同于一般的分类器,这个分类器实际上还可以标定物体在图像中的位置,相当于具有了目标检测的能力。
参考:
https://mp.weixin.qq.com/s/MI4vajsiQ63jow8AYL-Vig
一个小改动,CNN输入固定尺寸图像改为任意尺寸图像
SegNet
SegNet是Vijay Badrinarayanan于2015年提出的。
论文:
《SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling》
代码:
https://github.com/alexgkendall/caffe-segnet
除此之外,还有一个demo网站:
http://mi.eng.cam.ac.uk/projects/segnet/
Vijay Badrinarayanan,印度人,班加罗尔大学本科(2001年)+Georgia理工硕士(2005年)+法国INRIA博士(2009年)。剑桥大学讲师。
Alex Kendall,新西兰奥克兰大学本科(2014年)+剑桥大学博士在读。本文二作,但是代码和demo都是他写的。
Roberto Cipolla,剑桥大学本科(1984年)+宾夕法尼亚大学硕士(1985年)+牛津大学博士(1991年)。剑桥大学教授。
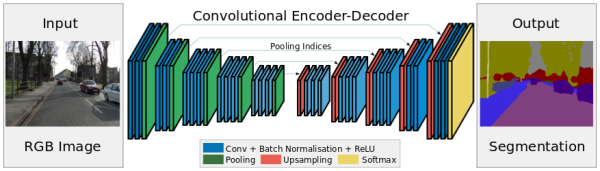
相比于CNN下采样阶段的结构规整,FCN上采样时的结构就显得凌乱了。因此,SegNet采用了几乎和下采样对称的上采样结构。
参考:
http://blog.csdn.net/fate_fjh/article/details/53467948
SegNet
https://mp.weixin.qq.com/s/YwmHiQ0vyFAx_dhjsmOlAQ
编解码结构SegNet
DeconvNet
DeconvNet是韩国的Hyeonwoo Noh于2015年提出的。
论文:
《Learning Deconvolution Network for Semantic Segmentation》
代码:
https://github.com/HyeonwooNoh/DeconvNet
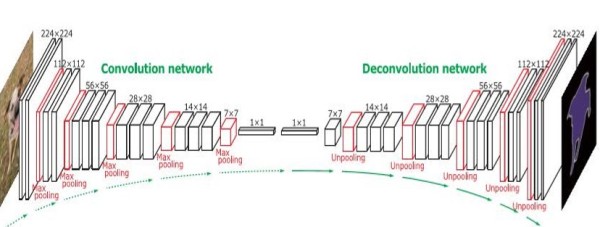
从上图可见,DeconvNet和SegNet的结构非常类似,只不过DeconvNet在encoder和decoder之间使用了FC层作为中继。
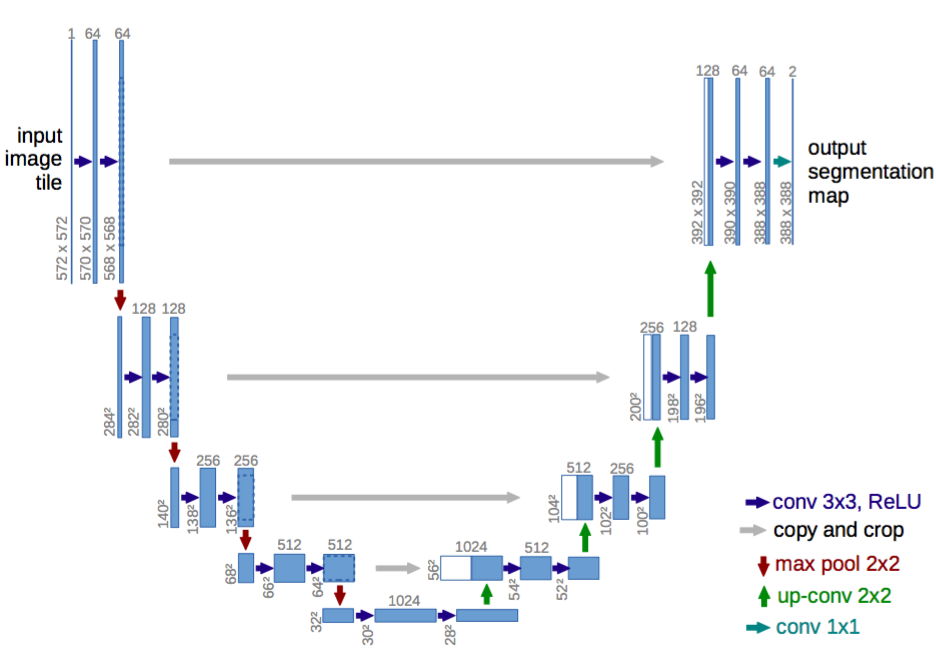
类似这样的encoder-decoder对称结构的还有U-Net(因为它们的形状像U字形):
论文:
《U-Net: Convolutional Networks for Biomedical Image Segmentation》
官网:
https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
Olaf Ronneberger,弗莱堡大学教授,DeepMind研究员。
U-Net使用center crop和concat操作实现了不同层次特征的upsample,这和后面介绍的DenseNet十分类似。
参考:
https://mp.weixin.qq.com/s/ZNNwK1pkL4e0KeYw-UycgA
Kaggle车辆边界识别第一名解决方案:使用预训练权重轻松改进U-Net
DeepLab
DeepLab共有4个版本(v1, v2, v3, v3+),分别对应4篇论文:
《Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs》
《DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs》
《Rethinking Atrous Convolution for Semantic Image Segmentation》
《Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation》
Liang-Chieh(Jay) Chen,台湾国立交通大学本科(2004年)+密歇根大学硕士(2010年)+UCLA博士(2015年)。现为Google研究员。
个人主页:
http://liangchiehchen.com/
DeepLab针对FCN主要做了如下改进:
1.用Dilated convolution取代Pooling操作。因为前者能够更好的保持空间结构信息。
2.使用全连接条件随机场(Dense Conditional Random Field)替换最后的Softmax层。这里的CRF或者Softmax,也被称为语义分割网络的后端。
常见的后端还有Markov Random Field、Gaussian CRF等。这些都与概率图模型(Probabilistic Graphical Models)有关。
总之,目前的主流一般是FCN+PGM的模式。然而后端的计算模式和普通的NN有所差异,因此如何将后端NN化,也是当前研究的关键点。
参考:
https://mp.weixin.qq.com/s/ald9Dq_VV3PYuN6JoY3E5Q
DeepLabv3+:语义分割领域的新高峰
https://mp.weixin.qq.com/s/zLyAwtG49A-vwWa1iPziew
谷歌最新语义图像分割模型DeepLab-v3+今日开源
https://mp.weixin.qq.com/s/L1JtK9eUhVJMGWm-SjWW5w
DeepLab v1
https://zhuanlan.zhihu.com/p/34783156
读Xception和DeepLab V3+
https://mp.weixin.qq.com/s/m7sUib6YQdb528G40LjpPg
DeepLab v2及调试过程
https://mp.weixin.qq.com/s/Za_h1BWR-mQKtgArxwsjRw
语义分割网络DeepLab-v3的架构设计思想和TensorFlow实现
https://mp.weixin.qq.com/s/JidoZ9-V8JGWfB2gyO2AlA
Deeplab v2安装及调试全过程
https://mp.weixin.qq.com/s/pL1Wvd3oBRVtqG9I4O4oDg
DeepLab V3
https://zhuanlan.zhihu.com/p/54911894
语义分割之DeepLabv2
https://mp.weixin.qq.com/s/bFe4F1QGIWm-yCAx9YvWDQ
人人必须要知道的语义分割模型:DeepLabv3+
ENet
ENet是波兰的Adam Paszke于2016年提出的。
论文:
《ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation》
代码:
https://github.com/TimoSaemann/ENet

ENet的网络结构如上图所示。其中的initial和bottleneck结构分别见下图的(a)和(b):
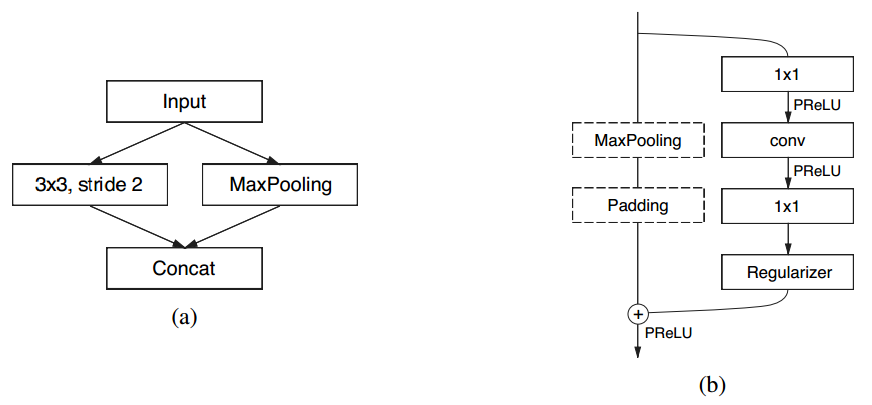
从大的结构来看,ENet的设计主要参考了Resnet和SqueezeNet。
ENet对Pooling操作进行了一定的修改:
1.下采样时,除了输出Pooling值之外,还输出Pooling值的位置,即所谓的Pooling Mask。
2.上采样时,利用第1步的Pooling Mask信息,获得更好的精确度。
显然这个修改在思路上和Dilated convolution是非常类似的。
参考:
http://blog.csdn.net/zijinxuxu/article/details/67638290
论文中文版blog
https://mp.weixin.qq.com/s/_Sz8u7A6_01e_Xbkvuoscg
快速道路场景分割—ENet
Global Convolutional Network
Global Convolutional Network是孙剑团队的Chao Peng于2017年提出的。
论文:
《Large Kernel Matters – Improve Semantic Segmentation by Global Convolutional Network》
孙剑,西安交通大学博士(2003年)。后一直在微软亚洲研究院工作,担任首席研究员。2016年7月正式加入旷视科技担任首席科学家。
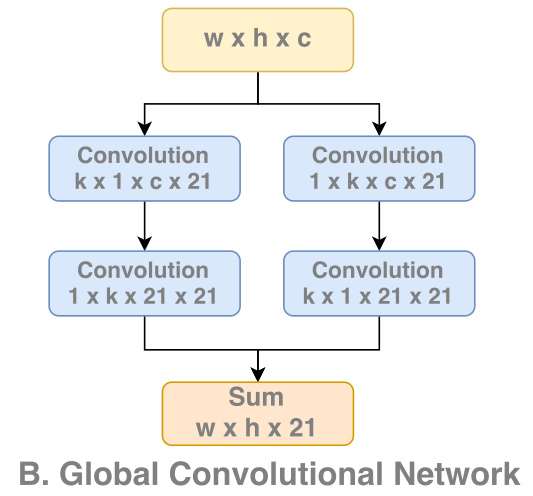
上图是论文的关键结构GCN,它主要用于计算超大卷积核。这里借鉴了Separable convolution的思想(将一个k x k的卷积运算,转换成1 x k + k x 1的卷积运算)。
然而正如我们在《深度学习(九)》中指出的,不是所有的卷积核都满足可分离条件。单纯采用先1 x k后k x 1,或者先k x 1后1 x k,效果都是不好的。而将两者结合起来,可以有效提高计算的精度。
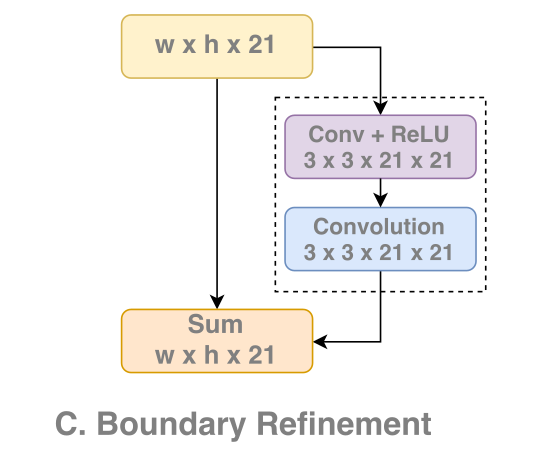
这是GCN提出的另一个新结构。

上图是GCN的整体结构图。
参考:
http://blog.csdn.net/bea_tree/article/details/60977512
旷视最新:Global Convolutional Network
语义分割的展望
俗话说,“没有免费的午餐”(“No free lunch”)。基于深度学习的图像语义分割技术虽然可以取得相比传统方法突飞猛进的分割效果,但是其对数据标注的要求过高:不仅需要海量图像数据,同时这些图像还需提供精确到像素级别的标记信息(Semantic labels)。因此,越来越多的研究者开始将注意力转移到弱监督(Weakly-supervised)条件下的图像语义分割问题上。在这类问题中,图像仅需提供图像级别标注(如,有“人”,有“车”,无“电视”)而不需要昂贵的像素级别信息即可取得与现有方法可比的语义分割精度。

您的打赏,是对我的鼓励
