Segmentation » 语义分割(一)——概述, 常见评价指标, 前DL时代, DL进化史
2020-04-29 :: 5639 Words概述
Semantic segmentation是图像理解的基石性技术,在自动驾驶系统(具体为街景识别与理解)、无人机应用(着陆点判断)以及穿戴式设备应用中举足轻重。
我们都知道,图像是由许多像素(Pixel)组成,而“语义分割”顾名思义就是将像素按照图像中表达语义含义的不同进行分组(Grouping)/分割(Segmentation)。

上图是语义分割网络ENet的实际效果图。其中,左图为原始图像,右图为分割任务的真实标记(Ground truth)。
显然,在图像语义分割任务中,其输入为一张HxWx3的三通道彩色图像,输出则是对应的一个HxW矩阵,矩阵的每一个元素表明了原图中对应位置像素所表示的语义类别(Semantic label)。
因此,图像语义分割也称为“图像语义标注”(Image semantic labeling)、“像素语义标注”(Semantic pixel labeling)或“像素语义分组”(Semantic pixel grouping)。
由于图像语义分割不仅要识别出对象,还要标出每个对象的边界。因此,与分类目的不同,相关模型要具有像素级的密集预测能力。
目前用于语义分割研究的两个最重要数据集是PASCAL VOC和MSCOCO。
参考:
https://mp.weixin.qq.com/s/Nmr5oLe_MSLjYjWXUILiMw
视觉分割任务:论文与评测基准列表汇总
https://zhuanlan.zhihu.com/p/21824299
从特斯拉到计算机视觉之“图像语义分割”
https://zhuanlan.zhihu.com/SemanticSegmentation
一个语义分割的专栏
https://mp.weixin.qq.com/s/zZ-i54_wqzVQxTCFABNIMQ
闲聊图像分割这件事儿
https://mp.weixin.qq.com/s/9F2UB_5ah1nEe3dfyoeRhg
图像分割算法综述
常见评价指标
假设总计有k+1分类(标记为\(L_0\)到\(L_k\),其中包含一个背景类别),\(P_{ij}\)表示类别为i的像素被预测为类别为j的数目,这样来说\(P_{ii}\)就表示TP(true positives),\(P_{ij}\)与\(P_{ji}\)分别表示为FP(false positives)与FN(false negatives)。
- PA(Pixel Accuracy)
最简单的度量计算,总的像素跟预测正确像素的比率:
\[PA=\frac{\sum_{i=0}^k P_{ii}}{\sum_{i=0}^k \sum_{j=0}^k P_{ij}}\]- MPA(Mean Pixel Accuracy)
基于每个类别正确的像素总数与每个类别总数比率求和得到的均值:
\[MPA=\frac{1}{k+1}\sum_{i=0}^k\frac{P_{ii}}{\sum_{j=0}^k P_{ij}}\]- MIoU(Mean Intersection over Union)
它通过计算交并比来度量,这里交并比代指ground truth与预测分割结果之间。是重新计算TP跟 (TP + FN+FP)之和之间的比率。IoU是基于每个类别计算,然后再求均值。公式如下:
\[MIoU=\frac{1}{k+1}\sum_{i=0}^k\frac{P_{ii}}{\sum_{j=0}^k P_{ij} + \sum_{j=0}^k P_{ji}-P_{ii}}\]- FWIoU(Frequency Weighted Intersection over Union)
MIoU的改进版本,它会根据每个分类出现频率,对每个分类给予不同权重。它的计算方法如下:
\[FWIoU=\frac{1}{\sum_{i=0}^k \sum_{j=0}^k P_{ij}}\sum_{i=0}^k\frac{\sum_{j=0}^k P_{ij}P_{ii}}{\sum_{j=0}^k P_{ij} + \sum_{j=0}^k P_{ji}-P_{ii}}\]上述几种精度计算方法,MIoU是各种基准数据集最常用的标准之一,绝大数的图像语义分割论文中模型评估比较都以此作为主要技术指标。
参考:
https://mp.weixin.qq.com/s/87U2CZsca9XtIg-BXZPJhw
深度学习图像语义分割常见评价指标详解
前DL时代
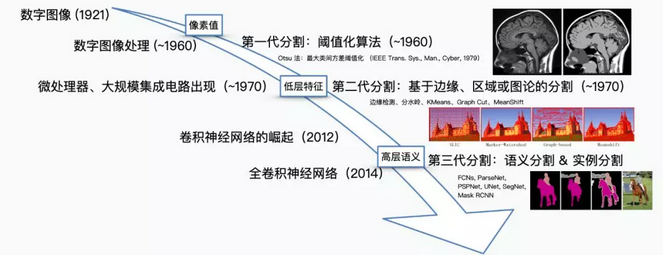
从最简单的像素级别“阈值法”(Thresholding methods)、基于像素聚类的分割方法(Clustering-based segmentation methods)到“图划分”的分割方法(Graph partitioning segmentation methods),在DL“一统江湖”之前,图像语义分割方面的工作可谓“百花齐放”。在此,我们仅以“Normalized cut”和“Grab cut”这两个基于图划分的经典分割方法为例,介绍一下前DL时代语义分割方面的研究。
Normalized cut
Normalized cut (N-cut)方法是基于图划分(Graph partitioning)的语义分割方法中最著名的方法之一,于2000年Jianbo Shi和Jitendra Malik发表于相关领域顶级期刊TPAMI。
通常,传统基于图划分的语义分割方法都是将图像抽象为图(Graph)的形式\(\bf{G}=(\bf{V},\bf{E})\)(\(\bf{V}\)为图节点,\(\bf{E}\)为图的边),然后借助图理论(Graph theory)中的理论和算法进行图像的语义分割。
常用的方法为经典的最小割算法(Min-cut algorithm)。不过,在边的权重计算时,经典min-cut算法只考虑了局部信息。如下图所示,以二分图为例(将\(\bf{G}\)分为不相交的\(\bf{A},\bf{B}\)两部分),若只考虑局部信息,那么分离出一个点显然是一个min-cut,因此图划分的结果便是类似\(n_1\)或\(n_2\)这样离群点,而从全局来看,实际想分成的组却是左右两大部分。
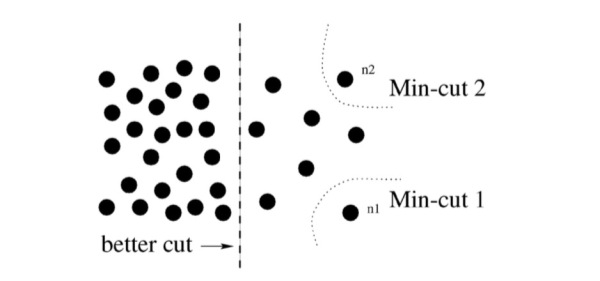
针对这一情形,N-cut则提出了一种考虑全局信息的方法来进行图划分(Graph partitioning),即,将两个分割部分\(\bf{A},\bf{B}\)与全图节点的连接权重(\({\rm assoc(\bf{A},\bf{V})}\)和\(\rm assoc(\bf{B},\bf{V})\))考虑进去:
\[N_{cut}(\bf{A},\bf{B})=\frac{cut(\bf{A},\bf{B})}{assoc(\bf{A},\bf{V})}+\frac{cut(\bf{A},\bf{B})}{assoc(\bf{B},\bf{V})}\]如此一来,在离群点划分中,\(N_{cut}(\bf{A},\bf{B})\)中的某一项会接近1,而这样的图划分显然不能使得\(N_{cut}(\bf{A},\bf{B})\)是一个较小的值,故达到考虑全局信息而摒弃划分离群点的目的。这样的操作类似于机器学习中特征的规范化(Normalization)操作,故称为Normalized cut。N-cut不仅可以处理二类语义分割,而且将二分图扩展为K路(K-way)图划分即可完成多语义的图像语义分割,如下图例。

Grab cut
Grab cut是微软剑桥研究院于2004年提出的著名交互式图像语义分割方法。与N-cut一样,grab cut同样也是基于图划分,不过grab cut是其改进版本,可以看作迭代式的语义分割算法。Grab cut利用了图像中的纹理(颜色)信息和边界(反差)信息,只要少量的用户交互操作即可得到比较好的前后背景分割结果。
在Grab cut中,RGB图像的前景和背景分别用一个高斯混合模型(Gaussian mixture model, GMM)来建模。两个GMM分别用以刻画某像素属于前景或背景的概率,每个GMM高斯部件(Gaussian component)个数一般设为k=5。接下来,利用吉布斯能量方程(Gibbs energy function)对整张图像进行全局刻画,而后迭代求取使得能量方程达到最优值的参数作为两个GMM的最优参数。GMM确定后,某像素属于前景或背景的概率就随之确定下来。
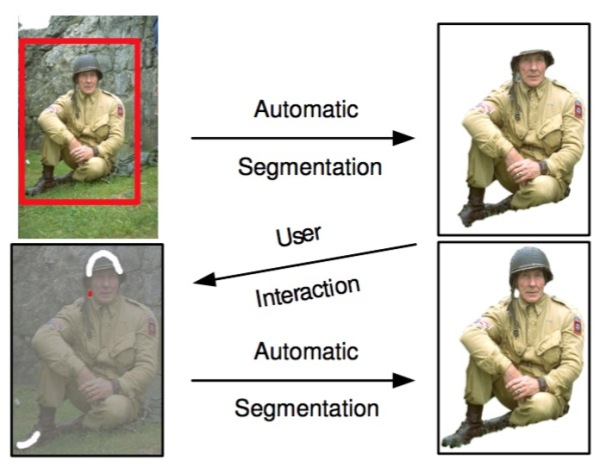
在与用户交互的过程中,Grab cut提供两种交互方式:一种以包围框(Bounding box)为辅助信息;另一种以涂写的线条(Scribbled line)作为辅助信息。以下图为例,用户在开始时提供一个包围框,grab cut默认的认为框中像素中包含主要物体/前景,此后经过迭代图划分求解,即可返回扣出的前景结果,可以发现即使是对于背景稍微复杂一些的图像,grab cut仍有不俗表现。

不过,在处理下图时,grab cut的分割效果则不能令人满意。此时,需要额外人为的提供更强的辅助信息:用红色线条/点标明背景区域,同时用白色线条标明前景区域。在此基础上,再次运行grab cut算法求取最优解即可得到较为满意的语义分割结果。Grab cut虽效果优良,但缺点也非常明显,一是仅能处理二类语义分割问题,二是需要人为干预而不能做到完全自动化。
不难看出,前DL时代的语义分割工作多是根据图像像素自身的低阶视觉信息(Low-level visual cues)来进行图像分割。由于这样的方法没有算法训练阶段,因此往往计算复杂度不高,但是在较困难的分割任务上(如果不提供人为的辅助信息),其分割效果并不能令人满意。
人为提供更强的辅助信息的过程,通常被称作交互式分割。
参考:
https://mp.weixin.qq.com/s/AiuwMytfux9BMt__eVtj6w
基于图割算法的木材表面缺陷图像分析
https://mp.weixin.qq.com/s/sQ9XGbt0UslHJ9_FYOpKrw
指哪分哪:交互式分割近期发展
https://zhuanlan.zhihu.com/p/30732385
图像分割 传统方法 整理
DL进化史
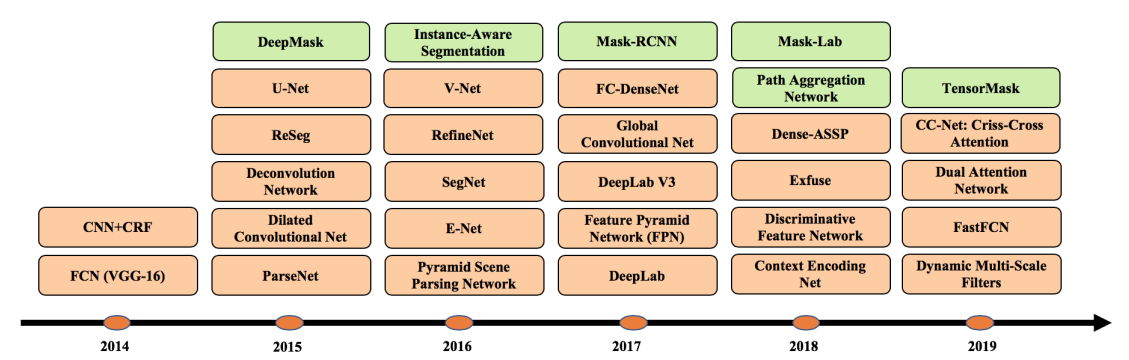
上图中,橙色表示语义分割模型,绿色表示实例分割模型。
参考:
https://mp.weixin.qq.com/s/w7pYxm52QbcFPRBe12iMdA
纽约大学发布“深度学习图像分割”最新综述论文,带你全面了解100个10大类深度图像分割算法
https://zhuanlan.zhihu.com/p/22308032
图像语义分割之FCN和CRF
https://zhuanlan.zhihu.com/p/25515361
图像语义分割之特征整合和结构预测
https://zhuanlan.zhihu.com/p/27794982
语义分割中的深度学习方法全解:从FCN、SegNet到各代DeepLab
https://mp.weixin.qq.com/s/mQqEe4LC0VHBH2ZAtFanWQ
基于深度学习的图像语义分割方法回顾
https://mp.weixin.qq.com/s/9G3kahaoOSoB-DiGey1VLA
基于深度学习的图像语义分割算法综述
https://mp.weixin.qq.com/s/jCv259hI0vl7st80Obfrcg
图像语义分割的工作原理和CNN架构变迁
https://mp.weixin.qq.com/s/KcVKKsAyz-eVsyWR0Y812A
分割算法——可以分割一切目标
https://mp.weixin.qq.com/s/JbdwtpA3iRXReyerO4HYIg
一文了解什么是语义分割及常用的语义分割方法有哪些
https://mp.weixin.qq.com/s/MFNKDNTrF-8VuKrwcsTDLw
纵览图像语义分割发展史,11篇关键文章简介
https://mp.weixin.qq.com/s/s0tg-6RoLV0KlXtowWHHBQ
一文读懂语义分割与实例分割
FCN
深度学习最初流行的分割方法是,打补丁式的分类方法 (patch classification) 。逐像素地抽取周围像素对中心像素进行分类。由于当时的卷积网络末端都使用全连接层 (full connected layers) ,所以只能使用这种逐像素的分割方法。
Fully Convolutional Networks是Jonathan Long和Evan Shelhamer于2014年提出的网络结构。
论文:
《Fully Convolutional Networks for Semantic Segmentation》
代码:
https://github.com/shelhamer/fcn.berkeleyvision.org
Jonathan Long,CMU本科(2010年)+UCB博士在读。
个人主页:
https://people.eecs.berkeley.edu/~jonlong/
Evan Shelhamer,UCB博士在读。
个人主页:
http://imaginarynumber.net/
Trevor Darrell,University of Pennsylvania本科(1988年)+MIT硕博(1992年、1996年)。MIT教授(1999~2008)。UCB教授。
个人主页:
https://people.eecs.berkeley.edu/~trevor/

您的打赏,是对我的鼓励
