RL » 强化学习(一)——概述
2018-11-18 :: 4455 Words概述
相关教程资源参见《深度强化学习(一)》。
历史
早期的强化学习有两个主要的丰富绵长的发展线索:
-
源于动物学习的试错法;在早期的人工智能中发展,于二十世纪八十年代促进了强化学习的复兴。
-
最优控制及其解决方案:值函数和动态规划。最优控制大部分没有包括学习。
这两个线索先是分头进展,到二十世纪八十年代,时序差分(temporal-difference)方法出现,形成第三条线索。然后几种线索交织融合到一起,发展成现代强化学习。
最优控制始于二十世纪五十年代,设计控制器来优化动态系统一段时间内行为的性能指标。动态规划是最优控制的一个解决方法,由Richard Bellman等人提出。Bellman还提出离散随机版的最优控制问题,即马尔科夫决策过程(Markov decision processes, MDP)。Ronald Howard在1960年给MDP问题设计了策略迭代方法。
最优控制、动态规划与学习的联系,确认得比较慢。可能的原因是这些领域由不同的学科在发展,而目标也不尽相同。一个流行的观点是动态规划是离线计算的,需要准确的系统模型,并给出Bellman等式的解析解。还有,最简单的动态规划是按时间从后向前运算的,而学习则是从前往后的,这样,则很难把两者联系起来。
试错学习法最早可以追溯到十九世纪五十年代。1911年,Edward Thorndike简明地把试错学习法当成学习的原则:对于同一情况下的几个反应,在其它因素一样时,只有伴随着或紧随动物的喜悦之后的那些反应,才会被更深刻地与当下的情况联系起来,这样,当这些反应再次发生,再次发生的可能性也更大;而只有伴随着或紧随动物的不适之后的那些反应,与当下的情况联系会被削弱,这样,当这些反应再次发生,再次发生的可能性会更小。喜悦或不适的程度越大,联系的加强或减弱的程度也越大。Thorndike称其为“效果定律”(Law of Effect), 因为它描述了强化事件对选择动作的倾向性的效果,也成为许多行为的基本原则。
“强化”这一术语出现于1927年巴甫洛夫(Pavlov)条件反射论文的英译本,晚于Thorndike的效果定律。巴甫洛夫把强化描述成,当动物接收到刺激,也就是强化物,对一种行为模式的加强,而这个刺激与另一个刺激或反应的发生有合适的时间关系。
二十世纪六十年代、七十年代试错学习法有一些发展。Harry Klopf在人工智能领域对试错法在强化学习中的复兴做了重要贡献。Klopf发现,当研究人员专门关注监督学习时,则会错过自适应行为的一些方面。按照Klopf所说,行为的快乐方面被错过了,而这驱动了从环境成功获得结果,控制环境向希望的结果发展,而远离不希望的结果。这是试错法学习的基本思想。Klopf的思想对强化学习之父Richard Sutton和Andrew Barto有深远影响,使得他们深入评估监督学习与强化学习的区别,并最终专注强化学习,包括如何为多层神经元网络设计学习算法。
时序差分学习部分上起源于动物学习心理学,尤其是次要强化物的概念。次要强化物与像食物和痛苦这样的主要强化物相伴而来,所以也就有相应的强化特点。明斯基于1954年意识到这样的心理学原则可能对人工学习系统的重要意义;1959年,Arthur Samuel在其著名的国际跳棋程序中,第一次提出并实现了包括时序差分学习的学习方法。Klopf在1972年把试错学习法与时序差分学习联系起来。
Sutton和Barto于1981年提出了行动者-评价者体系结构,把时序差分学习与试错学习结合起来。Sutton1984年的博士论文深入讨论了这个方法。Sutton于1988年把时序差分学习与控制分开,把它当做一种通用的预测方法。
1989年,Chris Watkins提出Q学习,把时序差分学习、最优控制、试错学习法三个线索完全融合到一起。这时,开始在机器学习和人工智能领域出现大量的强化学习方面的研究。
1992年,Gerry Tesauro成功地使用强化学习和神经元网络设计西洋双陆棋(Backgammon)的TD-Gammon算法。
监督学习的局限
举个例子,如果我们想让机器学会开车,一个很直接的想法是观察人类行为,并且模仿人类,在相应观测下做出人类所做行为。这种方法也叫作模仿学习(Imitation Learning)。
将这个想法实现起来也很简单,只需要收集该任务的一些观测(路面的画面),以及每个观测人类会做出的反应(转动方向盘),然后像监督学习一样训练一个神经网络,以观测为输入,人类的行为为标签,如果行为是离散的,就是分类任务,如果行为是连续的,则是回归任务。
然而这简单的监督学习理论上并不可行,一个直观的原因是由于现实的随机性或者复杂性,使得机器所采用的动作和人类的动作有偏差或者动作所产生的结果有偏差,这样在有偏差的下一状态,机器还会做出有偏差的动作,使得之后状态的偏差积累,导致机器遇到监督学习时没有碰到过的状态,那机器就完全不知道该怎么做了,也就是如下图所示:
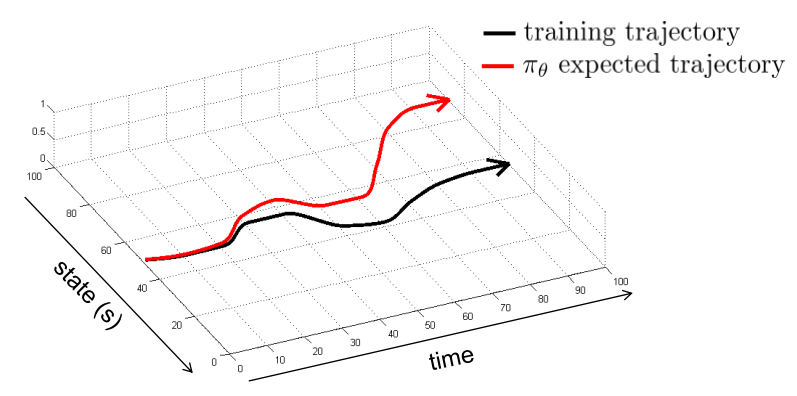
即使我们可以使用一些算法来改善模仿学习的效果,但模仿学习始终有如下问题:
1.需要人类提供的大量数据(尤其是深度学习,需要大量样本)。
2.人类对一些任务也做的不太好,对于一些复杂任务,人类能做出的动作有限。
3.我们希望机器能自动学习,即能不断地在错误中自我完善,而不需要人类的指导。
概述
强化学习是一个多学科交叉的领域。它的主要组成以及和其他学科的关系如下图所示:
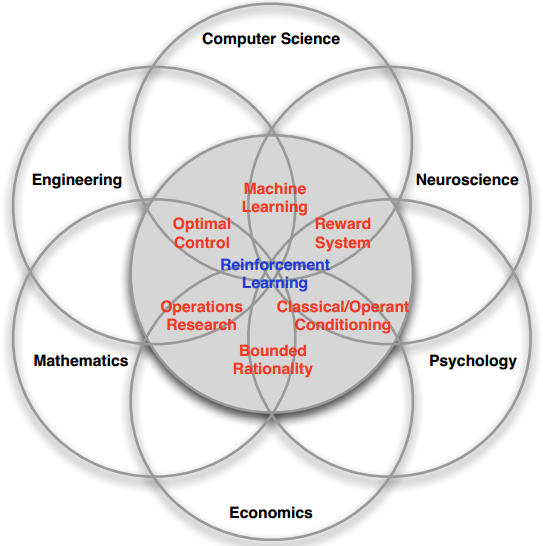
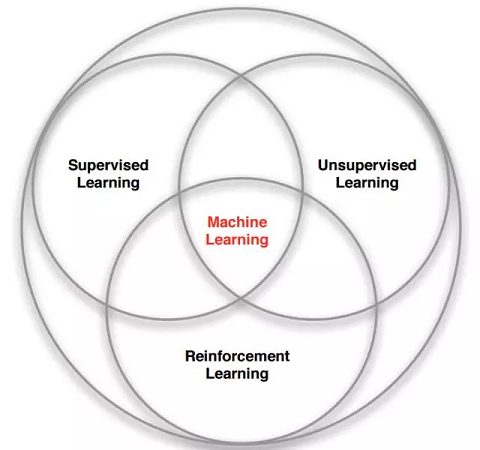
上图是Reinforcement Learning和其他类型算法的关系图。
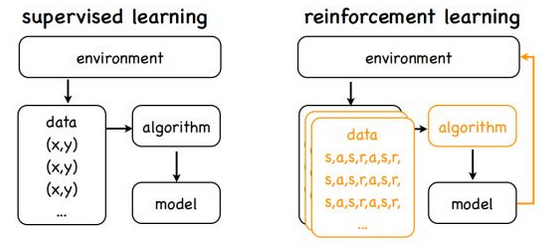
不像监督学习,对于每一个样本,都有一个确定的标签与之对应,而强化学习没有标签,只有一个时间延迟的奖励,而且游戏中我们往往牺牲当前的奖励来获取将来更大的奖励。这就是信用分配问题(Credit Assignment Problem),即当前的动作要为将来获得更多的奖励负责。
而且在我们找到一个策略,让游戏获得不错的奖励时,我们是选择继续坚持当前的策略,还是探索新的策略以求更多的奖励?这就是探索与开发(Explore-exploit Dilemma)的问题。
因此,强化学习某种意义上可看做具有延迟标记信息的监督学习。
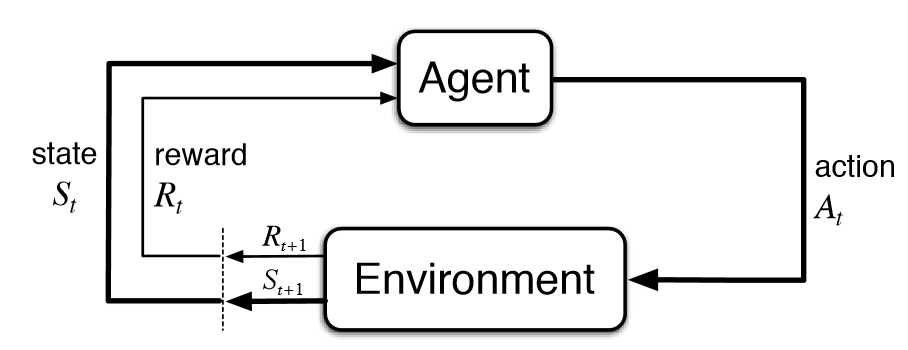
上图是强化学习的基本流程图。从控制论的角度来说,这是一个反馈控制系统,和经典的Kalman filters系统非常类似。因此,目前强化学习的主要用途,也多数和系统控制相关,例如机器人和自动驾驶。
在推荐系统领域,由于有用户的反馈信息,亦可使用相关强化学习算法。
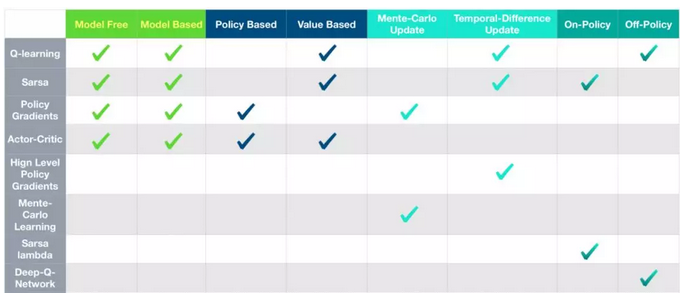
这是传统RL算法的分类图:
MDP
强化学习任务通常用马尔可夫决策过程(Markov Decision Process)来描述:
\[<\mathcal{S},\mathcal{A},\mathcal{P},\mathcal{R},\gamma>\]这个五元组依次代表:states、actions、state transition probability matrix、reward function、discount factor。
MDP中有两个对象:Agent和Environment。
1.Environment处于一个特定的状态(State)(如打砖块游戏中挡板的位置、各个砖块的状态等)。
2.Agent可以通过执行特定的动作(Actions)(如向左向右移动挡板)来改变Environment的状态。
3.Environment状态改变之后会返回一个观察(Observation)给Agent,同时还会得到一个奖励(Reward)(可以为负,就是惩罚)。
4.Agent根据返回的信息采取新的动作,如此反复下去。Agent如何选择动作叫做策略(Policy)。MDP的任务就是找到一个策略,来最大化奖励。
注意State和Observation区别:State是Environment的私有表达,我们往往不会直接得到。
在MDP中,当前状态State包含了所有历史信息,即将来只和现在有关,与过去无关,因为现在状态包含了所有历史信息。只有满足这样条件的状态才叫做马尔科夫状态(Markov state)。当然这只是理想状况,现实往往不会那么简单。
正是因为State太过于复杂,我们往往可以需要一个对Environment的观察来间接获得信息,因此就有了Observation。不过Observation是可以等于State的,此时叫做Full Observability。
这里可以类比围棋和星际争霸。前者的所有信息都在明面上,因此是Full Observability,而后者由于战争迷雾的存在,显然就不是Full Observability的了。
状态、动作、状态转移概率组成了MDP,一个MDP周期(episode)由一个有限的状态、动作、奖励队列组成:
\[s_0,a_0,r_1,s_1,a_1,r_2,s_2,\dots,s_{n-1},a_{n-1},r_n,s_n\]这里\(s_i\)代表状态,\(a_i\)代表行动,\(r_{i+1}\)是执行动作后的奖励。最终状态为\(s_n\)。
折扣未来奖励(Discounted Future Reward)
为了获得更多的奖励,我们往往不能只看当前奖励,更要看将来的奖励。
给定一个MDP周期,总的奖励显然为:
\[R=r_1+r_2+\dots+r_n\]那么,从当前时间t开始,总的将来的奖励为:
\[R_t=r_t+r_{t+1}+\dots+r_n\]但是Environment往往是随机的,执行特定的动作不一定得到特定的状态,因此将来的奖励所占的权重要依次递减,因此使用discounted future reward代替:
\[R_t=r_t+\gamma r_{t+1}+\gamma^2 r_{t+2}+\dots+\gamma^{n-t}r_n\]这里\(\gamma\)是0和1之间的折扣因子——越是未来的奖励,折扣越多,权重越小。而明显上式是个迭代过程,因此可以写作:
\[R_t=r_t+\gamma(r_{t+1}+\gamma (r_{t+2}+\dots))=r_t+\gamma R_{t+1}\]即当前时刻的奖励等于当前时刻的即时奖励加上下一时刻的奖励乘上折扣因子\(\gamma\)。
如果\(\gamma=0\),意味着只看当前奖励;
如果\(\gamma=1\),意味着环境是确定的,相同的动作总会获得相同的奖励(也就是cyclic Markov processes)。
因此实际中\(\gamma\)往往取类似0.9这样的值。因此我们的任务变成了找到一个策略,最大化将来的奖励R。

您的打赏,是对我的鼓励
