RL » 强化学习(十)——Integrating Learning and Planning(1)
2019-10-03 :: 4595 Words博弈论(续)
高风险下的纳什均衡
在一些特殊情况下,即使犯错误的可能性很小也可能导致大的灾难(比如核电站,出问题就非常严重),纳什均衡就可能不会产生有说服力的解释。考虑如下博弈:
| 乙 | |||
| 左 | 右 | ||
| 甲 | 上 | 8,10 | -1000,9 |
| 下 | 7,6 | 6,5 | |
在这个博弈中,参与人甲会选择“下”,因为如果乙不小心(低概率)犯错误,要避免产生右上的灾难性情况。
这个例子说明,个体可能不想我们所假设的那样完全理性,在遇到高风险的情况下,人们会考虑风险,从而使得最终结果可能偏离纳什均衡战略。
智猪博弈问题
智猪博弈问题是John Nash于1950年提出的问题。
在一个猪圈里养着一头大猪和一头小猪,在猪圈的一端放有一个猪食槽,在另一端安装有一个按钮,它控制着猪食的供应量。假定:
- 猪按一下按钮,就有8单位猪食进槽,但谁按按钮就会首先付出2单位成本;
- 若大猪先到食槽,则大猪吃到7单位食物,而小猪仅能吃到1单位食物;
- 若小猪先到,则大猪和小猪各吃到4单位食物;
- 若两猪同时到,则大猪吃到5单位,小猪仅吃到3单位。
显然,在这里按按钮有两个成本:
- 直接成本:2单位成本。
- 间接成本:先按按钮的猪,肯定会最后到达食槽。
因此,这个问题写成策略矩阵,则是:
| 小猪 | |||
| 按 | 等待 | ||
| 大猪 | 按 | 3,1 | 2,4 |
| 等待 | 7,-1 | 0,0 | |
该博弈不存在占优战略均衡,因为尽管小猪有一个严格占优战略,但大猪并没有占优战略。
为了解决这个问题,Nash提出了重复剔除的占优战略均衡(iterated dominance equilibrium)。
其具体做法如下:
Step 1:大猪没有劣战略,策略保持不变。
Step 2:小猪有一个劣战略: “按”。
“按”的支付值: 1, -1
“等待”的支付值: 4, 0
Step 3:剔除小猪的劣战略“按”。
Step 4:剔除之后,大猪有一个劣战略:“等待”。
Step 5:剔除大猪的劣战略“等待”,剩下最后一个战略组合:
大猪:“按” + 小猪:“等待”
在小企业经营中,学会如何“搭便车”是一个精明的职业经理人最为基本的素质。在某些时候,如果能够注意等待,让其他大的企业首先开发市场,是一种明智的选择。这时候有所不为才能有所为!
最大最小策略
0阶理性共识:每个人都是理性的,但不知道其他人是否是理性的;
1阶理性共识:每个人是理性的,并且知道其他每个人也都是理性的,但并不知道其他人是否知道自己是理性的;
2阶理性共识:每个人是理性的,并且知道其他每个人也都是理性的,并且知道其他人知道自己是理性的,但不知道其他人是否知道自己知道其他人都是理性的。。。。。。。3阶、4阶。。。n阶依次类推。
重复剔除不仅要求每个人是理性的,而且要求每个人知道其他人都是理性的,每个人知道每个人知道每个人是理性的,如此等等,即理性是“共识”。
优势策略均衡与纳什均衡的概念是建立在博弈者理性行为的基础上的,任何出现的一点错误将可能使博弈者蒙受巨大的损失,因而可能有player会采取比较保守的策略。
其中一种保守的策略是最大最小策略(Maximin strategy)。
它是指博弈者所采取的策略是使自己能够获得的最小收入最大化。所谓最小收入是指采取某种策略所能获得的最小收入。
最大最小策略是一种保守的策略而不是利润最大化的策略。
很显然,博弈者往往是在信息不完全的情况下才采取最大最小策略。在信息完全的情形下,他肯定是会采取促使他利润最大化的策略。
在囚徒困境问题中,两人都坦白是最大最小策略,而两人都抵赖则是利润最大化策略。
最大最小均衡存在以下问题:
-
“最大最小”均衡没有考虑到局中人之间在策略选择上的互动。
-
由“最大最小”方法得到的“均衡”很难说是一种“均衡”。
策梅洛定理
在二人完美信息回合制抽象策略游戏中,以下三者有且只有一项成立:
1、先手方有必胜策略;
2、后手方有必胜策略;
3、双方的最优策略将会导向平局。
后手方有优势的对称棋类游戏是存在的,比如动物将棋。
参考:
https://www.zhihu.com/question/452293747
根据策梅洛定理,中国象棋是不是应该红方必胜或必和棋?
其他博弈问题
当年英国政府将流放澳洲的犯人交给往来于澳洲之间的商船来完成,由此经常会发生因商船主或水手虐待犯人,致使大批流放人员因此死在途中(葬身大海)的事件发生。
后来大英帝国对运送犯人的办法(制度)稍加改变,流放人员仍然由往来于澳洲的商船来运送,只是运送犯人的费用要等到犯人送到澳洲后才由政府按实到犯人人数支付给商船。
仅就这样一点小小的“改变”,几乎再也没有犯人于中途死掉的事情发生。
枪手博弈是指,在三个枪手A、B、C之间一场对决即将展开,枪手A的枪法最好,命中率达到80%;枪手B的枪法次之命中率60%;而枪手C的命中率最差只有50%。
而此时由于是三方对决,先瞄准谁成了关键,对于A枪手来说,当然先瞄准仅次于他的B枪手,但对于B和C枪手而言,威胁最大的当然是A,在A倒下后B面对C的胜率会大很多,同时C的存活率也会提高,所以枪口都会对上A。
结论:
-
第一轮枪战,枪法最差的C竟然存活概率最大——肯定存活,而枪法好的A和B存活概率远低于C。启示:韬晦很重要。
-
如果在第一轮枪战中A、B均被击中,则C成为最终幸存者;只要A、B在第一轮枪战中有一人存活,那最终胜出的很可能是A和B中的幸存者。启示:实力很关键。能力较差的C靠着策略虽然能在第一轮枪战中暂时获胜,但只要A、B在第一轮枪战中有一人存活,那么第二轮枪战里C的存活的概率就会比对手低了。
逆博弈论:很多案例不需要优化参与者的策略,而是围绕理智参与者的行为设计游戏,这就是逆博弈论。拍卖被认为是逆博弈论中的主要案例。
参考
https://www.cnblogs.com/steven-yang/tag/博弈论/
一个博弈论的专栏
https://mp.weixin.qq.com/s/5o3m8RLwYkZJEhqNxOLq_A
不对称多代理博弈中的博弈理论解读
https://mp.weixin.qq.com/s/D9bRjYVJOMT0Jkh59XZ-Rg
DeepMind于Nature子刊发文提出非对称博弈的降维方法
https://mp.weixin.qq.com/s/1t6WuTQpltMtP-SRF1rT4g
当博弈论遇上机器学习:一文读懂相关理论
https://news.mbalib.com/story/242878
智猪博弈、龟兔悖论、谷堆悖论…这些有趣的博弈论值得一看!
https://blog.csdn.net/qq_27351341/article/details/81119533
偏好函数、无差异曲线、帕累托标准、卡尔多-希克斯标准等基础概念
https://blog.csdn.net/qq_27351341/article/details/81138774
囚徒困境、智猪博弈、纳什均衡与一致预期
https://blog.csdn.net/qq_27351341/article/details/81268801
多重均衡与制度和文化
https://blog.csdn.net/qq_27351341/article/details/81276298
动态博弈、威胁与承诺
https://blog.csdn.net/sobermineded/article/details/79541511
几个经典博弈模型(囚徒的困境、赌胜博弈、产量决策的古诺模型)
https://mp.weixin.qq.com/s/5k6A4NExdb9Ysbd753pPHw
博弈论速成指南:那些融入深度学习的经典想法和新思路
Integrating Learning and Planning
前面的章节主要介绍了Model-Free RL,下面将讲一下Model-Based RL,主要包括如下内容:
-
如何从经历中直接学习Model。
-
如何基于模型来进行Planning(规划)。
-
如何将“学习”和“规划”整合起来。
 |
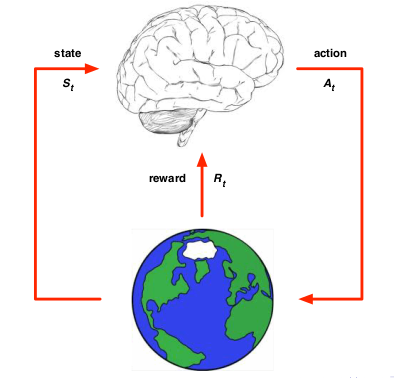 |
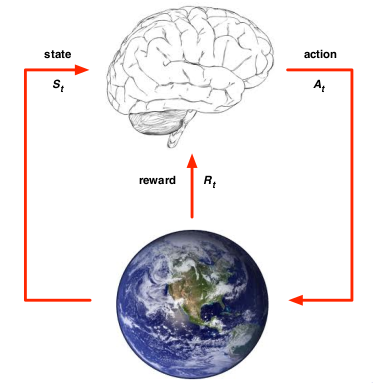
上面两图形象的说明了Model-Free RL(左图)和Model-Based RL(右图)的差别。
Model-Based RL
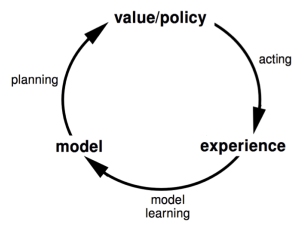
上图比较好的说明了模型学习在整个RL学习中的位置和作用。
我们首先看一下Model的定义:Model是一个参数化(参数为\(\eta\))的MDP<S, A, P, R>,其中假定:状态空间S和行为空间A是已知的,则\(M=<P_\eta, R_\eta>\),其中\(P_\eta \approx P, R_\eta \approx R\)。则:
\[S_{t+1} \sim P_\eta (S_{t+1} | S_t, A_t)\] \[R_{t+1} = R_\eta (R_{t+1} | S_t, A_t)\]通常我们需要如下的假设,即状态转移函数和奖励函数是条件独立的:
\[P[S_{t+1}, R_{t+1} | S_t, A_t] = P[S_{t+1} | S_t, A_t] P[R_{t+1} | S_t, A_t]\]Model Learning
所谓Model Learning是指:从experience\(\{S_1, A_1, R_2, \dots, S_T\}\),学习
\[S_1, A_1\to R_2,S_2\] \[S_2, A_2\to R_3,S_3\] \[\dots\] \[S_{T-1}, A_{T-1}\to R_T,S_T\]这实际上是一个监督学习的问题。其中,\(s,a\to r\)是一个回归问题(regression problem),而\(s,a\to s'\)是一个密度估计问题(density estimation problem)。
选择一个损失函数,比如均方差,KL散度等,优化参数\(\eta\)来最小化经验损失(empirical loss)。所有监督学习相关的算法都可以用来解决上述两个问题。
根据使用的算法不同,可以有如下多种模型:查表式(Table lookup Model)、线性期望模型(Linear Expectation Model)、线性高斯模型(Linear Gaussian Model)、高斯决策模型(Gaussian Process Model)、和深信度神经网络模型(Deep Belief Network Model)等。
这里主要以查表模型来解释模型的构建。

您的打赏,是对我的鼓励
