graphics » 图像处理理论(八)——Viola-Jones, 目标跟踪, Meanshift
2018-07-29 :: 5665 WordsLBP(续)
参考
http://blog.csdn.net/smartempire/article/details/23249517
LBP方法
http://blog.csdn.net/dujian996099665/article/details/8886576
LBP算法的研究及其实现
https://mp.weixin.qq.com/s/iFlnZ8z5baUdWCZxIGkq5g
机器学习实战——LBP特征提取
https://mp.weixin.qq.com/s/Kj1enaH_O-vVu3APDDX8sQ
如何在较暗环境进行人脸检测?
Fisherface
Fisherface由Peter N. Belhumeur, Joao P. Hespanha和David J. Kriegman于1997年提出。
Peter N. Belhumeur,Brown University本科(1985)+Harvard University博士(1993),Yale University和Columbia University教授。
Joao P. Hespanha,Instituto Superior Técnico, Lisbon, Portugal本硕(1991,1993)+ Yale University博士。UCSB教授。
David J. Kriegman,Princeton University本科(1983)+Stanford University硕博(1984,1989)。UCSD教授。
论文:
《Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection》
Eigenfaces的主要原理基于PCA,而Fisherface的主要原理基于LDA(参见《机器学习(三十一)》)。这里不再赘述。
参考:
http://blog.csdn.net/smartempire/article/details/23377385
Fisherface(LDA)
Viola-Jones
Viola-Jones方法由Paul Viola和Michael Jones于2001年提出。
Paul Viola,MIT本科(1988)+博士(1995)。先后在微软、Amazon担任研究员。
Michael Jones,MIT博士(1997)。现为Mitsubishi electric research laboratories研究员。
论文:
《Rapid Object Detection using a Boosted Cascade of Simple Features》
《Robust real-time face detection》
《An Extended Set of Haar-like Features for Rapid Object Detection》
《Learning Multi-scale Block Local Binary Patterns for Face Recognition》
《Implementing the Viola-Jones Face Detection Algorithm》
概述
和之前的方法不同,Viola-Jones不仅是一个算法,更是一个框架,前DL时代的人脸检测一般都采用该框架。其准确度也由Fisherface时代的不到70%,上升到90%以上。当然,这里所用的数据集以今天的眼光来看,只能算作玩具了——基本都是正面、无遮挡的标准照,光照也比较理想。但不管怎么说,这也是第一个进入商业实用阶段的目标检测框架,目前(2016),大多数的商业化产品仍然基于该框架。
Viola-Jones框架主要有三个要点:
1.Haar-like特征,AdaBoost算法和Cascade结构。Haar-like特征利用积分图像(Integral Image)快速的计算矩形区域的差分信号;
2.AdaBoost算法选择区分能力强的特征结合Stump函数做弱分类器,然后把若干这些弱分类器线性组合在一起增强分类性能;
3.Cascade结构做Early decision快速抛弃明显不是人脸的扫描窗口。
下面我们分别描述一下这几个要点。
Integral image
Integral image一种计算差分数据的快速方法。
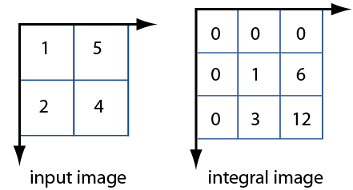
上图左侧是图像的像素值,右侧是相应的积分图。
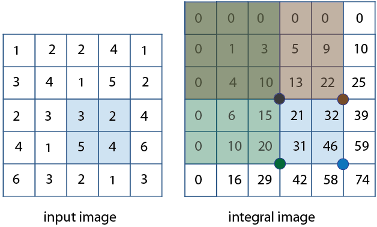
由\(46 – 22 – 20 + 10 = 14\),我们可以很快计算出左侧蓝色区域的像素值之和。
参考:
http://www.mathworks.com/help/vision/ref/integralimage.html
Integral image
Cascade分类器
Cascade分类器,简单来说,就是先将几个通过Adaboost方法得到的强分类器进行排序,排序原则是简单的放在前边。因为通常来说人脸只占一小部分,所以可以很放心地在前几层分类器就拒绝掉大部分非人脸区域。只要前一级拒绝了,就不在进入下一级分类器,这可以大大提高速度。其本质是一颗退化决策树。
史前时代
Viola-Jones实际上已经是第二代框架了。早期的目标检测(00年以前)没有遵循滑动窗口检测等统一的检测理念。当时的检测器通常基于如下低层和中层的视觉设计,即将目标检测定义为测量对象组件、形状和轮廓之间的相似性,包括距离变换、形状上下文、小边特征等。这类方法在复杂的检测问题上,进展得并不顺利。
参考:
https://mp.weixin.qq.com/s/_Rm37O2gS-C_HIccZjPWrg
近20年最权威的目标检测总结
参考
https://www.jianshu.com/p/024ad859c8de
人脸检测的Viola-Jones方法
https://blog.csdn.net/laiqun_ai/article/details/46761437
从Viola&Jones的人脸检测说起
http://www.cnblogs.com/hrlnw/archive/2013/10/23/3374707.html
Viola Jones Face Detector
目标跟踪
概述
目标跟踪(object tracking)就是在连续的视频序列中,建立所要跟踪物体的位置关系,得到物体完整的运动轨迹。
目标跟踪分为单目标跟踪和多目标跟踪。本文如无特别指出,均指单目标跟踪。
通常的做法是:
1.在第1帧给一个bbox框住需要跟踪的物体。
2.在不借助重检测(re-detection)的情况下,尽可能长时间的跟住物体。
3.不能使用依赖外部特征的姿态估计(pose estimation)。
当然这是针对目标跟踪算法的要求,至于实际产品中,对象的重检测以及依赖外部特征的姿态估计都是必不可少的。
比如,自动驾驶领域的车辆跟踪,一般都会针对车辆的运动特点建立模型,以辅助目标跟踪。
TB50 & TB100
这个领域最著名的数据集是吴毅提出的OTB50 & OTB100,50和100分别代表视频数量。有的论文也把它们称作OTB-2013和OTB-2015。
吴毅,中国科学院自动化研究所博士(2009年)。南京审计大学副教授。
官网:
http://cvlab.hanyang.ac.kr/tracker_benchmark/
论文:
《Online object tracking: A benchmark》
《Object tracking benchmark》
上面的论文在TB数据集上比较了包括2012年及之前的29个顶尖的tracker,基本解决了统一标准的问题,因此也成为了目标跟踪领域的权威数据集。
《Object tracking: A survey》
这篇论文总结了2006年以前的目标跟踪算法。
VOT
VOT竞赛数据集是另一个常用数据集。官网:
http://votchallenge.net/challenges.html
OTB包括25%的灰度序列,但VOT都是彩色序列,这也是造成很多颜色特征算法性能差异的原因。
目标跟踪的难点
![]()
![]()
目标跟踪算法的分类
![]()
上图是目标跟踪算法的分类,下表是具体分类和代表算法。
![]()
点跟踪:在连续帧中检测到的目标被表达为点。这种方法需要引入其它方法来进行目标检测。
核跟踪:关联与目标的形状和外观表达。核函数可以是关联与一个直方图的矩形或椭圆模板。目标通过在连续帧中计算核的运动来跟踪。运动可以是参数形式的平移、旋转或仿射等。
轮廓跟踪:由在每帧中估计目标区域进行跟踪。轮廓跟踪方法用到的信息可以是外观密度和形状模型。给定目标模型,轮廓由形状匹配或轮廓推导得到。这些方法都可以视作时域上的目标分割。
按照是否依赖先验知识可分为两类:
1.不依赖于先验知识,直接从图像序列中检测到运动目标,并进行目标识别,最终跟踪感兴趣的运动目标;
2.依赖于目标的先验知识,首先为运动目标建模,然后在图像序列中实时找到相匹配的运动目标。
按照摄像机是否固定,可分为:
1.静态背景。
2.运动场。摄像机的运动形式可以分为两种:a)摄像机的支架固定,但摄像机可以偏转、俯仰以及缩放; b)将摄像机装在某个移动的载体上。
经典的目标跟踪算法主要有:meanshift、camshift、Kalman filter、particle filter、Optical flow、TLD、KCF、Struck等。
参考:
https://blog.csdn.net/app_12062011/article/details/48436959
目标跟踪算法的分类(一)
https://blog.csdn.net/app_12062011/article/details/51760256
目标跟踪算法的分类(二)
https://blog.csdn.net/app_12062011/article/details/52277537
目标跟踪算法的分类(三)
参考
https://www.zhihu.com/question/26493945
计算机视觉中,目前有哪些经典的目标跟踪算法?
https://mp.weixin.qq.com/s/Wz-loMz1oOlxtm10gazQRg
目标检测(Object Detection)和目标跟踪(Object Tracking)的区别
https://mp.weixin.qq.com/s/XJ5uVzYULWHLRjhb5iE8Qg
一文读懂图像定位及跟踪技术
https://mp.weixin.qq.com/s/OqMqQRwI5c6H6FzvgdwWfg
目标追踪综述
https://mp.weixin.qq.com/s/_BVJZxY0TiS18nGgb88LVw
视觉目标跟踪漫谈:从原理到应用
https://zhuanlan.zhihu.com/p/257854666
VOT2020-ST Winner(RPT/RPTS)算法方案分享
https://mp.weixin.qq.com/s/RkUDFJtlSAa2AI65UA33qw
视频目标跟踪从0到1,概念与方法
https://mp.weixin.qq.com/s/bk1-N1RjeKb_1A29n8o15Q
目标跟踪入门篇-相关滤波
Meanshift
Meanshift聚类
Meanshift(均值漂移)首先是个聚类算法,然后才应用到目标跟踪领域。它是Keinosuke Fukunaga和Larry D. Hostetler于1975年发明的。
Keinosuke Fukunaga,日本裔美国科学家,普渡大学教授。著有《Introduction to Statistical Pattern Recognition》一书。
我们首先来定义一下Mean Shift向量。
对于给定的d维空间\(R^d\)中的n个样本点\(x_i, i=1,\cdots , n\),则对于x点,其Mean Shift向量的基本形式为:
\[M_h\left ( x \right )=\frac{1}{k}\sum_{x_i\in S_h}\left ( x_i-x \right )\]其中,\(S_h\)指的是一个半径为h的高维球区域,如上图中的蓝色的圆形区域。\(S_h\)的定义为:
\[S_h\left ( x \right )=\left ( y\mid \left ( y-x \right )\left ( y-x \right )^T\leqslant h^2 \right )\]从物理的角度来看,由于\(\frac{1}{k}\sum_{x_i\in S_h}x_i\)实际上是\(S_h\)的质量中心,因此\(M_h\left ( x \right )\)实际上就是从x指向质心的向量,也被叫做归一化的概率密度梯度。所以,Meanshift聚类实际上是一种密度聚类。
下面来看一下Meanshift算法的具体步骤。
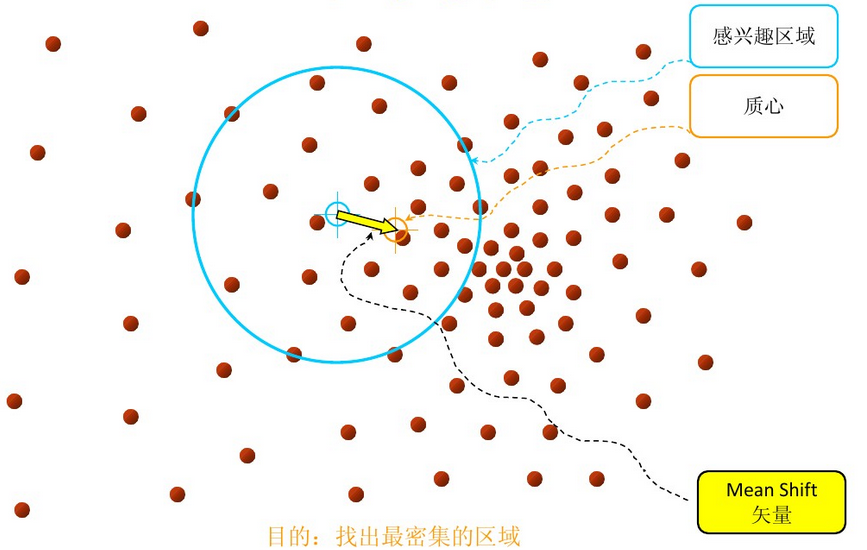
首先,在空间中任选一点x(上图中蓝色的圈),以x为圆心,h为半径做一个高维球(上图中蓝色的圆)。计算得到质心(上图中黄色的圈)。移动x到质心,并重复之前的步骤。最终x会收敛到最密集区域的质心。

您的打赏,是对我的鼓励
