DRL » 深度强化学习(四)——A2C & A3C, DDPG, TD3, PPO
2019-06-19 :: 6518 WordsA2C & A3C
Actor-Critic一般简称AC算法。针对它的一般用法参见《强化学习(八)》。
AC算法也可用于DRL领域,具体的做法和DQN类似:
-
一个Actor网络,用来近似V值。
-
一个Critic网络,用来近似Q值。
这里有个小技巧:
Actor网络和Critic网络可以共享网络参数,两者仅最后几层使用不同结构和参数。(参见下图A3C的图)
针对AC的改进,衍生出了A2C和A3C。
Advantage Actor-Critic(A2C):advantage function + AC
Asynchronous Advantage Actor-Critic(A3C):Async + A2C
advantage function的含义参见《强化学习(八)》,这里谈谈A3C。
A3C
论文:
《Asynchronous Methods for Deep Reinforcement Learning》
在《强化学习(七)》的Experience Replay一节,我们指出训练数据间的相关性会影响算法收敛到最优解。
除了Experience Replay之外,异步更新也是一种有效的消除训练数据间相关性的方法。
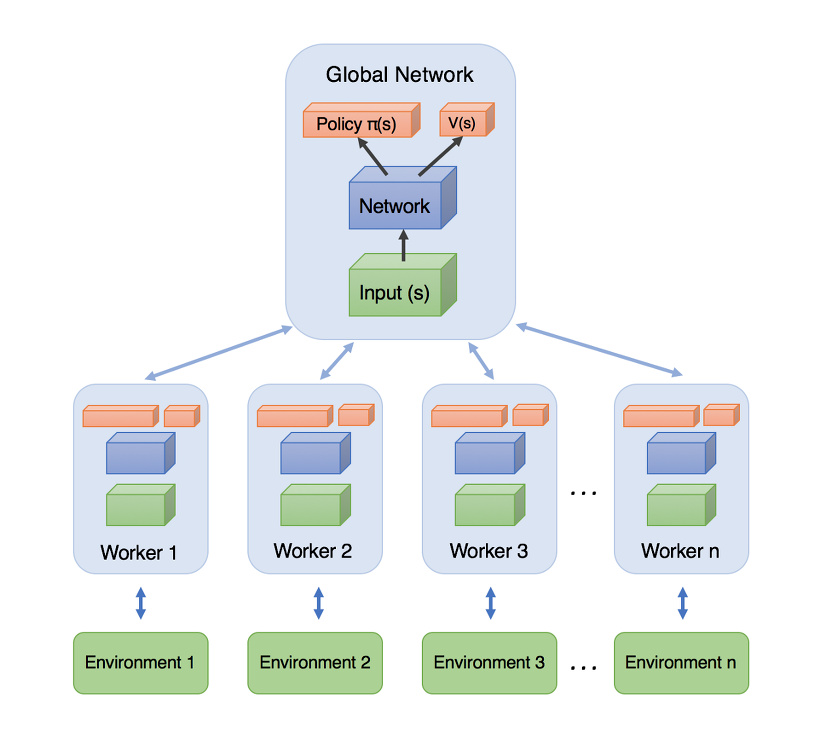
上图是A3C的网络结构图。它实际上就是将A2C放在了多个线程中进行同步训练。可以想象成几个人同时在玩一样的游戏,而他们玩游戏的经验都会同步上传到一个中央大脑。然后他们又从中央大脑中获取最新的玩游戏方法。
A3C的原始论文运行在CPU上,这里还有一个GPU版本:
《GA3C: Reinforcement Learning through Asynchronous Advantage Actor-Critic on a GPU》
代码:
https://github.com/NVlabs/GA3C
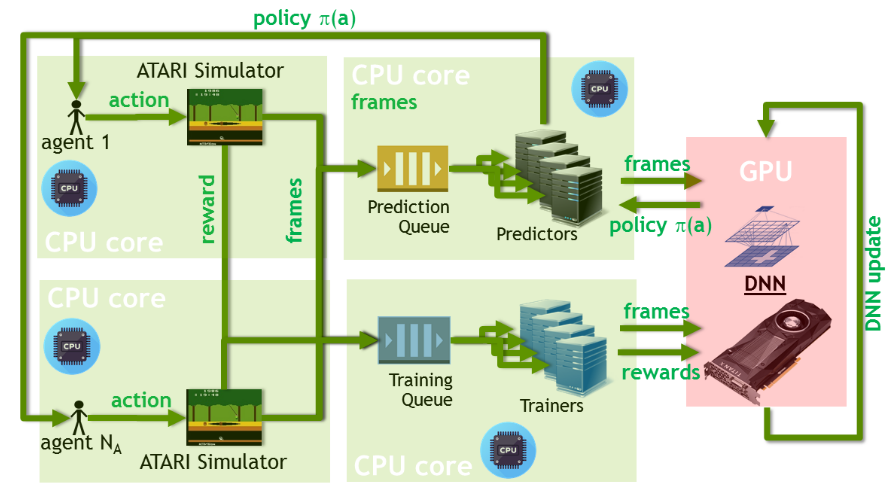
这是GA3C的网络结构图。
AC vs. GAN
论文:
《Connecting Generative Adversarial Networks and Actor-Critic Methods》
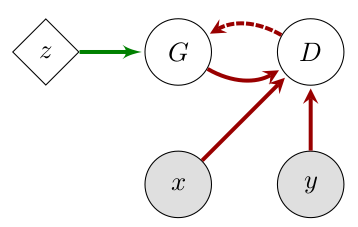 |
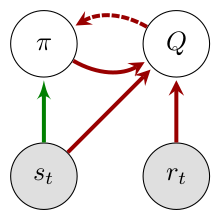 |
左图是GAN,右图是AC。
| Method | GANs | AC |
|---|---|---|
| Freezing learning | yes | yes |
| Label smoothing | yes | no |
| Historical averaging | yes | no |
| Minibatch discrimination | yes | no |
| Batch normalization | yes | yes |
| Target networks | n/a | yes |
| Replay buffers | no | yes |
| Entropy regularization | no | yes |
| Compatibility | no | yes |
参考
https://zhuanlan.zhihu.com/p/51645768
强化学习AC、A2C、A3C算法原理与实现!
https://mp.weixin.qq.com/s/c4xoy4CJ_hsVdmGe1n3rTQ
A3C——一种异步强化学习方法
https://mp.weixin.qq.com/s/5kI72vg4JNAZWD93EYAUWA
直观的强化学习算法(A2C)
https://blog.csdn.net/u013236946/article/details/73195035
A3C
https://zhuanlan.zhihu.com/p/70360272
最前沿:深度解读Soft Actor-Critic算法
https://mp.weixin.qq.com/s/R308ohdMU8b7Ap4CLofvDg
OpenAI开源算法ACKTR与A2C:把可扩展的自然梯度应用到强化学习
DDPG
论文:
《Continuous control with deep reinforcement learning》
DDPG主要从:PG->DPG->DDPG发展而来。
Policy Gradient的概念参见《强化学习(七)》,这里不再赘述。
DPG
Deterministic Policy Gradient是Deepmind的D.Silver等在2014年提出的,即确定性的行为策略,每一步的行为通过函数\(\mu\)直接获得确定的值:
\[a_{t} = \mu(s_{t} | \theta^{\mu})\]换句话说就是:PG的action是采样出来的,而DPG是算出来的。
为何需要确定性的策略?简单来说,PG方法有以下缺点:
-
即使通过PG学习得到了随机策略之后,在每一步行为时,我们还需要对得到的最优策略概率分布进行采样,才能获得action的具体值;而action通常是高维的向量,比如25维、50维,在高维的action空间的频繁采样,无疑是很耗费计算能力的;
-
在PG的学习过程中,每一步计算policy gradient都需要在整个action space进行积分:
这个积分我们一般通过Monte Carlo 采样来进行估算,需要在高维的action空间进行采样,耗费计算能力。
- 如果采取简单的Greedy策略,即每一步求解\(\arg\max_a Q(s,a)\)也不可行,因为在连续的、高维度的action空间,如果每一步都求全局最优解,太耗费计算性能。
当然,反过来说,DPG也有一个缺点:无法探索环境。因此,在DPG的实际使用中,我们要采用其他策略来弥补这个缺点。
Noisy
在介绍Rainbow的时候,我们提到了NoisyNet,但没有展开,这里可以说说Noisy在DRL中的作用。
Noisy在DRL中的用法主要有:
-
Noise on Action。就是随机乱选。
-
Noise on Parameters。这种方法由于网络结构不变,参数也不是全换,因此相当于是有约束的随机选择,或者说是有系统的尝试。
在DPG中,一般采用第二种方法。
需要注意的是,参数的改变意味着策略的改变,因此,Noise在episode中需要保持不变,这样才能检测随机策略的真正效果。否则就是无目的的乱抖了。(类似帕金森症)
产生噪声的方法有:
-
Independent Gaussian noise。
-
Factorised Gaussian noise。
DDPG
Deepmind在2016年提出了DDPG(Deep Deterministic Policy Gradient)。从通俗角度看:DDPG=DPG+A2C+Double DQN。
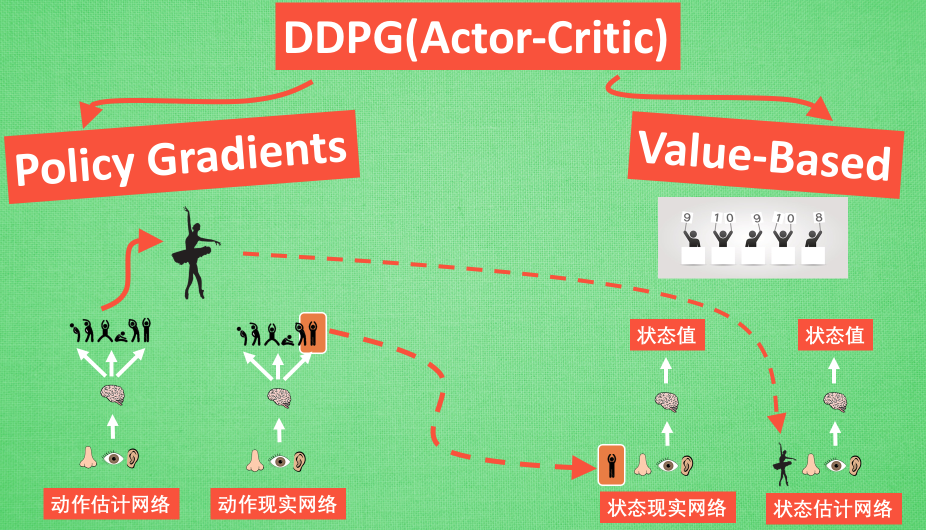
上图是DDPG的网络结构图。仿照Double DQN的做法,DDPG分别为Actor和Critic各创建两个神经网络拷贝,一个叫做online,一个叫做target。即:
-
Actor(策略网络) online network(动作估计网络)
-
Actor(策略网络) target network(动作现实网络)
-
Critic(Q网络) online network(状态估计网络)
-
Critic(Q网络) target network(状态现实网络)
简单来说就是,Actor online network和Critic online network组成一对Actor-Critic;而Actor target network和Critic target networ组成另一对Actor-Critic。
当然,DDPG实际的步骤远比示意图复杂的多,可参见下图,这里不再赘述。
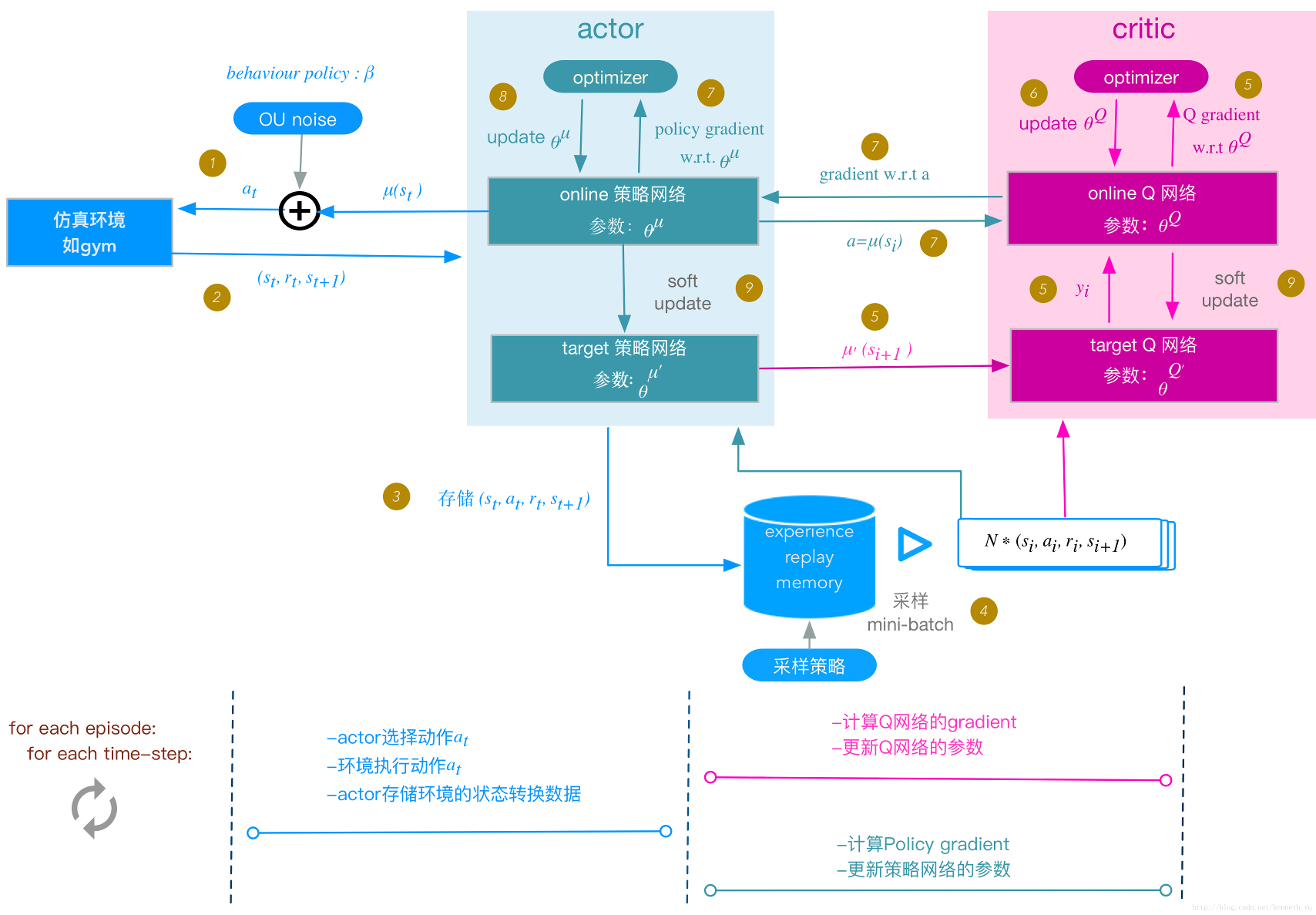
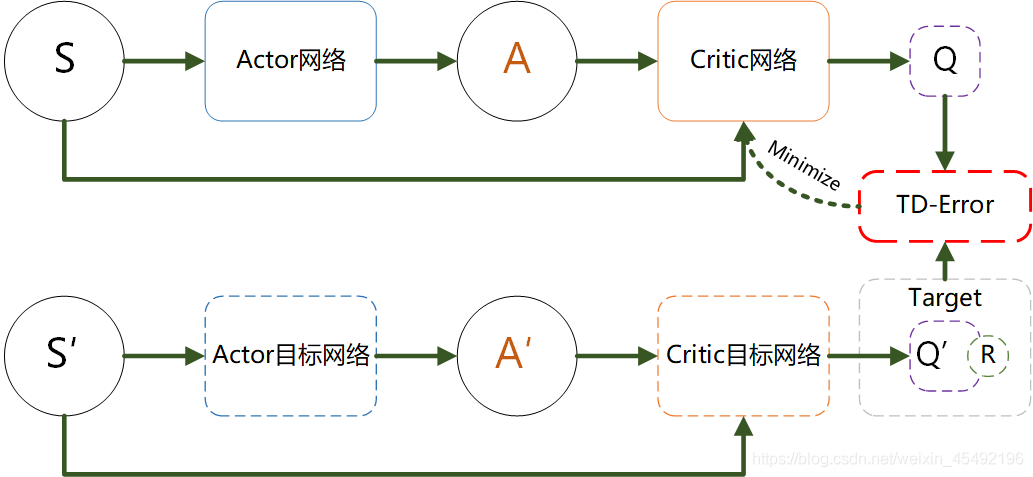
DDPG还有一个分布式版本。
论文:
《Distributed Distributional Deterministic Policy Gradients》
参考
https://mp.weixin.qq.com/s/dgLJrn3omUKMqmqTIEcoyg
Tensorflow实现DDPG
https://github.com/jinfagang/rl_atari_pytorch
ReinforcementLearning Learn Play Atari Using DDPG and LSTM.
https://zhuanlan.zhihu.com/p/65931777
强化学习-基于pytorch的DDPG实现
https://mp.weixin.qq.com/s/p2jF2Awmgeem-XGCkix-Lg
深度确定性策略梯度DDPG详解
https://mp.weixin.qq.com/s/_dskX5U8gHAEl6aToBvQvg
从Q学习到DDPG,一文简述多种强化学习算法
https://www.zhihu.com/question/323420831
强化学习中A3C/DDPG/DPPO哪个效果更好?
https://blog.csdn.net/gsww404/article/details/80403150
从确定性策略(DPG)到深度确定性策略梯度(DDPG)算法的原理讲解及tensorflow代码实现
https://blog.csdn.net/qq_39388410/article/details/88828548
强化学习(DDPG,AC3,DPPO)
https://blog.csdn.net/qq_30615903/article/details/80776715
DDPG(Deep Deterministic Policy Gradient)算法详解
https://blog.csdn.net/kenneth_yu/article/details/78478356
DDPG原理和算法
https://zhuanlan.zhihu.com/p/27699682
荐译一篇通俗易懂的策略梯度(Policy Gradient)方法讲解
TD3
TD3:Twin Delayed Deep Deterministic Policy Gradient

TD3 = DDPG + DDQN
- Twin
TD3在DDPG的基础上,借鉴DDQN的思想,把Critic分成了两个网络,表示不同的Q值,通过选取最小的那个作为我们更新的目标(Target Q Value),抑制持续地过高估计。
过估计是指估计的值函数比真实的值函数大。因为DQN是一种off-policy的方法,每次学习时,不是使用下一次交互的真实动作,而是使用当前认为价值最大的动作来更新目标值函数,所以会出现对Q值的过高估计。(处于学习阶段的Q值,显然不是真正最优的Q值)
- Delayed
Critic更新多次后,Actor再进行更新。即让critic更加确定,actor再行动。
参考:
https://blog.csdn.net/weixin_45492196/article/details/107866309
TD3算法:DDPG的进化
PPO
Proximal Policy Optimization
TRPO(Trust Region Policy Opimization,2015):考虑到连续动作空间无法每一个动作都搜索一遍,因此大部分情况下只能靠猜。如果要猜,就最好在信任域内部去猜。而TRPO将每一次对策略的更新都限制了信任域内,从而极大地增强了训练的稳定性。
TRPO引入KL散度评估信任域,这被后来的PPO算法吸收并改进。
PPO是2017年由OpenAI提出的一种基于随机策略的DRL算法,也是当前OpenAI的默认算法。
PPO是一种Actor-Critic算法。它的主要改进在它的Actor部分。
我们知道,Policy Gradient算法的训练过程中,始终存在着new Policy和old Policy这样一对矛盾。
一方面,我们需要new Policy和old Policy有一定的差异,防止模型收敛到局部最优。
另一方面,两者的差异又不能太大,否则,模型的训练将无法收敛。
那么,如何衡量new Policy和old Policy的差异程度呢?
PPO的答案是:我们可以用两种Policy得到的动作的概率分布的KL散度,来描述这种差异。
具体的做法是在\(J(\theta)\)上添加一个KL惩罚项:
\[J^{\theta^k}_{PPO}(\theta)=J^{\theta^k}(\theta)-\beta KL(\theta, \theta^k)\]这里的惩罚系数\(\beta\)可以是定值,也可以是一个自适应的值。例如,我们可以在KL值小于最小阈值时,减小\(\beta\),在KL值大于最大阈值时,增大\(\beta\)。
除了KL惩罚项之外,还可以使用clip来限制Gradient的大小,这就是PPO2的做法。
和A3C类似,PPO也有一个分布式版本,叫做DPPO(Distributed Proximal Policy Optimization)。
Online Policy RL:边玩边学,用自己最新的数据更新自己。典型算法:PPO、A2C、REINFORCE。
Offline Async RL:读旧日志、分布式异步训练,学一个新策略。典型算法:BCQ、CQL、TD3+BC 等离线算法 + 异步分布式框架(如 AReaL、RollFlash)。
参考:
https://www.jianshu.com/p/f4d383b0bd4c
TRPO与PPO实现
https://mp.weixin.qq.com/s/09JCUUhsXKhvYGfXT2gDLg
解读TRPO论文,深度强化学习结合传统优化方法
https://bluefisher.github.io/2018/07/03/Proximal-Policy-Optimization-Algorithms/
Proximal Policy Optimization Algorithms
https://www.jianshu.com/p/9f113adc0c50
Proximal Policy Optimization(PPO)算法原理及实现!
https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/6-4-DPPO/
Distributed Proximal Policy Optimization(DPPO)
https://mp.weixin.qq.com/s/3uzx54YtqPeG6EDCVTE0YA
24分钟让AI跑起飞车类游戏(Distributed PPO)
https://mp.weixin.qq.com/s/sbE44zbyRpFyfQKYByBXzA
深度强化学习之:PPO训练红白机1942

您的打赏,是对我的鼓励
