DRL » 深度强化学习(八)——MARL, StarCraft
2020-01-06 :: 5908 WordsMARL
Multi-agent Reinforcement Learning(MARL),一般被称为多智能体强化学习。与之相对的则是Single-agent Reinforcement Learning(SARL)。
书籍:
http://www.masfoundations.org/download.html
《MULTIAGENT SYSTEMS Algorithmic, Game-Theoretic, and Logical Foundations》
以下主要参考了如下文章:
https://zhuanlan.zhihu.com/p/39037444
多智能体强化学习笔记 01
https://zhuanlan.zhihu.com/p/43579796
多智能体强化学习笔记 02
论文:
《Multi-agent reinforcement learning: An overview》
《Game Theory and Multi-agent Reinforcement Learning》
《Is multiagent deep reinforcement learning the answer or the question? A brief survey》
MARL应用了大量博弈论的知识,可参见《强化学习(十)》。
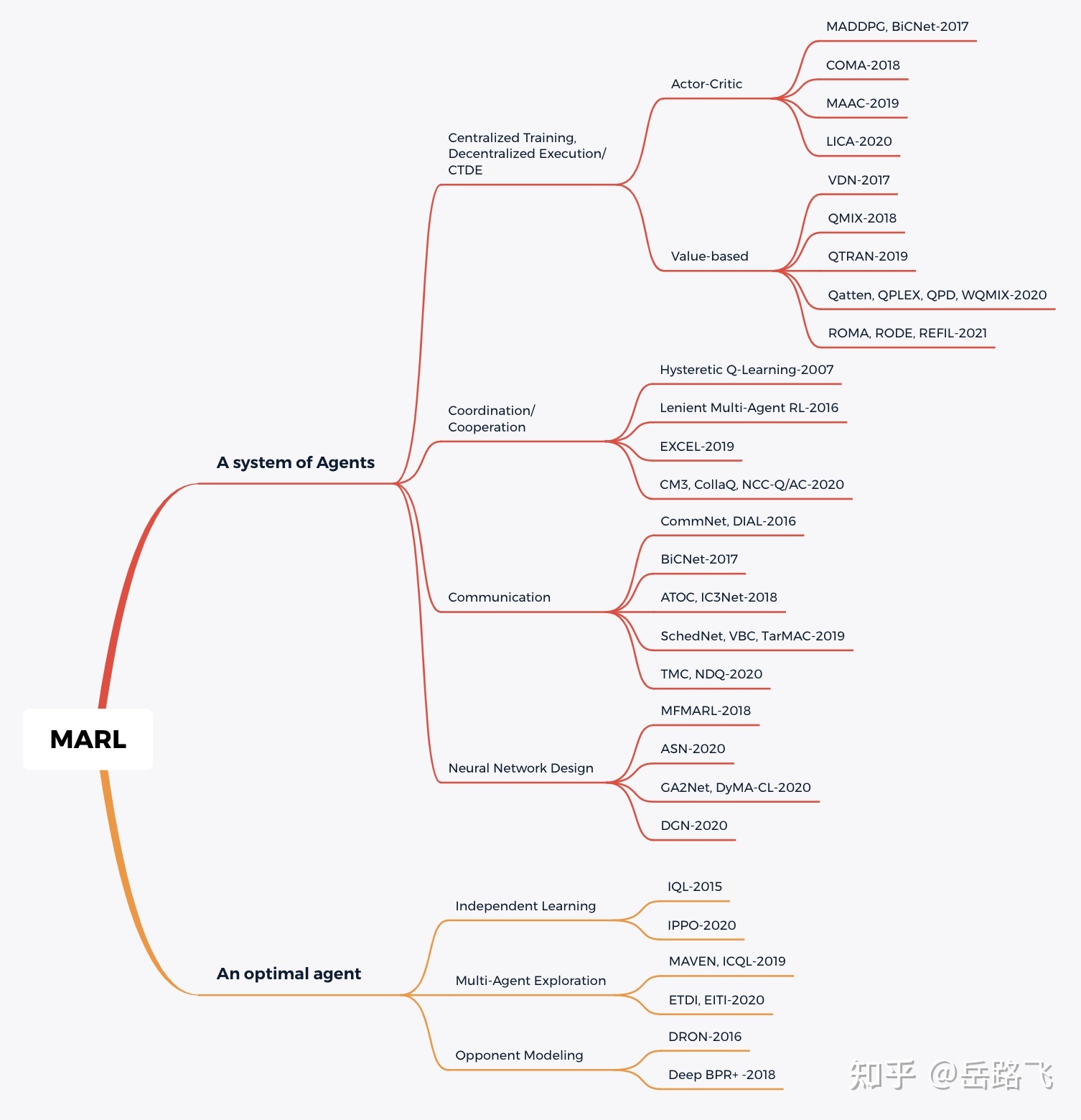
多智能体学习有三种范式:集中式学习、独立式学习和集中式训练分布式执行(Centralized Training with Decentralized Execution, CTDE)。
集中式学习将整个系统视为一个整体,采用单智能体强化学习算法训练,解决了环境非平稳问题,但需要上帝视角全局通信,无法解决无通信、大规模和大动作空间的问题;
独立式学习让每个智能体独立训练自己的策略,忽视了多智能体系统的特性,带来环境极不平稳问题;
集中式训练分布式执行作为折中,训练时拥有上帝视角,执行时独立决策,一定程度上解决了上述问题,是一种比较好的方法。
https://zhuanlan.zhihu.com/p/349092158
多智能体强化学习路线图 (MARL Roadmap)
我们使用如下示例,探讨一下什么是MARL?
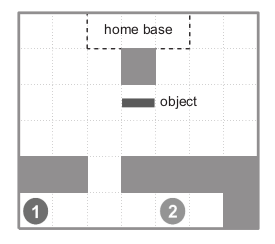
上图是两个智能体1、2将金条(object)搬运回家的例子。这根金条需要两个人一人抬着一边才能扛回家。
要想把金条扛回家,小红和小蓝必须先绕过障碍物,然后每个人到达金条的一边,扛起金条后,两人还得绕开家门口的障碍物,这样才能将金条扛回家。
从上面的问题可以看出,MARL至少应该包括如下几个要素:
-
在多智能体系统中至少有两个智能体。
-
智能体之间存在着一定的关系,如合作关系(如本例),竞争关系(如多人游戏),或者同时存在竞争与合作的关系。
-
每个智能体最终所获得的回报不仅仅与自身的动作有关系,还跟对方的动作有关系。如本例中每个智能体要想获得回报,必须是金条被两个智能体一起搬回家。
SARL用MDP来描述,而MARL则需要用Markov game(马尔科夫博弈,又称随机博弈(stochastic game))来描述。
类似于MDP,Markov game可形式化表示为:
\[(n,S,A_1,\dots,A_n,T,\gamma,R_1,\dots,R_n)\]n为玩家的个数,在本例中n为2。
S为系统状态,一般指多智能体的联合状态,即每个智能体的联合状态。
T为状态转移函数,指给定玩家当前状态和联合行为时,下一状态的概率分布。
R为回报函数。它描述了多智能体之间的关系。当每个智能体的回报函数一致时,则表示智能体之间是合作关系;当回报函数相反时,则表示智能体之间是竞争关系,当回报函数介于两者之间,则是混合关系。
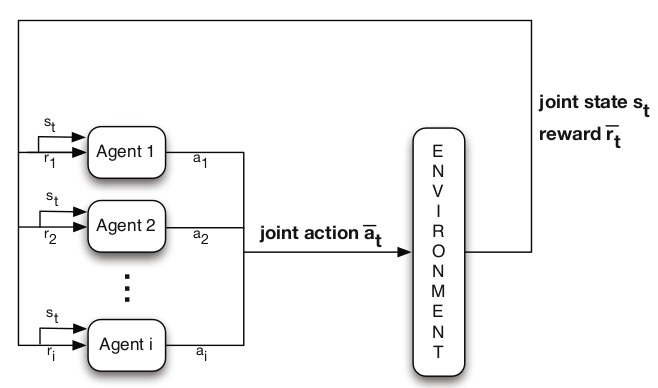
MARL的结构一般如下图所示。
静态博弈:static/stateless game是指没有状态s,不存在动力学使状态能够转移的博弈。例如一个矩阵博弈。
阶段博弈:stage game,是随机博弈的组成成分,状态s是固定的,相当于一个状态固定的静态博弈,随机博弈中的Q值函数就是该阶段博弈的奖励函数。若干状态的阶段博弈组成一个随机博弈。
重复博弈:智能体重复访问同一个状态的阶段博弈,并且在访问同一个状态的阶段博弈的过程中收集其他智能体的信息与奖励值,并学习更好的Q值函数与策略。
MARL的目标是找到每一个状态的纳什均衡策略,然后将这些策略联合起来。
| Game setting | ||||
| Stateless Games | Team Markov Games | General Markov Games | ||
| Information Requirement |
Independent Learners | Stateless Q-learning Learning Automata IGA FMQ Commitment Sequences Lenient Q-learners |
Policy Search Policy Gradient |
MG-ILA (WoLF-)PG Learning of Coordination Independent RL CQ-learning |
| Joint Action Learners | Distributed- Q Sparse Tabular Q Utile Coordination |
Nash-Q Friend-or-Foe Q Asymmetric Q Joint Action Learning Correlated-Q |
||
参考:
https://zhuanlan.zhihu.com/c_1061939147282915328
一个MARL方面的专栏
https://www.zhihu.com/people/yao-xing-hu/posts
一个MARL方面的专栏
https://github.com/LantaoYu/MARL-Papers
Paper list of multi-agent reinforcement learning (MARL)
https://mp.weixin.qq.com/s/5I8-_4Xsj8wzJwmDOQpkWQ
多智能体学习231页PPT总结
https://blog.csdn.net/qq_38163755/article/details/98057751
Game Theory and Multi-agent Reinforcement Learning笔记1
https://blog.csdn.net/qq_38163755/article/details/98223987
Game Theory and Multi-agent Reinforcement Learning笔记2
https://mp.weixin.qq.com/s/Yx0pfAJwOSQD2ABJd3gJSA
多智能体强化学习(MARL)近年研究概览
https://mp.weixin.qq.com/s/bQx-ydEAfijgK1Ii5ilPFQ
UCL汪军团队新方法提高群体智能,解决大规模AI合作竞争
https://mp.weixin.qq.com/s/4lj_G2z0Lbfk5mOgvxLC6w
对抗式协作:一个框架解决多个无监督学习视觉问题
https://mp.weixin.qq.com/s/0v57oHMEDcJuUivs8D5pnQ
善于单挑却难以协作,构建多智能体AI系统为何如此之难?
https://mp.weixin.qq.com/s/tME5GsKEXveVcgWb-Zbx_A
乔明达ICML 2018论文提出协作学习的鲁棒性方法
https://mp.weixin.qq.com/s/0Xuxr7CXqsxrssW2I6NCBQ
通用智能化:BAIR简述人类-机器人协作新技术
https://mp.weixin.qq.com/s/GNbCu1lbOmwJDCU3vgMbtQ
OpenAI发布多智能体深度强化学习新算法LOLA
https://mp.weixin.qq.com/s/5Go20MyBxdVI1r5SkwA6lw
面向星际争霸:DeepMind提出多智能体强化学习新方法
https://mp.weixin.qq.com/s/TlcVxjhHXXGSpIvptC4H8g
使用Gym和CNN构建多智能体自动驾驶马里奥赛车
https://mp.weixin.qq.com/s/zRcq1LMtK72Cl4T3877tgQ
牛津教授吐槽DeepMind心智神经网络,还推荐了这些多智能体学习论文
https://mp.weixin.qq.com/s/qU6XD45RGeMI-T7GI0dg2Q
OpenAI竞争性自我对抗训练:简单环境下获得复杂的智能体
https://mp.weixin.qq.com/s/cUFSaHWGKhyZhEvRdX09hw
谷歌大脑QT-Opt算法,机器人探囊取物成功率96%
https://mp.weixin.qq.com/s/xxB1lsiQxSfaHPKwZUI9bw
拔掉机器人的一条腿,它还能学走路?——三次元里优化的DRL策略
https://mp.weixin.qq.com/s/e4hriDvTRLkg-mIifVWayw
如何解决深度学习中的多体问题
https://mp.weixin.qq.com/s/Js8lvoqtl7vcwdw3i7UOHg
多智能体(MARL)强化学习与博弈论
https://zhuanlan.zhihu.com/p/61060358
Paper survey: Multi-Agent Reinforcement Learning
https://zhang-yi-chi.github.io/2019/08/15/cooperative-multi-agent-rl/
Cooperative Multi-Agent Reinforcement Learning
https://mp.weixin.qq.com/s/pLN-FHNSDYPcKmJCa4vOYA
机器人在线“偷懒”怎么办?阿里研究出了这两套算法
https://mp.weixin.qq.com/s/dkJr29LqO2PdSR6ds7X2qg
协作多智能体强化学习中的回报函数设计
https://mp.weixin.qq.com/s/m18xiMRryXl_BoCxKVUbTA
多Agent强化学习综述
https://mp.weixin.qq.com/s/R12bVEDWpHydNair-P5TzA
多智能体深度强化学习中的Q值路径分解
https://mp.weixin.qq.com/s/1JJo0FgMVlhIy6R9CxI_sQ
多智能体强化学习算法理论研究
https://mp.weixin.qq.com/s/qnAXhfGb74ivRwlGcdApOQ
一文详解多智能体强化学习的基础和应用
https://mp.weixin.qq.com/s/4AfoQ6IBJ2rKbmKvYD1Dow
多Agent深度强化学习综述(中文版),21页pdf
https://mp.weixin.qq.com/s/KPS6RWtmeawR_vPAY4Bh1A
听说你的多智能体强化学习算法不work?那你用对MAPPO了吗?
https://mp.weixin.qq.com/s/qof0GWI3Jfsy3Tpc41wa4A
通过奖励随机化发现多智能体游戏中多样性策略行为,清华、UC伯克利等研究者提出全新算法RPG
https://mp.weixin.qq.com/s/aVDcwkcDkbU23MN4Wcf0mg
多智能体深度强化学习:综述
StarCraft
AIIDE(Artificial Intelligence and Interactive Digital Entertainment)
曾经有人设计出一种 “悍马2000(Automation 2000)”的脚本,极限APM达到15000(顶尖职业选手APM大约为200+),实现了一系列诸如“100只狗拆掉20辆坦克”、“机枪兵甩毒爆”、“无双运输机甩牛”等眼花缭乱的壮举。
https://mp.weixin.qq.com/s/zbki0baZw-NjAgZwKcfgFg
《星际争霸》与人工智能
https://mp.weixin.qq.com/s/Jdd7S6JFKRdsVe2w-W01IA
Facebook田渊栋开源游戏平台ELF,简化版《星际争霸》完美测试人工智能
https://mp.weixin.qq.com/s/QD6BdAB332xHoSH3dIfM5Q
学习顶级玩家Replay,人工智能学会了星际争霸的“大局观”
https://mp.weixin.qq.com/s/0Q-Kg6pNVRl3tqv8-wH-bg
Facebook开源史上最大星际争霸AI研究数据集
https://mp.weixin.qq.com/s/KbFvs8EcEfm29zhLCPt0Iw
DeepMind进军星际争霸2,谷歌Facebook打响通用AI战争
https://mp.weixin.qq.com/s/WTRD3wRQ_wSXjjlt7jiwSg
CommandCenter:基于暴雪官方API的星际争霸2 AI Bot
https://mp.weixin.qq.com/s/CQmZcwI4bgrEiWHP0gBLfQ
DeepMind星际争霸2开源机器学习平台入门
https://zhuanlan.zhihu.com/p/28434323
迈向通用人工智能:星际争霸2人工智能研究环境SC2LE完全入门指南
https://zhuanlan.zhihu.com/p/29246185
重现DeepMind星际争霸强化学习算法
https://mp.weixin.qq.com/s/vA9cHv73iHgTy9Q_bk4KCw
DeforGAN:用GAN实现星际争霸开全图外挂!
https://mp.weixin.qq.com/s/x0G-LNCano7qjGdpj-fpCQ
2017年度星际争霸AI竞赛结果出炉
https://mp.weixin.qq.com/s/AndV-htPeTXlpAm1GONNtA
中科院开源星际争霸2宏观运营研究数据集MSC

您的打赏,是对我的鼓励
