Deep Object Detection » 深度目标检测(四)——YOLO, SSD
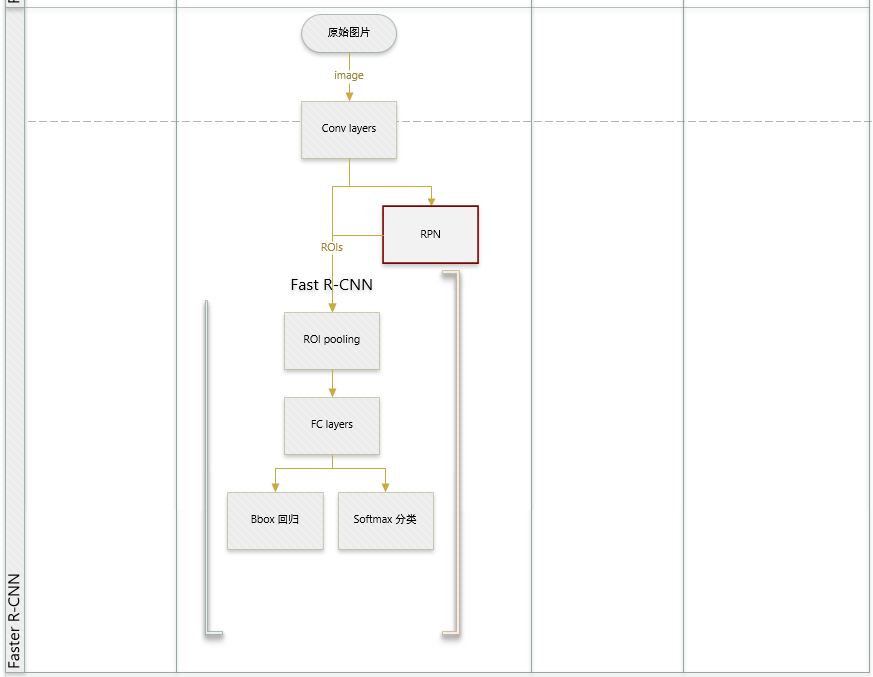
2018-11-20 :: 5880 WordsFaster R-CNN
RPN和Fast R-CNN协同训练(续)
数据不平衡问题
如果每幅图的所有anchor都去参与优化loss function,那么最终会因为负样本过多导致最终得到的模型对正样本预测准确率很低。因此,可在每幅图像中随机采样256个anchors去参与计算一次mini-batch的损失。正负比例1:1(如果正样本少于128则补充采样负样本)
总结
参考:
https://zhuanlan.zhihu.com/p/24916624
Faster R-CNN
http://blog.csdn.net/shenxiaolu1984/article/details/51152614
Faster RCNN算法详解
https://mp.weixin.qq.com/s/VKQufVUQ3TP5m7_2vOxnEQ
通过Faster R-CNN实现当前最佳的目标计数
https://zhuanlan.zhihu.com/p/31426458
一文读懂Faster RCNN
https://mp.weixin.qq.com/s/IZ9Q3fDJVawiEbD6x9WRLg
Object Detection系列(三)Fast R-CNN
https://mp.weixin.qq.com/s/M_i38L2brq69BYzmaPeJ9w
像玩乐高一样拆解Faster R-CNN:详解目标检测的实现过程
https://mp.weixin.qq.com/s/oTo12fgl1p5D7yzdfWIT8Q
使用Faster R-CNN、ResNet诊断皮肤病,深度学习再次超越人类专家
https://mp.weixin.qq.com/s/5OkPWPLRyf07mZwLRSZ3Fw
机器视觉目标检测补习贴之R-CNN系列—R-CNN,Fast R-CNN,Faster R-CNN
https://mp.weixin.qq.com/s/KL6gB0SsclyHqedS_tThXA
里程碑式成果Faster RCNN复现难?我们试了一下
YOLO
YOLO: Real-Time Object Detection,是一个基于神经网络的实时对象检测软件。它的原理基于Joseph Chet Redmon 2016年的论文:
《You Only Look Once: Unified, Real-Time Object Detection》
这也是Ross Girshick去Facebook之后,参与的又一力作。
官网:
https://pjreddie.com/darknet/yolo/
Joseph Chet Redmon,Middlebury College本科+华盛顿大学博士(在读)。网名:pjreddie。
pjreddie不仅是个算法达人,也是个造轮子的高手。YOLO的原始代码基于他本人编写的DL框架——darknet。
YOLO的caffe版本有很多(当然都是非官方的),这里推荐:
https://github.com/yeahkun/caffe-yolo
概述
从R-CNN到Fast R-CNN一直采用的思路是proposal+分类(proposal提供位置信息,分类提供类别信息),这也被称作two-stage cascade。
YOLO不仅是end-to-end,而且还提供了另一种更为直接的思路:直接在输出层回归bounding box的位置和bounding box所属的类别(整张图作为网络的输入,把Object Detection的问题转化成一个Regression问题)。

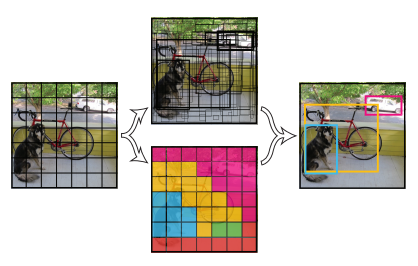
上图是YOLO的大致流程:
Step 1:Resize成448x448,图片分割得到7x7网格(cell)。
Step 2:CNN提取特征和预测:卷积部分负责提取特征,全连接部分负责预测。
a) 7x7x2=98个bounding box(bbox) 的坐标\(x_{center},y_{center},w,h\)和是否有物体的confidence。
b) 7x7=49个cell所属20个物体分类的概率。
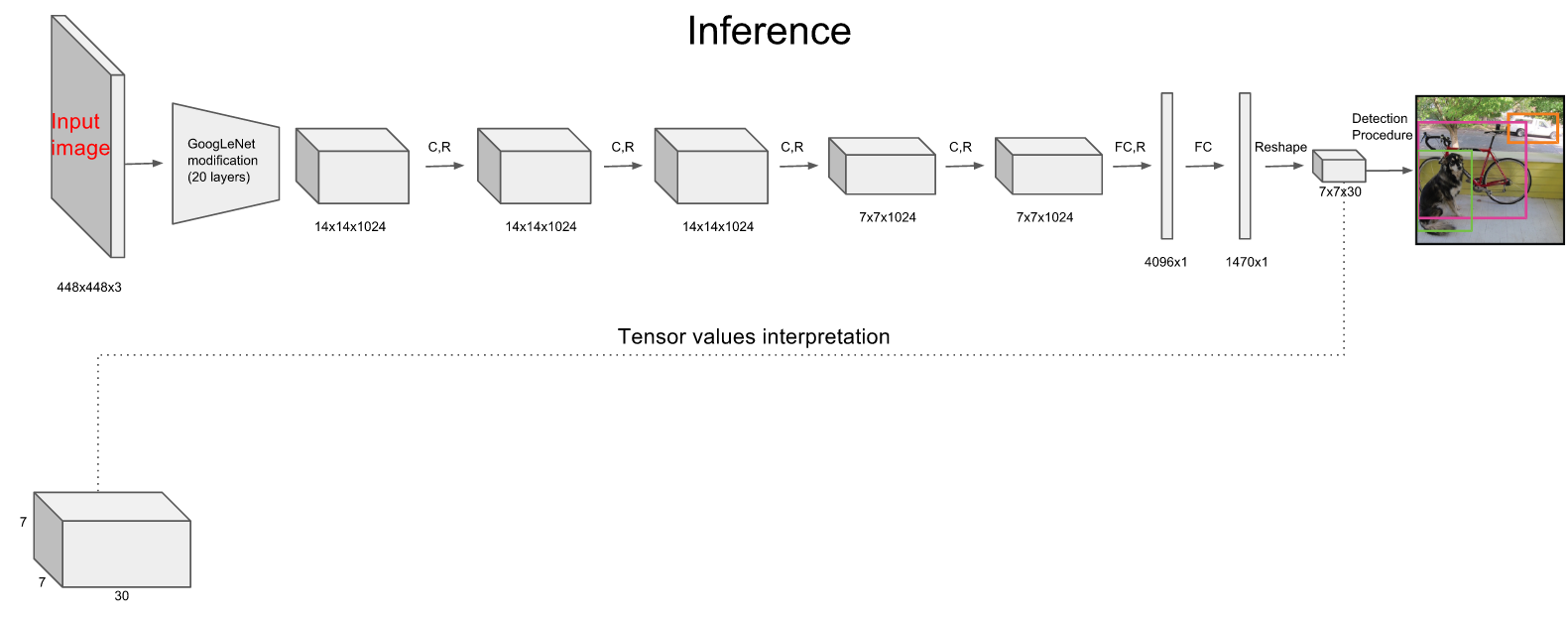
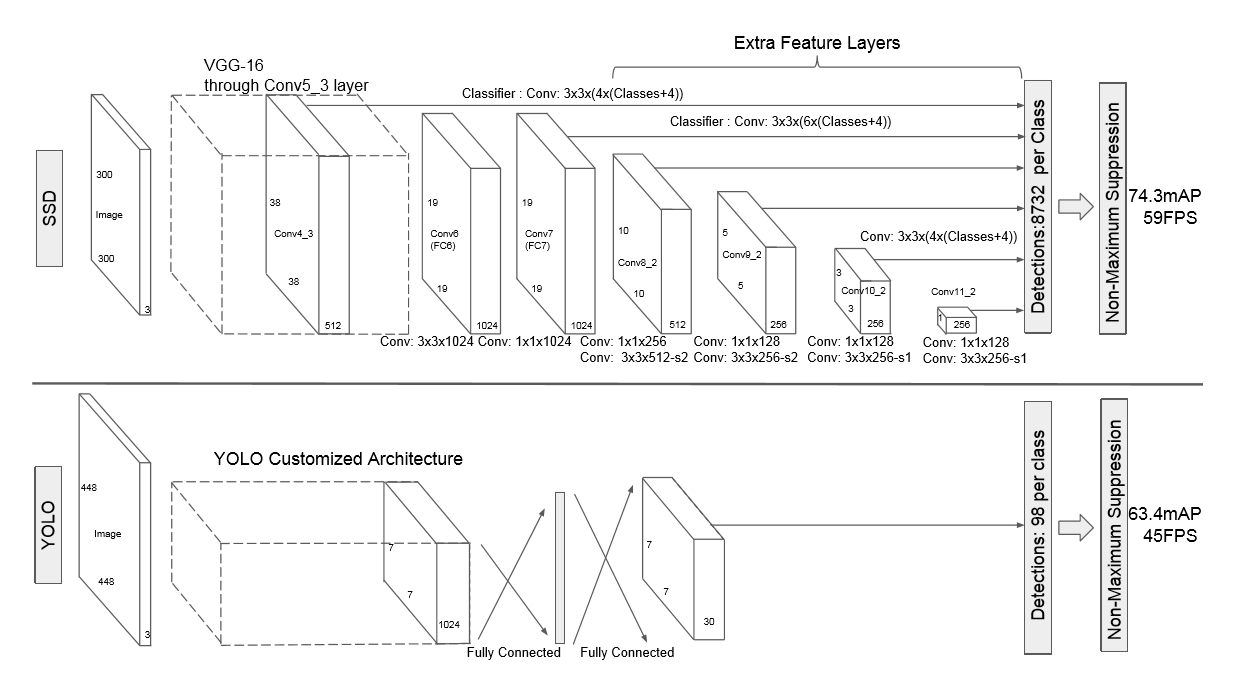
上图是YOLO的网络结构图,它采用经过修改的GoogLeNet作为base CNN。
从表面看,YOLO的输出只有一个,似乎比Faster RCNN两个输出少一个,然而这个输出本身,实际上要复杂的多。
YOLO的输出是一个7x7x30的tensor,其中7x7对应图片分割的7x7网格。30表明每个网格对应一个30维的向量。
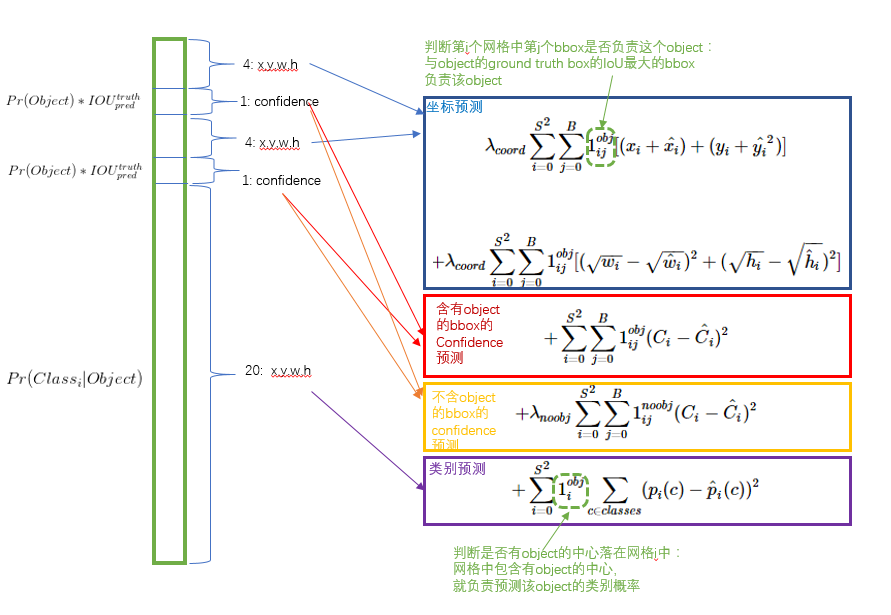
上图是这个30维向量的编码方式:2个bbox+confidence是5x2=10维,20个物体分类的概率占其余20维。
总结一下,输出tersor的维度是:\(S\times S \times (B \times 5 + C)\)
这里的confidence代表了所预测的box中含有两重信息:object的置信度和这个box预测的有多准。
\[\text{confidence} = \text{Pr}(Object) ∗ \text{IOU}_{pred}^{truth}\]在loss函数设计方面,简单的把结果堆在一起,然后认为它们的重要程度都一样,这显然是不合理的,每个loss项之前的参数\(\lambda\)就是用来设定权重的。
Step 3:过滤bbox(通过NMS)。
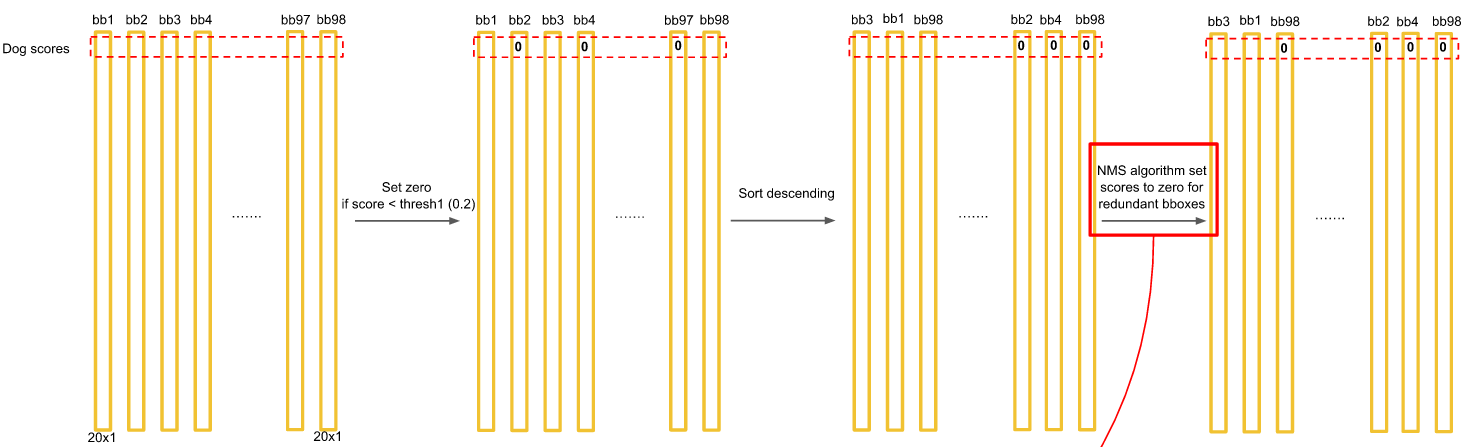
上图是Test阶段的NMS的过程示意图。
参考
https://zhuanlan.zhihu.com/p/24916786
图解YOLO
https://mp.weixin.qq.com/s/n51XtGAsaDDAatXYychXrg
YOLO比R-CNN快1000倍,比Fast R-CNN快100倍的实时对象检测!
http://blog.csdn.net/tangwei2014/article/details/50915317
论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
https://mp.weixin.qq.com/s/Wqj6EM33p-rjPIHnFKtmCw
计算机是怎样快速看懂图片的:比R-CNN快1000倍的YOLO算法
http://lanbing510.info/2017/08/28/YOLO-SSD.html
目标检测之YOLO,SSD
http://www.yeahkun.com/2016/09/06/object-detection-you-only-look-once-caffe-shi-xian/
Object detection: You Look Only Once(YOLO)
http://blog.csdn.net/zy1034092330/article/details/72807924
YOLO
https://mp.weixin.qq.com/s/c9yagjJIe-m07twPvIoPJA
YOLO算法的原理与实现
https://mp.weixin.qq.com/s/JKyX5cdvknIRoF341Au7Ew
单级式目标检测方法概述:YOLO与SSD
SSD
SSD是Wei Liu于2016年提出的算法。
论文:
《SSD: Single Shot MultiBox Detector》
代码:
https://github.com/weiliu89/caffe
Wei Liu,南京大学本科(2009)+北卡罗莱娜大学博士(在读)。
个人主页:
http://www.cs.unc.edu/~wliu/
网络结构
YOLO有一些缺陷:每个网格只预测一个物体,容易造成漏检;对于物体的尺度相对比较敏感,对于尺度变化较大的物体泛化能力较差。
针对YOLO中的这些不足,SSD在这两方面都有所改进,同时兼顾了mAP和实时性的要求。其思路就是Faster R-CNN+YOLO,利用YOLO的思路和Faster R-CNN的anchor box的思想。
上图是SSD的网络结构图。其特点为:
1.采用VGG16的基础网络结构,使用前面的前5层。
2.使用Dilated convolution将fc6和fc7层转化成两个卷积层。
3.再额外增加了3个卷积层,和一个average pool层。不同层次的feature map分别用于default box的偏移以及不同类别得分的预测。
4.通过NMS得到最终的检测结果。
这些增加的卷积层的feature map的大小变化比较大,允许能够检测出不同尺度下的物体:在低层的feature map,感受野比较小,高层的感受野比较大,在不同的feature map进行卷积,可以达到多尺度的目的。
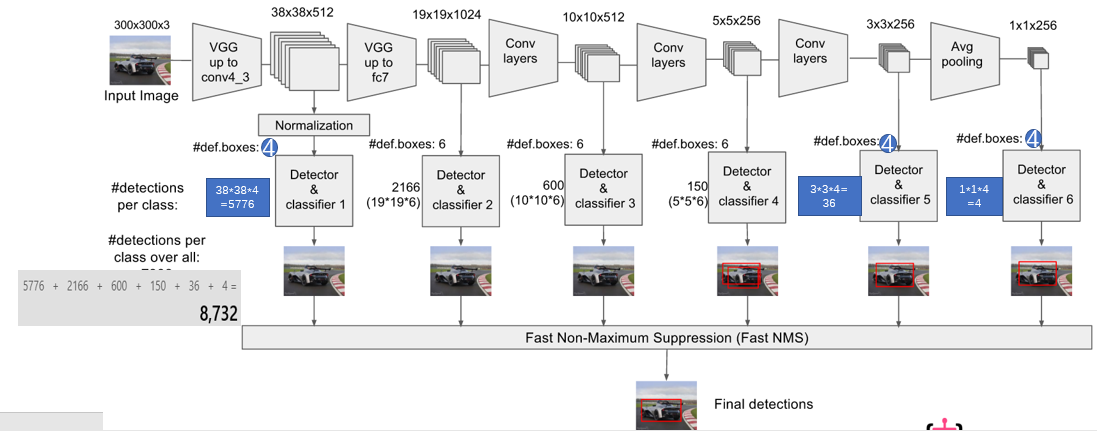
上图是从另一个角度观察SSD,可以看出SSD可检出8372个default box(也叫做prior box)。这里沿用Faster R-CNN的Anchor方法生成default box。
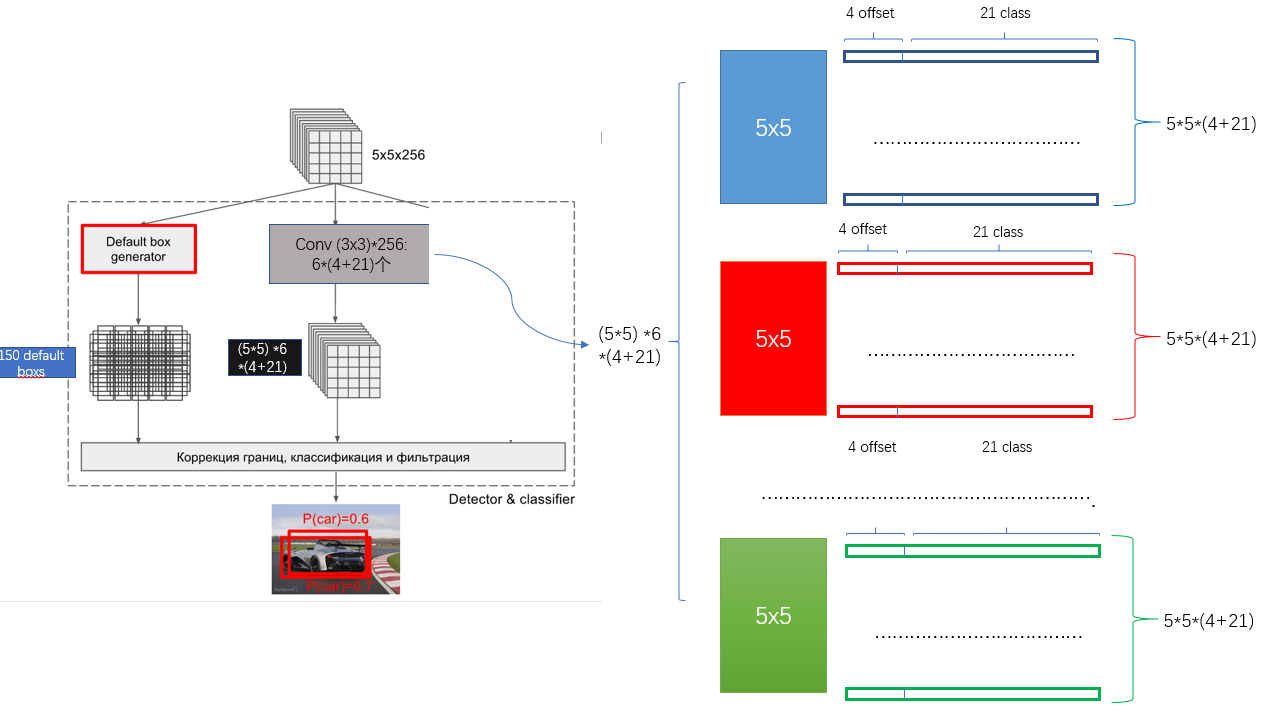
和YOLO一样,卷积层的每个点都是一个vector,含义也和YOLO类似,只是分类的时候,多了一个背景的类别,所以就成了20+1类。
在YOLO中,由于每个格子只有1个default box,所以对于一个格子中包含两个物体的情况是无能为力的。SSD的Anchor方法略微改善了这方面的性能,但对于超过Anchor数量的情况,仍然无能为力。因此,这两者对于小目标的检测,没有RCNN系列算法的效果好。
训练策略
监督学习训练的关键点:如何把标注信息(ground true box,ground true category)映射到(default box上)?
正负样本
与ground truth box的IOU大于0.5的default box,被定为该ground truth box的正样本,其它的default box则为负样本。
而一般的MultiBox算法中,只有IOU最大的default box才是正样本。
显然,在SSD中,一个ground truth box可能对应多个default box。
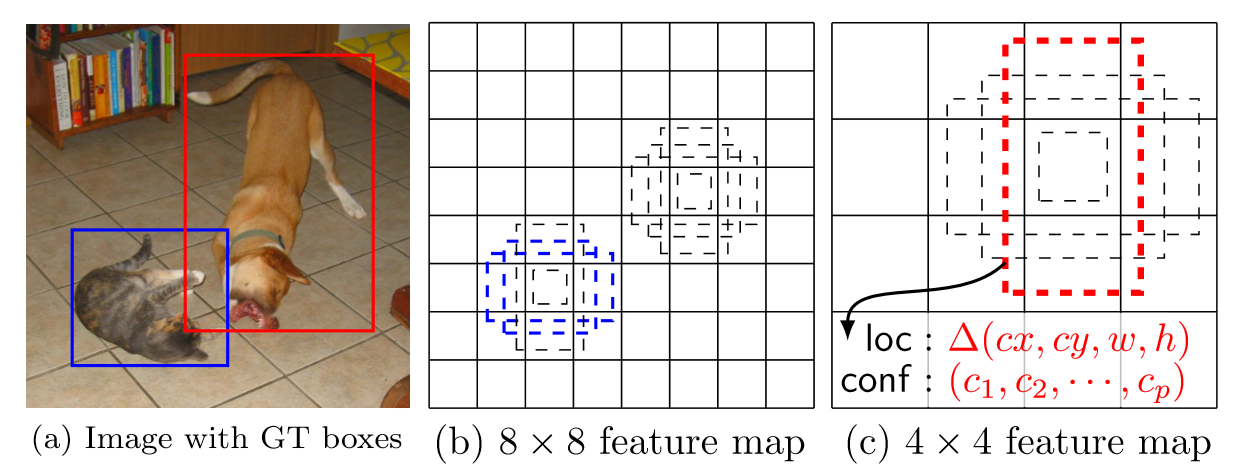
例如上图,有两个default box与猫匹配,一个default box与狗匹配。
Hard Negative Mining
Hard Negative Mining是机器学习领域的一个常用技巧。
对于正负样本数量不均衡的数据集(这里假设负样本数量远大于正样本数量),通常的做法有:
1.增加正样本的数量。这个过程通常叫做数据增强(Data Augmentation)。例如对图片进行旋转、位移得到新的正样本。
2.减少负样本的数量。这里实际上是一个筛选有价值的负样本的过程。Hard Negative Mining就属于这类方法,它认为负样本的分数越高,越有价值。
具体到图像分类任务就是:那些不包含该物体但分值却很高的样本。通俗的讲,就是那些容易被混淆的负样本。
3.修改正负判定门限,以匹配正负样本比例。例如,提高IOU门限。
4.异常点检测。
在SSD中,用于预测的feature map上的每个点都对应有6个不同的default box,绝大部分的default box都是负样本,导致了正负样本不平衡。
在训练过程中,采用了Hard Negative Mining的策略(根据confidence loss对所有的box进行排序,使正负例的比例保持在1:3)来平衡正负样本的比率。
参考:
https://mp.weixin.qq.com/s/D0JaJaHeNX4kljSTxTsAAw
一文概览卷积神经网络中的类别不均衡问题
https://mp.weixin.qq.com/s/ZRwr4lIyi3EHafuNAwUrLw
Soft Sampling:探索更有效的采样策略
Caffe实现的细节问题
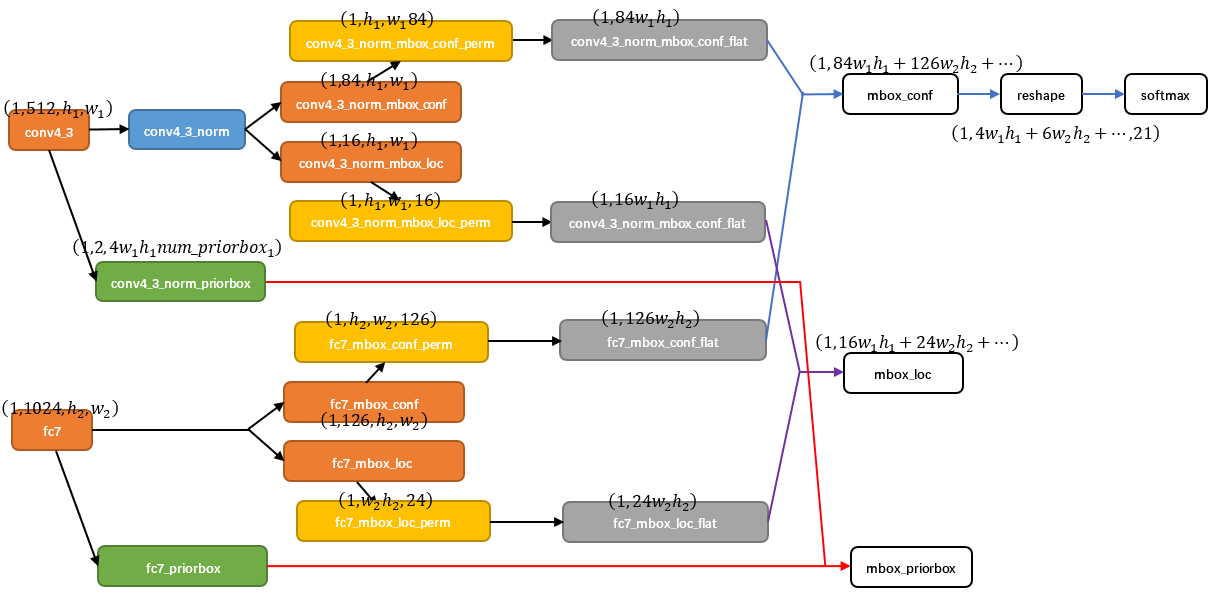
上图是SSD末端的caffe结构图。我们注意到在flatten之前有个permute的操作。这个实际上还是和caffe blob的格式有关。
只有flatten的效果:[B, CxHxW]
permute+flatten的效果:[B, HxWxC]
C在最后,意味着同一个点的不同通道的信息挨着放在一起,从而保证了信息的局部空间性保持不变。
显然,这里如果是TensorFlow的tensor结构的话,permute就没有存在的必要了。
参考
http://www.jianshu.com/p/ebebfcd274e6
Caffe-SSD训练自己的数据集教程
https://zhuanlan.zhihu.com/p/24954433
SSD
http://blog.csdn.net/zy1034092330/article/details/72862030
SSD详解
http://blog.csdn.net/jesse_mx/article/details/74011886
SSD模型fine-tune和网络架构
http://blog.csdn.net/u010167269/article/details/52563573
SSD论文阅读
http://blog.csdn.net/zijin0802034/article/details/53288773
另一个SSD论文阅读
http://www.lai18.com/content/24600342.html
还是一个SSD论文阅读
https://www.zhihu.com/question/49455386
为什么SSD(Single Shot MultiBox Detector)对小目标的检测效果不好?
https://mp.weixin.qq.com/s/hGRZzNzflbed2w4XosC40w
使用SSD进行目标检测
https://mp.weixin.qq.com/s/vfC1FPi8sjatFh2HMjTEXQ
目标检测算法之SSD

您的打赏,是对我的鼓励
